

作者:小羊 编辑:韩数
大家好,我是韩数,本文的作者是我的好朋友小羊,本次呢,特地邀请小羊大神来撰写大数据系列的高级教程,随着大数据的发展,越来越多优秀的开源框架逐渐进入到我们开发者的生活中,包括hadoop,spark,flink等等,而Hadoop在大数据领域几乎无法撼动的地位,也成了每个大数据程序员的必修课,而MR(MapReduce),这一由google所提出的分布式计算模型,也是Hadoop的核心概念之一。本文呢,将从 MIT 6.824 课程 LEC 1 的内容出发,通过对 MapReduce 原论文的解读,以及课后作业代码的具体实现,来帮助大家去深入理解MapReduce模型,从而对分布式有一个深入的理解。
注:
6.824 是 MIT(斯坦福) 开设的分布式系统课程 ,其中第一节是 阅读论文并梳理 MR 模型的执行流程,实现单机版、分布式版的 word count,最后使用模型来生成倒排索引。
不说废话,上东西。
分布式的引入:
什么是分布式系统?
分布式系统就是有多台协同的计算机组成的系统,这些系统往往用于大型数据的存储,计算等传统单机模式下不能完成任务的场景。比如,云盘存储,spark,Hadoop等计算引擎。
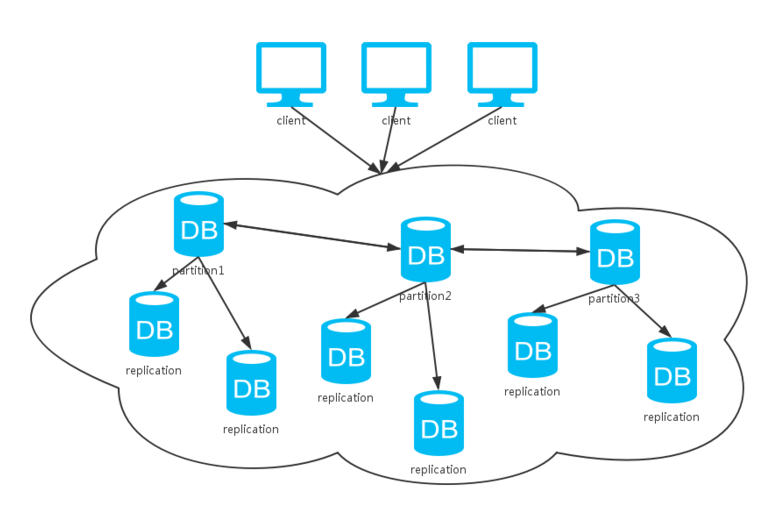
如图所示,分布式系统通常会有多个副本,多个分区,以此来保证数据和系统的可靠性。
如何实现分布式:
分布式的实现,依赖彼此之间的通信和协同,同时需要对数据的一致性,集群的可靠性等进行维护。
- 首先需要将物理独立的个体,通过通信模块,组织到一起工作。
- 需要多副本来实现数据和系统的可靠性,保证容错。
- 支持水平扩展来扩容,提高吞吐量。
分布式的优缺点:
- 优势:
- 并发执行任务快,理论上只受最慢的一个任务影响,理想状态下,
N台机器并发,耗时几乎可以变为T/N
- 并发执行任务快,理论上只受最慢的一个任务影响,理想状态下,
- 缺点:
- 复杂,并发部分难以实现
- 受到CAP原理的限制
- 需要处理局部失败的问题
MapReduce 论文 解读
什么是MapReduce
MapReduce 是一种编程模型,该模型主要分为两个过程,即 Map 和 Reduce。 MapReduce 的整体思想是: 将输入的数据分成 M 个 tasks, 由用户自定义的 Map 函数去执行任务,产出 <Key, Value>形式的中间数据,然后相同的 key 通过用户自定义的 Reduce 函数去聚合,得到最终的结果。 比如论文提及到的 词频统计, 倒排索引,分布式排序等,都可以通过MapReduce来实现。
如下图所示:
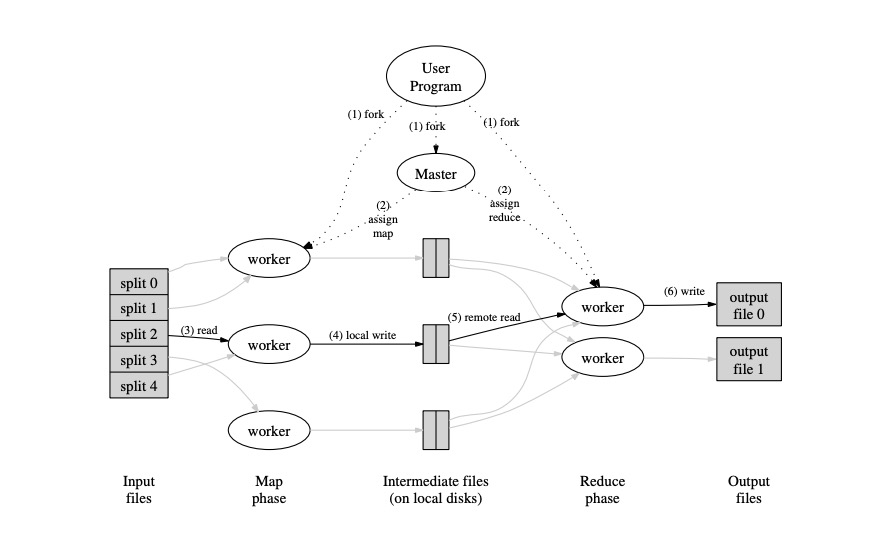
MapReduce 的实现
过程如下:
-
Map 端
- 根据输入输入信息,将输入数据 split 成 M 份, 比如上图中的 split0 - split4
(这里M=5) - 在所有可用的
worker节点中,起 M 个task任务的线程, 每个任务会读取对应一个 split 当做输入。 - 调用
map函数,将输入转化为<Key, Value>格式的中间数据,并且排序后,写入磁盘。 这里,每个task会写 R 个文件,对应着Reduce任务数。 数据写入哪个文件的规则有Partitioner决定,默认是hash(key) % R - (可选) 为了优化性能,中间还可以用一个
combiner的中间过程
- 根据输入输入信息,将输入数据 split 成 M 份, 比如上图中的 split0 - split4
-
Reduce 端
map阶段结束以后, 开始进入Reduce阶段,每个Reduce task会从所有的Map中间数据中,获取属于自己的一份数据,拿到所有数据后,一般会进行排序(Hadoop 框架是这样做)。
说明: 这个排序是非常必要的,主要因为
Reduce函数的输入 是<key, []values>的格式,因为需要根据key去排序。有同学想为啥不用map<>()去实现呢? 原因:因为map必须存到内存中,但是实际中数据量很大,往往需要溢写到磁盘。 但是排序是可以做到的,比如归并排序。 这也就是map端产出数据需要排序,Reduce端获取数据后也需要先排序的原因。- 调用
Reduce函数,得到最终的结果输出结果,存入对应的文件 - (可选) 汇总所有
Reduce任务的结果。一般不做汇总,因为通常一个任务的结果往往是另一个MapReduce任务的输入,因此没必要汇总到一个文件中。
Master 数据结构:
master 是 MapReduce 任务中最核心的角色,它需要维护 状态信息 和 文件信息。
-
状态信息:
map任务状态Reduce任务状态worker节点状态
-
文件信息
- 输入文件信息
- 输出文件信息
map中间数据文件信息
注:
由于
master节点进程是整个任务的枢纽,因此,它需要维护输入文件地址,map任务执行完后,会产出中间数据文件等待reducer去获取,因此map完成后, 会向master上报这些文件的位置和大小信息,这些信息随着Reduce任务的启动而分发下推到对应的worker。
容错
worker 节点失败
master会周期性向所有节点发送ping 心跳检测, 如果超时未回复,master会认为该worker已经故障。任何在该节点完成的map 或者Reduce任务都会被标记为idle, 并由其他的worker` 重新执行。
说明: 因为
MapReduce为了减少网络带宽的消耗,map的数据是存储在本地磁盘的,如果某个worker机器故障,会导致其他的Reduce任务拿不到对应的中间数据,所以需要重跑任务。那么这也可以看出,如果利用hadoop等分布式文件系统来存储中间数据,其实对于完成的map任务,是不需要重跑的,代价就是增加网络带宽。
Master 节点失败:
master节点失败,在没有实现HA 的情况下,可以说基本整个MapReduce任务就已经挂了,对于这种情况,直接重新启动master 重跑任务就ok了。 当然啦,如果集群有高可靠方案,比如master主副备用,就可以实现master的高可靠,代价就是得同步维护主副之间的状态信息和文件信息等。
失败处理的语义:
论文中提到,只要Map Reduce函数是确定的,语义上不管是分布式执行还是单机执行,结果都是一致的。每个map Reduce 任务输出是通过原子提交来保证的, 即:
一个任务要么有完整的最终文件,要么存在最终输出结果,要么不存在。
- 每个进行中的任务,在没有最终语义完成之前,都只写临时文件,每个
Reduce任务会写一个,而每个Map任务会写 R 个,对应 R 个reducer. - 当
Map任务完成的时候,会向master发送文件位置,大小等信息。Master如果接受到一个已经完成的Map任务的信息,就忽略掉,否则,会记录这个信息。 - 当
Reduce任务完成的时候,会将临时文件重命名为最终的输出文件, 如果多个相同的Reduce任务在多台机器执行完,会多次覆盖输出文件,这个由底层文件系统的rename操作的原子性,保证任何时刻,看到的都是一个完整的成功结果
对于大部分确定性的任务,不管是分布式还是串行执行,最终都会得到一致的结果。对于不确定的map 或者Reduce 任务,MapReduce 保证提供一个弱的,仍然合理的语义。
举个例子来说:
确定性任务比如 词频统计 不管你怎么执行,串行或者并行,最终得到的都是确定性的统计结果。
第二个不确定性任务: 随机传播算法,
pageRank等,因为会有概率因素在里面,也就是说你每次跑的结果数据不一定能对的上。但是是合理的,因为本来就有很多随机的因素在里面。
存储优化
由于网络带宽资源的昂贵性,因此对MapReduce 存储做了很多必要的优化。
- 通过从本地磁盘读取文件,节约网络带宽
- GFS 将文件分解成多个 大小通常为 64M 的
block, 并多备份存储在不同的机器上,在调度时,会考虑文件的位置信息,尽可能在存有输入文件的机器上调度map任务,避免网络IO。 - 任务失败时,也会尝试在离副本最近的worker中执行,比如同一子网下的机器。
- MapReduce 任务在大集群中执行时,大部分输入直接可以从磁盘中读取,不消耗带宽。
任务粒度
通常情况下,任务数即为 O(M + R), 这个数量应当比worker数量多得多,这样利于负载均衡和失败恢复的情况,但是也不能无限增长,因为太多任务的调度,会消耗master 存储任务信息的内存资源,如果启动task所花的时间比任务执行时间还多,那就不偿失了。
优化
自定义分区函数 (partition):
自定义分区可以更好地符合业务和进行负载均衡,防止数据倾斜。 默认只是简单的 hash(key) % R
有序保证:
每个`partition`内的数据都是排序的,这样有利于`Reduce`阶段的`merge`合并
Combiner 函数:
这个是每个map阶段完成之后,局部先做一次聚合。比如:词频统计,每个 Word 可能出现了100次,如果不使用combiner, 就会发送100 个 <word, 1>, 如果combiner聚合之后,则为 <word, 100>, 大大地减少了网络传输和磁盘的IO。
输入输出类型
一个reader没必要非要从文件读数据,MapReduce 支持可以从不同的数据源中以多种不同的方式读取数据,比如从数据库读取,用户只需要自定义split规则,就能轻易实现。
计数器
MapReduce 还添加了计数器,可以用来检测MapReduce的一些中间操作。
论文剩下的一些测试和实验数据,还请读者自行阅读原论文,在此不再赘述。
课后作业 实现
接下来是 课程作业 的实现.
前提工作
- 配置 go 环境,这是必要的,就像你学习java电脑上得先有个java一样。
- 从MIT 的git上下载课程实现的源码,
- 由于笔者在实现时,还用到了一个uuid的库, 因此,还需要安装这个库
# 配置go环境
export GOPATH=/path/to/your/gopath
export GOROOT=/path/to/your/goroot
# 下载MIT原始git的骨架代码,这里人家自定义实现好了很多东西,代码的注释将提醒你一步一步实现
git clone git://g.csail.mit.edu/6.824-golabs-2018 6.824
# 下载uuid, 可选
go get github.com/satori/go.uuid
熟悉代码
这里主要是熟悉课程提供的代码。 因为所有的执行都是从测试文件开始,所以我们先从 test_test.go 文件入手, 这里需要一些 go 语言的基础,比如同一个包下的所有函数都是可见的,所以有些函数找起来会比较慢,最好还是用IDE,比如 Goland。
- 首先,测试代码中提供了输入文件数量,
map函数和Reduce函数, 和Reduce任务数, 文件内容由makeInput函数生成
const (
nNumber = 100000
nMap = 20
nReduce = 10
)
-
Sequence 方式运行
MapReduce任务这个随便去一个
TestSequentialMany测试代码进行分析:- 先启动一个
master, 代码在master.go文件中
func Sequential(jobName string, files []string, nreduce int, mapF func(string, string[]KeyValue, reduceF func(string, []string) string, ) (mr *Master) { // 这里开启多线程去并发 run 函数 go mr.run(jobName string, files []string, nreduce int, schedule func(phase jobPhase), finish func()) } // 这里的 schedule 函数只是针对不同的phrase,执行对应的doMap任务或者是doReduce任务 func(phase jobPhase) { switch phase { case mapPhase: for i, f := range mr.files { doMap(mr.jobName, i, f, mr.nReduce, mapF) } case reducePhase: for i := 0; i < mr.nReduce; i++ { doReduce(mr.jobName, i, mergeName(mr.jobName, i), len(mr.files), reduceF) } } }doMap和doReduce函数分别在commom_map.go和common_reduce.go中, 需要我们在Part I 中实现- run函数 , 注意:merge函数解析文件是使用json去解析,所以最好doMap 和doReduce用json存中间数据。
func (mr *Master) run(jobName string, files []string, nreduce int, schedule func(phase jobPhase), finish func(), ) { ...... schedule(mapPhase) schedule(reducePhase) // 调度完map 和Reduce任务后,执行finish任务, finish() mr.merge() ...... mr.doneChannel <- true }- 发送完done以后, 在
TestSequentialMany中 mr.wait() 函数返回,最终做一些校验和清理的工作。
- 先启动一个
-
Distributed 方式运行
MapReduce任务分布式下与串行执行直接最大的区别就是需要和
worker通信完成调度。- 首先,通过
setup()函数创建Distributed master,master注册 rpc 服务, 然后执行go run 函数,和串行方式的区别在于,调度函数需要在schedule.go中实现。 任务执行结束后,关闭worker和rpc服务。
func Distributed(jobName string, files []string, nreduce int, master string) (mr *Master) { mr = newMaster(master) mr.startRPCServer() go mr.run(jobName, files, nreduce, func(phase jobPhase) { ch := make(chan string) go mr.forwardRegistrations(ch) schedule(mr.jobName, mr.files, mr.nReduce, phase, ch) }, func() { mr.stats = mr.killWorkers() mr.stopRPCServer() }) return }startRPCServer()函数: 收到shutdown消息以后,
func (mr *Master) startRPCServer() { go func() { loop: for { select { case <-mr.shutdown: break loop default: } conn, err := mr.l.Accept() if err == nil { go func() { // 这个是长链接,里面有个无限循环, rpcs.ServeConn(conn) conn.Close() }() } else { debug("RegistrationServer: accept error %s", err) break } } debug("RegistrationServer: done\n") }() }- 创建
worker: 注意nRPC参数,这代表了执行多少任务后关闭, 如果是-1, 则无穷。
func RunWorker(MasterAddress string, me string, MapFunc func(string, string) []KeyValue, ReduceFunc func(string, []string) string, nRPC int, parallelism *Parallelism, ) { ... // 注册rpc 服务 .... // 向服务器注册 worker信息 wk.register(MasterAddress) // DON'T MODIFY CODE BELOW for { wk.Lock() if wk.nRPC == 0 { wk.Unlock() break } wk.Unlock() // 每获得一个请求, 即 call ( "Worker.doTask" ), 就 nRPC -= 1 conn, err := wk.l.Accept() if err == nil { wk.Lock() wk.nRPC-- wk.Unlock() go rpcs.ServeConn(conn) } else { break } } }后续执行和
Sequence模式差不多的逻辑。 - 首先,通过
Assignment
Part I
这个部分的任务是完善 doMap 和 doReduce 函数,实现串行执行的 test。
- doMap 任务
根据MapReduce 过程的分析,对于map阶段,需要读取文件,然后调用用户的 mapF 函数, 得到结果后存到中间文件中。 具体的代码在对应得github中: common_map.go
func doMap(
jobName string, // the name of the MapReduce job
mapTask int, // which map task this is
inFile string,
nReduce int, // the number of reduce task that will be run ("R" in the paper)
mapF func(filename string, contents string) []KeyValue,
) {
// 首先读取文件获得数据
data, err := ioutil.ReadFile(inFile)
// 调用map函数获得键值对
kvs := mapF(inFile, string(data))
.......
// 拿到键值对以后,需要对不同的reduce 任务写中间结果到文件中
intermediateFiles := make([]*os.File, nReduce)
.......
for _, kv := range kvs {
encoder := json.NewEncoder(intermediateFiles[ihash(kv.Key) % nReduce])
err := encoder.Encode(&kv)
if err != nil {
log.Fatal("encode kv failed", kv)
}
}
}
-
doReduce 任务
根据分析,
Reduce阶段需要 从各个map中,获取自己的文件内容,然后得到<key, []values>格式的数据, 最终调用用户定义的reduceF函数, 并将结果以json方式,写到outFile中。 Github 代码地址: common_reduce.gofunc doReduce( jobName string, // the name of the whole MapReduce job reduceTask int, // which reduce task this is outFile string, // write the output here nMap int, // the number of map tasks that were run ("M" in the paper) reduceF func(key string, values []string) string, ) { keyValues := make(map[string][]string) // 从多个map中读取文件 for mapTask := 0; mapTask < nMap; mapTask++ { fileName := reduceName(jobName, mapTask, reduceTask) file, err := os.Open(fileName) ...... decoder := json.NewDecoder(file) for decoder.More() { var kv KeyValue err := decoder.Decode(&kv) ....... keyValues[kv.Key] = append(keyValues[kv.Key], kv.Value) } file.Close() } // 对所有的key排序 var keys []string for k := range keyValues { keys = append(keys, k) } sort.Strings(keys) out, err := os.Create(tmpFile) ...... // 调用Reduce函数并存入文件中 encoder := json.NewEncoder(out) for _, key := range keys { result := reduceF(key, keyValues[key]) err = encoder.Encode(KeyValue{key, result}) ...... } } -
测试
cd ../mit6.824/mapreduce
go test -run Sequential
# 最终会输出pass,表示任务通过
Part 2
这里要求自己实现一个map 和Reduce函数,实现wordcount。 这个较为简单,直接看代码,github 地址为: wc.go
func mapF_wc(filename string, contents string) []mapreduce.KeyValue {
// Your code here (Part II).
worldList := strings.FieldsFunc(contents, func(c rune) bool {
return !unicode.IsLetter(c)
})
resMap := make(map[string]int)
for _, word := range worldList {
resMap[word] ++;
}
var res []mapreduce.KeyValue
for k, v := range resMap {
res = append(res, mapreduce.KeyValue{Key: k, Value: strconv.Itoa(v)})
}
return res
}
func reduceF_wc(key string, values []string) string {
// Your code here (Part II).
sum := 0
for _, value := range values {
_num, err := strconv.Atoi(value)
if err != nil {
log.Fatal(err)
continue
}
sum += _num
}
return strconv.Itoa(sum)
}
- 测试
cd /path/to/main/
go run wc.go master sequential pg-*.txt
sort -n -k2 mrtmp.wcseq | tail -10
# 对比以下的结果
that: 7871
it: 7987
in: 8415
was: 8578
a: 13382
of: 13536
I: 14296
to: 16079
and: 23612
the: 29748
## 或者 sh test-wc.sh
Part 3 4
这个部分是重点,要实现一个分布式的调度函数 schedule, 代码在 schedule.go 中。 主要是有几个注意的点:
-
master需要知道并记录任务状态,只有所有的map任务完成才会执行Reduce任务, 只有所有Reduce任务完成,才会合并最终结果并最终输出。 -
master需要知道当前可用worker的地址Addr, 才能调用rpc服务,且我们知道,在worker启动时,会向master注册,并在go mr.run()方法的时候,调用了go mr.forwardRegistrations(ch)将目前注册的worker发送到registerChan中,供schedule使用。 -
part 4 任务中,需要处理worker故障的情况,这个比任务失败要简单得多,因为实验只是在任务完成之后,节点故障,在worker上任务还是完成了的,只是master schedule的时候 call 函数 rpc 调用超时,所以任务只需要重新执行就好。
明确了问题所在之后,那么就可以看以下代码。 具体代码请看 schedule.go
// 这里需要用同步模块,用来监控任务的完成状态,只有成功执行才会进行Done操作减一 var wg sync.WaitGroup wg.Add(ntasks) // 这里建立一个带缓冲的任务通道,以减少阻塞的可能性,之所以不是for循环,是因为worker故障后,会出现失败任务,这些任务应该要重新运行而不是丢弃 taskChan := make(chan int, 3) go func() { for i := 0; i < ntasks; i++ { taskChan <- i } }() go func() { for { // 注意,这里从通道中取,如果任务成功,这里就表明worker正常,要把worker重新发到管道,否则会一直阻塞 availableWorker := <-registerChan task := <-taskChan doTaskArgs := DoTaskArgs{JobName: jobName, File: mapFiles[task], Phase: phase, TaskNumber: task, NumOtherPhase: n_other, } go func() { if call(availableWorker, "Worker.DoTask", doTaskArgs, new(struct{})) { // 任务成功 wg.Done() // 任务结束后,availableWorker 闲置,availableWorker 进入 registerChan 等待下一次分配任务 registerChan <- availableWorker } else { // 任务失败, 重新提交回任务, 等待下一次调度分配 taskChan <- doTaskArgs.TaskNumber } }() } }() wg.Wait()
- 测试
# 测试 part 3 并行调度
go test -run TestParallel
# 测试 part 4 失败处理
go test -run Failure
Part 5
这部分的要求是实现一个 倒排索引,即简单的理解是:找出一个单词出现过的所有文档! 其实主要就是自己自定义一个mapF 和 ReduceF 的要求,一个优化就是在map端 使用 set 来去重,减少中间文件的数据量。具体的代码在 main/ii.go . 代码比较简单,还请读者自行访问 github。
总结:
我相信看到这里的朋友想必已经对MapReduce有一个比大多数人都更加深入的理解了,本篇文章呢,虽然没有将重点主要集中在Hadoop这些开源大数据框架的使用上(这个系列的教程主要是韩数来做),但是这些理论性的文章却是整个Hadoop在实现自己的MapReduce重要参考,和java规范一样,如果了解了MapReduce的设计思想和实现思路,我相信,今后不管是Hadoop也好或者新的大数据开源技术也好,只要涉及到了MapReduce这块内容,那么他们所体现出来的实现思路也一定是大同小异的,这同时也是高级篇系列笔记所编写的初衷,不涉及具体框架的使用,而专注在这些技术的源头。
韩数OS:未来我会多督促小羊大神争取把文章写的通俗易懂的,马上安排上。
最后,本篇文章相关代码实现已经开源至小羊Github,一定要star哦。
万水千山总是情,给个Star行不行!
参考
[2] www.jianshu.com
