

大家好,我叫谢伟,是一名程序员。
今天的主题:kafka 上手指南--集群版
前提回顾:kafka 单节点
1. 基本概念
在消息系统中,涉及的概念都比较类似,初学消息系统,概念有时候理解不到位,需要读者反复的根据自己的学习进度回过头把基本概念捋清楚。
下面采用问答式陈述基本概念:
- 什么是 broker ?
简单的说,一个 kafka server 就是一个 broker。
- 什么是 生产者 producer ?
简单的说,提供消息的系统称为生产者
- 什么是 消费者 consumer ?
简单的说,对消息进行处理的系统称为消费者
- 什么是 topic ?
简单的说,区分消息的不同类型,人为的起个名字,所以 topic 是个逻辑概念。
- 什么是分区 partition ?
简单的说,是存储消息的实体,即将 topic 划分为不同的分区。物理层面看就是以 topic-N 命名的文件夹,文件夹下存储消息日志。当然分区可以在同一个 broker 上,也可以在不同 broker 上,如果你用上了集群版的 kafka。
topic-go-0
topic-go-1
topic-go-2
...
- 什么是 offset ?
简单的说,是一个表示位移的数字。用来给消费者做标记的。比如给你发了100 条消息,我怎么知道你消费到了第几个呢,offset 就是用来标记的。
- 什么是 消费者组 ?
简单的说,是一组消费者共同消费一个或者多个topic, 当然某个消费者消费的是一个或者多个分区内的消息。为什么有消费者,又要消费者组?消费者消费消息,需要订阅某个 topic, 消费者组共同消费一个或者多个 topic,这样可以的效果是:可拓展、容错。可拓展指,新加入一个消费者,可以承担部分任务,减轻其他消费者负担;同理,减少一个消费者,再重新给消费者分配消息。这种分配机制,在 kafka 系统中称之为:Rebalance,动态的调整。
那么什么时候会 Rebalance ?
- 消费者数目的变化
- topic 的变化
- 分区的变化
其中消费者数目的变化,是最常见的场景。Rebalance 有利有弊,利:可拓展,容错;弊:Rebalance 比较耗性能,某一个时刻会停止消费消息。
- 什么是 kafka 集群?
简单的说,集群是一群服务的集合,一个典型的特征是:多机器,多服务。这种特征能够保障系统的高可用,高并发。系统内部之间可以通过 zookeeper 、 Metadata 等发现彼此;对外,就像使用单服务一样。
- “能力”的大小怎么控制 ?
配置文件,比如我怎么保障生产者准确的发送消息呢,比如多个分区,我按什么分区策略呢,比如生产者的消息要不要压缩,采用什么压缩方式;比如消费者是从最新的消费,还是最老的消息消费;比如消费者组的 Rebalance 策略是什么?
这些特性,我把它称之为能力的大小,这些能力的大小,需要使用者足够熟悉才能发挥其能力,或者说能具体问题具体分析。
- broker “能力”的配置
- 生产者“能力”的配置
- 消费者“能力”的配置
- 消费者组“能力”的配置
2. 配置
启动服务时的配置文件,这也是绝大多少服务启动的一般方式,比如 MySQL 数据库服务,比如 Redis 服务等,都是启动时进行配置文件,赋予其能力。
broker
# 目录
config/server.properties
- log.dirs 消息存储目录,可以多个
log.dirs=/kafka/kafka-logs-kfk1
- zookeeper.connect ,可以多个,用于集群方式
zookeeper.connect=zookeeper-1:2181
- advertised.listeners 对外地址
advertised.listeners=PLAINTEXT://kfk1:9092
- listener.security.protocol.map 安全协议
listener.security.protocol.map=CONTROLLER:PLAINTEXT
一般这些配置就可以,其他默认,其中 log.dirs , zookeeper.connect 最为重要
topic
- auto.create.topics.enable 是否允许自动创建 topic
auto.create.topics.enable=false
启动服务之后,一般通过客户端工具,编写代码完成相应的设置。
就 go 中,kafka 客户端使用:sarama
type config struct {
Producer struct {
...
}
Consumer struct {
...
Group struct {
...
}
}
}
- 配置针对消费者,配置config.Consumer
- 配置针对生产者,配置config.Producer
- 配置针对消费者组,配置config.Consumer.Group
消费者:
c.Consumer.Fetch.Min = 1
c.Consumer.Fetch.Default = 1024 * 1024
c.Consumer.Retry.Backoff = 2 * time.Second
c.Consumer.MaxWaitTime = 250 * time.Millisecond
c.Consumer.MaxProcessingTime = 100 * time.Millisecond
c.Consumer.Return.Errors = false
c.Consumer.Offsets.CommitInterval = 1 * time.Second
c.Consumer.Offsets.Initial = OffsetNewest
c.Consumer.Offsets.Retry.Max = 3
其中,一般默认,否则配置:
- 是否返回错误:c.Consumer.Return.Errors
- 消费起始值:c.Consumer.Offsets.Initial
- 重试机制:Retry
生产者:
// 消息的最大值大概 1MB
c.Producer.MaxMessageBytes = 1000000
// 消息是否应答:0: 不应答,禁用;1: leader 收到即可 ; -1: 所有的副本都收到
c.Producer.RequiredAcks = WaitForLocal
c.Producer.Timeout = 10 * time.Second
// 分区策略:随机、轮询、hash 等
c.Producer.Partitioner = NewHashPartitioner
// 重试机制
c.Producer.Retry.Max = 3
c.Producer.Retry.Backoff = 100 * time.Millisecond
c.Producer.Return.Errors = true
// 压缩算法:gzip, zstd, lz4, snappy
c.Producer.CompressionLevel = CompressionLevelDefault
消费者组:
// 间隔
c.Consumer.Group.Session.Timeout = 10 * time.Second
// 心跳
c.Consumer.Group.Heartbeat.Interval = 3 * time.Second
// Rebalance 策略
c.Consumer.Group.Rebalance.Strategy = BalanceStrategyRange
c.Consumer.Group.Rebalance.Timeout = 60 * time.Second
c.Consumer.Group.Rebalance.Retry.Max = 4
c.Consumer.Group.Rebalance.Retry.Backoff = 2 * time.Second
3. 消费者组
普通的消费者,一般需要指定 topic, offset 指定消费:
比如:
config := sarama.NewConfig()
config.Consumer.Return.Errors = true
brokers := []string{"127.0.0.1:9092"}
master, err := sarama.NewConsumer(brokers, config)
consumer, err := master.ConsumePartition("topic-python", 0, sarama.OffsetNewest)
其中:
ConsumePartition(topic string, partition int32, offset int64) (PartitionConsumer, error)
- topic
- partition
- offset
但一般这种形式,需要指定 offset 这种,不方便使用。所以一般使用消费者组的形式。
type KafkaConsumerGroupAction struct {
group sarama.ConsumerGroup
}
func NewKafkaConsumerGroupAction(brokers []string, groupId string) *KafkaConsumerGroupAction {
config := sarama.NewConfig()
sarama.Logger = log.New(os.Stdout, "[consumer_group]", log.Lshortfile)
// 重平衡策略
config.Consumer.Group.Rebalance.Strategy = sarama.BalanceStrategySticky
config.Consumer.Group.Session.Timeout = 20 * time.Second
config.Consumer.Group.Heartbeat.Interval = 6 * time.Second
config.Consumer.IsolationLevel = sarama.ReadCommitted
config.Consumer.Offsets.Initial = sarama.OffsetNewest
config.Version = sarama.V2_3_0_0
consumerGroup, e := sarama.NewConsumerGroup(brokers, groupId, config)
if e != nil {
log.Println(e)
return nil
}
return &KafkaConsumerGroupAction{group: consumerGroup}
}
func (K *KafkaConsumerGroupAction) Consume(topics []string, wg sync.WaitGroup, ctx context.Context) {
var consumer = KafkaConsumerGroupHandler{ready: make(chan bool)}
go func() {
defer wg.Done()
for {
if err := K.group.Consume(ctx, topics, &consumer); err != nil {
log.Panicf("Error from consumer: %v", err)
}
if ctx.Err() != nil {
return
}
consumer.ready = make(chan bool)
}
}()
<-consumer.ready
log.Println("Sarama consumer up and running!...")
sigterm := make(chan os.Signal, 1)
signal.Notify(sigterm, syscall.SIGINT, syscall.SIGTERM)
select {
case <-ctx.Done():
log.Println("terminating: context cancelled")
case <-sigterm:
log.Println("terminating: via signal")
}
wg.Wait()
if err := K.group.Close(); err != nil {
log.Panicf("Error closing client: %v", err)
}
}
type KafkaConsumerGroupHandler struct {
ready chan bool
}
func (K *KafkaConsumerGroupHandler) Setup(sarama.ConsumerGroupSession) error {
return nil
}
func (K *KafkaConsumerGroupHandler) Cleanup(sarama.ConsumerGroupSession) error {
return nil
}
func (K *KafkaConsumerGroupHandler) ConsumeClaim(session sarama.ConsumerGroupSession, claim sarama.ConsumerGroupClaim) error {
for message := range claim.Messages() {
log.Printf("Message claimed: value = %s, timestamp = %v, topic = %s, partions = %d, offset = %d", string(message.Value), message.Timestamp, message.Topic, message.Partition, message.Offset)
lag := claim.HighWaterMarkOffset() - message.Offset
fmt.Println(lag)
session.MarkMessage(message, "")
}
return nil
}
消费者组:
type ConsumerGroup interface {
Consume(ctx context.Context, topics []string, handler ConsumerGroupHandler) error
Errors() <-chan error
Close() error
}
其中:
type ConsumerGroupHandler interface {
Setup(ConsumerGroupSession) error
Cleanup(ConsumerGroupSession) error
ConsumeClaim(ConsumerGroupSession, ConsumerGroupClaim) error
}
真实的消息处理,需要实现 ConsumerGroupHandler 接口。
4. 生产者的一般处理流程
如果这些概念你都清楚,那么整体来说,使用 kafka 的难点在哪呢?
- 如何确保消息准确无误地发送
- 如何确保不重复消费消息
- 如何确保消息不滞后,最好是生产者发往消息系统,消费者立马消费掉,没有延长
- 如何确保系统高可用
- 生产者配置
- 实例化生产者
- 构建消息
- 发送消息
- 关闭生产者实例
func NewAsyncProducer(addrs []string, conf *Config) (AsyncProducer, error) {
client, err := NewClient(addrs, conf)
if err != nil {
return nil, err
}
return newAsyncProducer(client)
}
//异步生产者
type AsyncProducer interface {
AsyncClose()
Close() error
Input() chan<- *ProducerMessage // 发送消息
Successes() <-chan *ProducerMessage
Errors() <-chan *ProducerError
}
5. 消费者的一般处理流程
消费者的一般处理流程:
- 消费者配置
- 实例化消费者
- 订阅主题
- 提交位移
- 关闭消费者
func NewConsumer(addrs []string, config *Config) (Consumer, error) {
client, err := NewClient(addrs, config)
if err != nil {
return nil, err
}
return newConsumer(client)
}
type Consumer interface {
Topics() ([]string, error) // 消息
Partitions(topic string) ([]int32, error) // 分区
ConsumePartition(topic string, partition int32, offset int64) (PartitionConsumer, error) // 消费消息
HighWaterMarks() map[string]map[int32]int64 // 高水位
Close() error
}
6. 消费者组的一般处理流程
普通的消费者,需要指定分区和位移,进行消费,不常用。一般选择消费者组。
那么消费者组一般的处理流程是?
- 配置消费者组
- 实例话消费者组,指定 topic, 指定消费者组 GroupID
- 消费消息
- 关闭消费者组
type ConsumerGroup interface {
Consume(ctx context.Context, topics []string, handler ConsumerGroupHandler) error
Errors() <-chan error
Close() error
}
消费者组处理器:
type ConsumerGroupHandler interface {
Setup(ConsumerGroupSession) error
Cleanup(ConsumerGroupSession) error
ConsumeClaim(ConsumerGroupSession, ConsumerGroupClaim) error
}
7. 集群
上文说到,集群一个特征是:多机器,多服务。
真实的线上环境,zookeeper 部署在不同机器,kafka server 部署在不同机器,组成的系统,共同服务于线上系统。
个人学习,为了达到集群的效果,即:使用不同的端口区分即可。
当然你可以本地配置 zookeeper, kafka。但我一般喜欢用容器的方式,部署起来方便。
- 多节点 zookeeper
zookeeper-1:
image: zookeeper
restart: always
hostname: zookeeper-1
ports:
- 2181:2181
environment:
ZOO_MY_ID: 1
ZOO_SERVERS: server.1=0.0.0.0:2888:3888;2181 server.2=zookeeper-2:2888:3888;2181 server.3=zookeeper-3:2888:3888;2181
volumes:
- /local/volumn/zookeeper1/data:/data
- /local/volumn/zookeeper1/datalog:/datalog
zookeeper-2:
image: zookeeper
restart: always
hostname: zookeeper-2
ports:
- 2182:2181
environment:
ZOO_MY_ID: 2
ZOO_SERVERS: server.1=zookeeper-1:2888:3888;2181 server.2=0.0.0.0:2888:3888;2181 server.3=zookeeper-3:2888:3888;2181
volumes:
- /local/volumn/zookeeper2/data:/data
- /local/volumn/zookeeper2/datalog:/datalog
zookeeper-3:
image: zookeeper
restart: always
hostname: zookeeper-3
ports:
- 2183:2181
environment:
ZOO_MY_ID: 3
ZOO_SERVERS: server.1=zookeeper-1:2888:3888;2181 server.2=zookeeper-2:2888:3888;2181 server.3=0.0.0.0:2888:3888;2181
volumes:
- /local/volumn/zookeeper3/data:/data
- /local/volumn/zookeeper3/datalog:/datalog
其中最重要的是环境变量:
ZOO_MY_ID 一般用一个数字表示 myid
ZOO_SERVERS
抽象出一个公式:server.A=B:C:D
- A 表示 myid,表示服务器的编号
- B 表示代表服务器的 ip 地址
- C 表示服务器与集群中的 leader 服务器交换信息的端口
- D 表示选举时服务器相互通信的端口
有人会说,我不知道这些环境变量怎么办,我也不知道具体的环境变量名呢?
看 Docker hub 上的具体文档啊:
zookeeper docker hub 文档:hub.docker.com/_/zookeeper
- 多节点 kafka:(kafka docker hub 地址:hub.docker.com/r/wurstmeis…)
kfk1:
image: index.docker.io/wurstmeister/kafka:latest
container_name: kfk1
hostname: kfk1
restart: always
ports:
- 9092:9092
- 19999:9999
expose:
- 19092
links:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kfk1:9092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092
JMX_PORT: 9999
volumes:
- /local/volumn/kfk1:/kafka/kafka-logs-kfk1
kfk2:
image: index.docker.io/wurstmeister/kafka:latest
container_name: kfk2
hostname: kfk2
restart: always
ports:
- 29092:29092
- 29999:9999
expose:
- 29092
links:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 2
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kfk2:29092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:29092
JMX_PORT: 9999
volumes:
- /local/volumn/kfk2:/kafka/kafka-logs-kfk2
kfk3:
image: index.docker.io/wurstmeister/kafka:latest
container_name: kfk3
hostname: kfk3
restart: always
ports:
- 39092:39092
- 39999:9999
expose:
- 39092
links:
- zookeeper-1
- zookeeper-2
- zookeeper-3
environment:
KAFKA_BROKER_ID: 3
KAFKA_ZOOKEEPER_CONNECT: zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kfk3:39092
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:39092
JMX_PORT: 9999
volumes:
- /local/volumn/kfk3:/kafka/kafka-logs-kfk3
其中最重要的是以下几个环境变量:
KAFKA_BROKER_ID broker.id 单节点时,默认值为-1
KAFKA_ZOOKEEPER_CONNECT kafka zookeeper 连接地址,对应上文 zookeeper 对外地址
KAFKA_ADVERTISED_LISTENERS 该节点对外公布的访问地址和端口
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:39092 该节点对外访问地址和端口
- 监控节点(kafka-manager docker hub 地址:hub.docker.com/r/sheepkill…)
ui:
image: index.docker.io/sheepkiller/kafka-manager:latest
restart: always
links:
- zookeeper-1
- zookeeper-2
- zookeeper-3
- kfk1
- kfk2
- kfk3
ports:
- 9000:9000
environment:
ZK_HOSTS: zookeeper-1:2181,zookeeper-2:2181,zookeeper-3:2181
KAFKA_BROKERS: kfk1:19092,kfk2:29092,kfk3:39092
其中环境变量:
ZK_HOSTS zookeeper 节点地址
KAFKA_BROKERS kafa 节点地址
启动:
docker-compose -f docker-compose.yml up -d
集群版本的kafka 服务,基本上和单节点的 kafka 服务使用方式一致,集群版本的系统更稳健,高可用,比如冗余备份,一旦一个节点失效了并不影响服务,除非全部节点失效。
- 备份:
创建 topic,备份的数目小于等于 kafka 节点数目。比如三个节点,备份2份,可能在 三个节点上任意两个。
- 分区
单节点,topic 的分区,都在同一个文件夹下;集群版本,分区的大致可以均匀的分布在集群节点上
对外服务,和单节点完全一致。
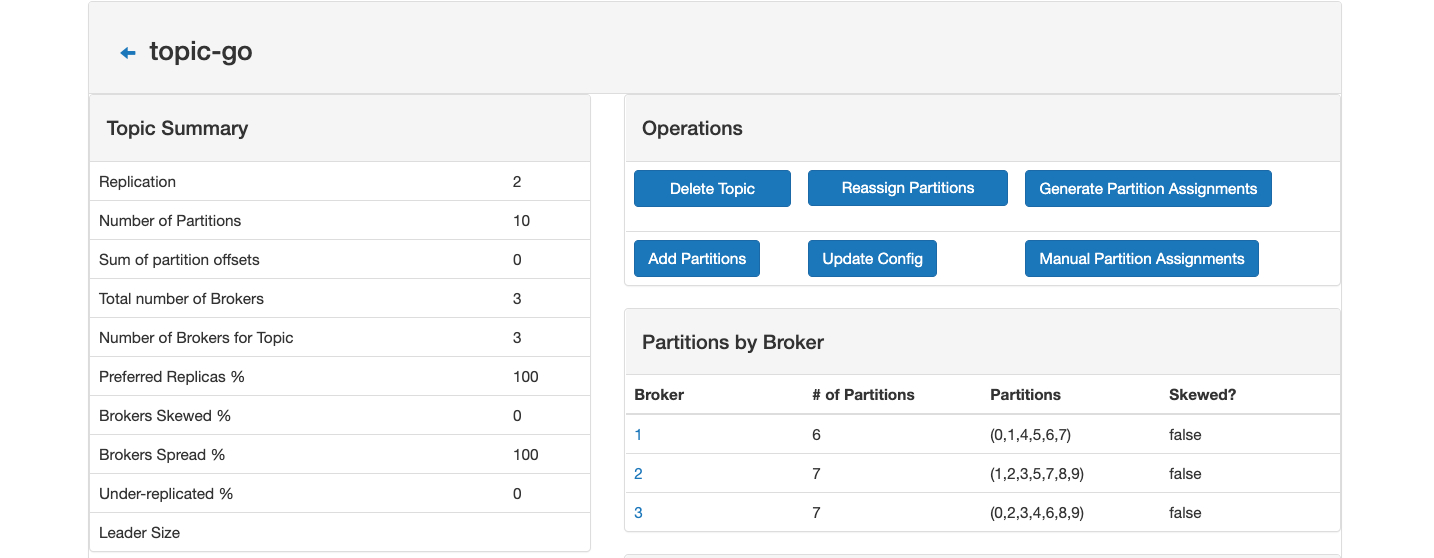
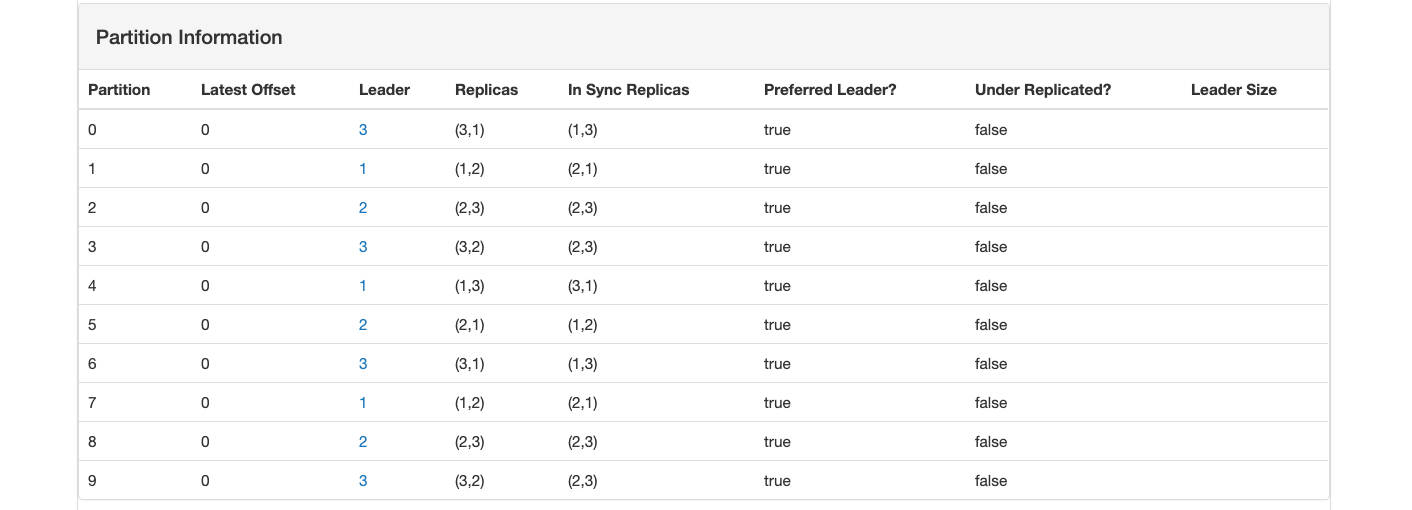
topic-go 10个分区,备份 2 份:三个节点分别存储:6,7,7 个分区
集群版本可能会出现的问题?
-
设置过 不自动创建 topic,记得先手动创建 topic
-
集群访问地址不通。1 设置 /etc/hosts ;2 开放端口,特别是云服务器,记得开放端口
-
消费滞后 Lag, 怎么办?增加消费者实例
参考:
代码地址:
