

一直希望能够深入的学习一下 Spark 相关的用法和原理,除了懒的原因之外,有一个重要的原因是实验环境的搭建太麻烦,光是 Spark 还好,但是用了 Spark 不用 HDFS 吗?Hive 呢?这样一来,有大量的时间倒会花在维护这个环境上,得不偿失。解决环境问题的杀器是什么?容器。其实我一直想抽空写 Spark 和 Kafka 的 Dockerfile,把各种乱七八糟的问题全在容器里解决,苦于没有时间和怕麻烦而已。虽然计划的文章内容泡汤了,但是找到了这个 All-In-One 的工具,名为 docker-hadoop-spark-workbench,它用 docker-compose 将 Hadoop、Spark、Hive、Hue 还有 Spark-Notebook 全部组装起来了,这是一个非常好的思路,虽然在文章中可以看到,这个工具还有待完善,但知道有这么个东西也挺好的,我会持续跟进并完善这个项目。
为了行文方便,本文将 docker-hadoop-spark-workbench 简称为 DHSW。
内容提要:
- 环境说明
- DHSW 的安装启动
- DHSW 的访问方法
- 通过 DHSW 完成 WordCount(遇到困难)
- 总结
1. 环境说明
- 操作系统:不限
- docker:必须,如果没有安装,可以参考:docs.docker.com/v17.09/engi…
- docker-compose:必须,如果没有安装,可以参考:docs.scala-lang.org/getting-sta…
2. DHSW 的安装启动
克隆项目
在合适的路径下克隆该项目:
git clone https://github.com/big-data-europe/docker-hadoop-spark-workbench
docker-compose 启动
cd docker-hadoop-spark-workbench
docker-compose up -d
因为组件比较多,拉取镜像需要较长时间,我前前后后大概用了一个小时。
在拉取镜像的过程中,有一个错出现了好几次,报错信息为:
ERROR: for namenode failed to register layer: Error processing tar file(exit status 1): write /opt/hadoop-2.8.0/share/doc/hadoop/hadoop-project-dist/hadoop-hdfs/api/src-html/org/apache/hadoop/hdfs/server/namenode/FsImageProto.SecretManagerSection.DelegationKey.html: no space left on device
搜索出来的原因是 inode 数耗尽,解决方法为:
curl -s https://raw.githubusercontent.com/ZZROTDesign/docker-clean/v2.0.4/docker-clean |
sudo tee /usr/local/bin/docker-clean > /dev/null && \
sudo chmod +x /usr/local/bin/docker-clean \
docker-clean
不过这个问题并没有完全解决,然后我又增大了 Docker 的 disk image size ,由 60G 增大到了 110G,不太确定是否相关,但最终不再报错。
来看下启动时的情况:
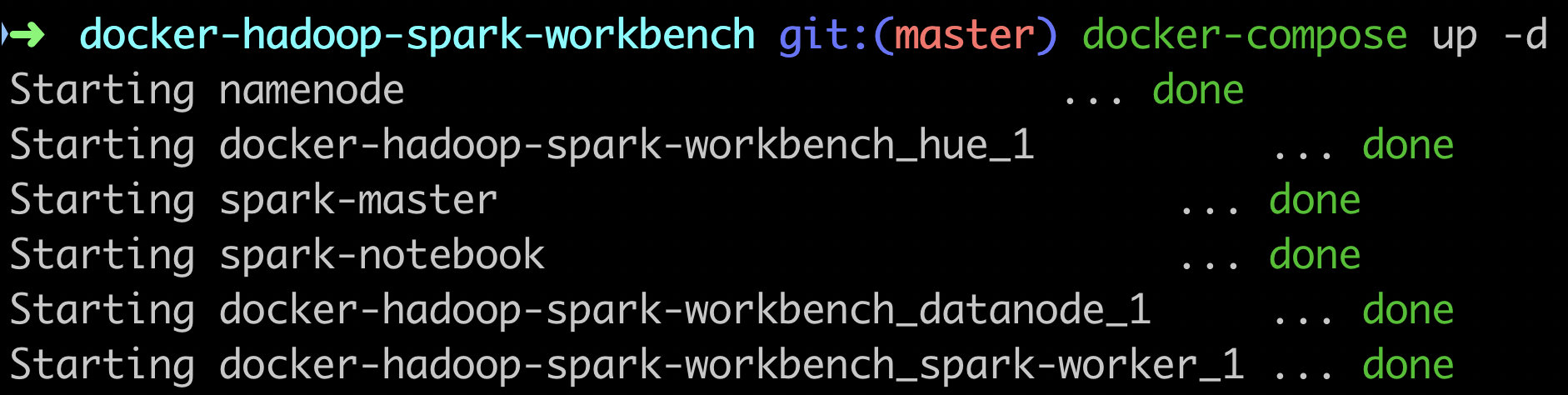
DHSW 总共启动了 6 个容器,分别是 HDFS 的 Namenode 和 Datanode,Spark 的 Master 和 Worker,Hue 以及 Spark-Notebook。
3. DHSW 的访问方法
每个容器除了可以通过 docker 的命令进入之外,都可以通过浏览器访问:
| 容器 | 访问地址 |
|---|---|
| HDFS Namenode | http://localhost:50070 |
| HDFS Datanode | http://localhost:50075 |
| Spark Master | http://localhost:8080 |
| Spark Notebook | http://localhost:9001 |
| Hue(HDFS Filebrowser) | http://localhost:8088/home |
如果本地这些端口已经被占用的话,可能需要做些调整。
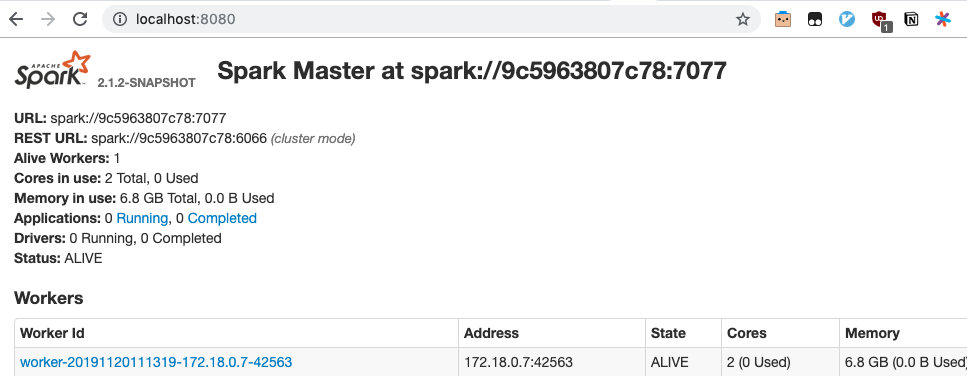
其实 Namenode 和 Datanode 没什么好看的,主要是下面三个,分别来一张图:
Spark Master:
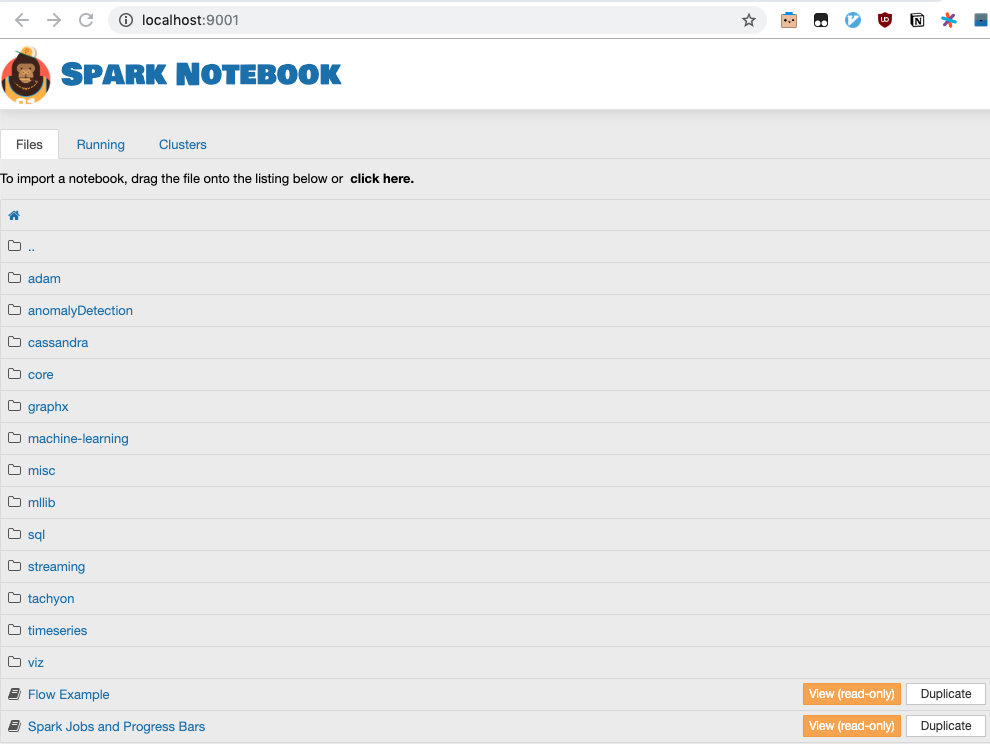
Spark Notebook:
Hue(HDFS Filebrowser,用 admin/admin 登录):
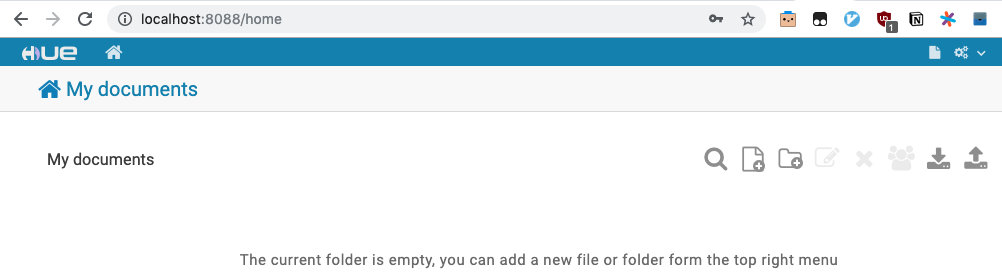
其实也都是熟悉的面孔。
Spark-Notebook 可能是一个新面孔,但它其实和 Jupyter Notebook 和 Apache Zeppelin 都很接近,可以在浏览器中非常方便的编写 Scala 代码,查询 SQL,结果实时反馈,交互性强,并且图表可视化功能非常强,感兴趣可以进一步了解:github.com/spark-noteb…
4. 通过 DHSW 完成 WordCount
下面用经典的 WordCount 例子来演示它的使用方法,这个例子会将各个组件联系起来。
通过 Hue 上传文件到 HDFS
点击 Hue 页面右上角的 HDFS Browser 按钮,出现 admin 用户的文件目录,点击 Upload,上传文件,我选择了一个 README.md,上传后这个文件就存在容器内的 HDFS 上:
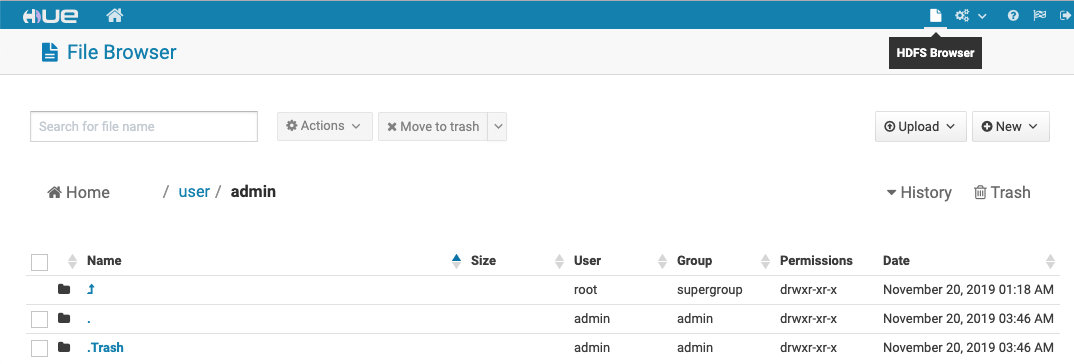
在 HDFS 中查看上传的文件
通过 docker ps 查看 Namenode 或者 Datanode 的容器 ID,然后用 docker exec -it <container-ID> bash 进入容器,查看 /user/admin 路径下的文件:

果然,文件已经上传。
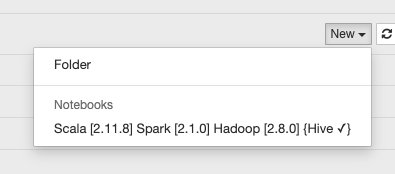
在 Spark-Notebook 中编写 Scala 代码
点击 Spark-Notebook 的页面右侧的New 按钮,选择 Scala...:
然后在弹出的对话框中输入 Notebook 的名字,点击确定:
然后开始在 Notebook 中编写代码,写一行运行一行:
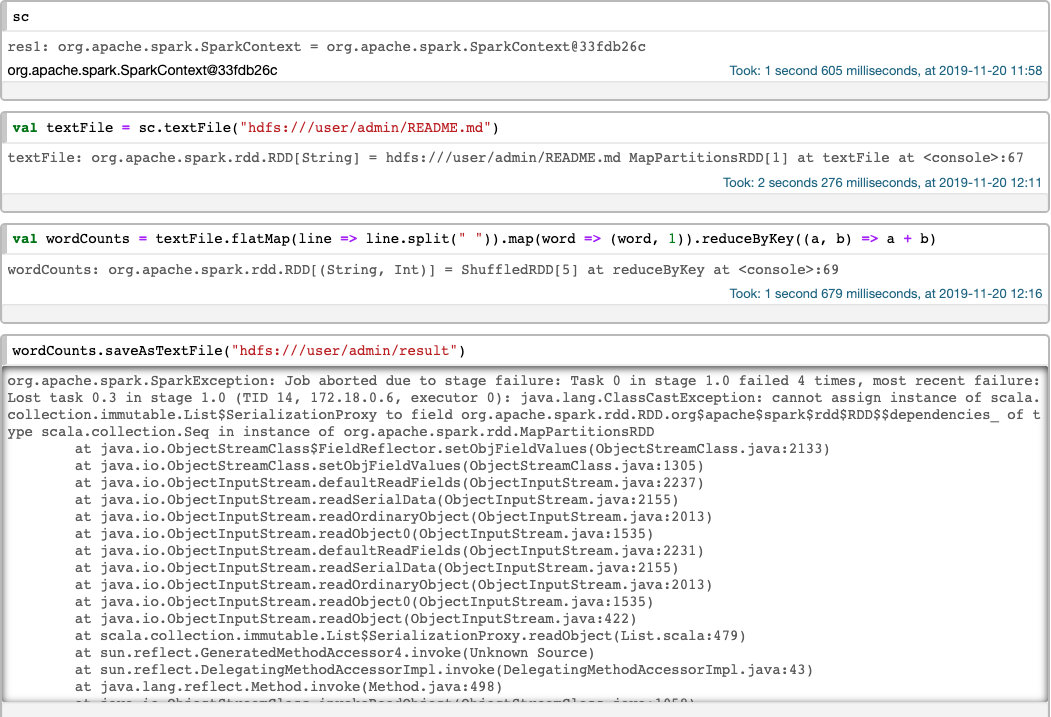
非常尴尬的事情发生了,最后一步报错了。
注意:这里失败了,说明这个项目应该是有点问题的,但不妨碍这个 DHSW 是个好工具,我会继续研究,想办法将这个问题修复。
Hive 支持
默认的启动方法是不包含 Hive 的,需要额外启动:
docker-compose -f docker-compose-hive.yml up -d namenode hive-metastore-postgresql
docker-compose -f docker-compose-hive.yml up -d datanode hive-metastore
docker-compose -f docker-compose-hive.yml up -d hive-server
docker-compose -f docker-compose-hive.yml up -d spark-master spark-worker spark-notebook hue
有了 Hive,Spark 可以做的事就更多了,但是由于上面的问题,这里就不进一步介绍了
5. 总结
总的来说,DHSW 有一个非常好的设想,通过容器技术快速的搭建一个 Spark 的实验环境,可以解决很多人的痛点,我将继续跟进并想办法完善这个项目。
欢迎交流讨论,吐槽建议,分享收藏。
勤学似春起之苗,不见其增,日有所长 辍学如磨刀之石,不见其损,日有所亏 关注【大数据学徒】,用技术干货助你日有所长
