

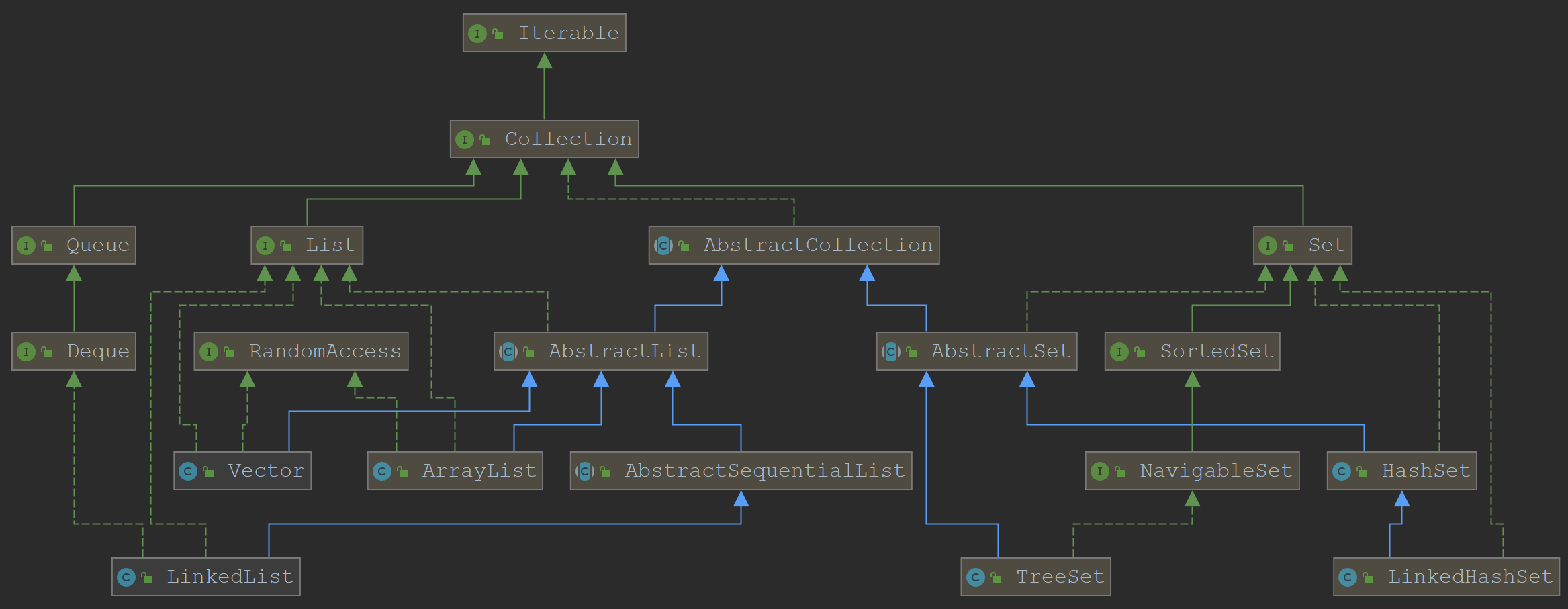
1. 概述
LinkedList是底层通过双向链表实现的集合类,其实现了List接口和Dqueue接口,所以支持列表和队列的操作方式
同时,LinkedList也是线程不安全的
2. 成员变量
/**
* LinkedList的长度
*/
transient int size = 0;
/**
* 链表中的第一个节点
*/
transient Node<E> first;
/**
* 链表中的最后一个节点
*/
transient Node<E> last;
可以看到LinkedList的成员变量很少,都很简单
Node是LinkedList的静态内部类,一个Node对象是链表上的一个节点
关于
Node内部类的详细分析,放在下文
以上三个成员变量都有transient关键字修饰,至于为什么要使用这个关键字修饰,我想不懂
3. 构造函数
public LinkedList() {
}
public LinkedList(Collection<? extends E> c) {
// 调用无参构造函数
this();
// 调用addAll方法将Collection中所有元素添加到LinkedList
addAll(c);
}
构造方法也是很简单,只有两个,自己look look
4. List接口的实现
java.util.LinkedList#add(E)
public boolean add(E e) {
// 添加节点到链表的末尾
linkLast(e);
return true;
}
void linkLast(E e) {
final Node<E> l = last;
// 构建节点
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
/*
最后一个节点为null
表示链表中没有节点
此时需要更新first指向newNode
*/
first = newNode;
else
// 在链表的尾部添加newNode
l.next = newNode;
// 链表长度+1
size++;
// 修改次数+1
modCount++;
}
方法还是很简单的,自己look look 就可以了
LinkedList跟ArrayList都会通过继承自AbstractList中的modCount记录对象的修改次数,用于线程不安全的集合类实现快速失败
java.util.LinkedList#add(int, E)
public void add(int index, E element) {
// 检查index是否越界
checkPositionIndex(index);
if (index == size)
// index = size表示元素添加在链表末尾
linkLast(element);
else
// 元素添加在链表中的某一处
linkBefore(element, node(index));
}
private void checkPositionIndex(int index) {
if (!isPositionIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
/**
* 检查指定的index对于迭代和添加操作是否为有效的位置
*/
private boolean isPositionIndex(int index) {
// [1]
return index >= 0 && index <= size;
}
/**
* 把方法的访问级别设置为默认,可以让内部类调用
*
* Returns the (non-null) Node at the specified element index.
*/
Node<E> node(int index) {
// assert isElementIndex(index);
if (index < (size >> 1)) {
// index的位置处于链表的前半段
Node<E> x = first;
for (int i = 0; i < index; i++)
// 通过first节点,正向遍历,获取index位置对应的节点
x = x.next;
return x;
} else {
// index的位置处于链表的后半段
Node<E> x = last;
for (int i = size - 1; i > index; i--)
// 通过last节点,逆向遍历,获取index位置对应的节点
x = x.prev;
return x;
}
}
void linkBefore(E e, Node<E> succ) {
// assert succ != null;
final Node<E> pred = succ.prev;
// 构建节点
final Node<E> newNode = new Node<>(pred, e, succ);
succ.prev = newNode;
if (pred == null)
// succ的前一个节点为null,表示该节点为头节点
// 所以需要更新first引用指向的节点
first = newNode;
else
pred.next = newNode;
// 链表长度+1
size++;
// 修改次数+1
modCount++;
}
[1]处:注意方法isPositionIndex仅适用添加操作和迭代时对index的检查
node方法写得有点妙,通过判断index跟size/2大小比较,决定寻找index对应的节点时,应该从first节点往后遍历,还是应该从last节点往前遍历,确实不错
尽管如此,还是可以看到,LinkedList根据index索引下标获取链表中的节点时无法避免要对链表的遍历,比起ArrayList可以直接根据索引下标获取元素,还是要稍逊一筹
linkBefore方法的作用是实现在指定节点succ前面插入新的节点,通过源码实现可以看到,LinkedList要插入一个节点,只需要变动新节点和前后两个节点的prev和next引用指向的对象,不需要像ArrayList那样,每次插入都需要通过java.lang.System#arraycopy方法移动后续的数组
java.util.LinkedList#addAll(java.util.Collection<? extends E>)
public boolean addAll(Collection<? extends E> c) {
// 在当前链表后拼接Collection的元素
// 指定添加元素的起始位置index = size
return addAll(size, c);
}
这里没什么好看的,主要就是调用了重载的addAll方法
java.util.LinkedList#addAll(int, java.util.Collection<? extends E>)
public boolean addAll(int index, Collection<? extends E> c) {
// 检查index有没有越界
checkPositionIndex(index);
Object[] a = c.toArray();
int numNew = a.length;
if (numNew == 0)
return false;
Node<E> pred, succ;
if (index == size) {
/*
如果index位置为链表中的最后一个节点的下一个位置
pred引用指向最后一个last节点
*/
succ = null;
pred = last;
} else {
/*
如果index的位置为链表中的任意一个节点的位置
则根据index获取链表中对应的节点succ
pred引用指向succ的前一个节点
*/
succ = node(index);
pred = succ.prev;
}
for (Object o : a) {
// 遍历数组,构建链表节点
@SuppressWarnings("unchecked") E e = (E) o;
Node<E> newNode = new Node<>(pred, e, null);
if (pred == null)
// pred = null,表示newNode为头节点
// 需要更新first指向的节点
first = newNode;
else
// 指定pred的下一个节点为newNode
pred.next = newNode;
// 将pred指向newNode
// 通过循环,将数组所有的元素构建成节点,加入链表中
pred = newNode;
}
if (succ == null) {
// 更新last节点
last = pred;
} else {
// 此时pred指向已经加入到链表中的数组元素的最后一个节点
// 将pred节点和succ节点连接起来
pred.next = succ;
succ.prev = pred;
}
// 更新size
size += numNew;
// 修改次数加1
modCount++;
return true;
}
代码稍微长了一点,但是不复杂,主要就是添加了对头节点、尾节点的判断操作,自己look look
java.util.LinkedList#clear
public void clear() {
// Clearing all of the links between nodes is "unnecessary", but:
// - helps a generational GC if the discarded nodes inhabit
// more than one generation
// - is sure to free memory even if there is a reachable Iterator
for (Node<E> x = first; x != null; ) {
// 遍历链表
Node<E> next = x.next;
// [1]释放x引用指向节点的item、next、prev节点
x.item = null;
x.next = null;
x.prev = null;
x = next;
}
// 重置first、last引用
first = last = null;
// 重置链表长度
size = 0;
// 修改次数+1
modCount++;
}
public int indexOf(Object o) {
int index = 0;
if (o == null) {
for (Node<E> x = first; x != null; x = x.next) {
// [2]正向遍历链表,寻找第一个节点的item为null的位置
if (x.item == null)
return index;
index++;
}
} else {
for (Node<E> x = first; x != null; x = x.next) {
// 正向遍历链表,寻找第一个节点的item等于o的位置
if (o.equals(x.item))
return index;
index++;
}
}
return -1;
}
[1]处,将节点中的item 、prev 、next引用设置为空,有助于在程序触发下一次GC的时候,可以回收这些引用原本指向的对象占用的空间
好习惯,可以学学
[2]处,从源码可以看到LinkedList是支持查找null的,这表示LinkedList也是支持存储null的
java.util.LinkedList#get
public E get(int index) {
// 检查index的越界问题
checkElementIndex(index);
// 获取index位置的node.item
return node(index).item;
}
private void checkElementIndex(int index) {
if (!isElementIndex(index))
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
private boolean isElementIndex(int index) {
return index >= 0 && index < size;
}
很简单,自己look look
java.util.LinkedList#remove(int)
public E remove(int index) {
// 检查index的边界
checkElementIndex(index);
// 根据index获取对应的节点
// 从链表中移除该节点
return unlink(node(index));
}
E unlink(Node<E> x) {
// assert x != null;
final E element = x.item;
final Node<E> next = x.next;
final Node<E> prev = x.prev;
if (prev == null) {
// 要移除的节点x是头节点
first = next;
} else {
prev.next = next;
x.prev = null;
}
if (next == null) {
// 要移除的节点x是尾节点
last = prev;
} else {
next.prev = prev;
x.next = null;
}
x.item = null;
size--;
modCount++;
return element;
}
移除节点的操作主要是对unlink方法的调用,在移除节点的时候,需要考虑到被移除的节点是头节点或尾节点的 操作
LinkedList对于List接口的实现比较常用的方法大概就是上面这些了 至于那些size之类很简单的方法就不放在这里了 源码阅读起来的难度不大,多看几次,看得懂的
5. Dqueue接口实现
java.util.LinkedList#addFirst
public void addFirst(E e) {
// 将元素添加到头节点
linkFirst(e);
}
private void linkFirst(E e) {
final Node<E> f = first;
final Node<E> newNode = new Node<>(null, e, f);
first = newNode;
if (f == null)
// 链表的头节点为null,表示链表为空
// 需要更新last的引用
last = newNode;
else
f.prev = newNode;
size++;
modCount++;
}
addFirst方法的核心调用是linkFirst方法,在添加元素到链表头部的时候,注意需要对链表为空的情况做处理
java.util.LinkedList#addLast
public void addLast(E e) {
linkLast(e);
}
void linkLast(E e) {
final Node<E> l = last;
// 构建节点
final Node<E> newNode = new Node<>(l, e, null);
last = newNode;
if (l == null)
/*
最后一个节点为null
表示链表中没有节点
此时需要更新first指向newNode
*/
first = newNode;
else
// 在链表的尾部添加newNode
l.next = newNode;
// 链表长度+1
size++;
// 修改次数+1
modCount++;
}
addLast的核心调用是linkLast,linkLast方法跟linkFirst方法一样,也需要注意对空链表的处理
java.util.LinkedList#offer
public boolean offer(E e) {
// 在链表尾部添加元素
return add(e);
}
该接口的实现是基于对List接口实现的调用
还有其他的一些offerFirst,offerLast方法实际上也是简单地调用现有的方法实现,很简单,可以自己去look look
java.util.LinkedList#peek
public E peek() {
// 获取链表的头节点元素
final Node<E> f = first;
return (f == null) ? null : f.item;
}
很简单,自己look look
java.util.LinkedList#poll
public E poll() {
// 移除链表的头节点
final Node<E> f = first;
return (f == null) ? null : unlinkFirst(f);
}
很简单,自己look look
LinkedList关于Dqueue接口的实现,在实现的内部,都是基于现有的方法调用,比较简单
6. 内部类
java.util.LinkedList.Node
private static class Node<E> {
/**
* 当前节点存储的元素
*/
E item;
/**
* 指向下一个节点的引用
*/
Node<E> next;
/**
* 指向上一个节点的引用
*/
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
Node是一个静态的内部类
类成员只有三个:节点存储的元素、上一个节点的引用、下一个节点的引用
只有一个全参的构造函数
java.util.LinkedList.ListItr
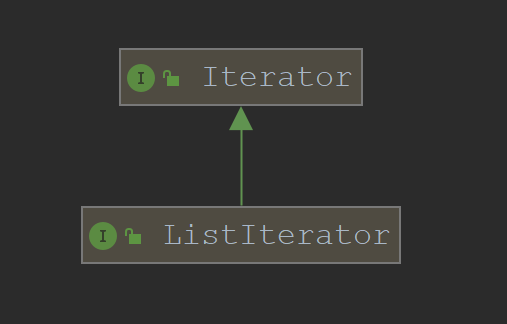
在LinkedList中也有一个迭代的内部类ListItr,这个内部类实现的接口不是Iterator,而是其子类ListIterator
ListIterator是一个列表迭代器,允许通过任意方向遍历列表(向前遍历、向后遍历),同时在迭代期间支持修改列表以及获取当前遍历的元素处于列表的位置

可以看到,Iterator定义的接口就只有4个,比较常用的就是next、hasNext以及remove方法
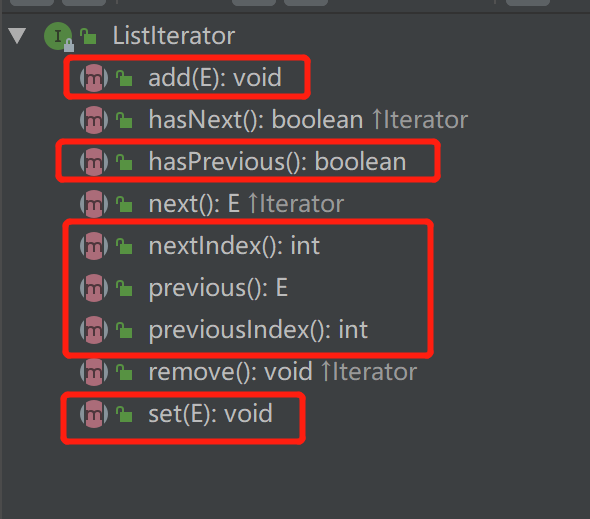
再来看看ListIterator接口,除了包含Iterator接口之外,还多出了几个方法:
add:向列表添加元素hasPrevious:是否有前一个元素nextIndex:下一个元素的位置previous:获取前一个元素previousIndex:前一个元素的位置set:设置某个元素的值
接下来看一下具体的方法实现
先来看看内部类的成员变量
/**
* 最近返回的节点
*/
private Node<E> lastReturned;
/**
* 下一个节点
*/
private Node<E> next;
/**
* 下一个节点对应的索引位置
*/
private int nextIndex;
/**
* 链表的期望修改次数
*/
private int expectedModCount = modCount;
很简单,再来看看构造函数
ListItr(int index) {
// assert isPositionIndex(index);
// [1]
next = (index == size) ? null : node(index);
nextIndex = index;
}
[1]处,可以看到在构造列表迭代器的时候 ,允许指定index为size,为什么要这样做呢?
我想应该是迭代器的游标可以遍历到最后一个元素的后一位,并且把这个作为遍历的终止条件
接下来看看Iterator接口的常用方法的实现
public boolean hasNext() {
return nextIndex < size;
}
public E next() {
// 检查modCount
checkForComodification();
if (!hasNext())
// 没有下一个节点,抛出异常
throw new NoSuchElementException();
lastReturned = next;
// next指向下一个节点
next = next.next;
nextIndex++;
return lastReturned.item;
}
final void checkForComodification() {
// 比较当前链表的修改次数和迭代器期望的修改次数
if (modCount != expectedModCount)
throw new ConcurrentModificationException();
}
public void remove() {
checkForComodification();
if (lastReturned == null)
// [1]没有调用过next或previous方法,lastReturned就会为null
throw new IllegalStateException();
// 移除lastReturned节点
Node<E> lastNext = lastReturned.next;
// 调用LinkedList的unlink方法
unlink(lastReturned);
if (next == lastReturned)
// 调用过previous方法才会使得next == lastReturned
next = lastNext;
else
// 调用过next方法,移除lastReturned后,下一个节点next的索引nextIndex要减一
nextIndex--;
lastReturned = null;
expectedModCount++;
}
[1]处可以看到,如果直接构造列表迭代器,再未使用过next方法或者previous方法之前,直接使用remove方法,会抛出异常
再来看看ListIterator接口的方法的实现
public void add(E e) {
checkForComodification();
lastReturned = null;
if (next == null)
linkLast(e);
else
linkBefore(e, next);
nextIndex++;
expectedModCount++;
}
public boolean hasPrevious() {
// nextIndex == 0,表示当前游标在第一个节点之前
return nextIndex > 0;
}
public int nextIndex() {
return nextIndex;
}
public E previous() {
// 检查modCount
checkForComodification();
if (!hasPrevious())
// 没有上一个节点,抛出异常
throw new NoSuchElementException();
// 迭代器最后一次调用next方法的时候会返回null
// 如果next为null,那么next的前一个节点为链表的最后一个节点last
lastReturned = next = (next == null) ? last : next.prev;
nextIndex--;
return lastReturned.item;
}
public int previousIndex() {
return nextIndex - 1;
}
public void set(E e) {
if (lastReturned == null)
throw new IllegalStateException();
checkForComodification();
lastReturned.item = e;
}
其中比较复杂的代码可能就是previous方法,多看几次,画个图,看看注释,可以理解的
在
ArrayList中同样也有关于ListIterator实现的内部类,基本思路不变,只是一个迭代数组,一个迭代链表而已,有兴趣自己look look
java.util.LinkedList.DescendingIterator
这个类我感觉是有点奇葩的,主要作用是:通过java.util.LinkedList.ListItr#previous方法,提供降序迭代的适配器
方法的实现全部都是基于ListItr方法的调用
private class DescendingIterator implements Iterator<E> {
private final ListItr itr = new ListItr(size());
public boolean hasNext() {
return itr.hasPrevious();
}
public E next() {
return itr.previous();
}
public void remove() {
itr.remove();
}
}
