

目录
前言
最近参加了一下头条后端工程师的面试, 很惨, 一面就挂掉了.
回来之后也对面试过程做了一些总结,就不夹带私货了,这篇文章主要对面试过程中的技术问题做一个复盘.
1. 求二叉树的最远节点的距离
这是一道 LeetCode 原题, 原题链接
求二叉树的最远距离节点间的节点. 首先总结几个规律:
- 一棵树的直径要么完全在其左子树中,要么完全在其右子树中, 要么路过根节点.
- 一棵树的直径 = 以该树中每一个节点为根节点, 求 路过根节点的最大直径, 所有节点的最大值就是这棵树的直径.
- 求经过根节点的直径, 可以分解为: 求左子树的最深叶子 + 右子树的最深叶子.
所以我们要做:
- 递归的求 每一个节点的 路过根节点的直径(求当前节点的左子树最深叶子和右子树的最深叶子),取其最大值.
- 求某一个节点的最深叶子, 就等于 他的 左子树最深叶子 + 1 和 右子树最深叶子 + 1 的较大值.
- 在求最深叶子的时候, 其实是求出了当前节点直径的(左边最深叶子 + 右边最深叶子 + 2), 为了避免重复计算, 我们在递归求最深叶子的时候, 把直径也记录下来.)
代码如下:
public int diameterOfBinaryTree(TreeNode root) {
AtomicReference<Integer> ret = new AtomicReference<>(0);
find(root, ret);
return ret.get();
}
private int find(TreeNode node, AtomicReference<Integer> result) {
if (node == null) return 0;
int left = 0, right = 0;
if (node.left != null) left = find(node.left,result) + 1;
if (node.right != null) right = find(node.right,result) + 1;
int tmp = Math.max(result.get(), left + right);
result.set(tmp);
return Math.max(left, right);
}
代码很简单, 就是递归的求节点的左子树最远叶子和右子树最远叶子. 然后在 计算过程中, 将 当前节点的直径 作为一个备选项存储,最后求最大直径即可.
2. Java的装箱与拆箱
Java在1.5添加了自动装箱和拆箱机制. 总的来说基本就是基本类型和对应的包装类型之间的自动转换.
如下面的代码中:
public class BoxTest {
public static void main(String [] args){
Integer a = 10; // 装箱
int b = a; // 拆箱
}
}
我们将代码编译之后进行反编译, 可以看到
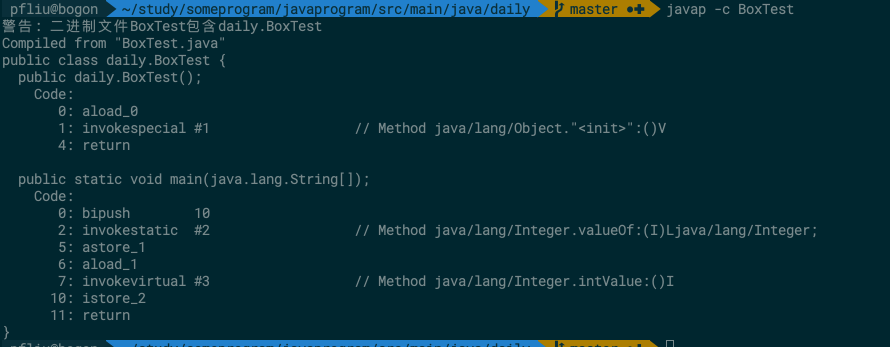
很明显在 代码中的 #2 ,#3 处进行了装箱和拆箱.
分别调用了Integer的 valueOf 方法和intValue 方法.
3. CMS垃圾收集器的收集过程中,什么时候会暂停用户线程?
这里不对所有的垃圾收集器展开讲解, 有兴趣的朋友们可以移步 JVM的数据区域与垃圾收集.
众所周知, CMS的垃圾收集过程如下:
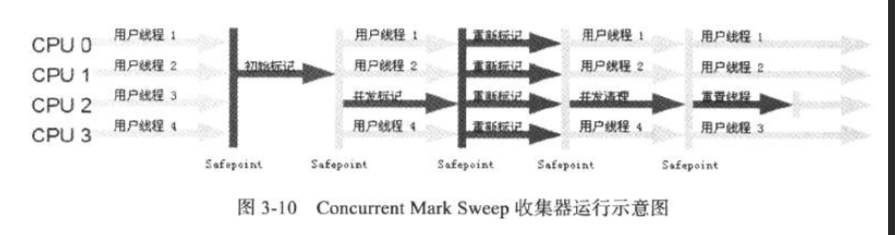
所以在初始标记和重新标记两个阶段还是需要暂停用户线程的.
4. ConcurrentHashMap在读取的过程中为什么不需要加锁?
查看ConcurrentHashMap 的源码可以发现, Node节点的定义是:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
volatile V val;
volatile Node<K,V> next;
}
可以看到, 里面定义了几个属性, 分别如下:
- final修饰的hash值,初始化后不能再次改变.
- final修饰的key,初始化后不能再次改变.
- volatile 修饰的值
- volatile 修饰的下一节点指针
在get(Ojbect)方法的调用过程中.
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
//获取hash值
int h = spread(key.hashCode());
//通过tabat获取hash桶, tabAt是一个线程安全的操作, 有UnSafe来保证的.
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {
//如果该hash桶的第一个节点就是查找结果,则返回
if ((eh = e.hash) == h) {
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//第一个节点是树的根节点,按照树的方式进行遍历查找
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
//第一个节点是链表的根节点,按照链表的方式遍历查找
while ((e = e.next) != null) {
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}
在这个过程中,
- 获取hash桶的根节点, 通过
tabAt来操作, 线程安全. - 遍历的时候用到了node的next属性, 由于其与volatile修饰的, 所以线程间可见,出现并发问题.
- 返回时读取node的volatile属性val.
所以 get 过程中不用加锁也可以正确的获取对象.
5. Redis的字典rehash和JDK中hashmap等rehash有什么不同?
这个问题比较宽泛,我个人的理解有以下两点.
- hashmap rehash的时候的 另外一张table是临时创建的. 而 redis 是时刻保持两张表的引用的. 只是在需要rehash的时候才分配足够的空间.
- hashmap rehash是一次性的,集中的完成rehash过程, 而redis是渐进式hash.
hashmap的rehash过程想必大家都是了解的, 那么这么稍微说一下redis的渐进式hash.
首先, rehash是要将原来表中的所有数据重新hash一遍,存放到新的表格中, 以进行扩容.
而redis是一个单线程的高性能的服务, 如果一个hash表中有几亿条数据, rehash 花费的时间将比较长, 而在此期间, redis是无法对外提供服务的, 这是不可接受的.
因此, redis实现了渐进式hash. 过程如下:
- 假如当前数据在ht[0]中, 那么首先为ht[1]分配足够的空间.
- 在字典中维护一个变量, rehashindex = 0. 用来指示当前rehash的进度.
- 在rehash期间, 每次对 字典进行 增删改查操作, 在完成实际操作之后, 都会进行 一次rehash操作, 将 ht[0] 在
rehashindex位置上的值rehash到ht[1]上. 将 rehashindex 递增一位. - 随着不断的执行, 原来的 ht[0] 上的数值总会全部rehash完成, 此时结束rehash过程.
在上面的过程中有两个问题没有提到:
- 假如这个服务器很空余呢? 中间几小时都没有请求进来, 那么同时保持两个 table, 岂不是很浪费内存?
解决办法是: 在redis的定时函数里, 也加入帮助rehash的操作, 这样子如果服务器空闲, 就会比较快的完成rehash.
- 在保持两个table期间, 该哈希表怎么对外提供服务呢?
解决办法: 对于添加操作, 直接添加到ht[1]上, 因此这样才能保证ht[0]的数量只会减少不会增加,才能保证rehash过程可以完结. 而删除,修改, 查询等操作会在ht[0]上进行, 如果得不到结果, 会去ht[1]再执行一遍.
渐进式hash带来的好处是显而易见的, 他采用了分而治之的思想, 将rehash操作分散到每一个对该哈希表的操作上,避免了集中式rehash带来的性能压力.
与此同时,渐进式hash也带来了一个问题, 那就是 在rehash的时间内, 需要保存两个 hash表, 对内存的占用稍大, 而且如果在redis服务器本来内存满了的时候, 突然进行rehash会造成大量的key被抛弃.
参考文章
《Redis设计与实现(第二版》
完。
ChangeLog
2019-05-19 完成
以上皆为个人所思所得,如有错误欢迎评论区指正。
欢迎转载,烦请署名并保留原文链接。
联系邮箱:huyanshi2580@gmail.com
更多学习笔记见个人博客或关注微信公众号 < 呼延十 > ------>呼延十
