

本文使用node.js实现文件分片上传,没有使用node.js的框架。前端使用javascript实现,也没有使用框架。这里用到了mongoDB数据库。(本文代码练习用,非项目)
准备工作
- 安装好node和mongoDB。
- 使用
npm init -y初始化项目。 - 使用
npm install mongodb —save安装上mongodb包。
实现思路
主要的思路就是将文件切片后,分片上传,后端将所有的分片都接收完成后,合并为一个完整的文件。通过<progress>展示上传的进度,当点击暂停的时候,中止所有未完成的请求,当点击继续上传的时候,重新发起请求。
画了一张流程图,如下:
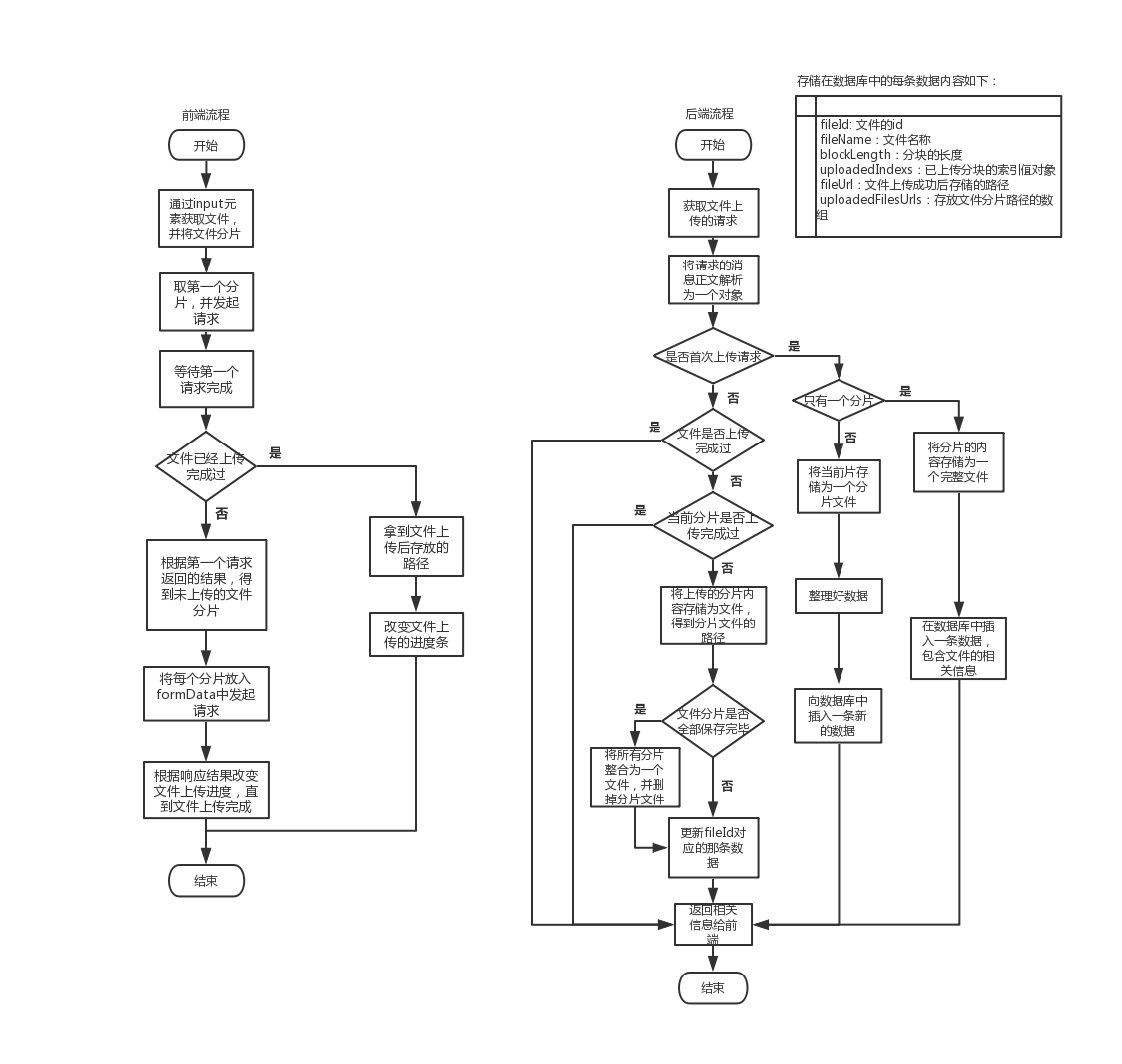
前端:当点击上传文件的按钮的时候,会发起第一个请求,后续的处理需要等待第一个请求完成。因为第一个请求的响应结果中会包含当前文件的上传情况,根据文件上传的情况不同做出相应的处理。
后端:文件的每个分片与其索引值对应。上传到后端后,索引为1的分片存放为文件之后,uploadedFilesUrls数组索引值为1的位置存放的就是已上传的分片文件存放在服务器的路径。当所有分片上传完毕之后,按索引的顺序将分片文件合并为一个整的文件。
前端实现
-
通过输入框选入文件的时候,得到选中的文件,并取文件的信息组成一个字符串,通过这个字符串生成一个
hash值,这个值将作为文件id(这里的id并不是唯一的,后文会说到)上传给后端。这里用到的jsSHA是用于生成一个代表文件的hash字符串的。// 改变当前选中的文件 function changeSelectedFile (event) { let fileUploadElement = event.target; let selectedFile = fileUploadElement.files[0]; // 得到当前选中的文件 globalData.selectedFile = selectedFile; // 使用SHA-512算法生成一个标志文件的hash字符串 const { name, lastModified, size, type, webkitRelativePath } = selectedFile; let fileStr = `${name}${lastModified}${size}${type}${webkitRelativePath}`; let shaObj = new jsSHA('SHA-512', 'TEXT'); // 创建一个jsSHA实例,代表采用SHA-512算法,要转换的数据为文本格式 shaObj.update(fileStr); // 传入要转换的数据 globalData.selectedFileHash = shaObj.getHash('HEX'); // 得到代表文件的hash值 } -
封装一个请求的方法,用于发起请求,上传文件的分片信息。这里使用了
fetch来发起请求,是为了使用async/await以及使用中止控制器AbortController。// 将文件的分片上传 function uploadBlock (body) { const controller = globalData.controller; let url = '/api/uploadFile'; let headersObj = { 'Content-Type': 'multipart/form-data' }; return fetch(url, { method: 'POST', body, headers: new Headers(headersObj), signal: controller.signal // 使用控制器实例的signal标志请求的情况 }).then(res => res.json()) .catch(error => ({ error })) .then(response => ({ response })); }以上代码中的
controller是定义在存放全局变量的globalData对象中的,是AbortController的一个实例,用于在点击“暂停上传”按钮的时候中止所有未完成的请求。let globalData = { ... controller: new AbortController() // 中止控制器的实例 } -
将第一个文件分片整理好后,发起上传请求。
selectedFile是选中的文件,能够直接使用slice方法将文件分片。创建一个FormData实例,将数据放入formData实例中,上传到服务器。这里是点击“上传文件”后发起的第一个请求,需要等待这个请求的完成并根据请求响应的结果做出相应的处理,如上文的流程图中所示。let start = 0, end = blockSize; let blockContent = selectedFile.slice(start, end); let formData = new FormData(); formData.set('fileId', selectedFileHash); formData.set('fileName', fileName); formData.set('blockLength', blockLength); formData.set('blockIndex', 0); formData.set('blockContent', blockContent); const { response } = await uploadBlock(formData); -
请求成功时候的具体处理。拿到请求返回的结果中的
fileUrl和uploadedIndexs,fileUrl是文件上传成功后存放在服务器上的文件的路径,uploadedIndexs是已上传的文件分片的索引。fileUrl存在,说明这个文件已经被上传过了,直接把进度条的值改为100就可以了。否则就根据已上传的分片索引uploadedIndexs得到未上传的分片的索引,调用uploadBlock依次将文件分片上传。if (response.code === 1) { // 请求成功 const { data } = response; const { fileUrl, uploadedIndexs } = data; if (fileUrl) { // 文件已经上传完成过 setProgress(100); } else { let uploadedIndexsArr = Object.keys(uploadedIndexs); // 已上传的分片索引 let allIndexs = Array.from({ length: blockLength }, (item, index) => `${index}`); // 所有分片的索引数组 let notUploadedIndexsArr = allIndexs.filter((item) => uploadedIndexsArr.indexOf(item) === -1); // 没有上传的分片的索引 let notUploadedIndexsArrLength = notUploadedIndexsArr.length; for (let i = 0; i < notUploadedIndexsArrLength; i++) { let item = notUploadedIndexsArr[i]; start = item * blockSize; end = (item + 1) * blockSize; end = end > fileSize ? fileSize : end; let blockContent = selectedFile.slice(start, end); formData.set('blockIndex', item); formData.set('blockContent', blockContent); const { response } = await uploadBlock(formData); const { data } = response; const { fileUrl, uploadedIndexs } = data; if (fileUrl) { setProgress(100); } else { let completedPart = Math.ceil((Object.keys(uploadedIndexs).length / blockLength) * 100); setProgress(completedPart); } } } }以上就是前端的主要代码。
后端实现
-
创建一个简单的
Node.js服务器。因为是练习,所以只创建了一个服务器,请求资源和请求接口都是在这个服务器上。以请求路径是否以/api开头来简单地判断是请求接口还是请求资源。创建一个
MongoClient实例:dbClient,调用dbClient的connect方法连接mongoDB数据库。使用dbClient.db(dbName)连接数据库,mongoDB是数据库对象。通过const collection = mongoDB.collection('documents');连接某个集合,以上的documents是集合名称。通过collection做增删改查的操作,比如向数据库中增加一条数据使用的是collection.insertOne。使用
http.createServer()创建一个服务器,并监听它的request事件。当服务器收到请求的时候,回调函数中的代码就会执行。let mongoDB = null; // 声明一个代表数据库的变量 const MongoClient = require('mongodb').MongoClient; const assert = require('assert'); const dbUrl = 'mongodb://127.0.0.1:27017'; const dbName = 'practice'; const dbClient = new MongoClient(dbUrl, {useNewUrlParser: true, useUnifiedTopology: true}); const serverPort = 8080; const server = http.createServer(); server.on('request', (req, res) => { const { url: requestUrl } = req; let parsedUrl = url.parse(requestUrl); let pathName = parsedUrl.pathname; if (/^\/api/.test(pathName)) { // 以/api开头的表示接口请求 fileUploadRequest(req, res, parsedUrl); } else { // 否则是资源请求 requestResource(req, res, parsedUrl) .catch(err => { handleError(JSON.stringify(err), res) }); } }); server.listen(serverPort, () => { console.log(`server is running at http://127.0.0.1:${serverPort}`); // 连接数据库 dbClient.connect((err) => { assert.equal(null, err); mongoDB = dbClient.db(dbName); console.log('mongodb connected successfully'); }); }); -
以下是对请求资源的处理,根据请求路径,到指定路径下读取文件,文件读取完成后将文件内容展示到浏览器中。
// 请求资源的处理方式 async function requestResource (req, res, parsedUrl) { let pathname = parsedUrl.pathname; let filePath = pathname.substr(1); filePath = filePath === '' ? 'index.html' : filePath; let suffix = path.extname(filePath).substr(1); let fileData = await readFile(filePath); res.writeHead(200, {'Content-Type': `text/${suffix}`}); res.write(fileData.toString()); res.end(); }以上代码中的
readFile是封装后的方法。文件读写,数据库读写等异步操作,都需要进行如下这样简单的封装,这样就能使用async/await了。// 读取文件 function readFile (path) { return new Promise((resolve, reject) => { fs.readFile(path, (err, data) => { if (err) { reject(); } else { resolve(data); } }); }); } -
当
Cotent-Type为multipart/form-data的请求,消息正文是以二进制数据的方式传递的。通过监听data和end事件,拿到消息正文。// 文件上传请求的处理方式 function fileUploadRequest (req, res) { req.on('error', (err) => { handleError(err.message, res); }); let body = []; req.on('data', (chunk) => { body.push(chunk); }); req.on('end', () => { body = Buffer.concat(body); let formattedData = formatData(body); storeFile(formattedData, res); }); }formatData将得到的二进制数据整理为一个对象。消息正文的数据格式如下图,其中fileContent部分是文件的二进制数据。具体的实现方式可以查看源码中的formatData.js文件。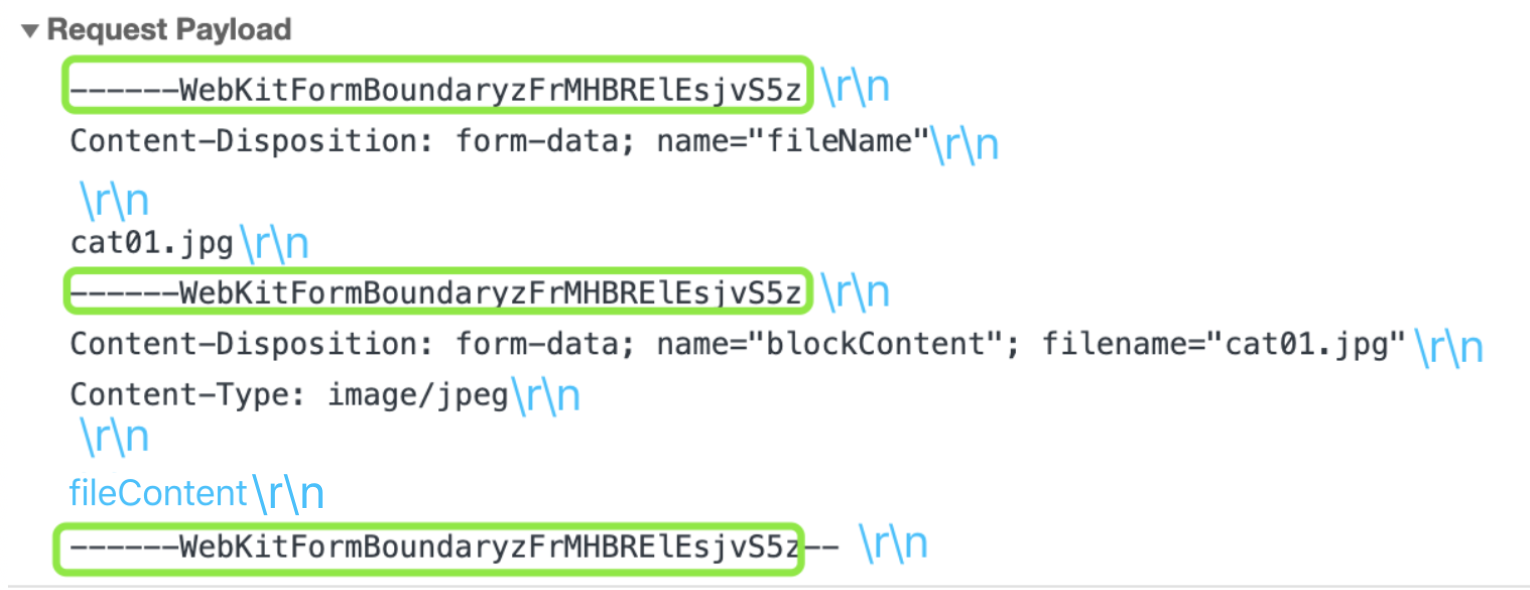
storeFile将文件的分片数据存储为单个文件。 -
storeFile按照上文的流程图对请求信息作出处理。主要部分是当文件不是首次上传的时候的处理。当文件分片全部上传完毕的时候,将分片整合为一个文件,并删除分片的文件。writeFile是和上文的readFile类似的封装的方法,用于将分片数据写成一个文件。通过判断存在数据库中的uploadedIndexs对象的所有关键字数量是否为全部分片的数量来判断分片是否上传完毕。分片上传完毕之后将所有分片合并为一个文件,然后删除所有的分片文件,更新对应的数据上fileUrl的值。let { fileUrl, blockLength, uploadedIndexs, uploadedFilesUrls } = result; if (fileUrl || uploadedIndexs[blockIndex]) { // 文件已经上传完成过或者当前分片已经上传过 handleSuccess(result, res); } else { let path = `./upload/${fileName}.${blockIndex}`; let blockUrl = await writeFile(path, blockContent, false); uploadedFilesUrls[blockIndex] = blockUrl; uploadedIndexs[blockIndex] = true; let blocksUploadCompleted = Object.keys(uploadedIndexs).length === blockLength; if (blocksUploadCompleted) { // 分块上传完毕,将所有分片合成为一个文件,并删除分块文件 let blockFileUrls = uploadedFilesUrls.slice(0); // 复制分片文件路径的数组 let path = `./upload/${fileName}`; let uploadedFileUrl = await combineBlocksIntoFile(uploadedFilesUrls, path); storageData.fileUrl = uploadedFileUrl; await updateData(collection, { fileId }, storageData); blockFileUrls.forEach((item) => { // 删除分片文件 fs.unlink(item, (err) => { if (err) throw err; }); }); handleSuccess(storageData, res); } else { storageData.uploadedFilesUrls = uploadedFilesUrls; storageData.uploadedIndexs = uploadedIndexs; await updateData(collection, { fileId }, storageData); handleSuccess(storageData, res); } } -
combineBlocksIntoFile是合并文件的方法。// 将分片文件合并成一个文件 function combineBlocksIntoFile (uploadedFilesUrls, fileUrl) { return new Promise((resolve) => { let writeStream = fs.createWriteStream(fileUrl); // 在fileUrl的位置创建一个可写流 let readStream; // 定义一个可读流 combineFile(); function combineFile () { if (!uploadedFilesUrls.length) { // 分片已经合并完毕 writeStream.end(); // 在这里结束写入 let uploadedFileUrl = getAbsolutePath(fileUrl); resolve(uploadedFileUrl); } else { let currentBlockUrl = uploadedFilesUrls.shift(); readStream = fs.createReadStream(currentBlockUrl); // 将可读流的数据放在可写流中,第二个参数的设置表示当读取完成后不结束写入,因为需要从多个文件读取 readStream.pipe(writeStream, { end: false }); readStream.on('end', () => { combineFile(); // 在当前分片文件读取完成后重新调用函数 }); } } }); }
问题
遇到的问题:
-
那是一个漆黑的夜晚,为了遍历未上传的分片的索引,并将索引对应的分片上传,写出了以下代码:
notUploadedIndexsArr.forEach(async (item) => { ... const { response } = await uploadBlock(formData); });将
forEach的回调函数定义为async函数。预想是并行发送所有的分片请求,减少用户的等待时间。实际上请求发送的间隔的确为几毫秒,但是分片越多,请求的等待时间就越长。我使用500M每片来划分的时候还好,使用50M每片的时候,直接把浏览器都整卡住了。猜想这是因为本文使用
Node.js搭建的服务器是单线程的,而文件的读取操作是异步的,每个分片上传的时候,我都需要将分片存储为一个文件。拿一个划分成了200个分片的文件来说,这就相当于服务器同时(几毫秒的差异)收到了200个请求,都需要做一些处理,然后将分块数据写为一个文件,因为文件读写操作是异步的,所以fs模块需要一下子将200个请求中拿到的数据写成200个文件,就像一次搬1块砖和一次搬200块砖的差别。解决方法: 使用
for循环,一片一片地上传文件。 -
一开始是将所有文件合并为一个完整的数据之后,写成一个文件,但是因为
Node.js中的Buffer不能容纳超过(2^31)-1约为2GB的数据,报错了。解决方法:使用了
Stream来实现文件合并。
遗留的问题:
-
生成的
hash值并不能唯一代表该文件,因为要生成文件的hash值,需要将文件先转换为ArrayBuffer格式的数据,而当文件很大时,这个过程比较耗时,所以我直接是用文件的一些信息简单组合成字符串后,通过这个字符串生成的hash值。以下为将文件内容转换为hash值的方式:function changeSelectedFile (event) { let fileUploadElement = event.target; let selectedFile = fileUploadElement.files[0]; let reader = new FileReader(); reader.readAsArrayBuffer(selectedFile); // 将文件(Blob数据)转换为ArrayBuffer reader.addEventListener('load', (event) => { let fileArrayBuffer = event.target.result; let shaObj = new jsSHA('SHA-512', 'ARRAYBUFFER'); // 创建一个使用SHA-512算法,输入的数据类型为ARRAYBUFFER的jsSHA实例 shaObj.update(fileArrayBuffer); // 传入要转换的数据 globalData.selectedFileHash = shaObj.getHash('HEX'); // 得到的hash值,输出类型为HEX globalData.selectedFile = selectedFile; }); } -
还有很多情况没有处理。比如说特定的错误没有返回特定状态码,直接统一返回
500了。
ps: 本文的练习使用的谷歌浏览器版本为78.0.3904.70,是当前的最新版,支持async/await;使用的node版本为v10.16.0,也支持async/await。
源码地址。
