

本文首发于个人博客
前言
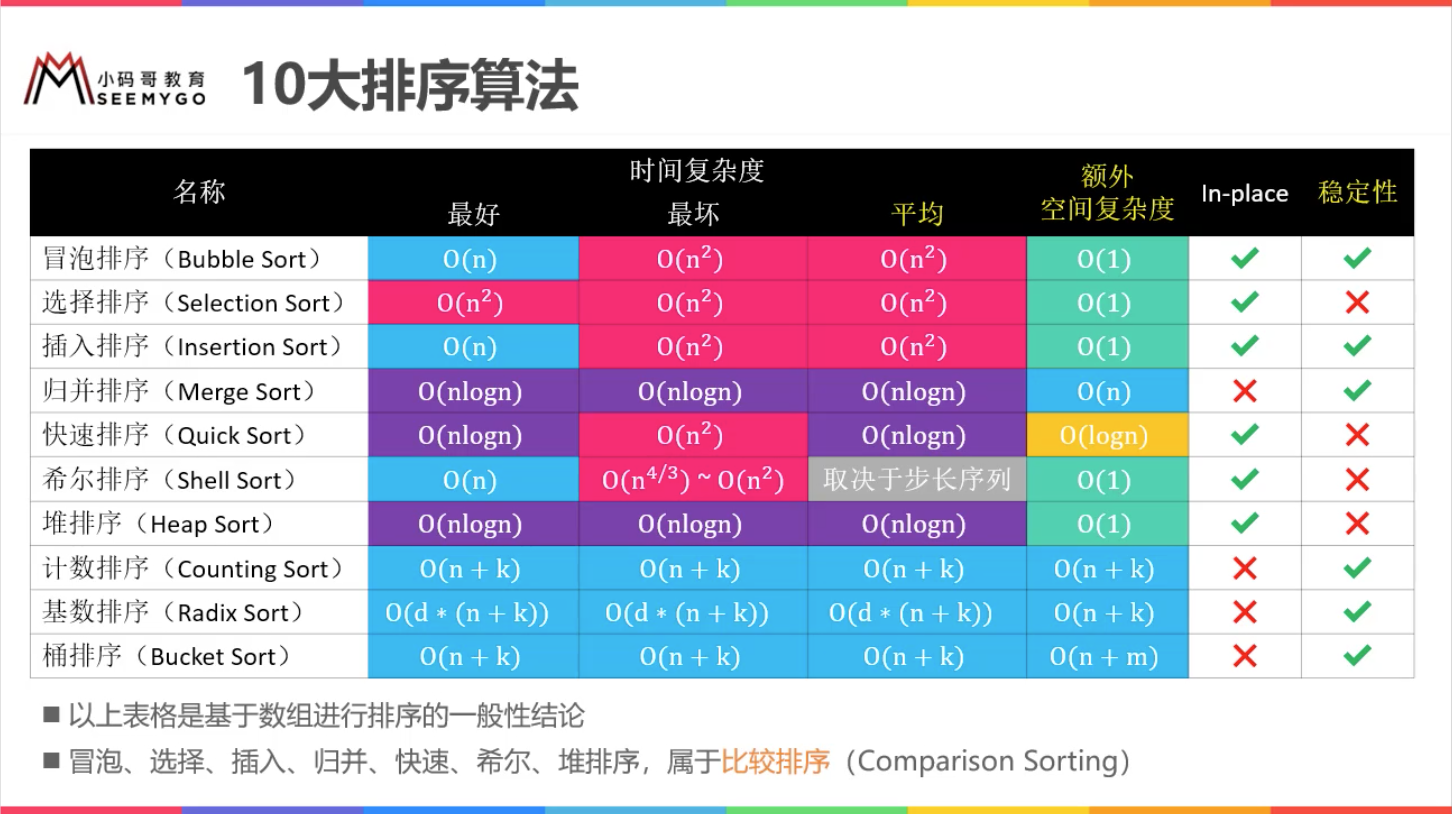
本系列排序包括十大经典排序算法。
- 使用的语言为:Java
- 结构为:
定义抽象类
Sort里面实现了,交换,大小比较等方法。例如交换两个值,直接传入下标就可以了。其他的具体排序的类都继承抽象类Sort。这样我们就能专注于算法本身。
/*
* 返回值等于0,代表 array[i1] == array[i2]
* 返回值小于0,代表 array[i1] < array[i2]
* 返回值大于0,代表 array[i1] > array[i2]
*/
protected int cmp(int i1, int i2) {
return array[i1].compareTo(array[i2]);
}
protected int cmp(T v1, T v2) {
return v1.compareTo(v2);
}
protected void swap(int i1, int i2) {
T tmp = array[i1];
array[i1] = array[i2];
array[i2] = tmp;
}
-
冒泡、选择、插入、归并、希尔、堆排序都是基于比较的排序
- 平均时间复杂度最低O(nlogn)
-
计数排序、桶排序、基数排序不是基于比较的排序
- 使用空间换时间,某些时候,平均时间复杂度可以低于O(nlogn)
什么是基数排序
- 基数排序(radix sort)属于“分配式排序”(distribution sort),又称“桶子法”(bucket sort)或bin sort,顾名思义,它是透过键值的部份资讯,将要排序的元素分配至某些“桶”中,藉以达到排序的作用,基数排序法是属于稳定性的排序,其时间复杂度为O (nlog(r)m),其中r为所采取的基数,而m为堆数,在某些时候,基数排序法的效率高于其它的稳定性排序法
实现方法
- 最高位优先(Most Significant Digit first)法,简称MSD法:先按k1排序分组,同一组中记录,关键码k1相等,再对各组按k2排序分成子组,之后,对后面的关键码继续这样的排序分组,直到按最次位关键码kd对各子组排序后。再将各组连接起来,便得到一个有序序列。
- 最低位优先(Least Significant Digit first)法,简称LSD法:先从kd开始排序,再对kd-1进行排序,依次重复,直到对k1排序后便得到一个有序序列。
算法思想
第一步
以LSD为例,假设原来有一串数值如下所示:
73, 22, 93, 43, 55, 14, 28, 65, 39, 81
首先根据个位数的数值,在走访数值时将它们分配至编号0到9的桶子中:
0
1 81
2 22
3 73 93 43
4 14
5 55 65
6
7
8 28
9 39
第二步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
81, 22, 73, 93, 43, 14, 55, 65, 28, 39
接着再进行一次分配,这次是根据十位数来分配:
0
1 14
2 22 28
3 39
4 43
5 55
6 65
7 73
8 81
9 93
第三步
接下来将这些桶子中的数值重新串接起来,成为以下的数列:
14, 22, 28, 39, 43, 55, 65, 73, 81, 93
这时候整个数列已经排序完毕;如果排序的对象有三位数以上,则持续进行以上的动作直至最高位数为止。
- LSD的基数排序适用于位数小的数列,如果位数多的话,使用MSD的效率会比较好。MSD的方式与LSD相反,是由高位数为基底开始进行分配,但在分配之后并不马上合并回一个数组中,而是在每个“桶子”中建立“子桶”,将每个桶子中的数值按照下一数位的值分配到“子桶”中。在进行完最低位数的分配后再合并回单一的数组中。
算法稳定性
- 基数排序是一种稳定排序算法。
是否是原地算法
- 何为原地算法?
- 不依赖额外的资源或者依赖少数的额外资源,仅依靠输出来覆盖输入
- 空间复杂度为 𝑂(1) 的都可以认为是原地算法
- 非原地算法,称为 Not-in-place 或者 Out-of-place
- 基数排序不属于 In-place
时空复杂度
-
最好、最坏、平均时间复杂度:O(d*(n+k))
- d是最大值的位数,k是进制
-
空间复杂度:O(n+k)
代码
-
十大排序算法之计数排序中,先使用最简单的实现方案,先求最大值,用于创建数组,然后遍历出来,统计元素出现的次数,最后再按照顺序赋值
-
基数排序内部的实现可以用计数排序的思路
package YZ.Sort;
public class RadixSort extends Sort<Integer> {
@Override
protected void sort() {
int max = array[0];
for (int i = 1; i < array.length; i++) {
if (array[i]>max) {
max = array[i];
}
}
// 个位数: array[i] / 1 % 10 = 3
// 十位数:array[i] / 10 % 10 = 9
// 百位数:array[i] / 100 % 10 = 5
// 千位数:array[i] / 1000 % 10 = ...
for (int divider = 1; divider <= max; divider*=10) {
sort(divider);
}
}
protected void sort(int divider) {
// TODO Auto-generated method stub
// 开辟内存空间,存储次数
int[] counts = new int[10];
// 统计每个整数出现的次数
for (int i = 0; i < array.length; i++) {
counts[array[i]/divider%10]++;
}// O(n)
// 累加次数
for (int i = 1; i < counts.length; i++) {
counts[i]+= counts[i-1];
}
//从后向前遍历元素,将她放在有序数组中的合适位置
int[] newArray = new int[array.length];
for (int i = array.length-1; i >=0 ; i--) {
//获取元素在counts中的索引
int index = array[i]/divider%10;
//获取元素在counts中的值
//counts[index];
//放在合适位置
newArray[--counts[index]] = array[i];
}
// 将有序数组赋值到array
for (int i = 0; i < newArray.length; i++) {
array[i] = newArray[i];
}
}
}
结果
数据源:
从1到80000之间随机生成20000个数据来测试
Integer[] array = Integers.random(20000, 1, 80000);
结果如下
【CountingSort】 稳定性:true 耗时:0.005s(5ms) 比较次数:0 交换次数:0
【QuickSort】 稳定性:false 耗时:0.009s(9ms) 比较次数:33.27万 交换次数:1.32万
【MergeSort】 稳定性:true 耗时:0.01s(10ms) 比较次数:26.10万 交换次数:0
【RadixSort】 稳定性:true 耗时:0.014s(14ms) 比较次数:0 交换次数:0
【ShellSort】 稳定性:false 耗时:0.016s(16ms) 比较次数:43.34万 交换次数:0
【HeapSort】 稳定性:false 耗时:0.023s(23ms) 比较次数:51.09万 交换次数:2.00万
【SelectionSort】 稳定性:true 耗时:0.514s(514ms) 比较次数:2.00亿 交换次数:2.00万
【InsertionSort1】 稳定性:true 耗时:1.362s(1362ms) 比较次数:9935.15万 交换次数:9933.15万
【BubbleSort】 稳定性:true 耗时:2.529s(2529ms) 比较次数:2.00亿 交换次数:9933.15万
代码地址:
- 文中的代码在git上:github地址
