

文章首发于公众号【大数据学徒】,感兴趣请搜索 dashujuxuetu 或者文末扫码关注。
本文介绍 Kafka 中的数据是如何存储的,了解这个有利于理解 Kafka 中的数据过期机制、容错机制以及优化相关配置,希望对你有用。
本文思维导图如下:
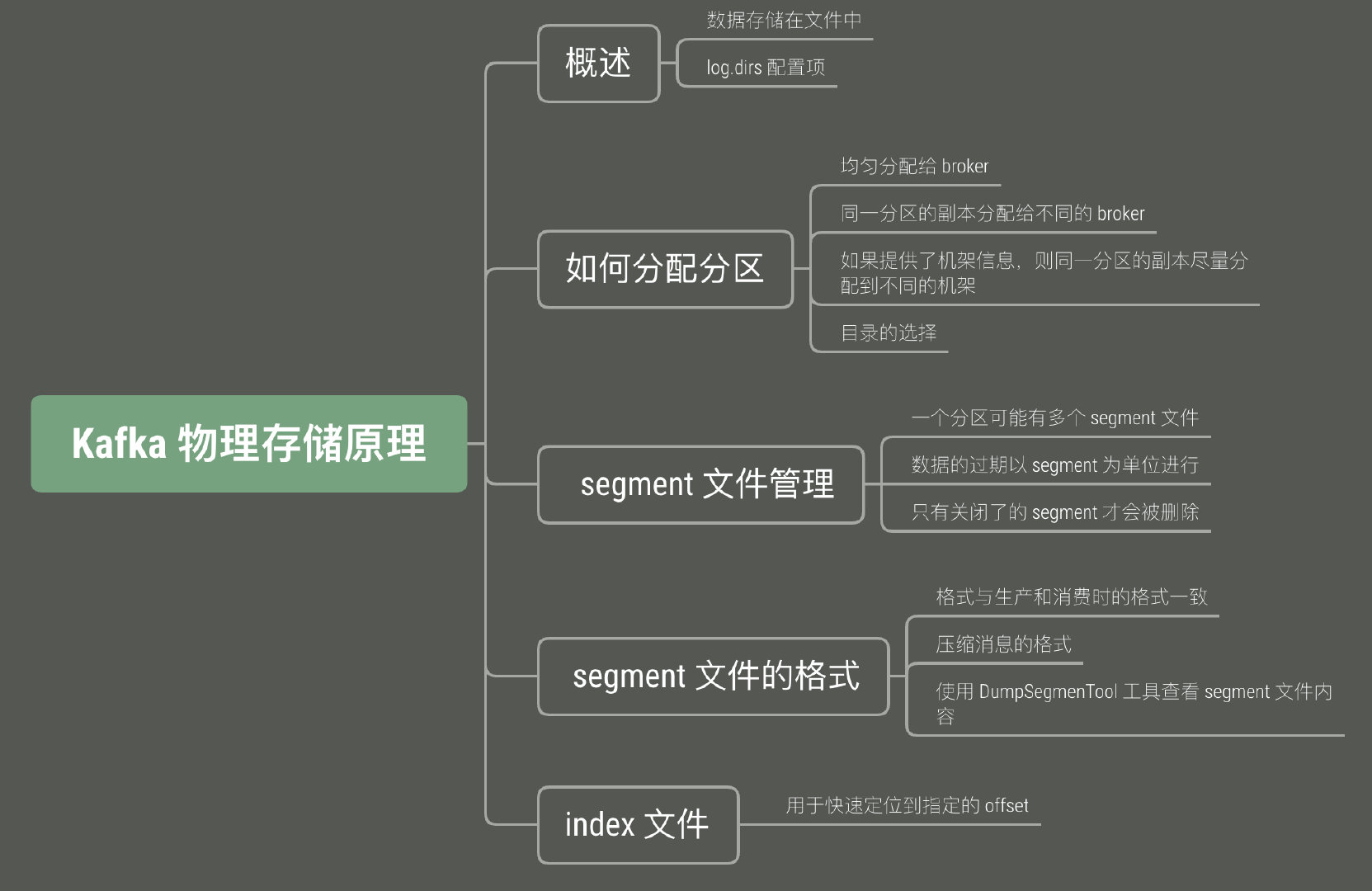
1. 物理存储概述
Kafka 通过文件的方式保存所有的 topic 数据,或者更准确的说法,保存分区副本。broker 有一个参数叫做 log.dirs ,这个参数的值是若干个逗号分隔的目录,比如 /first/kafka-logs,/second/kafka-logs,/third/kafka-logs ,注意不要和 Kafka 自身运行输出的日志搞混,那些日志的存储位置定义在 log4j.properties 里。
2. 如何分配分区
无机架信息
创建一个 topic 时,会指定分区数和副本数,然后 Kafka 需要决定这些副本应该分布在哪些 broker 上,分配的目标是:
- 均匀,尽量让每个 broker 上的副本数目一样多;
- 高可用,尽量将同一分区的多个副本分配到不同的 broker;
- 如果 broker 配置了机架的信息,那么也尽可能将每个分区的副本分配到不同的机架,以防一个机架出现故障造成整个分区的下线。
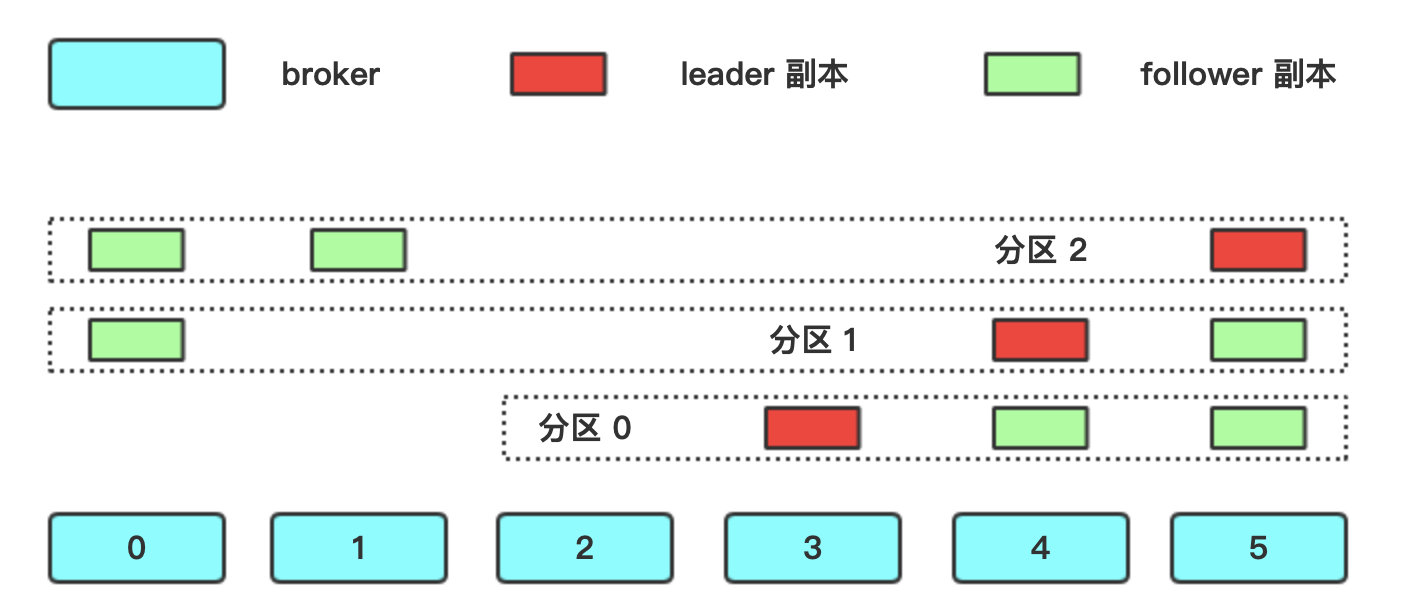
举个例子,假设我们有 6 台 broker,ID 分别为 0,1,2,3,4,5,现在要创建一个 3 分区、3 副本的 topic,怎么分配呢?过程如下:
- 按照分区顺序一个一个来,先分配分区 0 的 leader,为它随机选一个 broker,假设选择了 broker 3,那么分区 0 的第一个副本存储在 broker 4,第二个副本存储在 broker 5;
- 然后分配分区 1,因为分区 0 的 leader 在 broker 3 上,所以分区 1 的 leader 在 broker 4 上,然后两个 follower 副本分别在 broker 5 和 broker 0 上;
- 最后分配分区 2,leader 副本在 broker 5 上,两个 follower 副本分别在 broker 0 和 broker 1 上;
用图表示一下:
再用一个生产环境的例子来看一下,这是在 kafka-manager 里看到的一个 topic 各个分区的分布情况:

可以看到,和理论是一致的。
有机架信息
broker 有一个参数叫做 broker.rack,是一个字符串,用来配置每台 broker 所在的机架名称。当 broker 配置了这个参数之后,基本的分配分区的方式仍然不变,只是 broker 的排列方式有所调整。假设现在有两个机架,6 台 broker,还是来分配 3 分区、3 副本的 topic,如图所示:
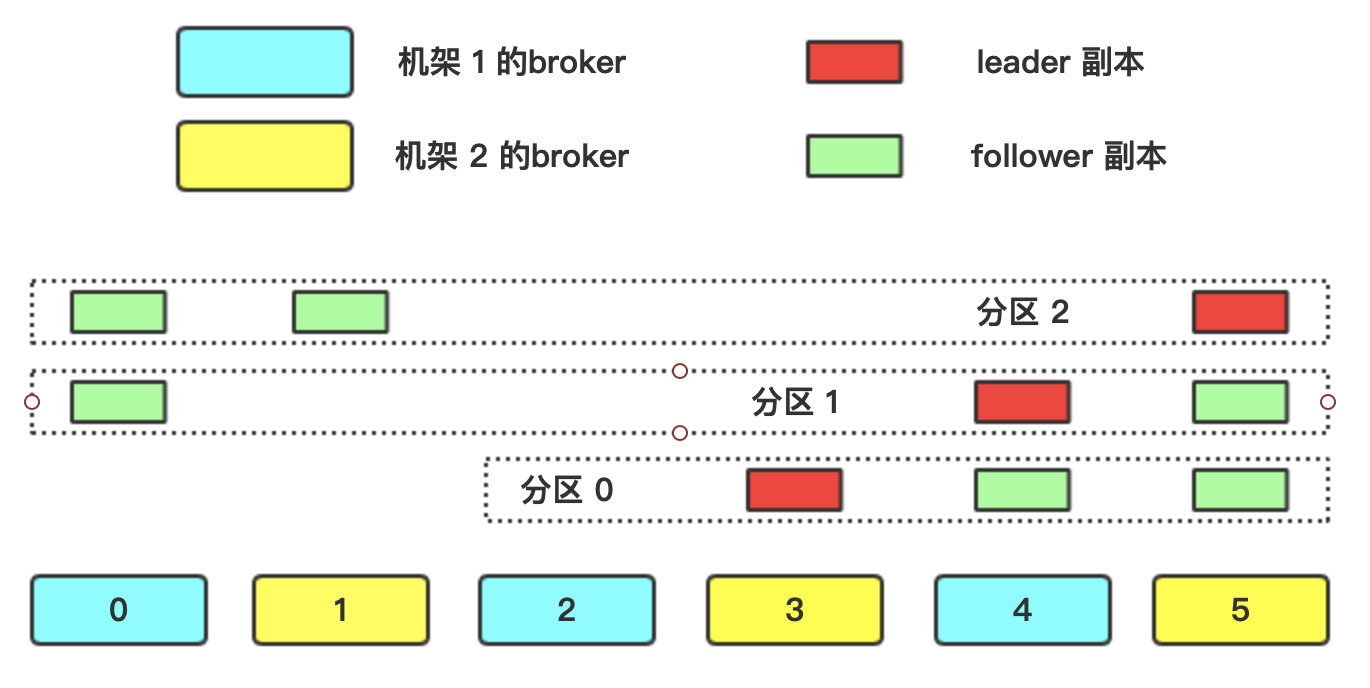
相比于无机架信息时的分配方式,只需要多做一个步骤:排列 broker 时尽量让每个 broker 和不同机架的 broker 相邻,因为同一分区的不同副本都是分配给相邻的 broker,这样做就可以保证副本会分布在不同机架上,避免了一个机架出现故障(比如掉电、断网),整个分区都不可用。注意:所说的排列是逻辑上的排列。
为分区副本选择 broker 的工作是由 controller 完成的。
目录的选择
当分区分配到了具体的 broker 后,broker 还需要选择将分区的数据存储在哪个目录(因为 log.dirs 一般都配置了多个目录),选择的方式很简单:哪个目录下的分区数最少,就将新的分区存储在哪个目录,似乎简单粗暴,注意,这种方式既没有考虑每个目录的总大小,也没有考虑每个目录的已用大小,因此会出现不均衡的情况。
3. 文件管理
每个分区的数据都存储在一个单独的目录下,目录名为 topic名-分区数,比如 iamabug 这个 topic 的第 0 个分区的目录名称就是 iamabug-0。在这个目录下,存储了这个分区的数据,但是分区数据并不是存储在一个文件里,而是分布在多个 segment 文件,为什么呢?
Kafka 是一个消息队列,并不是一个永久的存储系统,数据是有过期时间的,数据过期之后需要被删除,过期的判断要么根据时间要么根据大小,但是将数据从一个大文件中删除非常耗时并且容易出错,因此采用了一个更科学的方法,将每个分区的数据存储在多个 segment 文件中,以 segment 作为数据过期的基本单位,如果某个 segment 文件过期,直接把它删除即可。
segment 文件有两种状态:活跃状态和关闭状态,正在写入数据的 segment 处于活跃状态,活跃状态的 segment 文件不会被删除,当一个 segment 文件达到一定的大小或者有一段时间没有写入数据时,它就会被关闭,关闭的大小和时间分别由 log.segment.bytes 和 log.segment.ms 这两个参数控制,默认只设置了大小,值为 1G,当两个参数都设置时,有一个条件满足,这个 segment 文件就会被关闭。
注意:broker 对每个 segment 文件都持有一个文件句柄,即使是关闭的,所以需要小心调节操作系统的文件句柄相关参数。
4. 文件格式
格式说明
在每个 segment 文件里,存储了消息和对应的 offset,并且存储的格式和生产者向 broker生产 以及消费者从 broker 消费时的消息格式是一样的,这保证了 broker 向消费者发送消息时可以使用“零拷贝”技术,且避免了数据的压缩与解压(因为生产者发送的就是压缩过后的消息)。
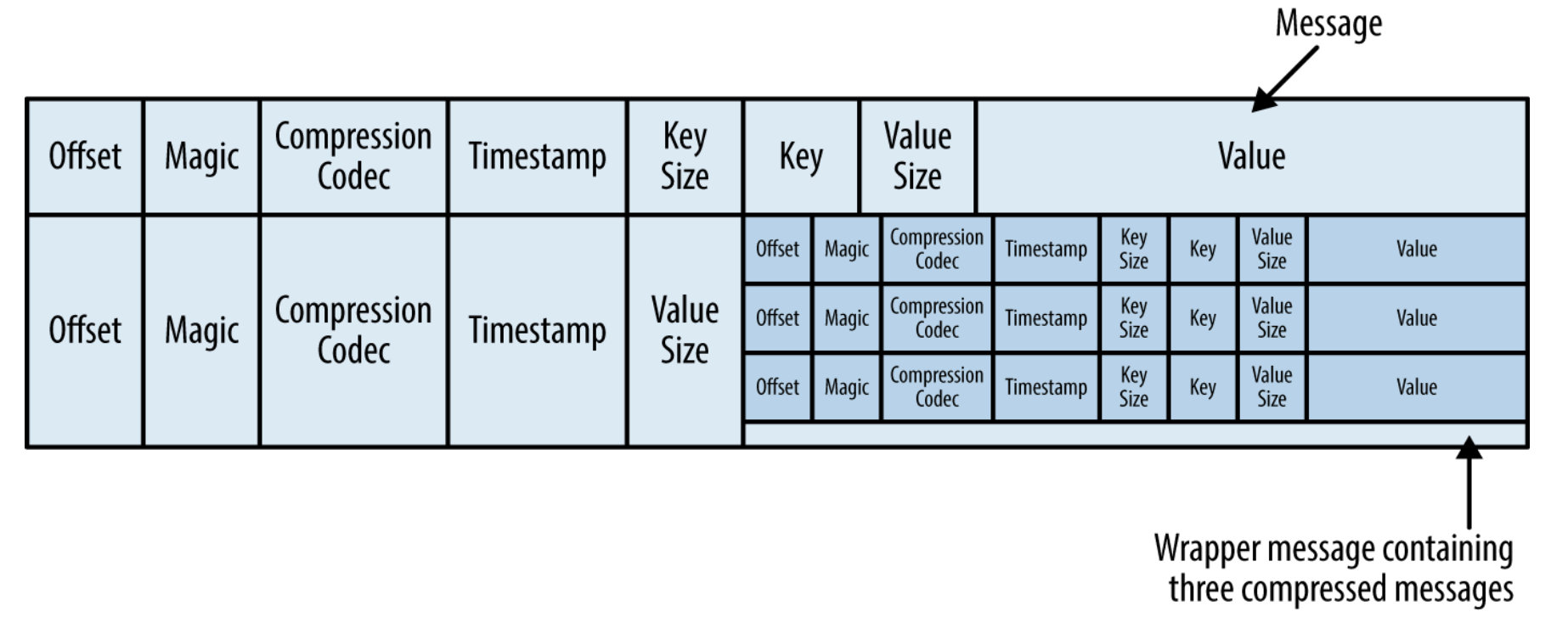
每条消息除了消息的 key、value 和 offset之外,还有消息大小、校验码、消息格式的版本、压缩格式和时间戳,时间戳可以是生产者发送时的时间戳,也可以是 broker 接收时的时间戳,由 log.message.timestamp.type 参数决定,可配置的值为 CreateTime 和 LogAppendTime。
当生产发送压缩的消息时,压缩了的多条消息被当做是一条消息,并且在这条消息内部,会包含每条消息原来的信息。具体的格式如下图所示:
实操验证
Kafka 提供了一个工具可以查看 segment 文件的内容,名为 DumpLogSegment,下面来验证一下,首先创建了一个名为 iamabug 的 topic,向里面写入几条消息,然后查看 segment 文件的内容:
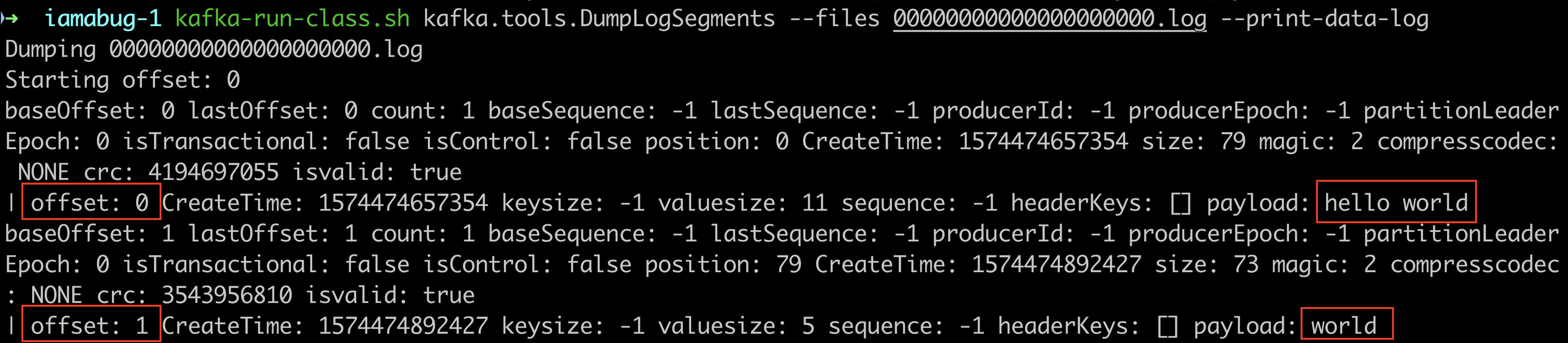
可以看到,和上面说的基本一致,但是字段更多。
5. 索引文件
因为 Kafka 支持消费者从任意指定的 offset 开始消费,所以 broker 要能够快速的定位消息,方法就是为每个 segment 文件建立索引文件。segment 文件的后缀是 .log,索引文件的后缀是 .index,两者的前缀相同,都是文件中第一条消息的 offset,在索引文件的内部则记录了 topic 的 offset 和实际数据在 segment 文件中的字节偏移量。
当需要定位一个指定的 offset 时,首先根据 .index 文件的前缀进行比较,找到合适的 .index 文件,然后查看这个 .index 文件的内容,找到指定的 offset 和对应的文件偏移量,根据这个偏移量直接在 .log 文件中 seek 到对应的位置,读取数据即可。这是一个简化的说法,实际上并不是每个偏移量可以找到的,因为 Kafka 实际上建立的是稀疏索引,有的时候需要找一个最接近的 offset,然后在 .log 文件中逐条消息查找。
索引文件中没有校验码,当发现存在数据异常或损坏时,broker 会直接重新生成索引文件。
注意:我试了下直接删除一个 topic 分区下的一个索引文件,结果没有立马生成,尝试生产和消费这个 topic也没有生成,重启 broker 倒是会重新生成索引文件。
欢迎交流讨论,吐槽建议,分享收藏。
勤学似春起之苗,不见其增,日有所长 辍学如磨刀之石,不见其损,日有所亏 关注【大数据学徒】,用技术干货助你日有所长
