

全文共2751字,预计学习时长8分钟

来源:Pexels
Notebook是数据科学家最好的朋友,也可能是工作上的一大噩梦。对于习惯于使用现代集成开发环境(IDEs)的人来说,使用Notebook感觉就像回到了几十年前。此外,现代Notebook运行环境大多受限于Python程序,并且缺乏其他编程语言的一流支持。
但几天前,Netflix开源了Polynote,这是一个全新的Notebook环境,可以应对其中的一些挑战。
Polynote的出现是为了实现加速Netflix数据科学实验的需求。多年来,Netflix建立了世界一流的机器学习平台,该平台主要基于Scala等JVM语言。Jupyter Notebooks等主流技术对这些语言的支持从根本上来说是基础,因此需要更好的解决方案。Polynote的出现是为了满足这一基本要求,但它汲取了在数据科学领域中搭建最具雄心的Notebook实验平台时所获得的经验教训。

Netflix的Notebook驱动器内部架构
在过去的几年中,Netflix转变了数据科学Notebook的使用方式,从实验制品转变成了机器学习解决方案中生命周期的关键组成部分。最初,Netflix将Jupyter Notebooks作为数据探索和分析的工具。但是,工程团队很快意识到Jupyter在运行时间抽象化、可扩展性、代码的可解释性和调试方面有着明显的优势,如果使用得当,可能会对数据科学工作量产生重大影响。为了扩大Jupyter在数据科学运行时间方面的使用,Netflix团队需要解决一些主要挑战:
- 代码输出不匹配:Notebook经常需要更换,在很多情况下,在运行环境中看到的输出与当前代码并不对应。
- 服务器要求:Notebook通常需要Notebook服务器运行,这在Notebook大规模使用时会带来架构上的挑战。
- 计划:大多数数据科学模型需要定期执行,但是用于计划Notebook的工具仍然相当有限。
- 参数化:Notebook是相当静态的代码环境,传递输入参数的过程绝非易事。
- 集成测试:Notebook是孤立的代码环境,众所周知,它很难与其他Notebook相互集成。因此,使用Notebook时,集成测试等任务将是一大噩梦。
为了满足这些要求,Netflix建立了一个雄心勃勃的架构,可以使Jupyter Notebooks投入运营。最初可以实现包括诸如“Papermill”之类的技术,该技术可实现Notebook的参数化。
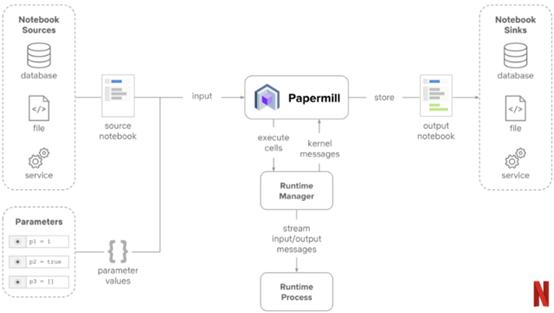
尽管Netflix最初的Notebook架构确实雄心勃勃,但也限制了Python程序,但现在改进后,可以进一步延伸了。
进入Polynote
Polynote是一个多语言Notebook实验环境。除了Python,当前版本还支持SQL,Vega(visualizations),当然还有Scala等语言。该平台还与数据科学基础架构(例如ApacheSpark)集成在一起。Polynote的核心包括以下功能:
a)改进的编辑经验:Polynote尝试让编辑体验更接近现代IDE。
b)多国语言支持:Polynote提供对Scala和数据科学环境中其他语言的一流支持。
c)数据可视化方面的改进:Polynote无需添加大量代码即可将本机数据可视化,并集成到Notebook的数据集中。
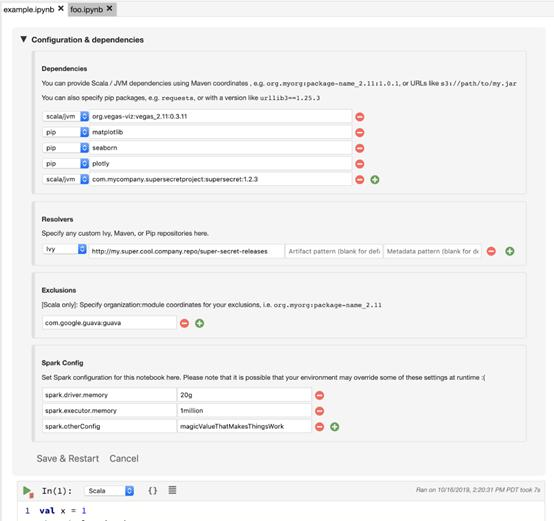
d)配置和依赖项管理:诸如Scala之类的语言在程序中需要复杂的程序包依赖项。Polynote将包依赖项配置保存在Notebook中,以解决JVM开发人员在该领域遇到的一些常见问题。
e)可重复性:将代码、数据和执行结果组合到一个文档中,可以使Notebook功能更加强大,但也难以复制。Polynote的可重复性是框架的一流功能。
a)改进的编辑经验
Polynote包含IDE中的常见功能,例如代码自动补全或语法错误高亮显示,从而改进了数据科学家和研究人员新建Notebook的体验。更多的编辑功能由Monaco编辑器提供,该编辑器可以支持Visual Studio Code的体验。
b)多国语言支持:
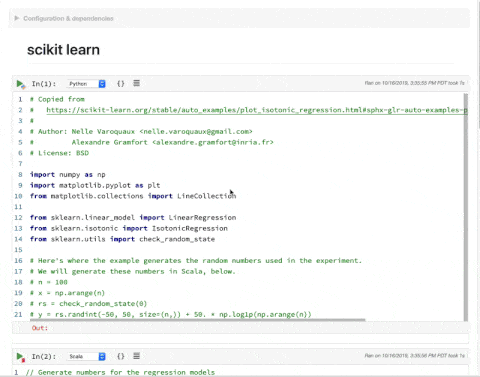
Polynote不仅对多种语言提供支持,而且还可将这些语言组合在一个程序中。在Polynote中,每个单元(cell)可以基于不同的语言。运行单元时,内核会向单元的语言解释器提供可用的类型化输入值,而解释器将结果输入的输出值返回到内核。这让PolynoteNotebook中的单元可以在相同的情境中运行。下面的示例呈现了一个Python库,用于计算使用Scala生成的数据集的保序回归(isotonic regression)。
c)数据可视化方面的改进:
数据可视化是大多数Notebook运行环境中的常见组件。但是,Polynote通过把可视化价值主张包含在平台的本机组件中,将可视化价值主张提升到另一层次,该平台不需要开发人员编写任何代码即可直观地探索数据集。
d)配置和依赖项管理
大多数时候,使用Notebook的数据科学家都可以享受Python程序包管理模型中处理程序依赖项的高效率。但是,在像Scala这样的JVM语言中,依赖项管理可能会是一大噩梦。Polynote通过将配置和依赖项直接存储在Notebook中而无需依赖外部文件,可以解决这一挑战。此外,Polynote还提供了一个用户友好型的“配置”部分,用户可以在其中为每个Notebook设置依赖项。
e)可重复性
借助Polynote,Netflix有一个新的代码解释模块,而无需像传统Notebook那样依赖REPL模型。新解释模型的一个关键功能就是消除了隐藏状态,这使数据科学家可以在Notebook中复制单元而无需从先前位置引入任何状态。
Polynote是雄心勃勃的数据科学Notebook竞争中的一个新版本,但它有自己的优点。基于JVM语言的支持可让使Polynote成为致力于Spark基础结构开发人员的最爱。同样,编辑和可重复性功能无疑是对传统Notebook环境的增强。
Polynote可以在Github上找到,也可以关注该项目的网站。


留言 点赞 关注
我们一起分享AI学习与发展的干货
欢迎关注全平台AI垂类自媒体 “读芯术”

(添加小编微信:dxsxbb,加入读者圈,一起讨论最新鲜的人工智能科技哦~)
