elasticsearch 安装与基础使用
1、elasticsearch 简介
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java语言开发的,并作为Apache许可条款下的开放源码发布,是一种流行的企业级搜索引擎。ElasticSearch用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。官方客户端在Java、.NET(C#)、PHP、Python、Apache Groovy、Ruby和许多其他语言中都是可用的。根据DB-Engines的排名显示,Elasticsearch是最受欢迎的企业搜索引擎,其次是Apache Solr,也是基于Lucene。
2、为什么要用elasticsearch
3、倒排索引
b树
4、elasticsearch 安装
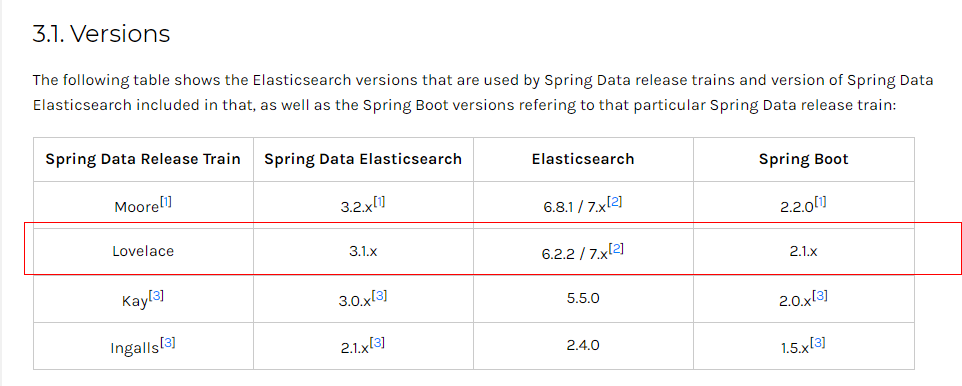
spring data elasticsearch 版本对应关系
elasticsearch

下载完成后解压进入bin文件夹 启动 elasticsearch.bat 即可运行服务
安装 ik分词器
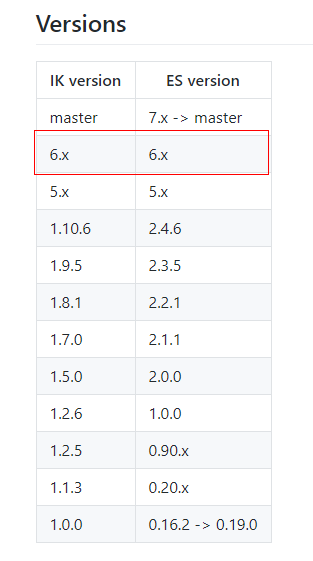
1、下载对应版本的ik分词器
将对应版本的压缩包解压到 elasticsearch 的plugins下
测试是否安装成功 -> 使用ik_smart 或 ik_max_word 对中文能够进行分成表明安装成功
get http://localhost:9200/_analyze
{
"analyzer":"english",
"text":"这是一个非常帅气的小伙"
}
{
"analyzer":"ik_smart",
"text":"这是一个非常帅气的小伙"
}
{
"analyzer":"ik_max_word",
"text":"这是一个非常帅气的小伙"
}
安装 elasticsearch-head 可视化插件
1、启动插件需要使用nodejs
2、由于npm 安装依赖速度实在感人 所以需要安装cnpm 走淘宝镜像
cmd -> npm install -g cnpm --registry=https://registry.npm.taobao.org
安装完成后需要配置环境变量,如果不知道安装到哪里了可以使用以下命令
cmd -> npm config ls
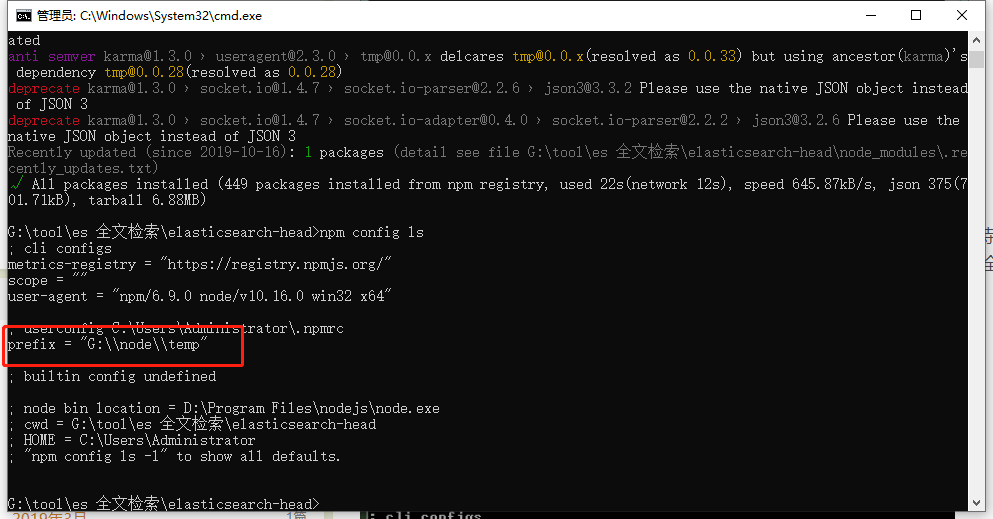
找到路径后配置环境变量即可
3、设置elasticsearch 跨域
找到 elasticsearch config 文件夹下的 elasticsearch.yml 文件增加如下两行
http.cors.enabled: true
http.cors.allow-origin: "*"
4、启动插件
安装依赖
cmd -> cnpm install
启动插件
cmd -> npm run start
启动成功后访问 localhost:9100
5、基于RestApi 的基本命令调用
1、index -> mysql database
新建索引
//test_index :索引名称
//number_of_shards :数据分片数
//number_of_replicas :数据备份数
put http://localhost:9200/test_index/
{
"settings":{
"index":{
"number_of_shards" : 5,
"number_of_replicas" : 1
}
}
}
//获取索引信息
get http://localhost:9200/test_index/_settings
//获取多个索引信息
get http://localhost:9200/test_index,test_index1/_settings
//获取所有索引信息
get http://localhost:9200/_all/_settings
//删除索引
delete http://localhost:9200/test_index
2、文档 -> mysql 数据
//test_index 索引名称
//book type名称
//1 文档ID
//插入文档
put http://localhost:9200/test_index/book/1
{
"title":"spring-boot",
"content":"Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can . We take an opinionated view of ",
"price":50
}
//插入文档自动生成ID
post http://localhost:9200/test_index/book
{
"title":"spring-boot",
"content":"Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can . We take an opinionated view of ",
"price":50
}
//获取文档
get http://localhost:9200/test_index/book/1
//获取指定字段
get http://localhost:9200/test_index/book/1?_source=title,price
//更新文档
put http://localhost:9200/test_index/book/1
{
"title":"spring-boot",
"content":"Spring Boot makes it easy to create stand-alone, production-grade Spring based Applications that you can . We take an opinionated view of ",
"price":500
}
//更新文档仅更新某字段
post http://localhost:9200/test_index/book/1/_update
{
"doc":{
"price":5000
}
}
//删除文档
delete http://localhost:9200/test_index/book/1
3、mapping -> 预先建立索引字段,使建立索引映射使索引更完善
mapping 可定义字段类型
-
字符串型:text、keyword(不会分词)
-
数值型:long、integer、short、byte、double、float、half_float等
-
日期类型:date
-
布尔类型:boolean
-
二进制类型:binary
mapping 可定义字段属性
-
"type" : "text", #是数据类型一般文本使用text(可分词进行模糊查询),keyword无法被分词(不需要执行分词器),用于精确查找
-
"analyzer" : "ik_max_word", #指定分词器,一般使用最大分词:ik_max_word
-
"copy_to" : "field_name", #自定_all字段;指定某几个字段拼接成自定义
-
"index" : true, #该字段是否会被索引和可查询 默认true
-
"null_value" : "NULL", #可以让值为null的字段显式的可索引、可搜索
-
"search_analyzer" : "ik_max_word" ,#查询分词器;一般情况和analyzer对应
-
"store" : true, #默认情况false,其实并不是真没有存储,_source字段里会保存一份原始文档。
对各个属性的测试
//添加映射
put http://localhost:9200/test_index1
{
"settings":{
"index":{
"number_of_shards" : 5,
"number_of_replicas" : 1
}
},
"mappings":{
"books":{
"properties":{
"title":{
"type":"text",
"copy_to":"copyto"
},
"name":{
"type":"keyword"
},
"notindex":{
"type":"text",
"index":false
},
"copyto":{
"type":"text"
},
"content":{
"type":"text",
"analyzer":"ik_max_word",
"search_analyzer":"ik_max_word",
"copy_to":"copyto"
}
}
}
}
}
//插入测试数据
put http://localhost:9200/test_index1/books/1
{
"title":"spring-boot你好",
"name":"spring-boot",
"content":"Spring Boot 这是一本非常好的书 ",
"notindex":"这个是不索引的"
}
//查询title type 为 text 可模糊检索
get http://localhost:9200/test_index1/books/_search?q=title:spring
//查询name type 为 keyword 不可模糊检索
get http://localhost:9200/test_index1/books/_search?q=name:spring
//查询notindex不检索
get http://localhost:9200/test_index1/books/_search?q=notindex:这个是不索引的
//分词查询content
get http://localhost:9200/test_index1/books/_search
{
"query":{
"match":{
"content":"你非常棒"
}
}
}
//copy_to 查询
get http://localhost:9200/test_index1/books/_search
{
"query":{
"match":{
"copyto":"你"
}
}
}
{
"query":{
"match":{
"copyto":"非常"
}
}
}
//获取mapping 信息
get http://localhost:9200/test_index1/_mapping
//获取所有mapping
get http://localhost:9200/_all/_mapping
//删除mapping 由于官方说明不支持多个type 所以无法单个删除_mapping 所以直接删除index 来重建
delete http://localhost:9200/test_index/
4、基本查询
测试数据准备
PUT 127.0.0.1:9200/bookdb_index
{ "settings": { "number_of_shards": 1 }}
put 127.0.0.1:9200/bookdb_index/book/_bulk
{ "index": { "_id": 1 }}
{ "title": "Elasticsearch: The Definitive Guide", "authors": ["clinton gormley", "zachary tong"], "summary" : "A distibuted real-time search and analytics engine", "publish_date" : "2015-02-07", "num_reviews": 20, "publisher": "oreilly" }
{ "index": { "_id": 2 }}
{ "title": "Taming Text: How to Find, Organize, and Manipulate It", "authors": ["grant ingersoll", "thomas morton", "drew farris"], "summary" : "organize text using approaches such as full-text search, proper name recognition, clustering, tagging, information extraction, and summarization", "publish_date" : "2013-01-24", "num_reviews": 12, "publisher": "manning" }
{ "index": { "_id": 3 }}
{ "title": "Elasticsearch in Action", "authors": ["radu gheorge", "matthew lee hinman", "roy russo"], "summary" : "build scalable search applications using Elasticsearch without having to do complex low-level programming or understand advanced data science algorithms", "publish_date" : "2015-12-03", "num_reviews": 18, "publisher": "manning" }
{ "index": { "_id": 4 }}
{ "title": "Solr in Action", "authors": ["trey grainger", "timothy potter"], "summary" : "Compre"}
单字段匹配
get 127.0.0.1:9200/bookdb_index/book/_search
{
"query": {
"match" : {
"title" : "guide"
}
}
}

全字段检索
get 127.0.0.1:9200/bookdb_index/book/_search?q=guide
get 127.0.0.1:9200/bookdb_index/book/_search
{
"query": {
"multi_match" : {
"query" : "guide"
}
}
}
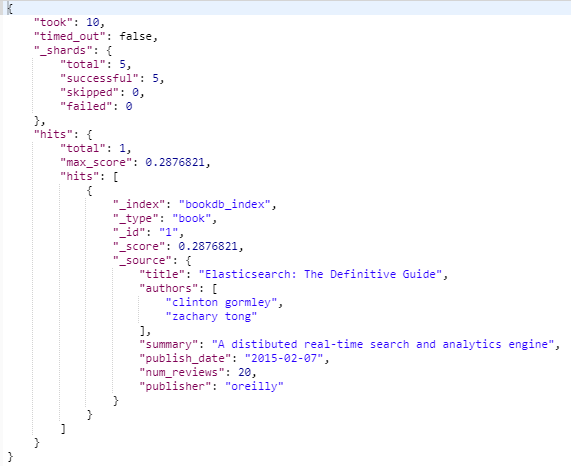
指定多字段任意字段匹配
fields 指定查询字段
{
"query": {
"multi_match" : {
"query" : "guide",
"fields" : ["title","authors"]
}
}
}
字段权重分值并显示指定字段
_source 指定显示字段
{
"query": {
"multi_match" : {
"query" : "elasticsearch guide",
"fields": ["title", "summary^3"]
}
},
"_source": ["title", "summary", "publish_date"]
}

Bool查询
-
must 参数(相当于AND)
-
must_not 参数(相当于NOT)
-
should 参数(相当于OR)
where ((title='Elasticsearch' or title='Solr') and authors='clinton gormely') and authors != 'radu gheorge'
{
"query": {
"bool": {
"must": {
"bool" : {
"should": [
{ "match": { "title": "Elasticsearch" }},
{ "match": { "title": "Solr" }}
],
"must": { "match": { "authors": "clinton gormely" }}
}
},
"must_not": { "match": {"authors": "radu gheorge" }}
}
}
}

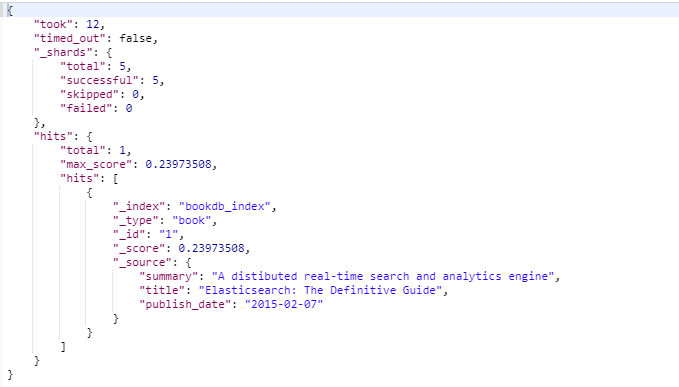
针对拼写错误,模糊查询
fuzziness 表示模糊度,允许错几个字符
{
"query": {
"multi_match" : {
"query" : "engina",
"fields": ["title", "summary"],
"fuzziness": "AUTO"
}
},
"_source": ["title", "summary", "publish_date"],
"size": 1
}
通配符匹配
-
? 匹配任何字符和
-
* 匹配零个或多个字符
-
highlight :关键字高亮
-
查找具有名称以字母“t”开头的作者的所有记录:
{
"query": {
"wildcard" : {
"authors" : "t*"
}
},
"_source": ["title", "authors"],
"highlight": {
"fields" : {
"authors" : {}
}
}
}
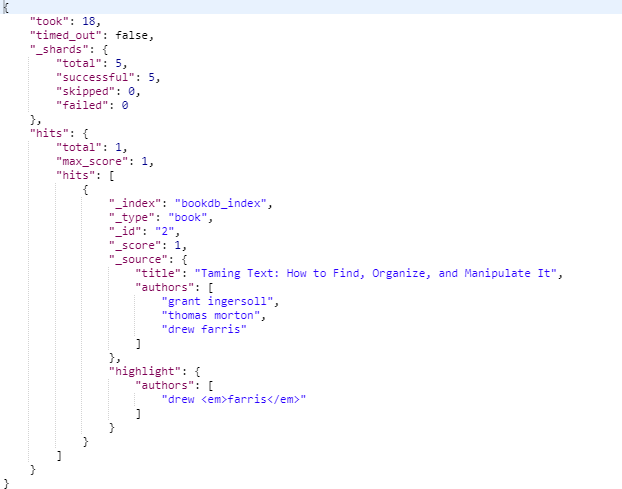
正则匹配
- 查找具有名称以字母t开头y结尾中间任意英文字符的作者的所有记录:
{
"query": {
"regexp" : {
"authors" : "t[a-z]*y"
}
},
"_source": ["title", "authors"],
"highlight": {
"fields" : {
"authors" : {}
}
}
}

短语匹配
-
phrase查询首先解析查询字符串来产生一个分词列表。然后会搜索所有的分词,但只保留包含了所有搜索分词的文档,并且分词的位置要邻接
-
slop:搜索文本的分词,要经过几次移动才能与一个document匹配,这个移动的次数,就是slop
{
"query": {
"multi_match" : {
"query": "search engine",
"fields": ["title", "summary"],
"type": "phrase",
"slop": 2
}
},
"_source": [ "title", "summary", "publish_date" ]
}
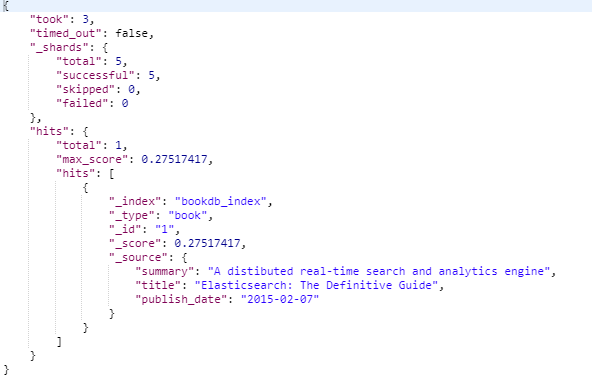
无分词全匹配查询
{
"query": {
"term" : {
"publisher": "manning"
}
},
"_source" : ["title","publish_date","publisher"]
}
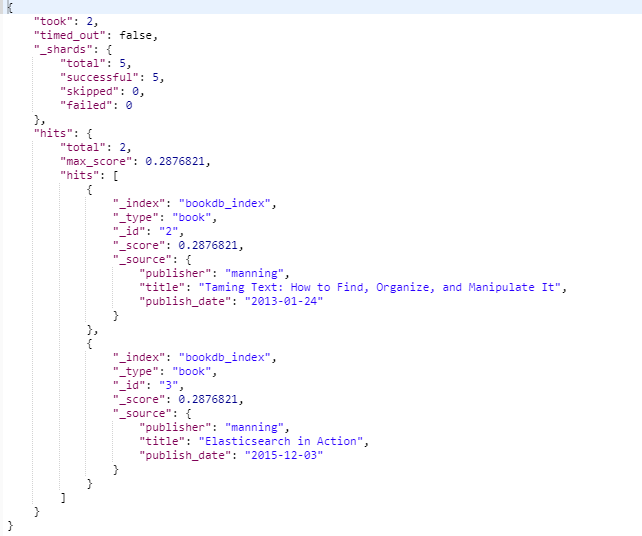
无分词全匹配+排序
- sort 字段排序
{
"query": {
"term" : {
"publisher": "manning"
}
},
"_source" : ["title","publish_date","publisher"],
"sort": [
{ "publish_date": {"order":"desc"}}
]
}
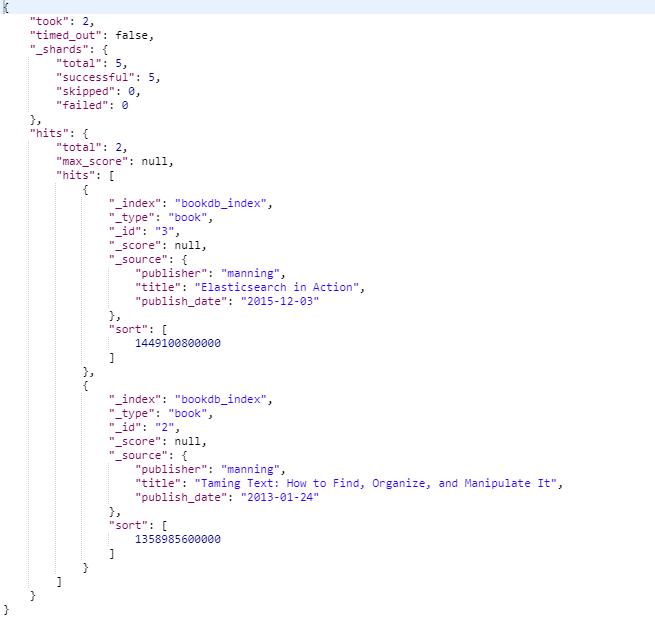
范围查询
{
"query": {
"range" : {
"publish_date": {
"gte": "2015-01-01",
"lte": "2015-12-31"
}
}
},
"_source" : ["title","publish_date","publisher"]
}

postmain 密码查询