

前端应用能否实现音视频聊天?
答案是:能!
借助WebRTC不仅能做到音视频聊天,还能实现点对点文件传输。
WebRTC是什么?
WebRTC(Web Real-Time Communication)是一项实时通讯技术,它允许网络应用或者站点,在不借助中间媒介的情况下,建立浏览器之间点对点(Peer-to-Peer)的连接,实现视频流音频流或者其他任意数据的传输。
WebRTC包含的这些标准使用户在无需安装任何插件或者第三方的软件的情况下,创建点对点(Peer-to-Peer)的数据分享和视频会议成为可能。
WebRTC的前世今生
1990年,
Gobal IP Solutions成立于瑞典斯德哥尔摩(以下简称GIPS),这是一家VoIP软件开发商,提供了可以说是世界上最好的语音引擎。 Skype、腾讯 QQ、WebEx、Vidyo 等都使用了它的音频处理引擎,包含了受专利保护的回声消除算法,适应网络抖动和丢包的低延迟算法,以及先进的音频编解码器。Google 在 Gtalk 中也使用了 GIPS 的授权。
2010年5月,Google以6820万美元收购了
GIPS,并将其源代码开源。加上在 2010 年收购的On2获取到的VPx系列视频编解码器,WebRTC开源项目应运而生,即GIPS音视频引擎 + 替换掉H.264的VPx。 随后,Google 又将在Gtalk中用于P2P打洞的开源项目libjingle融合进了WebRTC。
2012年1月,谷经把
WebRTC集成到了Chrome浏览器中。
所以目前 WebRTC 提供了在 Web、iOS、Android、Mac、Windows、Linux 在内的所有平台的 API,保证了 API 在全平台的一致性。
使用 WebRTC 的好处主要有以下几个方面
- 免费使用
GIPS先进的音视频引擎,在此之前都需要付费授权(当然,WebRTC由于开源,所以相较于GIPS阉割了一部分内容,导致性能没有GIPS那么优异)。 - 由于音视频传输是基于点对点传输的,所以实现简单的 1 对 1 通话场景,只需要较少的服务器资源,借助免费的
STUN/TURN服务器可以大大节约成本开销。 - 开发 Web 版本的应用非常方便,使用简单的 JS 接口,无需安装任何插件,即可实现音视频互通。
当前浏览器支持情况
- 桌面PC端
- Microsoft Edge
- Google Chrome 23
- Mozilla Firefox 22
- Opera 18
- Safari 11
- Android端
- Google Chrome 28(从版本29开始默认开启)
- Mozilla Firefox 24
- Opera Mobile 12
- Google Chrome OS
- Firefox OS
- iOS 11
- Blackberry 10内置浏览器
附一张浏览器版本支持图如下:
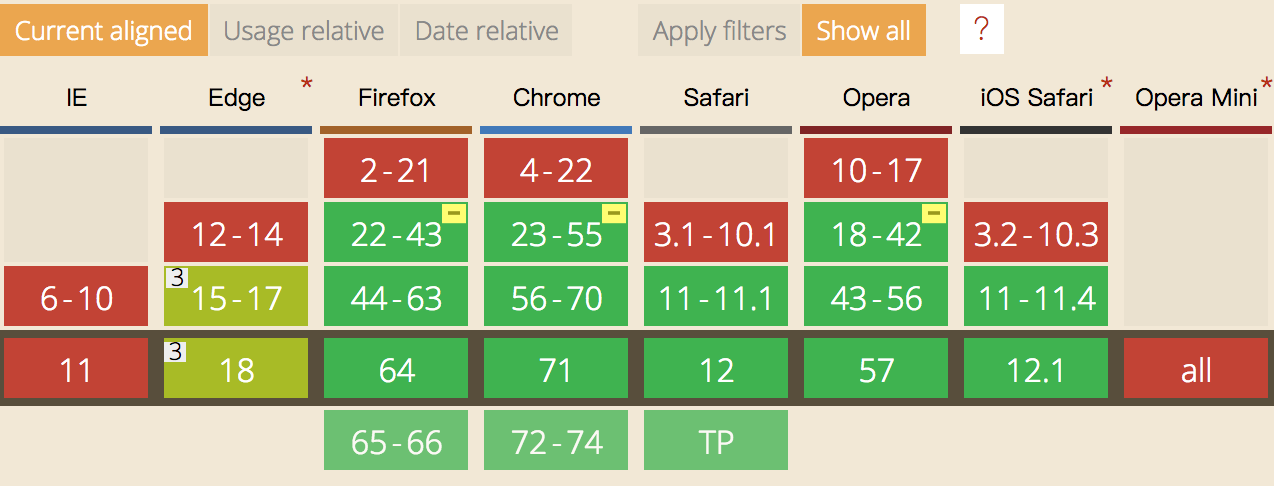
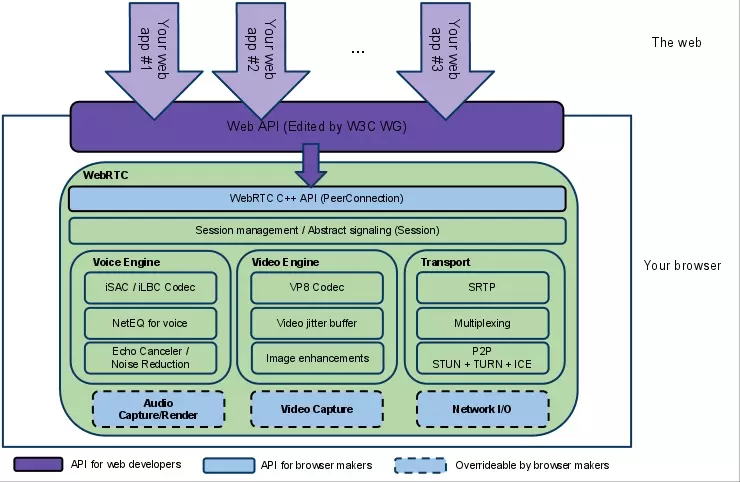
WebRTC技术组成
底层技术
- 图像引擎 (
VideoEngine)- VP8编解码
- jitter buffer: 动态抖动缓冲
- Image enhancements: 图像增益
- 声音引擎 (
VoiceEngine)- iSAC/iLBC/Opus等编解码
- NetEQ语音信号处理
- 回声消除和降噪
- 会话管理 (
Session Management) iSAC音效压缩VP8Google自家WebM项目的影片编解码器- APIs (Native C++ API, Web API)
WebRTC的底层实现非常复杂,附一张架构图如下:
几个重要API
WebRTC虽然底层实现极其复杂,但是面向开发者的API还是非常简洁的,主要分为三方面:
- Network Stream API
MediaStream媒体数据流MediaStreamTrack媒体源
- RTCPeerConnection
RTCPeerConnection允许用户在两个浏览器之间直接通讯。RTCIceCandidateICE协议的候选者RTCIceServer
- Peer-to-peer Data API
RTCDataChannel:数据通道接口,表示一个在两个节点之间的双向的数据通道。
技术点介绍
Network Stream API 网络流媒体接口
主要有两个API:MediaStream与MediaStremTrack:
MediaStreamTrack代表一种单类型数据流,一个MediaStreamTrack代表一条媒体轨道,VideoTrack或AudioTrack。这给我们提供了混合不同轨道实现多种特效的可能性。MediaStream一个完整的音视频流,它可以包含多个MediaStreamTrack对象,它的主要作用是协同多个媒体轨道同时播放,也就是我们常说的音画同步。
MediaStream
我们要通过浏览器实现音视频通话,首先需要访问音/视频设备,这很简单:
const constraints = {
audio: {
echoCancellation: true,
noiseSuppression: false
},
video: true
};
const stream = await navigator.mediaDevices.getUserMedia(constraints);
document.getElementById('#video').srcObject = stream;
调用navigator.mediaDevices.getUserMedia方法即可得到流媒体对象MediaStream。
constraints是一个约束配置,它是用来规范当前采集的数据是否符合需要。
因为,在采集视频时,不同的设备有不同的参数设置,更优的设备可以使用更高的参数(分辨率、帧率等)。
常用的配置如下所示:
{
"audio": {
echoCancellation: boolean,
noiseSuppression: boolean
}, // 是否捕获音频
"video": { // 视频相关设置
"width": {
"min": "381", // 当前视频的最小宽度
"max": "640"
},
"height": {
"min": "200", // 最小高度
"max": "480"
},
"frameRate": {
"min": "28", // 最小帧率
"max": "10"
}
}
}
有些机器只具备麦克风,没有摄像头怎么办呢?这时如果设置video: true就会抛出异常:Requested device not found。
因此,我们需要检测设备是否具备语音/视频的可行性,通过navigator.mediaDevices.enumerateDevices可以枚举出所有的媒体设备,格式如下:
{
deviceId: "2c6e3e1b727b1442f905459e4cd47902988ccac6dff4361ae657cf44c4f3f55c"
groupId: "781470b0bba090c6eb2b26eaa2e643e65a08e37f252f406d31da4d90cc3952e9"
kind: "audioinput"
label: "默认 - 麦克风"
},
{
deviceId: "fe4d04d603512966a729e1313067574f462dbdc579d6ddaad7ad4460089239e1"
groupId: "48c2f2d3191adf2d1d371d23d2219e228268ffbcfa4ba7dfe67a5855c81e6f13"
kind: "videoinput"
label: "默认 - 摄像头"
}
以此可以作为判断设备是否具备语音/视频通话能力的依据。
MediaStreamTrack
上面我们获得了MediaStream对象,通过它我们可以拿到音频/视频的MediaStreamTrack:
const videoTracks = stream.getVideoTracks();
const audioTracks = stream.getAudioTracks();
可以看到,MediaStream中的视频轨与音频轨分为了两个数组。
当然,我们也可以单独操作MediaStreamTrack对象:
videoTracks[0].stop();
它还提供了如下属性和方法,便于我们操作单个轨道数据:
enabled: boolean;
readonly id: string;
readonly isolated: boolean;
readonly kind: string;
readonly label: string;
readonly muted: boolean;
onended: ((this: MediaStreamTrack, ev: Event) => any) | null;
onisolationchange: ((this: MediaStreamTrack, ev: Event) => any) | null;
onmute: ((this: MediaStreamTrack, ev: Event) => any) | null;
onunmute: ((this: MediaStreamTrack, ev: Event) => any) | null;
readonly readyState: MediaStreamTrackState;
applyConstraints(constraints?: MediaTrackConstraints): Promise<void>;
clone(): MediaStreamTrack;
getCapabilities(): MediaTrackCapabilities;
getConstraints(): MediaTrackConstraints;
getSettings(): MediaTrackSettings;
stop(): void;
RTCPeerConnection WebRTC连接
前面一节,我们成功的拿到了MediaStream流媒体对象,但是仍然仅限于本地查看。
如何将流媒体与对方互相交换(实现音视频通话)?
答案是我们必须建立点对点连接(peer-to-peer),这就是RTCPeerConnection要做的事情。
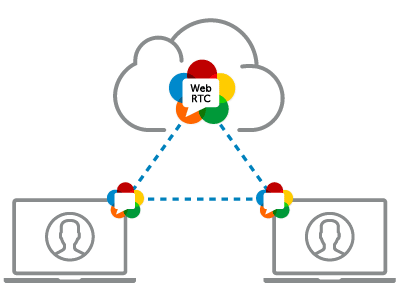
WebRTC区别于传统音视频通话的特点便是两台机器之间直接创建点对点连接,无须通过服务器直接交换音视频流数据!创建点对点连接是
WebRTC中最难的点(RTCPeerConnection内部做了很多工作来简化我们的使用),许多文章都用了非常大的篇幅去阐述它的原理。我接下来会试图用几张图来尽可能的解释下。
但在这之前,我先得提一个概念:信令服务器
两台公网上的设备要互相知道对方是谁,需要有一个中间方去协商交换它们的信息。这就好比媒人做媒一样,互不相识的一男一女,需要一个认识他们俩的媒人去搭桥牵线,让他们能够喜结连理。
信令服务器干的就是这个事儿,下面几张图中的云朵就是信令服务器。
好了,我们开始解释原理。
点对点连接原理
1. 最理想的情况
要在两台设备之间创建点对点连接,最理想的情况是双方都具有公网IP:
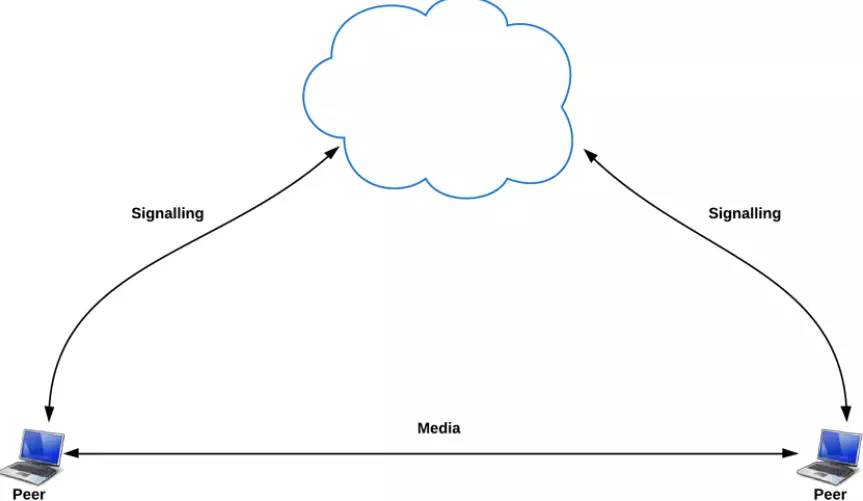
然而,这种情况出现的概率小到几乎可以忽略不计,因为公网IP实在太稀少了。
2. 两台设备都在NAT/防火墙后面
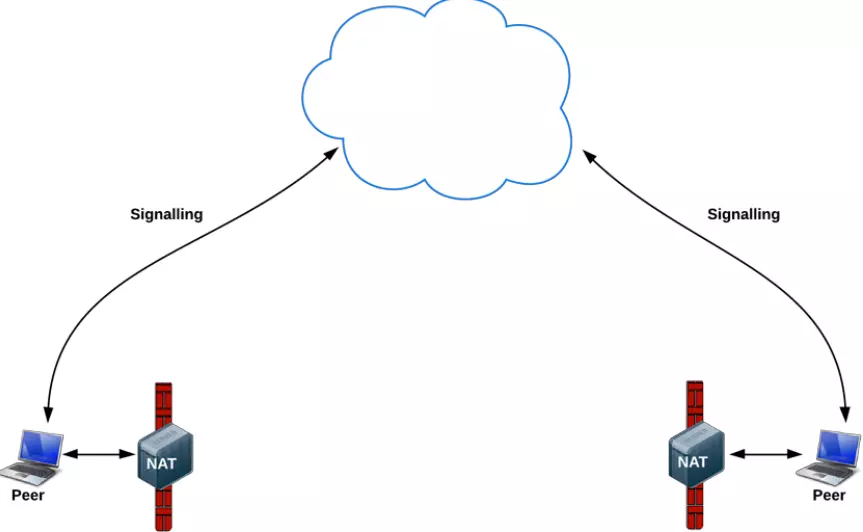
先解释一下上图中的NAT是什么
这是因为IPV4引起的,我们上网很可能会处在一个NAT设备(无线路由器之类)之后。 NAT设备会在IP封包通过设备时修改源/目的IP地址。对于家用路由器来说, 使用的是网络地址端口转换(NAPT), 它不仅改IP, 还修改TCP和UDP协议的端口号, 这样就能让内网中的设备共用同一个外网IP。我们的设备经常是处在NAT设备的后面, 比如在大学里的校园网, 查一下自己分配到的IP, 其实是内网IP, 表明我们在NAT设备后面, 如果我们在寝室再接个路由器, 那么我们发出的数据包会多经过一次NAT。
NAT会造成一个很棘手的问题,那就是内网穿透。
NAT有一个机制,所有外界对内网发送的请求,到达NAT的时候,都会被NAT屏蔽,这样如果我们处于一个NAT设备后面,我们将无法得到任何外界的数据。
但是这种机制有一个解决方案:就是如果我们A主动往B发送一条信息,这样A就在自己的NAT上打了一个通往B的洞。这样A的这条消息到达B的NAT的时候,虽然被丢掉了,但是如果B这个时候在给A发信息,到达A的NAT的时候,就可以从A之前打的那个洞中,发送给到A手上了。
简单来讲,就是如果A和B要进行通信,那么得事先A发一条信息给B,B发一条信息给A。这样提前在各自的NAT上打了对方的洞,这样下一次A和B之间就可以进行通信了。
NAT网络分为四种类型
- 完全锥型NAT
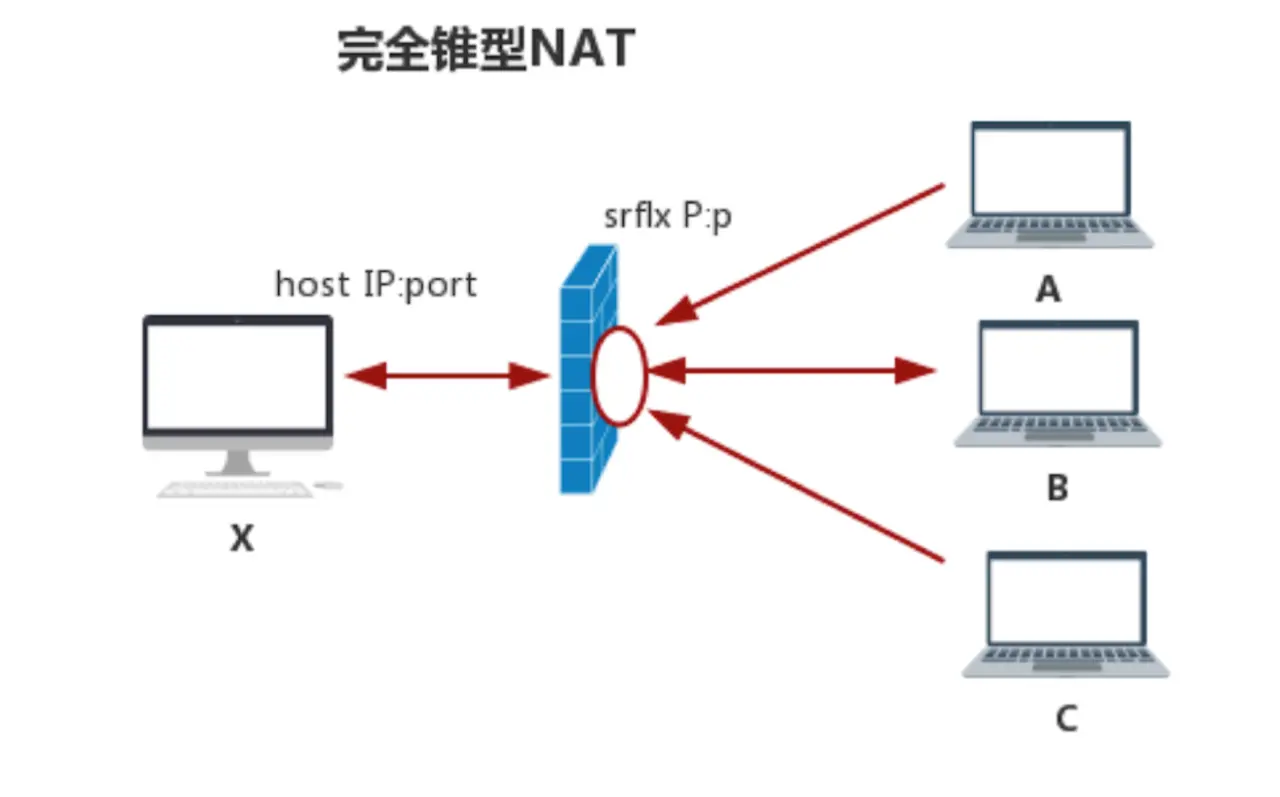
完全锥型NAT的特点是:当host主机通过NAT访问外网的B主机时,就会在NAT上打个“洞”,所有知道这个洞的主机都可以通过它与内网主机上的侦听程序通信。 这个所谓的“洞”就是一张内外网的映射表,简单表示成一个4元组如下:
{
内网IP,
内网端口,
映射的外网IP,
映射的外网端口
}
有了这个“洞”的数据,A主机与C主机都能通过这个洞与host通信了。
- IP限制锥型NAT
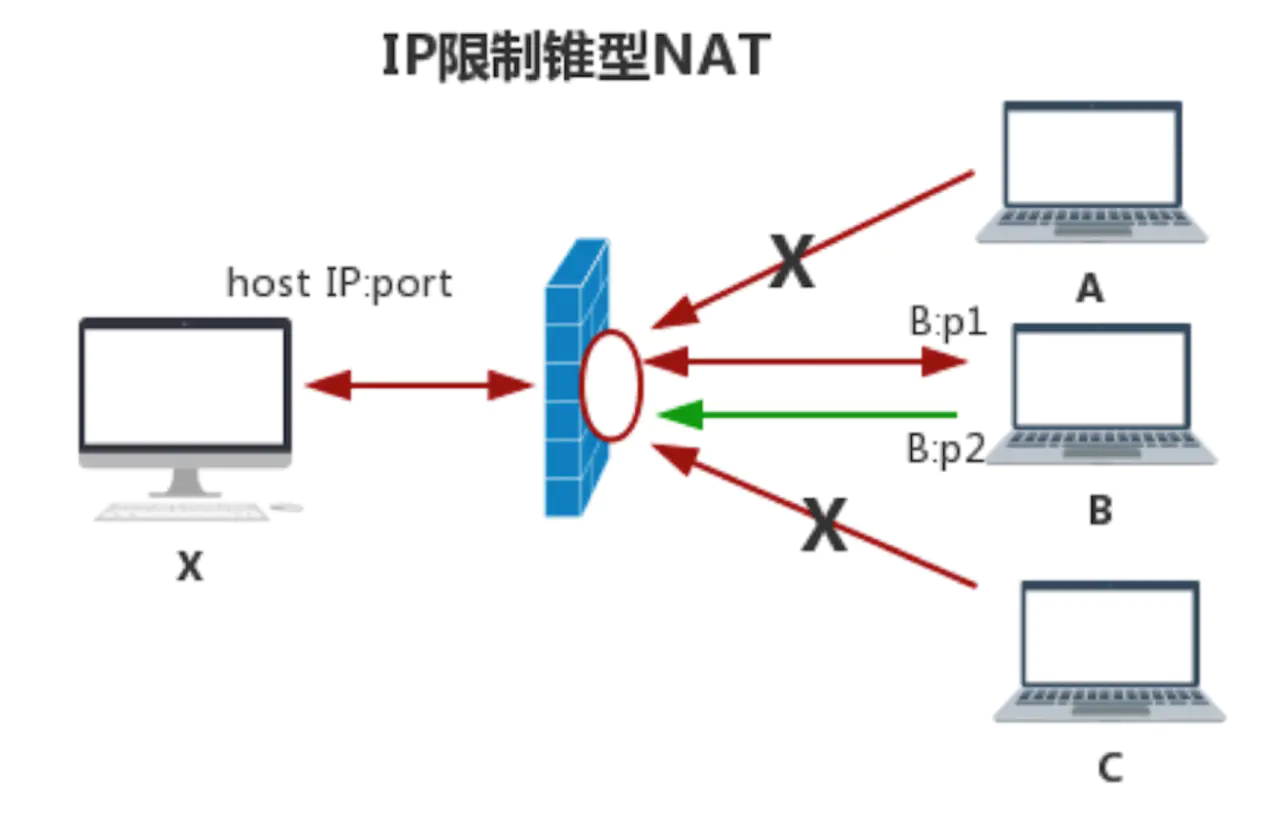
IP限制锥型要比完全锥型NAT严格得多,它的主要特点是:host主机在NAT上打“洞”后,NAT会对穿越洞口的IP地址做限制。只有登记的IP地址才可以通过,也就是说,只有host主机访问过的外网主机才能穿越NAT。其它主机即使知道了这个“洞”也不能与host通信,因为NAT会检查IP地址。 简单表示成一个5元组如下:
{
内网IP,
内网端口,
映射的外网IP,
映射的外网端口,
被访问主机的IP
}
- 端口限制锥型NAT
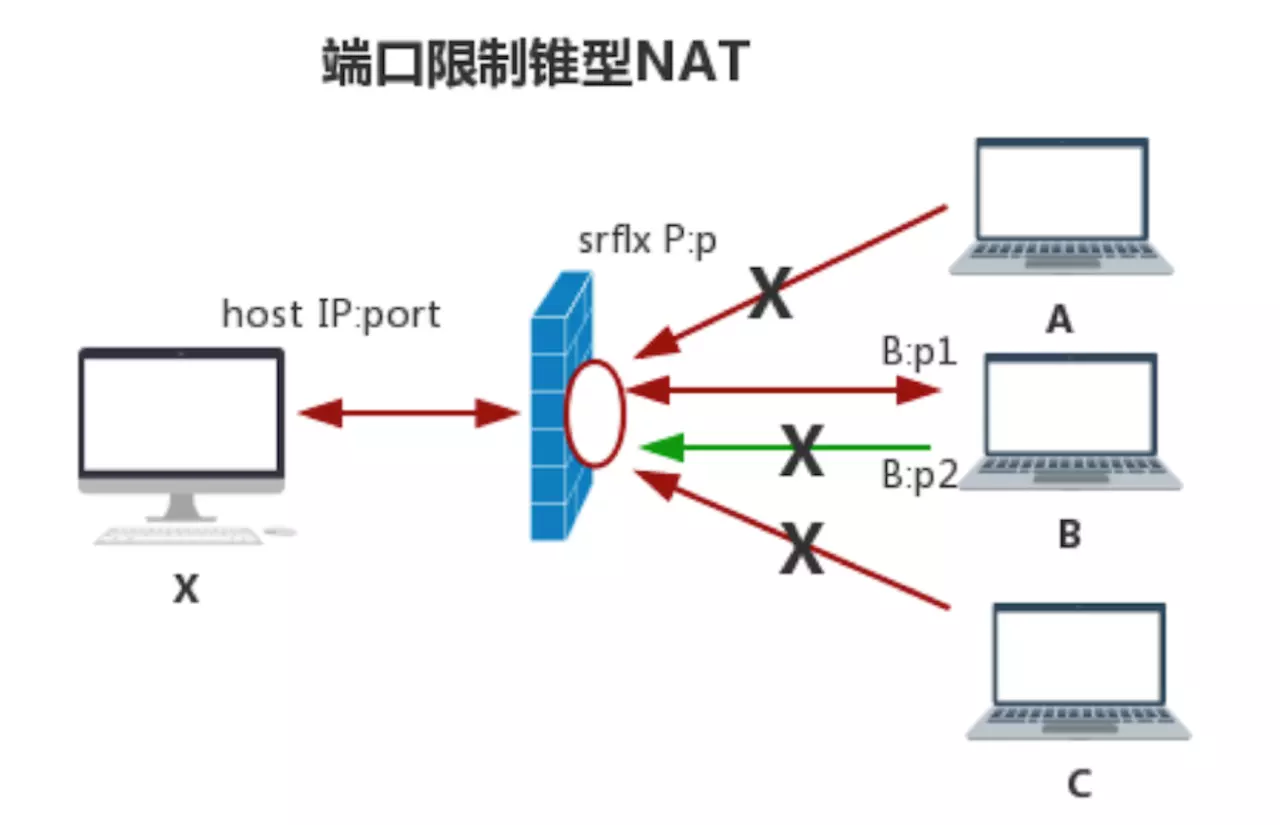
端口限制锥型比IP限制锥型NAT更加严格,它的主要特点是:不光在NAT上对打“洞”的IP地址做了限制,还对具体的端口做了限制。 简单表示成一个6元组如下:
{
内网IP,
内网端口,
映射的外网IP,
映射的外网端口,
被访问主机的IP,
被访问主机的端口
}
如上图所示,只有B主机的P1端口才能穿越NAT与host通信,P2端口都无法穿越。
- 对称型NAT
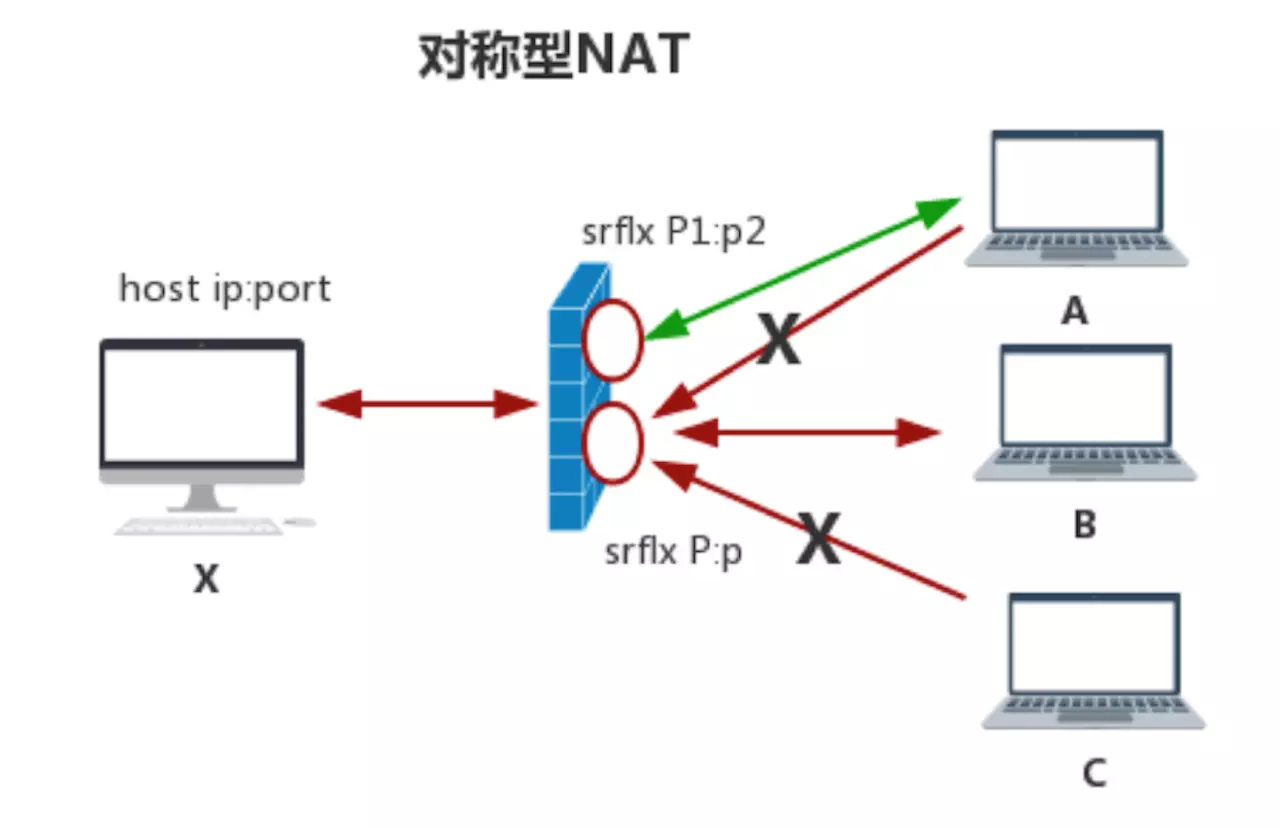
对称型NAT是所有NAT类型中最严格的一种类型,它也是IP+端口限制,但它与端口限制锥型不同之处在于:host与A主机和B主机通信时会打两个不同的“洞”,每访问一个新的主机时,它都会重新开一个“洞”(使用不同的端口,甚至更换IP地址),而端口限制锥型多个连接使用的是同一个端口。
所以,当对称型NAT碰到对称型NAT或对称型NAT遇到端口限制型NAT时,基本上双方是无法穿透成功的。
NAT解释到这里就差不多了,有需要的童鞋可以查找相关资料去详细了解一下,这里不作过多的阐述。
回到刚刚的话题,WebRTC会怎么处理NAT呢?答案是STUN/TURN。
STUN(Session Traversal Utilities for NAT,NAT会话穿越应用程序)是一种网络协议,它允许位于NAT(或多重NAT)后的客户端找出自己的公网地址,查出自己位于哪种类型的NAT之后以及NAT为某一个本地端口所绑定的Internet端端口。
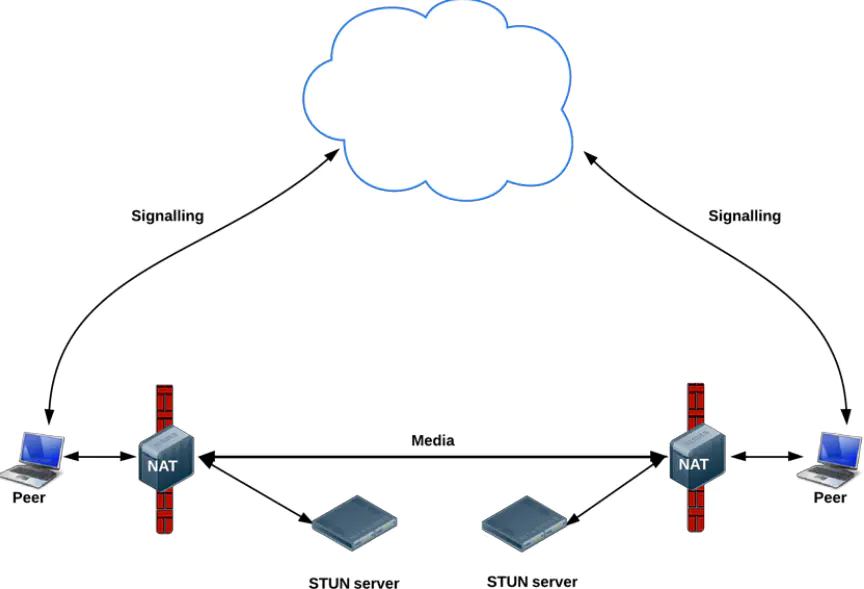
WebRTC首会先使用STUN服务器去找出自己的NAT环境,然后试图找出打“洞”的方式,最后试图创建点对点连接。
STUN服务器可以直接使用google提供的免费服务stun.l.google.com:19302。
STUN/TURN服务都可以自己搭建。
当它尝试过不同的穿透方式都失败之后,为保证通信成功率会启用TURN服务器进行中转,此时所有的流量都会通过TURN服务器。这时如果TURN服务器配置不好或带宽不够时,通信质量基本上很差。
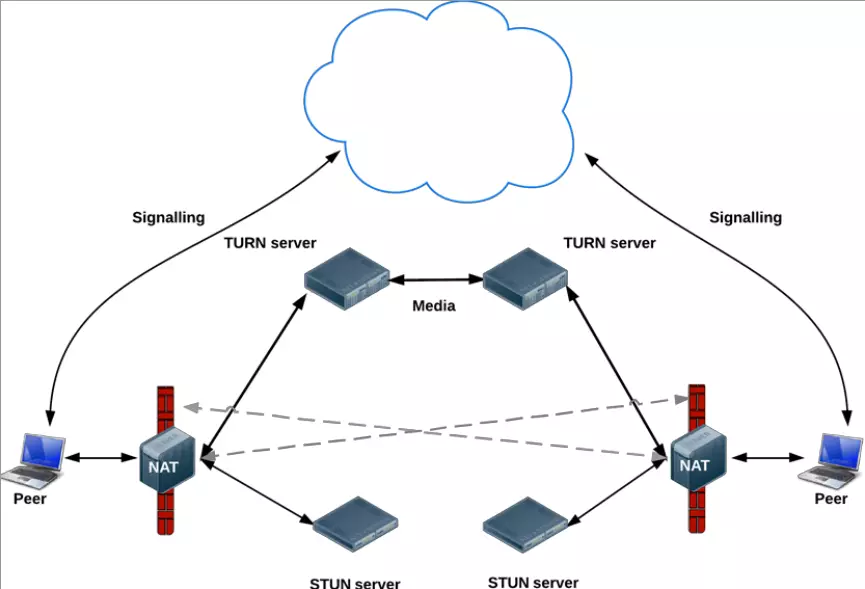
RTCPeerConnection的使用
上面解释了点对点连接的原理,那么具备穿透成功的条件之后,我们要正式使用RTCPeerConnection创建连接了:
const pc = new RTCPeerConnection({ iceServers: [
{
'url': 'stun:turn.mywebrtc.com'
},
{
'url': 'turn:turn.mywebrtc.com',
'credential': 'siEFid93lsd1nF129C4o',
'username': 'webrtcuser'
}
]
});
pc.onicecandidate = candidate => sendEvent(Events.Candidate, { candidate });
stream.getTracks().forEach(track => {
pc.addTrack(track, stream);
});
const answer = await pc.createAnswer();
pc.setLocalDescription(answer);
sendEvent(Events.Answer, { answer });
const offer = await pc.createOffer(options);
pc.setLocalDescription(offer);
sendEvent(Events.Offer, { offer });
- 实例化一个
RTCPeerConnection对象,需要提供iceServers属性,提供STUN/TURN服务地址; - 监听
onicecandidate事件,当本地与对方offer/answer握手之后,icecandidate时会被通知到,再通过信令服务器将candidate信息发送给对方; pc.addTrack(track, stream);绑定媒体轨道;- 收到
offer发送answer/ 收到answer发送offer
用时序图表示可能更便于理解:
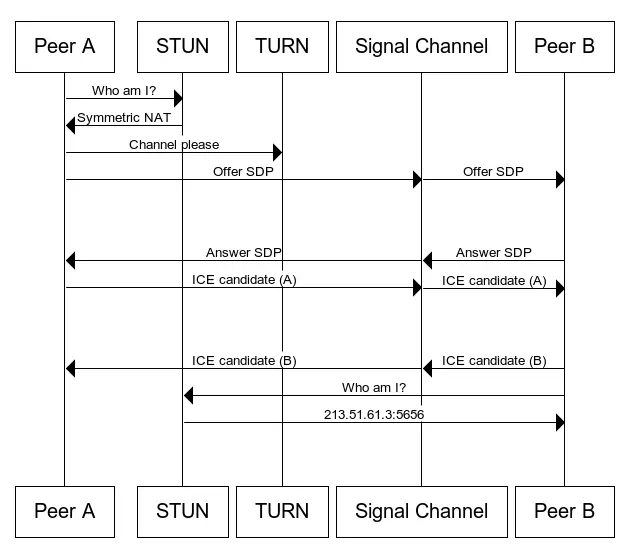
- Peer A实例化一个
RTCPeerConnection对象,并监听onicecandidate事件; - Peer A创建
offercreateOffer并通过信令服务器发送给Peer B; - Peer B收到
offer后setRemoteSDP,创建answercreateAnswer并通过信令服务器发送给Peer A; - Peer A收到
answer后setRemoteSDP; - Peer A与Peer B互相处理完
offer/answer,icecandidate被通知到,Peer A与Peer B交换candidate信息; - 连接建立完成!
推送MediaStream
当连接建立完成之后,RTCPeerConnection会将本地的tracks轨道推送给对方,这就是为什么要pc.addTrack(track, stream);了
注意
pc.addTrack(track, stream);的第二个参数stream非常重要,如果不给,对方拿到的结果streams会是空数组!
当对方接收到tracks推送时,会通知回调函数pc.ontrack,可以从event对象中拿到远程流媒体对象:
pc.ontrack = event => {
this.remoteMediaStream = event.streams[0];
};
当互相拿到对方的流媒体对象时,语音/视频通话就成功了,将流赋给<video />标签即可。
WebRTC的规范这几年变动比较大,网上有很多文章和demo都有点旧了,有些API已经废弃,比如现在的ontrack以前是onaddstream,现在的addTrack取代了之前的addStream。如果大家看到addStream或onaddstream不必担心,使用TypeScript的好处就是在这方面它总能给你最新的代码提示。
综上所述,RTCPeerConnection主要负责穿透并建立连接,并且它还会自动推流。
但它的能力可不止于此,它还有一个能力:RTCDataChannel。
RTCDataChannel
标题里除了实时语音/视频聊天,还提到了文件传输,这便是RTCDataChannel的功能。
利用它,能传输string、ArrayBuffer、Blob(目前仅FireFox支持)类型的数据。
所以,传输文本和文件不在话下。它的使用和MediaStream一样,都需要依附RTCPeerConnection,这也能理解,离开了连接,不论是流媒体还是文件都传输不了吧?
RTCPeerConnection提供了一个方法用来创建RTCDataChannel:
const dataChannel = pc.createDataChannel(label: string);
查阅官方API文档,
label只是一个描述,不要求唯一,也没有实际意义。
假设使用Peer A的RTCPeerConnection创建了RTCDataChannel,那么Peer B也需要创建RTCDataChannel吗?
答案是:不用!
Peer B只需要监听RTCPeerConnection的ondatachannel事件即可,当Peer A创建RTCDataChannel成功后,Peer B的RTCPeerConnection会收到通知,并触发ondatachannel事件传入Peer A的RTCDataChannel对象。
解释有点绕,直接看代码:
// Peer A
const dataChannel = pc_a.createDataChannel('message');
// Peer B
pc_b.ondatachannel = event => {
// 成功拿到 RTCDataChannel
const dataChannel = event.channel;
};
当然,这一切的一切取决于Peer A与Peer B的RTCPeerConnection成功握手,所以说它才是最重要的,也是最难理解的。
那么接下来,如何发送消息呢?
发送文本消息是非常简单的:
// Peer A
dataChannel.send('hello , I am Peer A');
// Peer B
dataChannel.onmessage = event => {
console.log(event.data); // hello , I am Peer A
};
真的非常简单。
但是接下来我们要传输文件,就略微麻烦一些了……FireFox倒还好,支持直接发送Blob类型数据。
据我测试,FireFox发送的
Blob对象,Chrome也能接收到(虽然它发送不了,会直接抛出异常)。
对于Chrome而言,要发送文件,只能选择ArrayBuffer类型,而发送的时候需要进行分块传输,一般1024 byte为1块。 单个文件还好,如果是多个文件同时传输,接收方就需要判断每次接收的块是属于哪个文件的。
所以我选择了将对象{ fileId, data: chunk }转成字符串传输,接收方收到消息解码后能通过fileId还原到相应的文件上。
// Peer A发送文件
const fileReader = new FileReader();
let currentChunk = 0;
const readNextChunk = () => {
const start = chunkLength * currentChunk;
const end = Math.min(transfer.totalSize, start + chunkLength);
fileReader.readAsArrayBuffer(transfer.file.slice(start, end));
};
fileReader.onload = () => {
const raw = fileReader.result as ArrayBuffer;
transfer.transferedSize += raw.byteLength;
transfer.progress = transfer.transferedSize / transfer.totalSize;
this.channel.sendMessage({
fileId,
data: arrayBuffer2String(raw)
});
currentChunk++;
if(chunkLength * currentChunk < transfer.totalSize) {
readNextChunk();
} else {
transfer.status = TransferStatus.Complete;
};
};
readNextChunk();
// Peer B接收文件
dataChannel.onmessage = (event: MessageEvent, raw: string) => {
const result = JSON.parse(raw) as { fileId: string, data: string };
const { fileId, data } = result;
const buffer = string2ArrayBuffer(data);
const transfer = this.receiveFileQueue.find(f => f.id === fileId);
transfer.status = TransferStatus.Transfering;
transfer.data.push(buffer);
transfer.transferedSize += buffer.byteLength;
transfer.progress = transfer.transferedSize / transfer.totalSize;
if (transfer.transferedSize === transfer.totalSize) {
transfer.status = TransferStatus.Complete;
}
}
实际效果如下图所示:
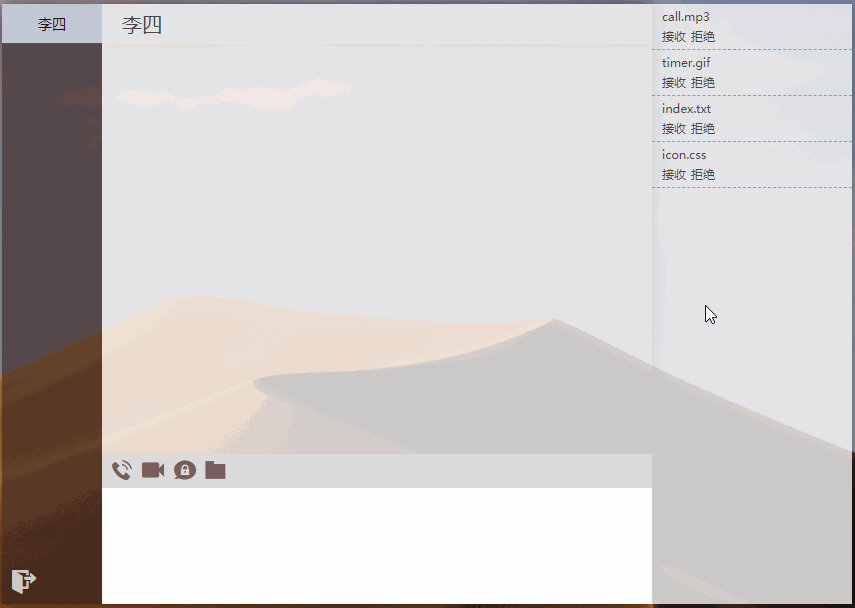
因为接收到文件后,我设计的交互是让用户自己选择是否下载或删除,所以我是将接收到的文件二进制数据直接存储在内存变量上,这也导致了一个问题:文件越多或者大文件(1M以上)就会占用内存导致浏览器卡顿。
关于这个问题有解决方案,就是使用IndexedDB将文件存储到浏览器的本地数据库中去,它使用的是本地文件系统。不过懒得折腾了,毕竟这只是个WebRTC的demo呢。
结束语
好吧,基本上讲完了,内容比较多,能坚持看到这里的童鞋已经很不容易了。
WebRTC本就是一个比较小众的技术,多数程序员平日都用不到它,甚至发布多年至今也不知道它的存在(我身边90%的同事都不知道它的存在)。
我是2017年在一家在线客服软件公司就职时了解到这项技术的,当时惊呆了,手机浏览器和PC浏览器竟然能在不借助任何插件的情况下实现语音视频通话!
工作上没用到这个技术,所以一直也没去细细研究。直到最近心血来潮才用它写了个demo,说白了还是太懒导致的……
