

puppeteer,相信大家都比较熟悉了,我们可以借助puppeteer调用Chrome DevTools开放的接口与Chrome通信,从而实现交互模拟和dom元素操作。
而puppeteer和Headless Chrome是绝配,可以实现挺多有意思的功能,例如爬虫。
当然,关于puppeteer的使用以及爬虫的功能实现,已经有挺多文章了,那么本文要讲的是:
- 爬虫实现简介
- 亚马逊爬取踩坑
- 上线实践
实现简介
const browser = await puppeteer.launch({
headless: true // 无界面模式
});
const page = await browser.newPage();
// 跳转某个页面,即用浏览器打开某个页面
await page.goto('url')
// 等待条件成熟后(例如某个元素加载完成),在该页面进行相关操作
page.waitForFunction(() => !!document.querySelector('button'))
// 点击按钮并进行跳转
await Promise.all([
page.waitForNavigation(),
page.click('xxx')
])
// 跳转完成,往新页面文本框中填入相关内容
await page.type('input', 'xxxxxxx')
上面这段代码,简单介绍了打开页面(url),等待按钮(button)加载完成后,点击按钮进行页面跳转,然后在新页面的文本框输入内容的过程。具体的api文档,可点击此处查看
亚马逊爬取踩坑
看完上述的简介,我们发现,多亏puppeteer,我们可以如此方便的实现一些模拟交互和chrome api调用。ok,心动不如行动,先拿亚马逊开刀(说错了,是coding)。用代码实现亚马逊收货地址更改,大致要进行的操作如下:
- 打开amazon.com
- 如下图所示,按顺序点击标号1,2,3,进行zip code修改(例如原来是中国,输入:53969,改写成美国的)
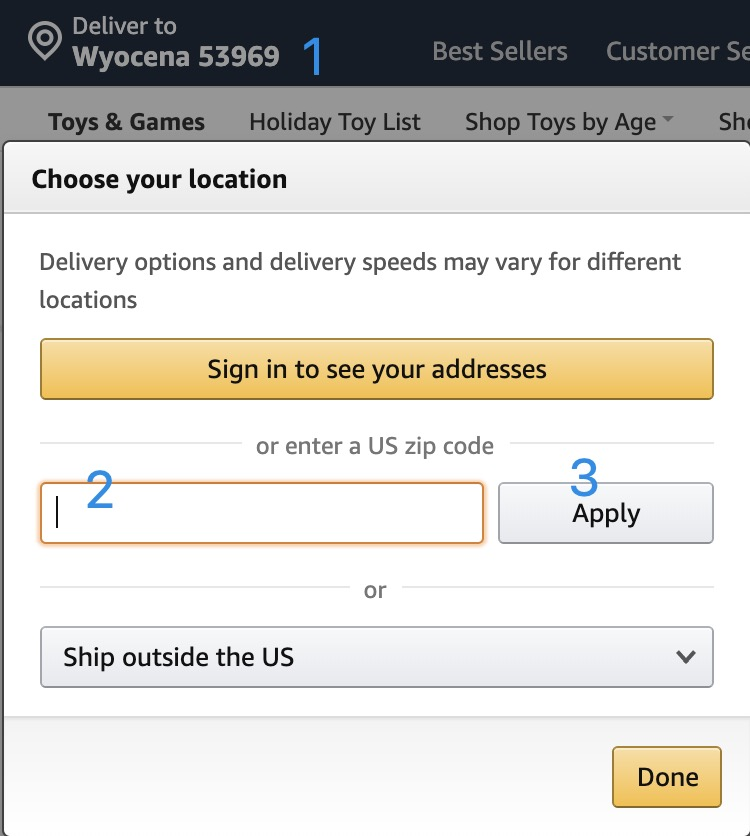
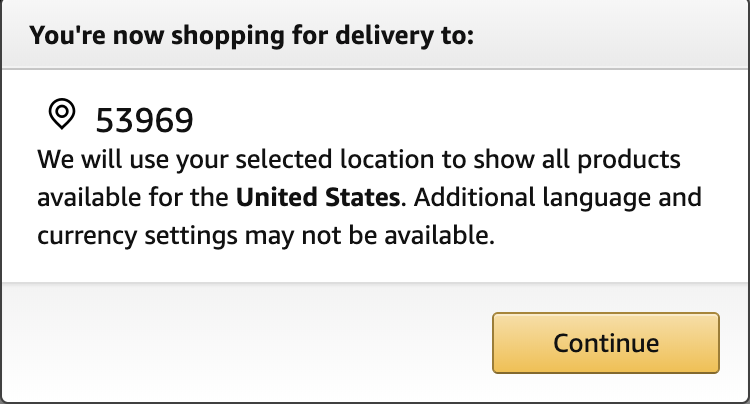
- 步骤三,如下图所示,点击图中按钮(continue),完成收货地址更改
puppeteer有一定的了解的读者,上述流程看来并不复杂,所以建议想要练手的读者,可以实操一下(基本的项目搭建,本文没讲,但是网上有非常多的资料,而且也挺简单的,读者可自行查找)。也许你会这么实现:
async waitForBtn (page, selector) {
return page.waitForFunction(selector => !!document.querySelector(selector), {}, selector)
}
async handleLocation (page) {
var selector = '#nav-global-location-slot .a-popover-trigger'
await this.waitForBtn(page, selector)
await page.click(selector)
selector = '#GLUXZipUpdateInput'
await this.waitForBtn(page, selector)
await page.type(selector, '53969')
await page.click('#GLUXZipUpdate')
selector = '#GLUXConfirmClose'
await this.waitForBtn(page, selector)
await Promise.all([
page.waitForNavigation(),
page.click(selector)
])
console.log('zip code 切换成功')
}
一切准备妥当后,当你激情满满地运行该代码后,却发现报错了。。。
Error: Node is either not visible or not an HTMLElement
at ElementHandle._clickablePoint (/Users/shellhong/workspace/demo/node_modules/puppeteer/lib/JSHandle.js:217:13)
at processTicksAndRejections (internal/process/task_queues.js:89:5)
at async ElementHandle.click (/Users/shellhong/workspace/demo/node_modules/puppeteer/lib/JSHandle.js:283:20)
at async DOMWorld.click (/Users/shellhong/workspace/demo/node_modules/puppeteer/lib/DOMWorld.js:367:5)
at async Promise.all (index 1)
...此处省略n行
做为一个勇敢的程序员,这种小小的报错那都是家常便饭了,怎么可能难得倒我们。报错信息很清晰,那我们定位吧~~~~(>_<)~~~~
相信,根据报错信息,不难定位出来是Promise.all中的page.click(selector)报的错。
那么,如何解决呢。报错信息说由于该节点不可见或者不是HTMLElement,那么一点一点来验证。
- 第一点,可以通过设置
headless为false,进行界面观察(太快看不清?slowMo参数可以帮到你,具体可以查看api文档)。 - 第二点,打开控制台,如下图

好吧,看起来好像都还ok,不存在什么问题啊。。。怀疑人生中。。。
- 不如加点延时看看效果
- 没办法了,网上搜索一下
- why,why,抓头发。。。
哈哈哈,到此为止吧,不知道你解决了没,下面要公布答案了。

惊不惊喜,意不意外!居然有有两个id一样的节点。。。
所以,解决办法是:
// 修改该行选择器,让其能准确找到对应的节点
selector = '.a-popover-footer #GLUXConfirmClose'
await this.waitForBtn(page, selector)
await Promise.all([
page.waitForNavigation(),
page.click(selector)
])
console.log('zip code 切换成功')
上线实践
经过一波折腾,在本地跑起来了。
接下来,部署上线,收工吃鸡,完美,哈哈哈!
接下来的文章,均是基于该系统版本进行讲解
CentOS Linux release 7.6.1810 (Core)
各种node、pm2、依赖包等的安装,都是手到擒来,就不多说了(可能puppeteer的安装会遇到权限问题,这个比较容易找到相关资料,也不说了)。
接下来,要讲述的,主要是两个运行项目后,会遇到的两个报错以及解决办法。
- No.1
UnhandledPromiseRejectionWarning: Error: Failed to launch chrome!
/demo/node_modules/puppeteer/.local-chromium/linux-609904/chrome-linux/chrome:
error while loading shared libraries: libatk-bridge-2.0.so.0: cannot
open shared object file: No such file or directory
出现上述问题,把chrome运行需要的包都安装到你的服务上即可。当然,你也可以不用一个一个去装或者查询需要什么包,因为接下来这段命令已经为你准备妥当:
yum install pango.x86_64 libXcomposite.x86_64 libXcursor.x86_64 libXdamage.x86_64 libXext.x86_64 libXi.x86_64 libXtst.x86_64 cups-libs.x86_64 libXScrnSaver.x86_64 libXrandr.x86_64 GConf2.x86_64 alsa-lib.x86_64 atk.x86_64 gtk3.x86_64 ipa-gothic-fonts xorg-x11-fonts-100dpi xorg-x11-fonts-75dpi xorg-x11-utils xorg-x11-fonts-cyrillic xorg-x11-fonts-Type1 xorg-x11-fonts-misc -y
- No.2
Error: Failed to launch chrome!
[1028/113500.154204:ERROR:zygote_host_impl_linux.cc(89)] Running as root without --no-sandbox is not supported. See https://crbug.com/638180.
...此处省略n行
这个问题也好解决,献上代码:
const browser = await puppeteer.launch({
headless: true,
args: ['--no-sandbox', '--disable-setuid-sandbox']
});
