

今天读了Gergely小哥的一篇博客 Visualisation of embedding relations,觉得很有意思,想起了之前在知乎上简答过的一个问题:BERT为什么能区分一字多义?这篇文章就很形象的把BERT的一字多义展现了出来,同时也提出了一种句子表示的可视化方法。
Word2Vec的可视化
Word2Vec的可视化相信大家都见过不少,小哥把man-woman投影到了X轴,poor-rich投影到了Y轴之后得到了下图:
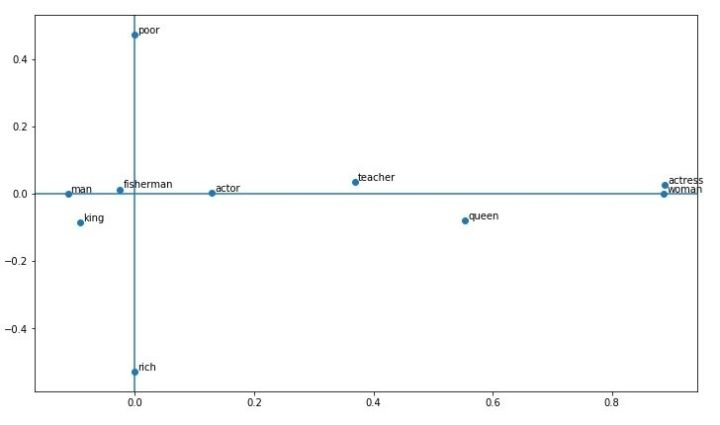
可以看出(以下纯属瞎扯,侵删):
- fishman是有点穷的男人
- king是比较富有的男人,queen是比king穷一些的女人(也没有特别女)
- teacher男女都可以,但是比fishman要穷
- actor是不穷不富的男人,actress是比fishman穷的女人
可见Word2Vec的词向量还是存储了不少东西,但如果teacher是指马老师呢?所以我们需要用BERT,在不同的语境下进行编码(一字多义),马老师就离rich近一些,李老师就离poor近一些。更多Word2Vec的可视化请见TF projector(密恐一定不要点)。
BERT Sentence的可视化
小哥用上一种方法,把[CLS]投影到(1,0),[SEP]投影到(0,1),每个点是一个词,用箭头表示顺序,得到了下图:
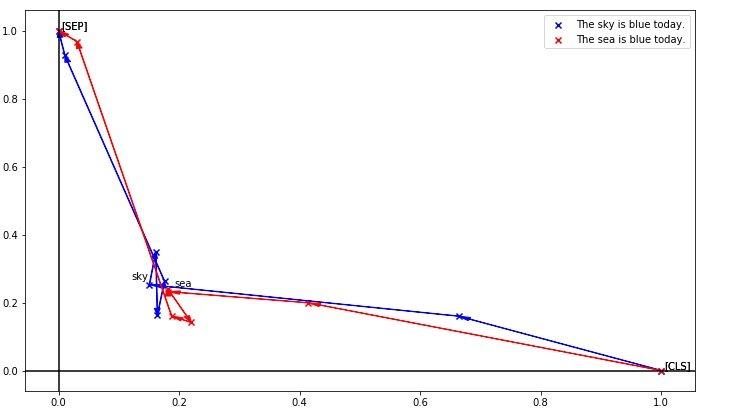
可以看到上下文对sky和sea两个词的影响,因为都是蓝色让两个词更相似了,“海天一色”可能说的就是这个吧。同时也可以看到contextual dependent词向量的一个缺点,就是上下文相似的情况下词向量也很接近。
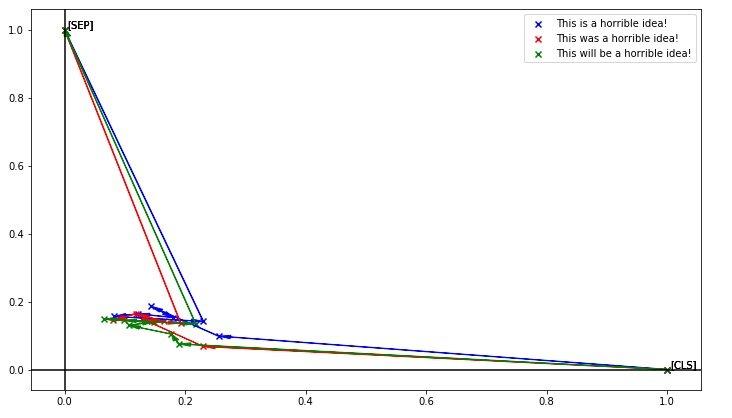
也可以看到动词时态的影响基本不大:
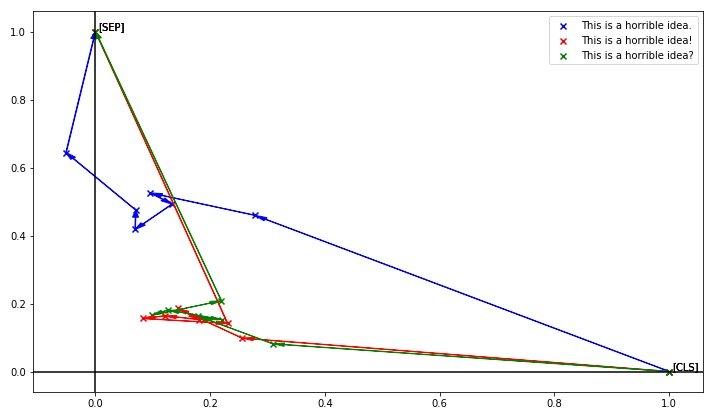
相比之下句末标点符号的影响就很大:
另外再来看一下同一个词Mexico在不同语境下的表示:
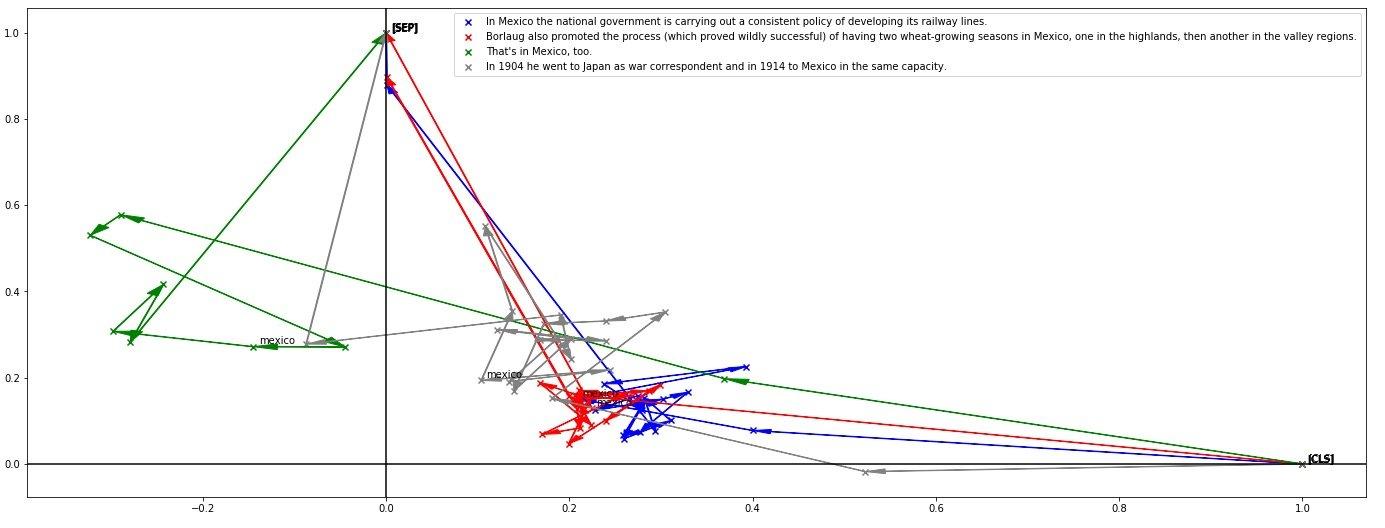
可以发现“That’s in Mexico, too”这句话跑到了-x区域。作者猜想可能是因为这句话更像是一个response,而BERT在预训练阶段的Next Sentence Prediction任务的时候,会把上下句进行拼接:
[CLS] This is the first sentence. [SEP] This is the second one. [SEP]
因此下半句会离[SEP]更近一些。为了验证这个猜想,作者又投影了几句“回复”意图的文本:
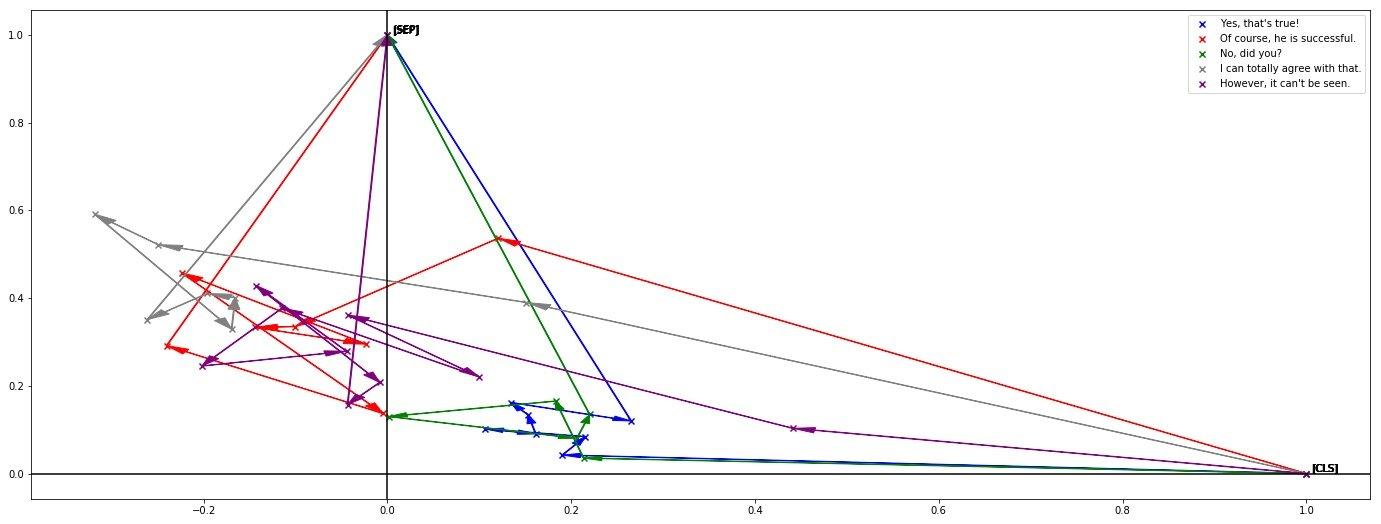
可以看到-x区域的点增多了。
最后,作者验证了一些无意义的错误的句子:
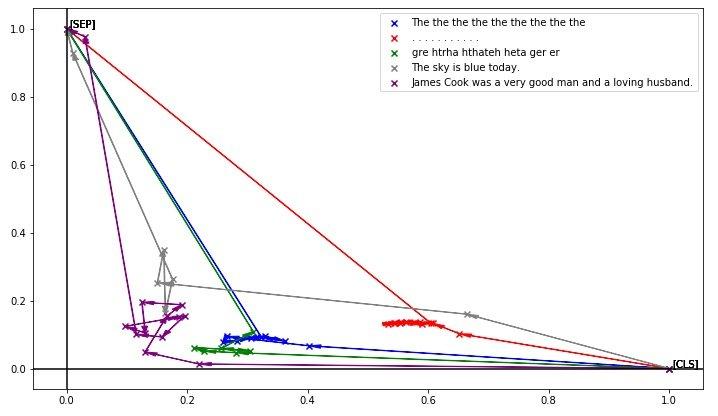
由于句子没有什么意义,各个词向量都堆在一起,有些不知道把自己放哪里的感觉。。。
好啦,这是一篇比较轻松的小文章,日常学习打卡,感谢阅读!!!
hi all!最近终于有了自己的公众号,叫NLPCAB,本来想叫LAB,但觉得和一个人能撑起实验室我就上天了,所以取了谐音CAB,有些可爱并且意味深长?之后会努力和Andy发干货,也希望各位同学投稿学习笔记~

