

前言
结合Spring Bean加载流程,本文对Spring单例构造器循环依赖及Field循环依赖进行分析。对于构造器循环依赖,目前Spring是无法解决的;Field循环依赖,Spring通过提前暴露实例化Bean及缓存不同阶段的bean(三级缓存)进行依赖排除。网上也有不少一些关于这方面的文章,但作者想从缓存生命周期及多例Bean循环依赖这方面另辟蹊径,深入理解下Spring Ioc的精髓。这是第二篇博文,希望能养成梳理笔记的好习惯。
什么是循环依赖?
循环依赖,简单地说,就是循环引用,两个或者多个 bean 相互之间的持有对方,形成一个闭环。如,A 依赖 B,B 又依赖 A,它们之间形成了循环依赖,又或者是 A 依赖 B,B 依赖 C,C 又依赖 A。可以用一张简图描述这种依赖关系。
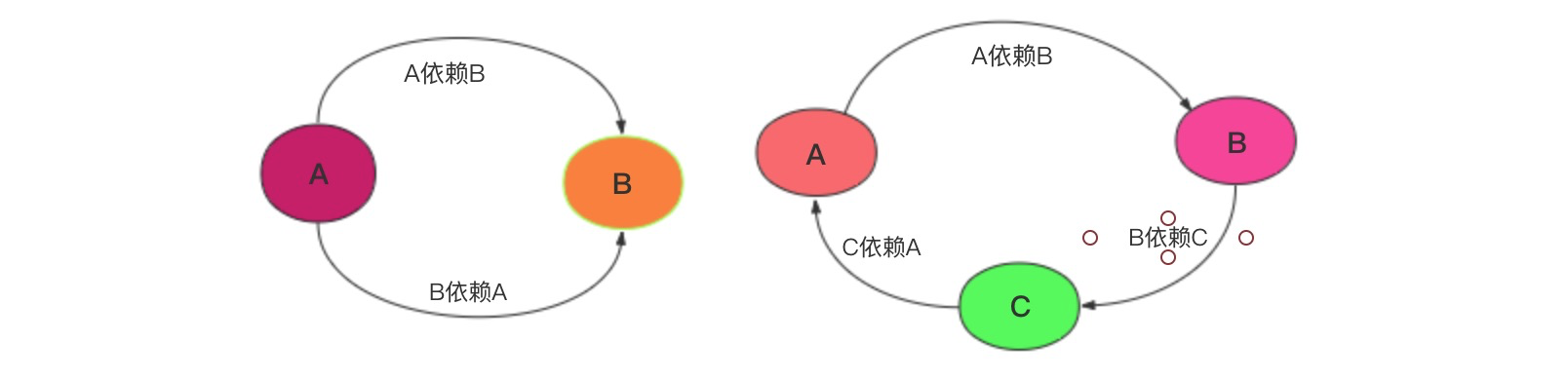
怎么解决循环依赖?
Spring循环依赖的理论依据其实是Java基于引用传递,当我们获取到对象的引用时,对象的field或者或属性是可以延后设置的。接下来,将通过构造器循环依赖及Field循环依赖进行阐述。
Spring Bean加载流程
在分析循环依赖之前我们先回顾下Spring mvc中 Bean加载的流程。
1)项目启动时创建ServletContext实例,将context-param中键值对值存入ServletContext中;
2)当创建Context LoaderListener时,由于监听器实现了ServletContextListener接口,而ServletContextListener提供了监听web容器启动时,初始化ServletContext后的事件监听及销毁ServletContext前的事件监听;因此,contextLoaderListener默认实现contextInitialized和contextDestroyed这两个方法;容器的初始化就是从contextInitialized开始的;
3)首先先创建WebApplicationContext的实例,如果配置了contextClass属性值,则代表配置了相应的WebApplicationContext容器实现类,如果没有配置,默认创建的实例对象是XmlWebApplicationContext;
4)通过contextConfigLocation获取容器加载的配置文件,循环遍历configLocation,调用AbstractBeanDefinitionReader的loadDefinitionBeans方法进行解析并注册,解析的过程主要有以下几个步骤:
-
将xml转换为Document对象,最终调用DefaultBeanDefinitionDocumentReader中的parseBeanDefinitions方法;
-
解析Document中的Node节点,如果是默认的bean标签直接注册(调用的是org.springframework.beans.factory.support.BeanDefinitionReaderUtils#registerBeanDefinition方法,如果是自定义的命名空间标签,获得命名空间后,拿到对应的NamespaceHandler(从spring中的jar包中的meta-inf/spring.handlers属性文件中获取),调用其parse方法进行解析;
-
调用NamespaceHandler的init方法注册每个标签对应的解析器;
-
根据标签名称获得对应的解析器,解析具体的标签; 解析注册这些步骤最终将解析所得的BeanDefinition放入一个map中,这时并没有进行注入。
5)实例化 入口是AbstractApplicationContext#finishBeanFactoryInitialization方法,以getBean方法为入口,先从缓存中获取,如果拿不到时,通过工厂方法或构造器实例化一个Bean,对于构造器我们可以指定构造参数。
6)依赖注入(populateBean) 装配bean依赖,项目中大都使用@Autowired注解,org.springframework.beans.factory.annotation.AutowiredAnnotationBeanPostProcessor#postProcessPropertyValues,这个过程可能进行递归进行依赖注入;最终通过反射将字段设置到bean中。
7)初始化:通过后置处理器完成对bean的一些设置,如判断否实现intializingBean,如果实现调用afterPropertiesSet方法,创建代理对象等;
8)最终将根上下文设置到servletContext属性中;
Spring bean的加载最主要的过程集中在5,6,7这三个步骤中,对应着createBean、populateBean及intializeBean这三个方法上,循环依赖产生在createBean和populateBean这两个方法中。
构造器循环依赖
对于构造器循环依赖,其依赖产生在实例化Bean上,也就是在createBean这个方法。对于这种循环依赖Spring是没有办法解决的。
<bean id = "aService" class="com.yfty.eagle.service.AService">
<constructor-arg index="0" ref="bService"/>
</bean>
<bean id = "bService" class="com.yfty.eagle.service.BService">
<constructor-arg index="0" ref="cService"/>
</bean>
<bean id = "cService" class="com.yfty.eagle.service.CService">
<constructor-arg index="0" ref="aService"/>
</bean>
执行流程
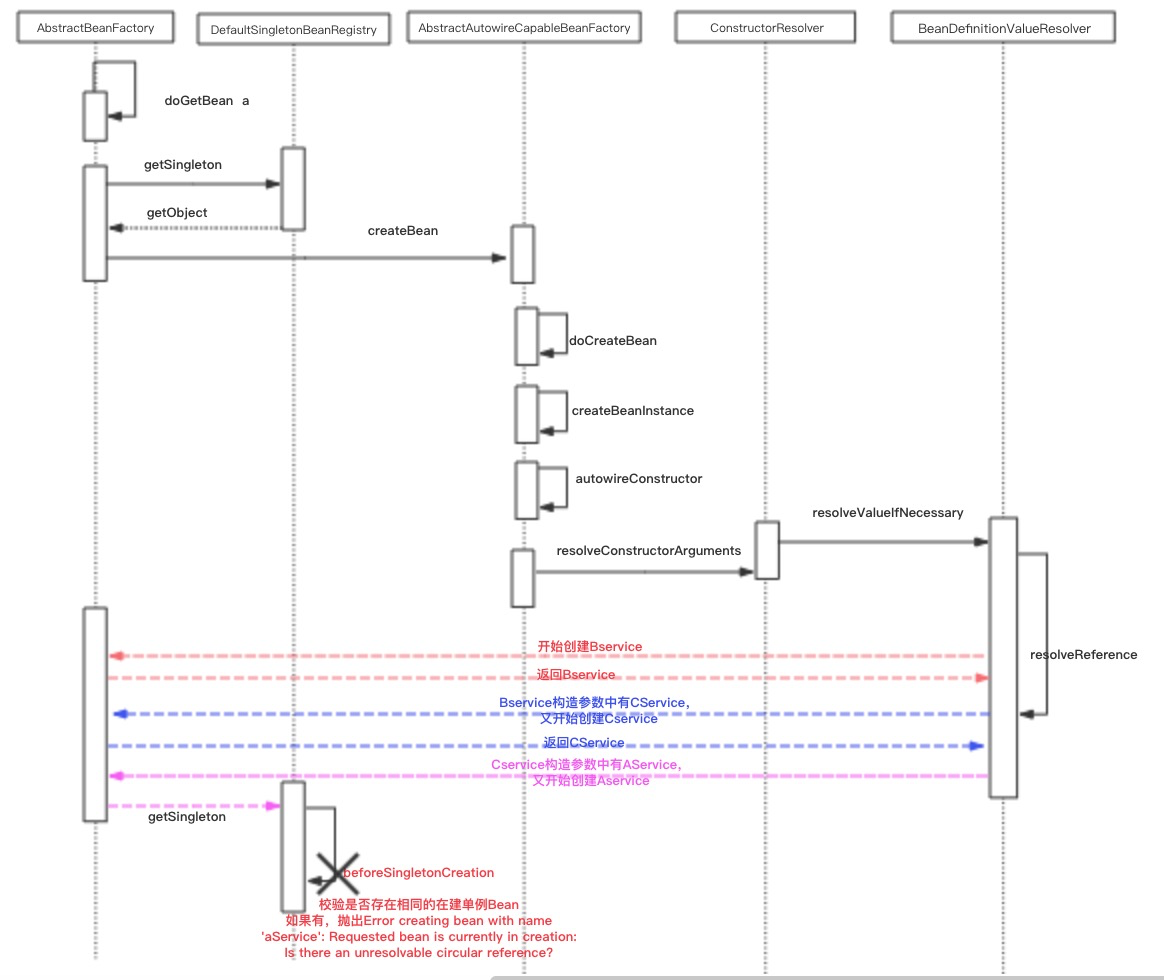
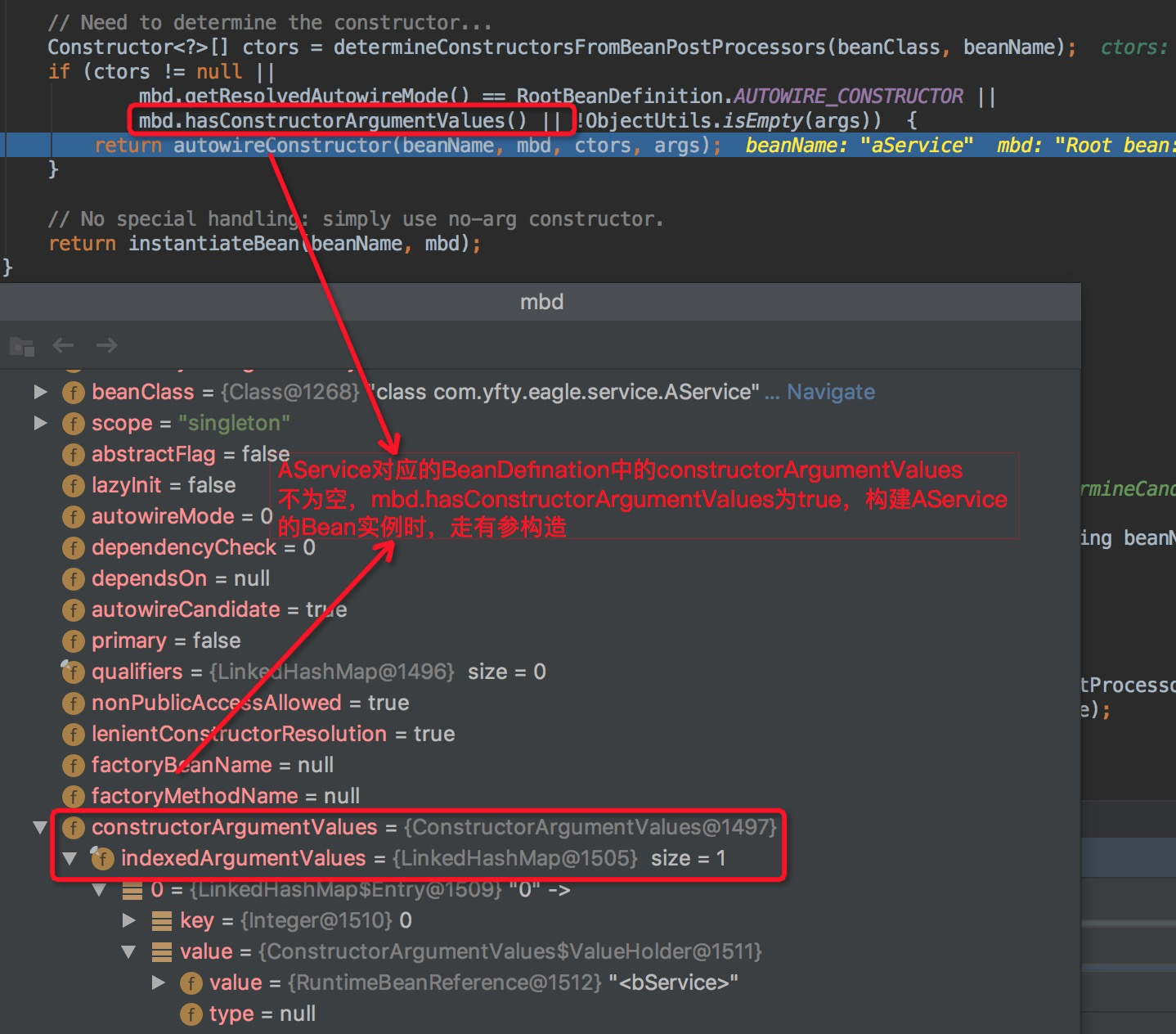
/**
* Callback before singleton creation.
* <p>The default implementation register the singleton as currently in creation.
* @param beanName the name of the singleton about to be created
* @see #isSingletonCurrentlyInCreation
*/
protected void beforeSingletonCreation(String beanName) {
if (!this.inCreationCheckExclusions.contains(beanName) && !this.singletonsCurrentlyInCreation.add(beanName)) {
throw new BeanCurrentlyInCreationException(beanName);
}
}
Field属性或Property循环依赖
在xml文件配置property属性或者使用@Autowired注解,其实这两种同属于一类。下面分析Spring是如何通过提前曝光机制+三级缓存来排除bean之间依赖的。
三级缓存
/** Cache of singleton objects: bean name --> bean instance */
一级缓存:维护着所有创建完成的Bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<String, Object>(256);
/** Cache of early singleton objects: bean name --> bean instance */
二级缓存:维护早期暴露的Bean(只进行了实例化,并未进行属性注入)
private final Map<String, Object> earlySingletonObjects = new HashMap<String, Object>(16);
/** Cache of singleton factories: bean name --> ObjectFactory */
三级缓存:维护创建中Bean的ObjectFactory(解决循环依赖的关键)
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<String, ObjectFactory<?>>(16);
依赖排除
由Spring Bean创建的过程,首先Spring会尝试从缓存中获取,这个缓存就是指singletonObjects,主要调用的方法是getSingleton;如果缓存中没有,则调下Spring bean创建过程中,最重要的一个方法doCreateBean。
protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// 从一级缓存中获取
Object singletonObject = this.singletonObjects.get(beanName);
// 如果一级缓存没有,并且bean在创建中,会从二级缓存中获取
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
synchronized (this.singletonObjects) {
singletonObject = this.earlySingletonObjects.get(beanName);
// 二级缓存不存在,并且允许从singletonFactories中通过getObject拿到对象
if (singletonObject == null && allowEarlyReference) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
// 三级缓存不为空,将三级缓存提升至二级缓存,并清除三级缓存
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
return (singletonObject != NULL_OBJECT ? singletonObject : null);
}
分析: Spring首先从singletonObjects(一级缓存)中尝试获取,如果获取不到并且对象在创建中,则尝试从earlySingletonObjects(二级缓存)中获取,如果还是获取不到并且允许从singletonFactories通过getObject获取,则通过三级缓存获取,即通过singletonFactory.getObject()。如果获取到了,将其存入二级缓存,并清除三级缓存。
如果缓存中没有bean对象,那么Spring会创建Bean对象,将实例化的bean提前曝光,并且加入缓存中。
protected Object doCreateBean(final String beanName, final RootBeanDefinition mbd, final Object[] args)
throws BeanCreationException {
// Instantiate the bean.
BeanWrapper instanceWrapper = null;
......
if (instanceWrapper == null) {
//这个是实例化Bean的方法,会调用构造方法,生成一个原始类型的Bean
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
// 提前曝光这个实例化的Bean,方便其他Bean使用
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
// 满足单例 + allowCircularReferences默认为true + bean在singletonsCurrentlyInCreation集合中时,earlySingletonExposure为true
if (earlySingletonExposure) {
if (logger.isDebugEnabled()) {
logger.debug("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
// 将bean加入三级缓存中
addSingletonFactory(beanName, new ObjectFactory<Object>() {
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
});
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
// 属性注入,这里可能发生循环依赖
populateBean(beanName, mbd, instanceWrapper);
if (exposedObject != null) {
// 初始化bean
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
}
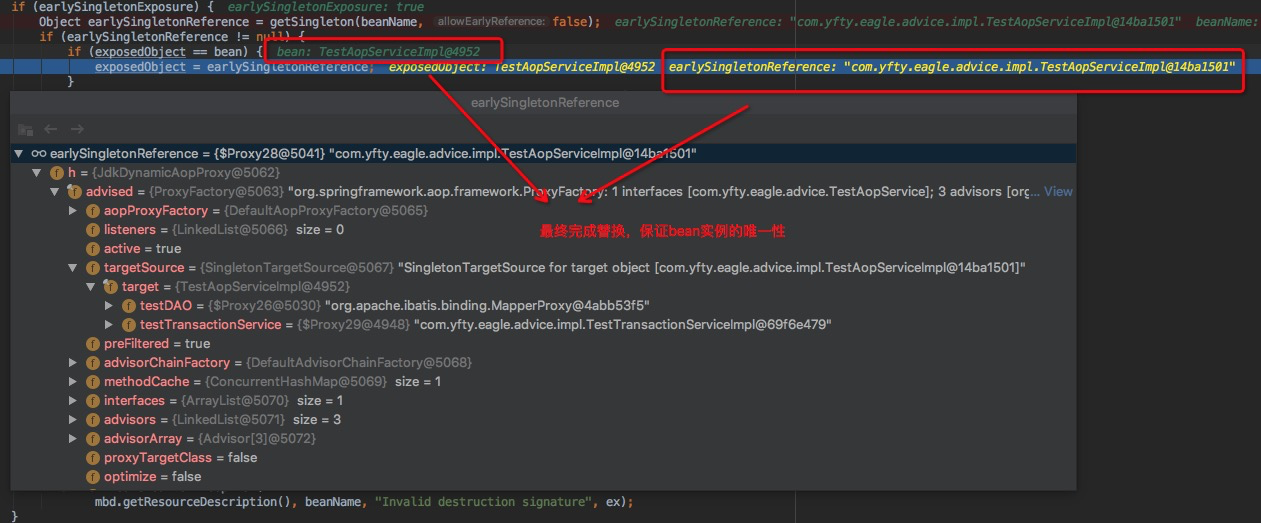
// 由于AService提前暴露,会走这段代码
if (earlySingletonExposure) {
// 从二级缓存中拿出AService(这个对象其实ObjectFactory.getObject()得来的,可能是个包装类,
而exposedObject可能依然是实例化的那个bean,这时为保证最终BService中的AService属性与AService本身
持有的引用一直,故再次进行exposedObject的赋值操作,保证beanName对应实例唯一性。)
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
}
// ...........
return exposedObject;
}
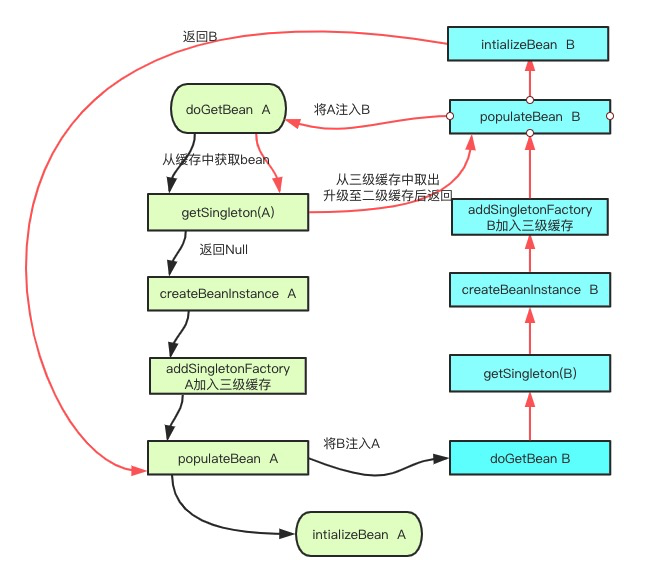
分析: 当通过无参构造,获得一个实例化bean时,Spring会将其提前曝光,即在实例化后注入属性前将其加入三级缓存中。下面以AService和BService相互依赖为例,说明依赖排除过程。
- AService实例化后,在注入属性前提前曝光,将其加入三级缓存singletonFactories中,供其他bean使用;
- AService通过populateBean注入BService,从缓存中获取BService,发现缓存中没有,开始创建BService实例;
- BService实例也会在属性注入前提前曝光,加入三级缓存中,此时三级缓存中有AService和BService;
- BService在进行属性注入时,发现有AService引用,此时,创建AService时,会先从缓存中获取AService(先从一级缓存中取,没有取到后,从二级缓存中取,也没有取到,这时,从三级缓存中取出),这时会清除三级缓存中的AService,将其将其加入二级缓存earlySingletonObjects中,并返回给BService供其使用;
- BService在完成属性注入,进行初始化,这时会加入一级缓存,这时会清除三级缓存中的BService,此时,三级缓存为空,二级缓存中有AService,一级缓存中有BService;
- BService初始化后注入AService中,AService进行初始化,然后通过getSingleton方法获取二级缓存,赋值给exposedObject,最后将其加入一级缓存,清除二级缓存AService;
从上述分析可知,singletonFactories即三级缓存才是解决循环依赖的关键,它是一个桥梁。当AService初始化后,会从二级缓存中获取提前暴露的对象,并且赋值给exposedObject。这主要是二级缓存的对象earlySingletonReference可能是包装类,BService持有的引用就是这个earlySingletonReference,赋值后保证beanName对应实例唯一性,这点回味无穷。
第三级缓存ObjectFactory的作用
我们已经知道了Spring如何解决循环依赖了,但是对于Spring为什么这么设计,总感觉云里雾里,网上的博文大都没有讲这点。下面作者谈下自己的观点。
三级缓存采用工厂设计模式,通过getObject方法获取bean,通过工厂获取bean最终是一个完整的bean,因为getObject这个方法本身就包含了一些生命周期回调的功能,判断是否创建代理类,如果需要就会创建代理类。就循环依赖而言,当BService通过populateBean注入AService时,通过三级缓存可以获取到最终引用地址,这就是AService最终初始化后形成的bean,保证了在循环依赖能获取到真正的依赖。
@Override
public Object getObject() throws BeansException {
return getEarlyBeanReference(beanName, mbd, bean);
}
protected Object getEarlyBeanReference(String beanName, RootBeanDefinition mbd, Object bean) {
Object exposedObject = bean;
if (bean != null && !mbd.isSynthetic() && hasInstantiationAwareBeanPostProcessors()) {
for (BeanPostProcessor bp : getBeanPostProcessors()) {
if (bp instanceof SmartInstantiationAwareBeanPostProcessor) {
SmartInstantiationAwareBeanPostProcessor ibp = (SmartInstantiationAwareBeanPostProcessor) bp;
exposedObject = ibp.getEarlyBeanReference(exposedObject, beanName);
if (exposedObject == null) {
return null;
}
}
}
}
return exposedObject;
}
第二级缓存earlySingletonObjects的作用
既然有了三级缓存了,为什么还要设计二级缓存呢?可能很多人觉得二级缓存是个鸡肋,可有可无,其实这是Spring大量使用缓存提高性能的一点体现。每次都通过工厂去拿,需要遍历所有的后置处理器、判断是否创建代理对象,而判断是否创建代理对象本身也是一个复杂耗时的过程。设计二级缓存避免再次调用调用getEarlyBeanReference方法,提高bean加载流程。只能说,Spring是个海洋。
缓存生命周期
实例化的bean是何时加入缓存中,又是何时将其删除的,它们之间有什么区别呢?接下来,本文会一一作答。
- 三级缓存
当earlySingletonExposure属性为true时,将beanFactory加入缓存;当通过getSingleton从三级缓存中取出实例化的原始bean时或者完成初始化后,并清除singletonFactories中bean的缓存。
- 二级缓存
当earlySingletonExposure属性为true时,将beanFactory加入缓存,当通过getSingleton从三级缓存中取出实例化的原始bean时,此时,将获取的bean加入二级缓存。当完成bean初始化,将bean加入一级缓存后,清除二级缓存;
- 一级缓存
当完成bean初始化,通过addSingleton将bean加入一级缓存singletonObjects中,并且这个缓存是常驻内存中的。
从上述分析可知,三级缓存和二级缓存是不共存的,且其在Spring完成初始化,都会被清除掉。
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, (singletonObject != null ? singletonObject : NULL_OBJECT));
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
总结
- Spring不能解决构造器循环依赖,主要原因循环获取获取构造参数时,将bean存入singletonsCurrentlyInCreation中,在创建bean的前置校验中,发现有已经存在的且相互依赖的bean在创建中,校验不通过,无法创建bean;
- Spring通过提前暴露机制+缓存解决property或field循环依赖,每次获取时,先从缓存中取,取不到时,再进行实例化,实例化后,将其加入三级缓存,供其他bean使用;
- 解决循环依赖中,三级缓存自动升级为二级缓存及bean初始化后,自动清除;在bean完成初始化后,二级缓存将会清除;
- 二级缓存的存在,避免循环依赖中再次通过工厂获取bean这一复杂流程,提升加载效率;
- 最后,作者还想对目前大多数网上所说Spring bean初始化时机进行下补充。目前大多数博文都说bean初始化是在initializeBean这个方法中,固然没错,但作者认为在存在依赖时,属性注入populateBean这个方法本身也存在着bean的初始化,即循环依赖时获取的bean本身就是一个初始化了的bean。
