

本文介绍 Detectron2训练自己的实例分割数据集
Detectron2训练自己的实例分割数据集
This article was original written by Jin Tian, welcome re-post, first come with jinfagang.github.io . but please keep this copyright info, thanks, any question could be asked via wechat:
jintianiloveu
本文介绍如何构造自己的类coco数据集,并用detectron2来训练并预测。实际上detectron2出来已经有几天了。但这个框架个人感觉离真正工业使用还有点距离,首先第一点是不好部署,其次是相关的其他模型导出支持比较差,比如不支持onnx,同时即便是导出的onnx模型也很难用上一些加速框架进行加速,比如不支持TensorRT。但如果你不是追求速度,用python做推理也是可以的,并且最关键的是,你可以用你的数据集训练你的模型,或者是在这个框架上增加一些自己的修改,看看效果是不是更好之类。
首先看看这个如何来训练自己的数据集。我们今天要用的数据是这个:
wget https://github.com/Tony607/detectron2_instance_segmentation_demo/releases/download/V0.1/data.zip
这篇文章很大借鉴于原作者的一些尝试,感兴趣的朋友可以给他github一个star,人家也不容易。这个data是一个非常非常适合来测试分割的一个微型数据集,小到什么程度?只有那么25张图片。。

类别大概是:
cats: [{'supercategory': 'date', 'id': 1, 'name': 'date'}, {'supercategory': 'fig', 'id': 2, 'name': 'fig'}, {'supercategory': 'hazelnut', 'id': 3, 'name': 'hazelnut'}]
(这里date的意思是枣椰子,fig的意思是无花果,hazelnut是榛子。)
如果你下载好了数据,那么基本上我们可以开始了。大家可以看到这个数据集还有一个trainval.json,完全是按照coco的标注方式来标注的。coco的json格式也是目前比较通用的是instance segmentation 或者是Panoptic segmentation标注格式。
Setup Detectron2
关于如何安装detectron2这里不展开叙述,大家可以按照github给予的步骤来。这里给大家几点提醒:
- 要python3.6;
- 要pytorch1.3.
其他的没有了。
训练
首先看一下这个非常小非常迷你的数据集,在100次训练之后的效果:

可以看出来,这个效果还是非常不错的啊。训练的脚本也非常简单:
import random
from detectron2.utils.visualizer import Visualizer
from detectron2.data.catalog import MetadataCatalog, DatasetCatalog
import fruitsnuts_data
import cv2
from detectron2.engine import DefaultTrainer
from detectron2.config import get_cfg
import os
from detectron2.engine.defaults import DefaultPredictor
from detectron2.utils.visualizer import ColorMode
fruits_nuts_metadata = MetadataCatalog.get("fruits_nuts")
if __name__ == "__main__":
cfg = get_cfg()
cfg.merge_from_file(
"../../configs/COCO-InstanceSegmentation/mask_rcnn_R_50_FPN_3x.yaml"
)
cfg.MODEL.WEIGHTS = os.path.join(cfg.OUTPUT_DIR, "model_final.pth")
print('loading from: {}'.format(cfg.MODEL.WEIGHTS))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # set the testing threshold for this model
cfg.MODEL.ROI_HEADS.NUM_CLASSES = 3
cfg.DATASETS.TEST = ("fruits_nuts", )
predictor = DefaultPredictor(cfg)
data_f = './data/images/2.jpg'
im = cv2.imread(data_f)
outputs = predictor(im)
v = Visualizer(im[:, :, ::-1],
metadata=fruits_nuts_metadata,
scale=0.8,
instance_mode=ColorMode.IMAGE_BW # remove the colors of unsegmented pixels
)
v = v.draw_instance_predictions(outputs["instances"].to("cpu"))
img = v.get_image()[:, :, ::-1]
cv2.imshow('rr', img)
cv2.waitKey(0)
大家可能觉得这个instance segmention训练的太容易,那么来挑战难度大一点的?
确实,这个坚果数据集实在是太简单了,简单到我们甚至打印不出任何训练过程,一眨眼模型就训练好了。那就来个难度大一点的吧,我们将用Detectron2训练Cityscapes的实例分割!
Detectron2 训练Cityscapes实例分割
尽管在Detectron2里面有Cityscapes的数据dataloader,但我们并不打算用它,相反,我们觉得使用统一化的coco数据集格式能够更好的让数据fit。当我们决定做这件事情的时候犯难了。如何从Cityscapes转到coco?
好在有这个需求的人不少,这值得我们开发一个工具来转它。我们维护的现成的工具脚本可以在这里找到:
实际上我们将数据转到coco之后,发现效果我们想象的还好,因为这些标注都非常精准,并且包含了我们感兴趣的常用类别,比如car,truck,rider,cyclist,motor-cycle等:

这是可视化的效果。这些步骤与我们上面训练坚果数据集的步骤差不多,大家仿造步骤来,首先可视化数据确保我们的数据是准确无误的。那么接下里的事情就很简单了。

看起来似乎还不错,这些类别众多而精准,接下来开始train:
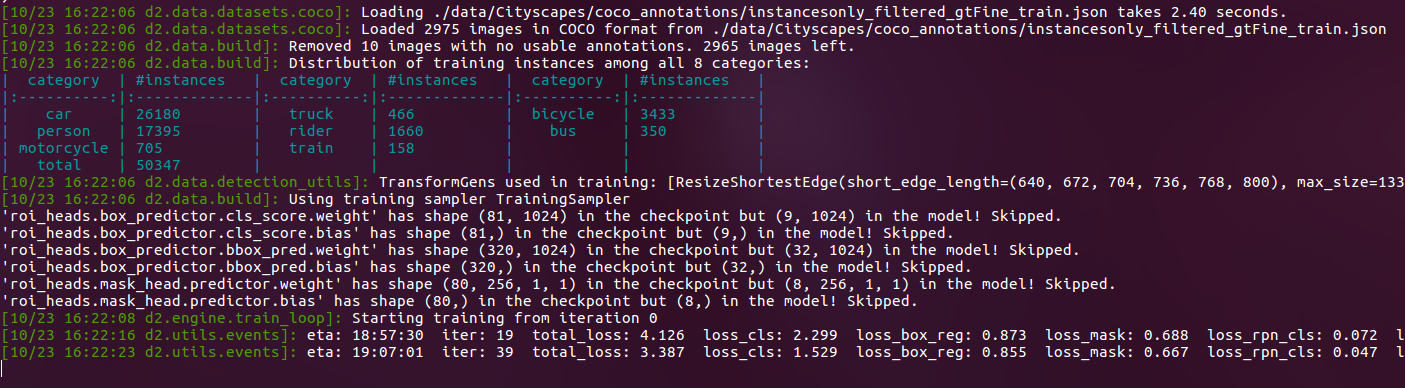
看起来似乎还不错。现在训练一个instance segmentation 简直是太简单了。
那么这个instance segmention模型训练完成之后是一种什么样的效果呢?模型还在训练,我们等下一期技术文章发布之后,给大家分享一下结果,同时,告诉大家一个好消息:
- 类似于MaskRCNN这样的模型速度是很难在实际场景中用起来的,原因也很简单,我们都需要realtime的东西,这速度差强人意,但是否有人尝试更轻便的backbone呢?不得而知,不过好消息是实际上通过一些加速框架,是可以把MaskRCNN加速到realtime的。而这些,我们等到detectron2go发布之后,或许会看得到一些好消息。
本文首发于MANA AI社区,如果你对AI感兴趣,欢迎加入我们的社区一起交流:t.manaai.cn
