

前言
Q4 了,秋高气爽适合养生。每天昏昏欲睡的我,今晚突然血气上涌,又来滥竽充数发表 yy 文了😁。
今日份主题:高可用服务!
以下服务案例是以 egg.js 为基础搭建。
理解高可用服务
高可用也就是大家常说的HA(High Availability),高可用的引入,是通过设计减少系统不能提供服务的时间,而不能保证系谢统可用性是能达到100%的🙇♀️!
- 😺不能保证系统可用性是能达到100%的!
- 😺不能保证系统可用性是能达到100%的!
- 😺不能保证系统可用性是能达到100%的!
背景
目前我们公司的服务部署主要分两种,一种是传统的多 ecs 服务器分布式集群,一种是 k8s 托管集群服务。
题主负责的服务大多是以 ecs 部署为主💻,内容展开也是以此为基础。
先看一组图
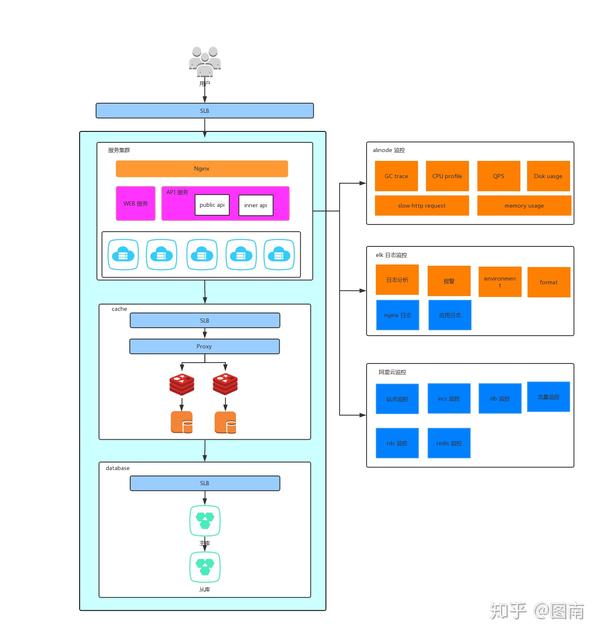
途中反映我们 ecs 应用集群的一个简要架构和监控体系。根据途中的情况,来讲讲我对高可用的一些处理~~😁
高可用的准则
基本上保证服务的高可用遵循两个原则 - 集群化 - 故障自动化处理
集群化主要还是分两类 - 单机进程集群 - 多机集群
集群化的部署本身也是为了规避单点(单进程、单机)故障导致的服务不可用的问题。当集群中某个服务/进程挂掉的时候,该单点所承载的流量会被其他服务/进程分担。
单机进程集群
单机进行多进程集群的部署,当集群中的某一个进程挂掉的时候,应该感知该进程的故障,及时将进程进行清理,流量均摊到其他进程,直到故障进程被重新拉起。
通常我们为了合理利用 cpu 资源,会根据 cpu 核心的数量启动相应数量的进程,但在单核机器上时,cpu 的核心数只有 1,针对单核机器需要做特殊处理。
我们可以通过一个简单的例子将启动命令通过脚本文件进行包装
// scripts/start.js
const os = require('os');
const child_process = require('child_process');
const cores = os.cpus().length;
// 当核心数只有 1 的时候,启动两个 worker 进程,其他情况根据 cpu 核心数启动 worker 进程
const workers = cores === 1 ? 2: cores;
const command = 'npm';
const argv = ['start', '--', `--workers=${worker}`];
const child = child_process.spawn(command, argv);
child.stdout.on('data', (data) => {
console.log(`stdout: ${data}`);
});
child.stderr.on('data', (data) => {
console.error(`stderr: ${data}`);
});
整理一下 package.json 的 scripts
{
"scripts": {
"start": "eggctl start --daemon --title=egg-server-myProject",
"scripts:start": "node scripts/start"
}
}这样子当我们通过指令 npm run scripts:start 来启动服务的时候 ,可以先获取当前机器的 cpu 核心数量来合理启动相应数量的 worker 进程。
多机集群
多机集群的目的是为了防止单机部署的一些不可控因素导致的服务不可用的情况,比如某些意外导致的宕机😣。。。可以及时的将宕机的流量均摊到集群中的其他机器上去。
多机集群通常通过负载均衡让每个节点都分担请求流量。据我了解到的阿里 slb 服务是改造过的 nginx - Tengine。原理和 nginx 实现的负载均衡类似,只是它本身就是高可用的服务,我们不需要去维护这个负载均衡服务。
资源冗余
不要为了省钱而采用够用就好的资源配置💥。当一台 2c4g 的机器能够承载 200qps 的时候,需要对机器的硬件资源做冗余,比如升级成 4c8g。否则当某个节点突然请求量上升,或系统本身服务在做一些处理比如日志轮转的时候,会造成资源竞争,导致一些不可控的问题。
关于资源冗余的点,ecs 部署相对于 k8s 来说,确实是属于资源编排相对浪费的的部署方式。
keepalived
在负载均衡(slb)中,通过 健康检查 检测服务器的工作状态,如果该服务器出现故障被检测到,将其剔除服务器群,直至正常工作后,自动检测到并加入到服务器群里面。
预发布
通常的测试环境与线上环境存在一些差异,可能会规避掉一些上线部署的风险😨。😖为了能保证代码上线能正常启动服务,应该预留一个与线上几乎一致的内部环境(网络,依赖,配置信息等)- 我们姑且称之为预发机器,先进行代码的预发布流程。当服务在预发机器能正常工作后,才将代码往线上发布。
版本迭代的平滑
互联网时代的发展是迅速的,需求每天都在变化。新的需求每天都在产生🔪,服务本身不会保持一成不变。我们每天都有大量的需求更新和 bug😣 fix 上线。
保证代码发布的平滑,是高可用中不可缺少的一环,对于 egg.js 服务集群如何做平滑重启,可以参考我之前发表的文章😁
api 过渡
通常随着版本的长期迭代,旧的 api 可能已经不满足业务需求,需要对 api 进行升级,这个时候新旧 api 是不兼容的🤔。
当新旧 api 进行切换的时候,会产生某些业务还依赖旧的 api,如果直接将旧的 api 进行改造,很可能对某些业务带来影响。
出现这种情况,从我们处理的经验上讲,新的 api 已经不兼容旧版本的 api,那么还是会保留旧的 api 接口,另外设计 v2 版本的新 api,保证新 api 在上线的时候,新旧 api 共存,直到业务方改造完毕,才废除旧版本的 api🙋。
服务降级
在突发大流量的情况下,可能会导致服务整体质量下滑的情况。这时候可以做服务降级来关闭一些不重要的服务来降低资源消耗。
对于服务降级的方案,我的考虑是这样的
- 统一的分布式开关,由配置中心(如 apollo)管理;
- 服务接入开关,并在一些非关键部位/接口上引入开关。接口方面可以通过中间件做开关;
- 操作配置中心的开关项,可以动态控制开关;
- 服务被通知开关变更,及时修改内部接口开关;
监控
前瞻性的监控预警是对服务高可用的一个保障。多维度的监控警报可以在故障的第一时间将问题抛到相应的负责人手上处理🐛。
监控的方式有很多,基础的监控有依赖阿里的云监控,rds、redis、ecs 等监控。
node 相关服务可以使用 alinode 做一些应用/主机级别的监控。
可选的一些监控体系如 elk 日志监控,sentry,opentracing 慢链路监控等。
总结
总之保证服务的高可用,简单的一句话就是不要把鸡蛋都放在一个篮子里,也不要让臭鸡蛋坏在篮子里。
one more thing
最后,该来的还是要来😁
如果你也对 eggjs,对 nodejs,对 js 有兴趣,有想探讨的问题,可以联系我的邮箱📮tunan@gaoding.com。
如果你对我们的工作感兴趣,想和我们一起攻克难关的话,也可以直接将简历发到我的邮箱。
我们有专职的 nodejs 研发工程师,有在厦门具有相当影响力的前端团队,相信喜欢 js 喜欢 nodejs 的你会喜欢我们的团队~
我们是:稿定(厦门)科技有限公司 - 平台技术部
