如果在大型高并发系统需要数据的分布式存储 希望数据均匀分布可扩展性强那么一致性hash算法就可以完美解决这个问题 一致性hash算法的应用再很多领域 缓存 hadoop ES 分布式数据库
一致性Hash算法原理
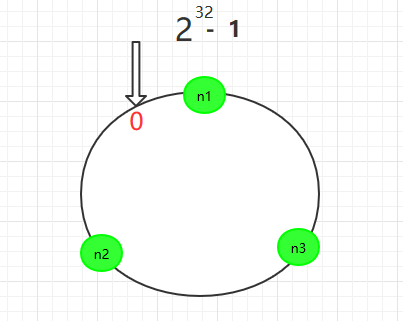
一致性Hash算法是使用取模的方法,一致性的Hash算法是对2的32方取模。即,一致性Hash算法将整个Hash空间组织成一个虚拟的圆环,Hash函数的值空间为0 ~ 2^32 - 1(一个32位无符号整型),整个哈希环如下: hash值是个整数 非负,对集群的某个属性比如节点名取hash值放到环上,对数据key取hash值也放到环上,按照顺时针方向找到离它最近的节点放到它上面, 整个圆环以顺时针方向组织,圆环0点右侧的第一个点代表n1服务器,以此类推。 我们将各个服务器使用Hash进行一个哈希,具体可以选择服务器的IP或主机名作为关键字进行哈希,这样每台服务器就确定在了哈希环的一个位置上,比如我们有三台机器,使用IP地址哈希后在环空间的位置如图所示:
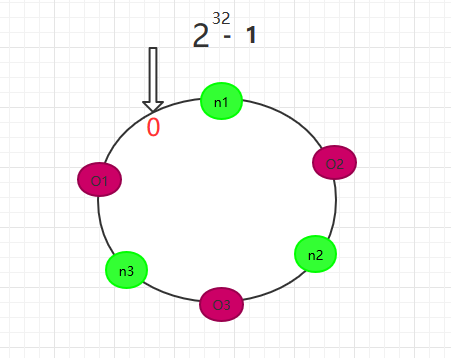
将数据Key使用相同的函数Hash计算出哈希值,并确定此数据在环上的位置,从此位置沿环顺时针查找,遇到的服务器就是其应该定位到的服务器。
如下图三个数据O1,O2,O3经过哈希计算后,在环空间上的位置如下: O1-->n1 O2-->n2 O3-->n3
一致性Hash算法的容错性和可扩展性
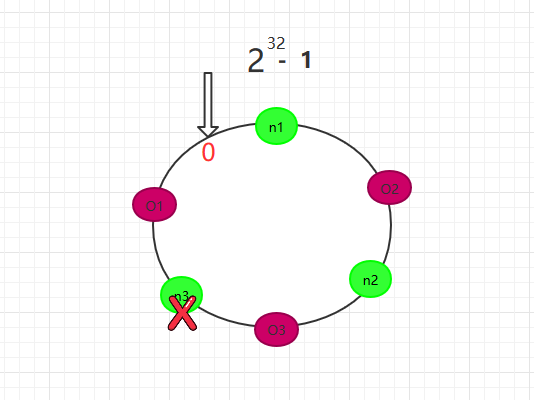
现在,假设我们的n3宕机了,我们从图中可以看到,n1、n2不会受到影响,只有O3对象被重新定位到n1。所以我们发现,在一致性Hash算法中,如果一台服务器不可用,受影响的数据仅仅是此服务器到其环空间前一台服务器之间的数据其他不会受到影响。如图 所示:
现在我们系统增加了一台服务器n4,如图 所示
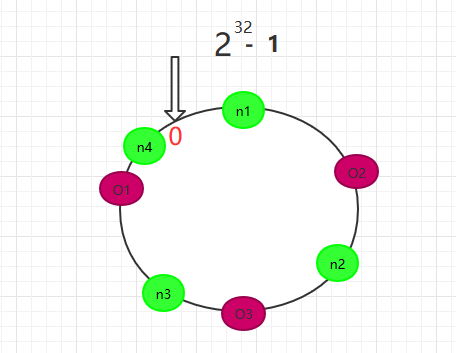
一致性Hash算法对于节点的增减都只需重定位环空间中的一小部分数据,有很好的容错性和可扩展性。 在一致性Hash算法服务节点太少的情况下,容易因为节点分布不均匀面造成数据倾斜(被缓存的对象大部分缓存在某一台服务器上)问题,如图 :
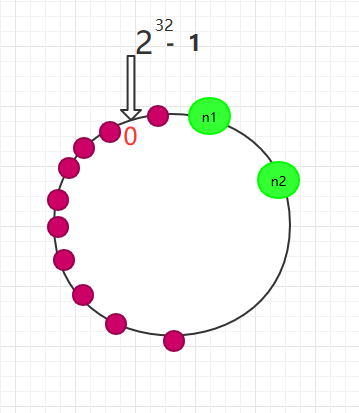
这时我们发现有大量数据集中在节点A上,而节点B只有少量数据。为了解决数据倾斜问题,一致性Hash算法引入了虚拟节点机制,即对每一个服务器节点计算多个哈希,每个计算结果位置都放置一个此服务节点,称为虚拟节点。 具体操作可以为服务器IP或主机名后加入编号来实现,实现如图 所示: 比如一个n1节点我们虚拟100个虚拟节点,在环上的便是虚拟节点,同理n2,n3也有100个虚拟节点,
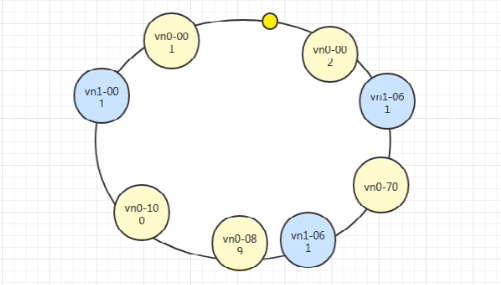
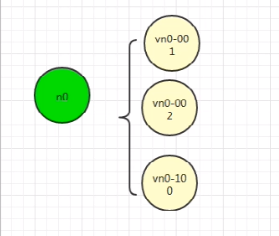
当数据过来以后如何判断放置到哪一个服务器呢
当数据过来入环以后先找到对应的虚拟节点,再通过虚拟节点找到对应的服务器,这样通过增加虚拟节点就可以做到数据的均匀分布,虚拟节点越多数据越均匀,一般我们一个服务器放置200个虚拟节点即可
数据定位算法不变,只需要增加一步:虚拟节点到实际点的映射。 所以加入虚拟节点之后,即使在服务节点很少的情况下,也能做到数据的均匀分布。 上面几种情况都是数据理想的情况下均匀分布的,其实一致性Hash算法存在一个数据倾斜问题
算法接口类
public interface IHashService {
Long hash(String key);
}
算法接口实现类
public class HashService implements IHashService {
/**
* MurMurHash算法,性能高,碰撞率低
*
* @param key String
* @return Long
*/
public Long hash(String key) {
ByteBuffer buf = ByteBuffer.wrap(key.getBytes());
int seed = 0x1234ABCD;
ByteOrder byteOrder = buf.order();
buf.order(ByteOrder.LITTLE_ENDIAN);
long m = 0xc6a4a7935bd1e995L;
int r = 47;
long h = seed ^ (buf.remaining() * m);
long k;
while (buf.remaining() >= 8) {
k = buf.getLong();
k *= m;
k ^= k >>> r;
k *= m;
h ^= k;
h *= m;
}
if (buf.remaining() > 0) {
ByteBuffer finish = ByteBuffer.allocate(8).order(ByteOrder.LITTLE_ENDIAN);
finish.put(buf).rewind();
h ^= finish.getLong();
h *= m;
}
h ^= h >>> r;
h *= m;
h ^= h >>> r;
buf.order(byteOrder);
return h;
}
}
模拟机器节点
public class Node<T> {
private String ip;
private String name;
public Node(String ip, String name) {
this.ip = ip;
this.name = name;
}
public String getIp() {
return ip;
}
public void setIp(String ip) {
this.ip = ip;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
/**
* 使用IP当做hash的Key
*
* @return String
*/
@Override
public String toString() {
return ip;
}
}
一致性Hash操作
public class ConsistentHash<T> {
// Hash函数接口
private final IHashService iHashService;
// 每个机器节点关联的虚拟节点数量
private final int numberOfReplicas;
// 环形虚拟节点
private final SortedMap<Long, T> circle = new TreeMap<Long, T>();
public ConsistentHash(IHashService iHashService, int numberOfReplicas, Collection<T> nodes) {
this.iHashService = iHashService;
this.numberOfReplicas = numberOfReplicas;
for (T node : nodes) {
add(node);
}
}
/**
* 增加真实机器节点
*
* @param node T
*/
public void add(T node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
circle.put(this.iHashService.hash(node.toString() + i), node);
}
}
/**
* 删除真实机器节点
*
* @param node T
*/
public void remove(T node) {
for (int i = 0; i < this.numberOfReplicas; i++) {
circle.remove(this.iHashService.hash(node.toString() + i));
}
}
public T get(String key) {
if (circle.isEmpty()) return null;
long hash = iHashService.hash(key);
// 沿环的顺时针找到一个虚拟节点
if (!circle.containsKey(hash)) {
SortedMap<Long, T> tailMap = circle.tailMap(hash);
hash = tailMap.isEmpty() ? circle.firstKey() : tailMap.firstKey();
}
return circle.get(hash);
}
}
测试类
public class TestHashCircle {
// 机器节点IP前缀
private static final String IP_PREFIX = "192.168.0.";
public static void main(String[] args) {
// 每台真实机器节点上保存的记录条数
Map<String, Integer> map = new HashMap<String, Integer>();
// 真实机器节点, 模拟10台
List<Node<String>> nodes = new ArrayList<Node<String>>();
for (int i = 1; i <= 10; i++) {
map.put(IP_PREFIX + i, 0); // 初始化记录
Node<String> node = new Node<String>(IP_PREFIX + i, "node" + i);
nodes.add(node);
}
IHashService iHashService = new HashService();
// 每台真实机器引入100个虚拟节点
ConsistentHash<Node<String>> consistentHash = new ConsistentHash<Node<String>>(iHashService, 500, nodes);
// 将5000条记录尽可能均匀的存储到10台机器节点上
for (int i = 0; i < 5000; i++) {
// 产生随机一个字符串当做一条记录,可以是其它更复杂的业务对象,比如随机字符串相当于对象的业务唯一标识
String data = UUID.randomUUID().toString() + i;
// 通过记录找到真实机器节点
Node<String> node = consistentHash.get(data);
// 再这里可以能过其它工具将记录存储真实机器节点上,比如MemoryCache等
// ...
// 每台真实机器节点上保存的记录条数加1
map.put(node.getIp(), map.get(node.getIp()) + 1);
}
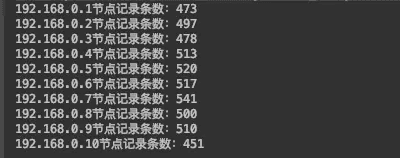
// 打印每台真实机器节点保存的记录条数
for (int i = 1; i <= 10; i++) {
System.out.println(IP_PREFIX + i + "节点记录条数:" + map.get(IP_PREFIX + i));
}
}
}
运行结果如下: