

github测试Demo项目地址:github.com/HopeAndStar…
一:概述
官网传送门,需要了解有关超时基础的配置请移步官网,Dubbo的官网绝对良心作品。本文主要的目的是通过简单的Demo论证三个问题:
- 简单的超时配置效果
- 通过多优先级配置论证优先级效果
- 加上重试机制后新增数据接口数据重复问题
二:配置效果
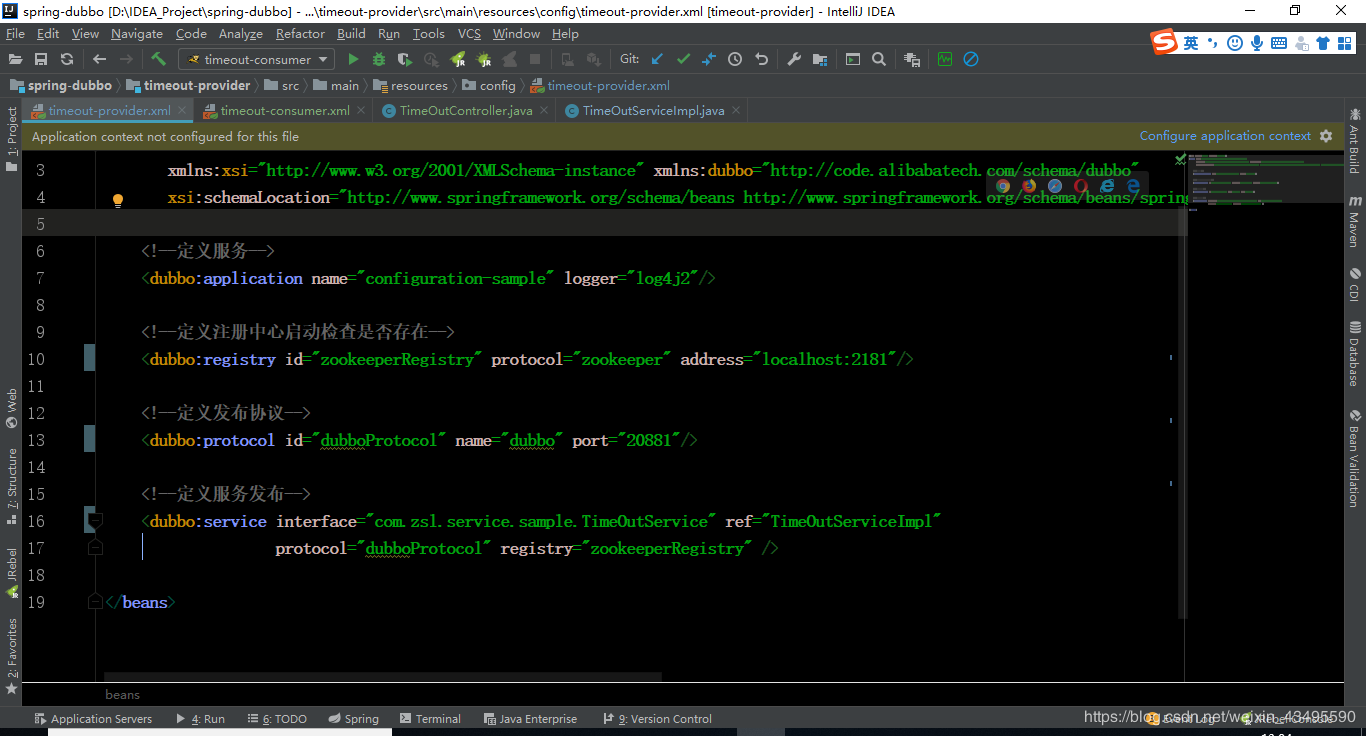
2.1 服务提供者配置
服务提供者配置比较简单,就是正常通过dubbo协议发布服务。这是的超时采用默认配置1000ms也就是1s
2.2 服务消费者配置
消费者通过zookeeper注册中心注入dubbo协议的服务,也没有做任何有关超时属性配置,还是采用默认的超时配置1000ms即1s
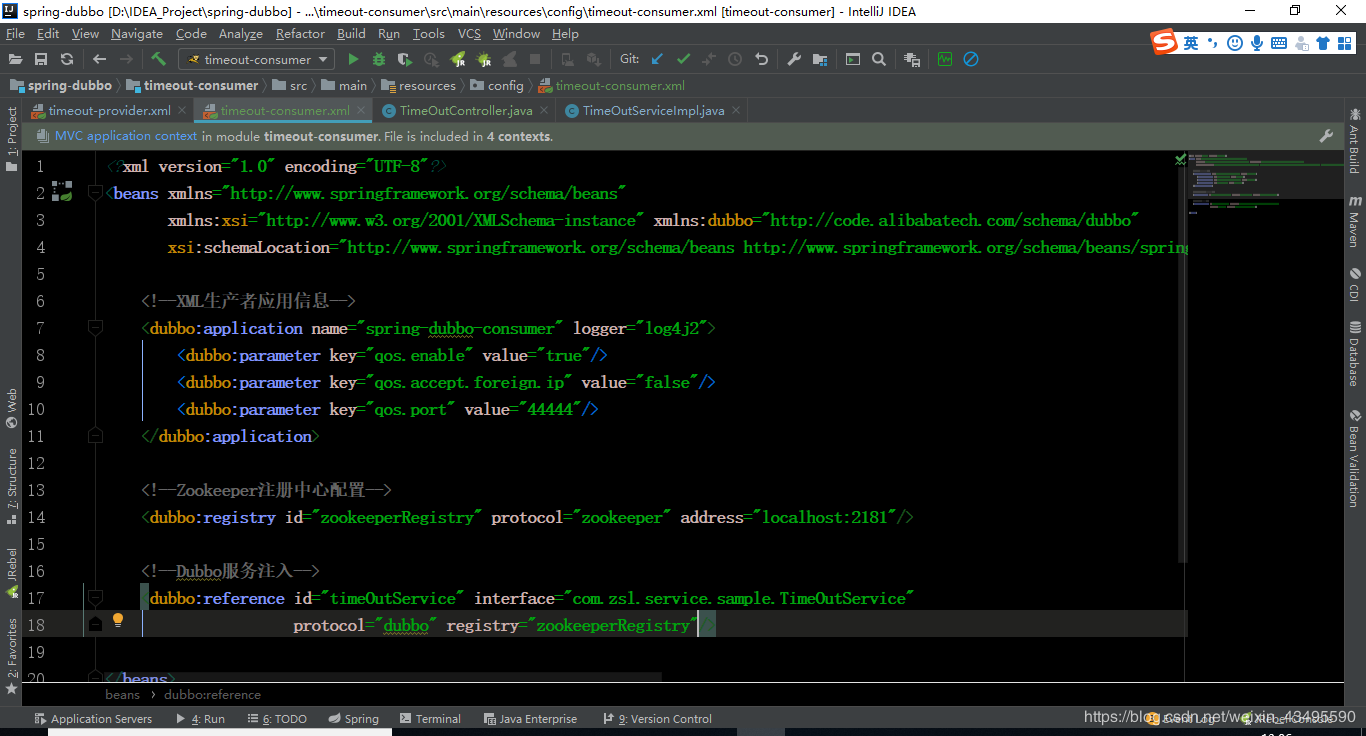
2.3 服务调用与效果
服务调用的时候通过Thread.sleep()让线程睡眠5s模拟服务耗时,睡眠5s超过了消费端与服务端默认配置的超时时长
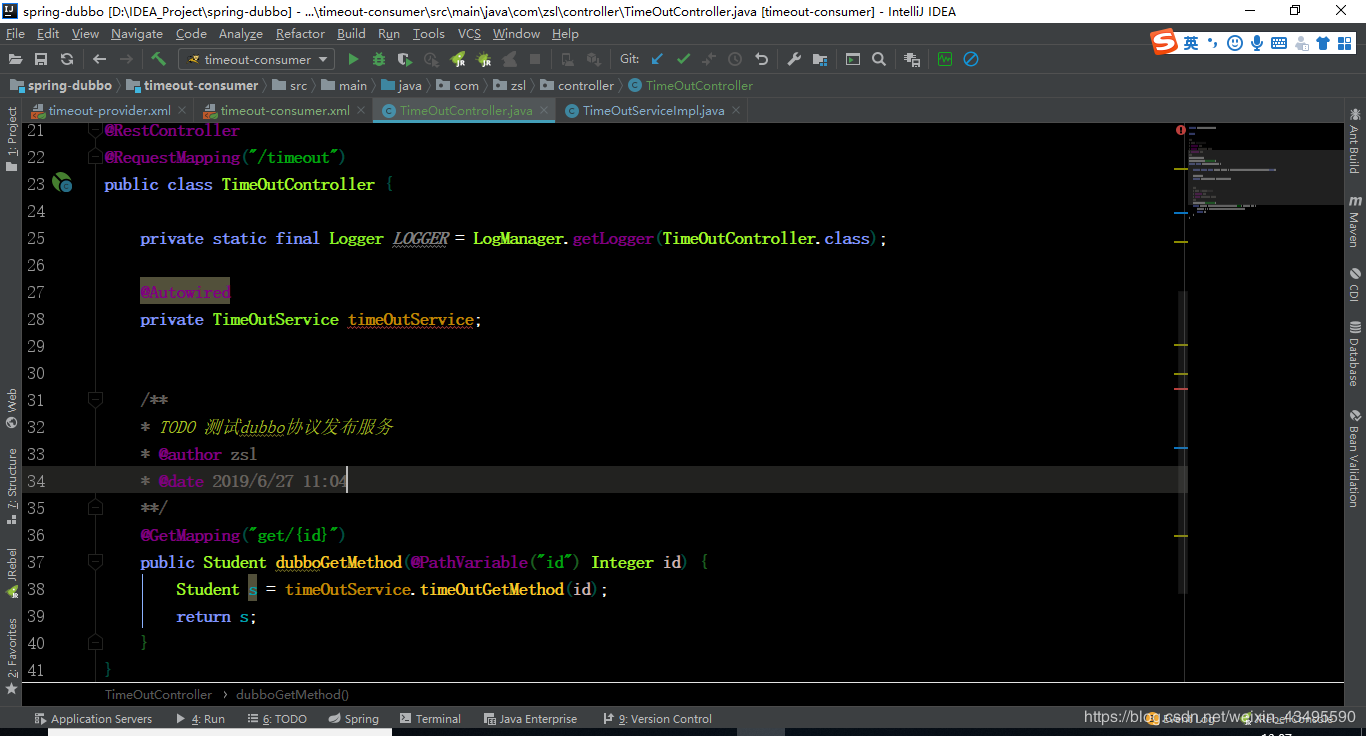
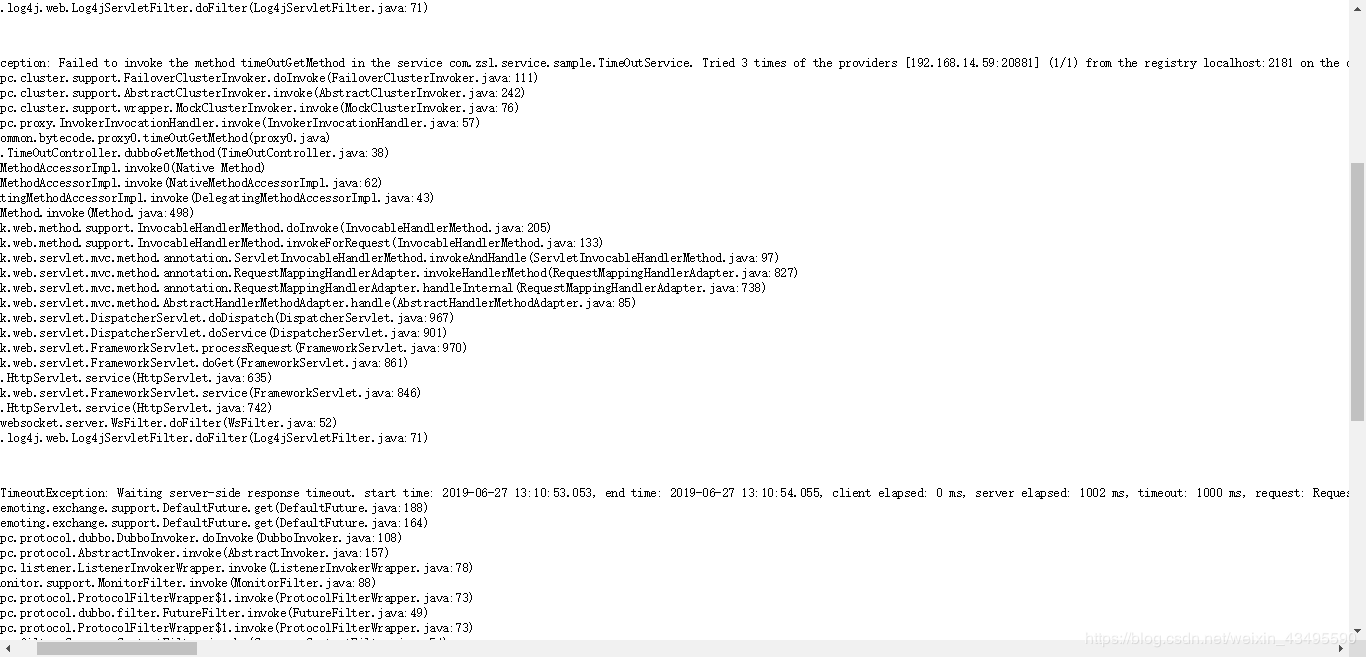
2.4 修改服务端超时配置
服务端暴露服务的时候显示声明服务调用超时时间为10s,保持消费端配置不变
三:配置优先级
超时时限可以在以下几个地方进行配置,官网也说的很清晰,并且给出了优先级示意图。但是在充分信任任何结论前做必要的尝试是一种态度:
- <dubbo:provider>
- <dubbo:consumer>
- <dubbo:service>
- <dubbo:refereence>
- <dubbo:method>
3.1 服务端全局与接口
第二节通过<dubbo:service>配置项在接口层面声明了超时时长,接下来修改一下服务端<dubbo:provider>配置,也就是全局配置超时为3s。看最后结果是否可以正常调用亦或是超时异常
3.2 接口与方法
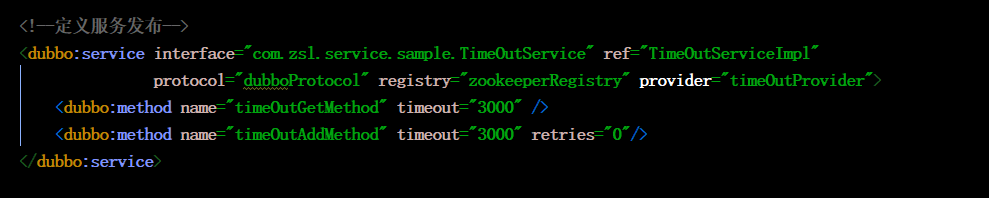
<dubbo:service>标签发布服务是整个接口中所有方法,配置也是针对接口中所有方法。如果想针对某个方法有特殊配置需要采用其子标签<dubbo:method>配置,通过其子标签方法配置超时,查看最后效果
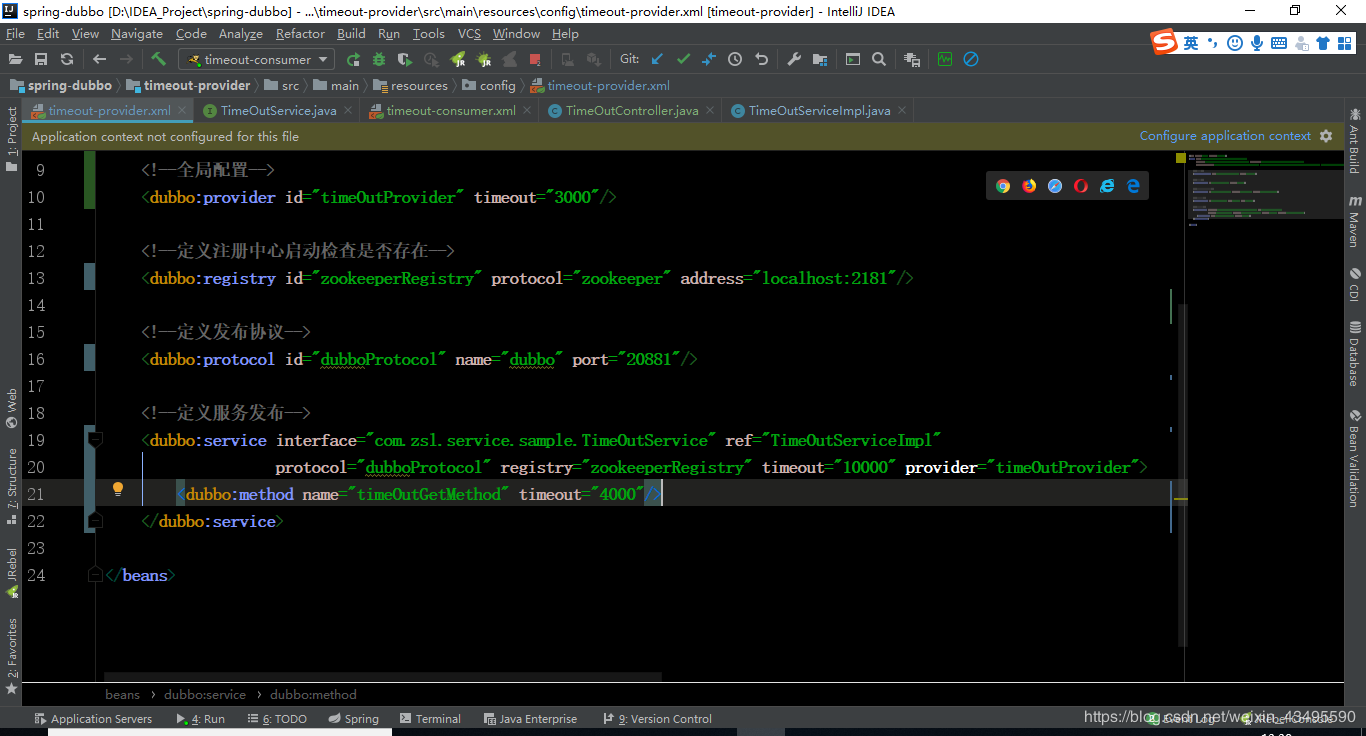
通过配置方法超时为3s,可以看到如下图所示的超时异常TimeoutException信息也是差不多服务端执行了4s左右,也就是方法级别配置覆盖了接口的配置。即方法 > 接口
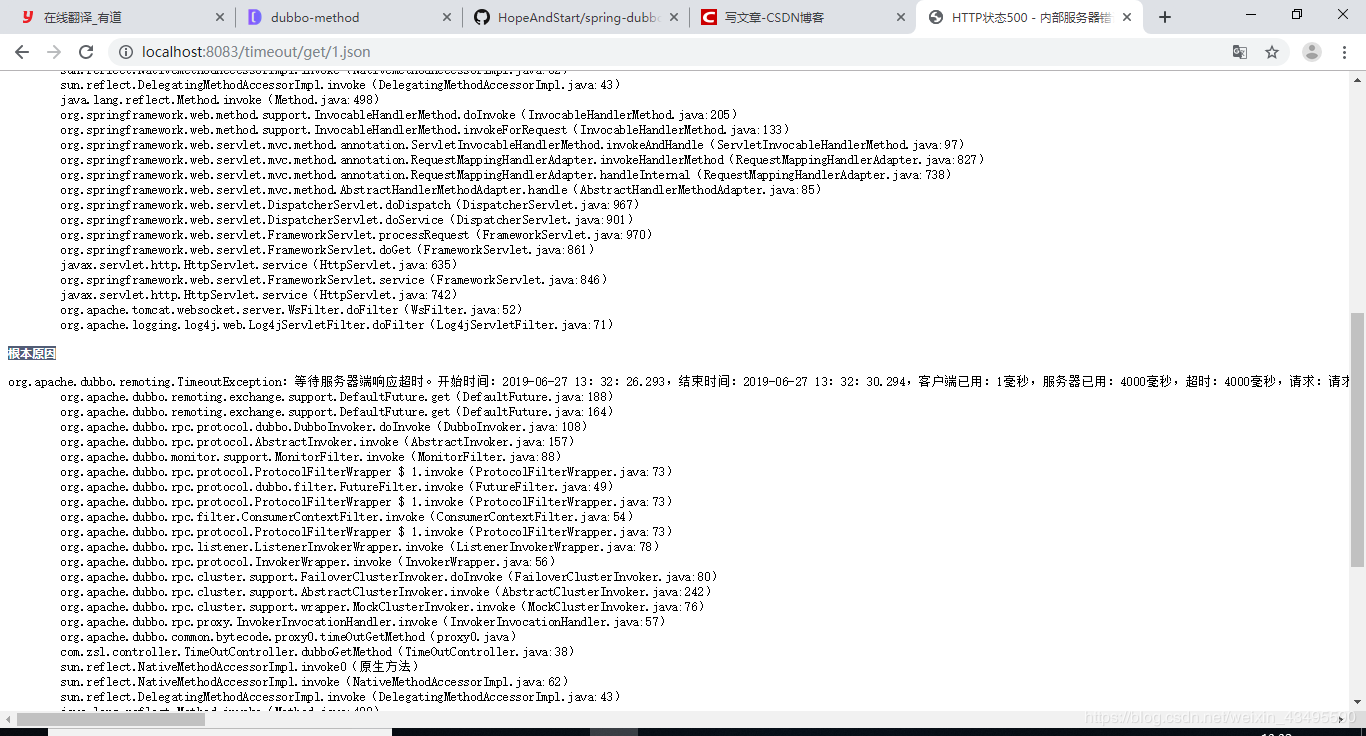
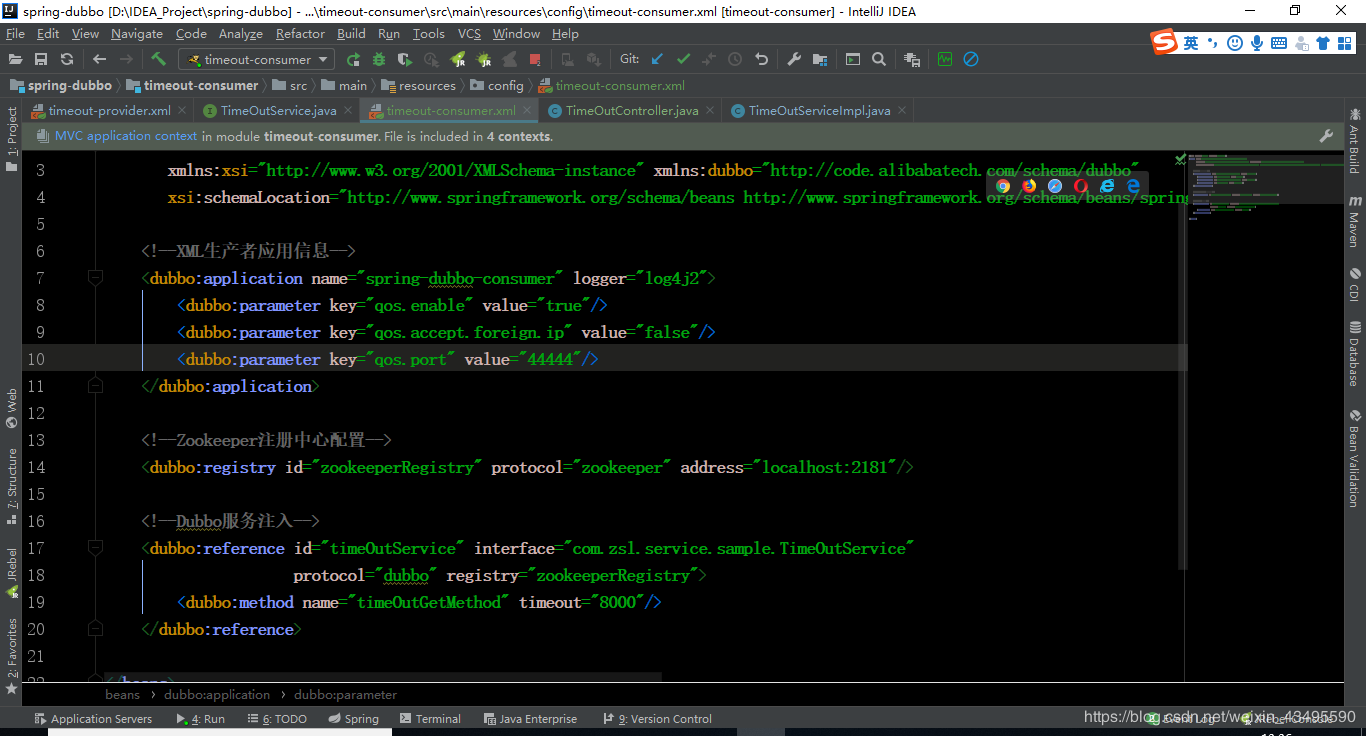
3.3 消费端与服务端
保持服务端配置不变,将消费端的方法超时设置为8s,查看最后调用情况
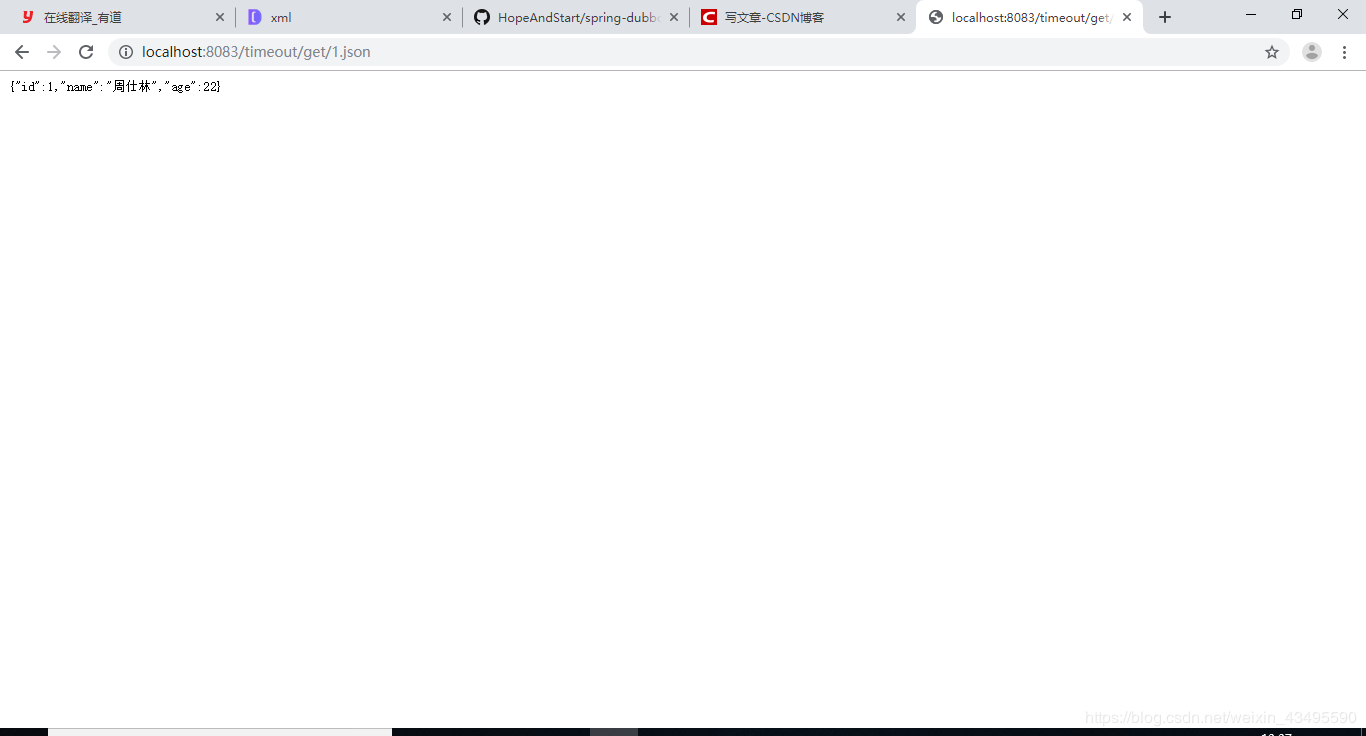
3.4 结论

- 方法 > 接口 > 全局
- 同级别下消费 > 生产
- 不仅针对超时timeout属性,所有可配置属性都具备该优先级规则
四:重试机制的超时问题
dubbo默认的集群方式是failover,该方式采用失败重试的集群容错机制。也就是可以配置的属性retries,该属性只有在failover集群方式下才会生效配置不包括第一次请求在内的调用失败后重试次数 这时候问题来了,假设服务端配置10s超时,消费端配置1s超时,程序执行5s。也就是当时间超过1s的时候消费端就会出现异常,但是服务端并不会异常停止,这时候消费端重试又会发起请求,这在消费端看来就是第二次请求,最后结果就是服务调用失败,但是消费端执行了retries + 1次逻辑
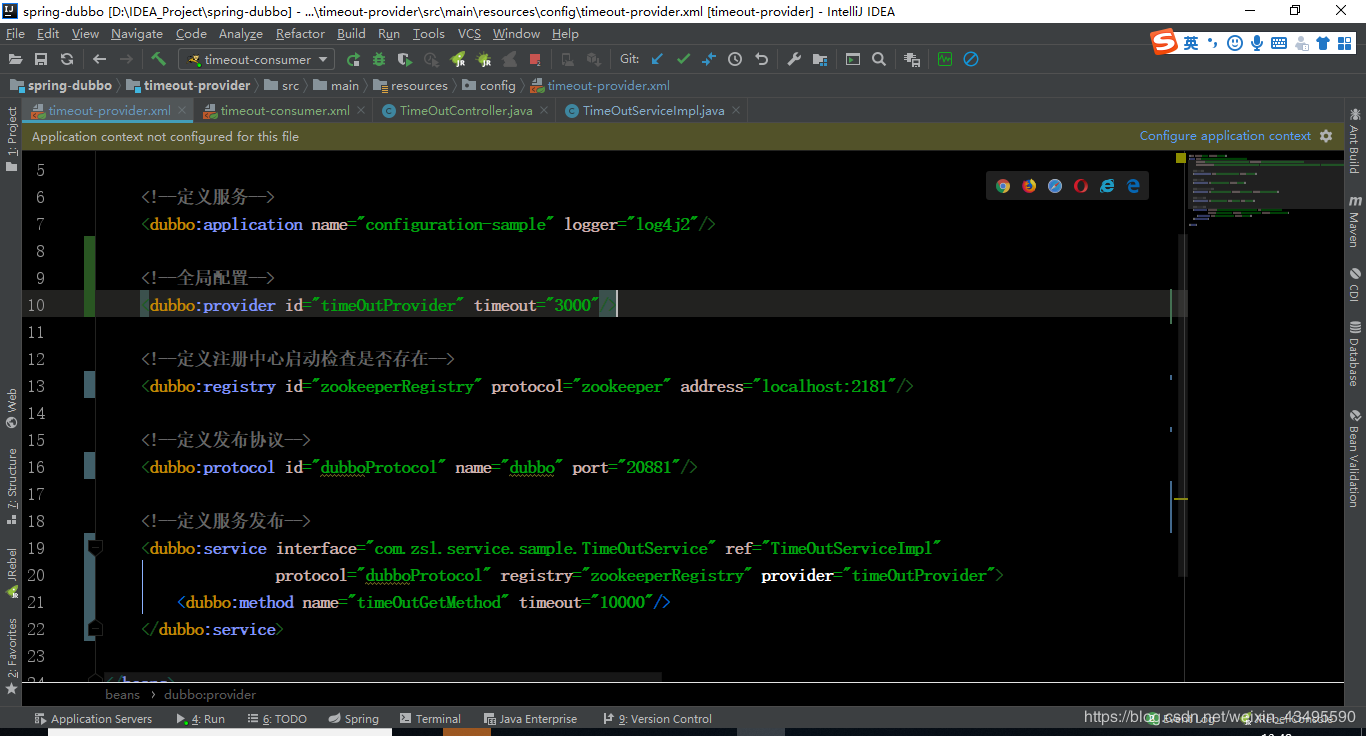
4.1 服务端配置
服务端采用10s超时时长配置,为了避免出现其它因素干扰,祛除了其它配置项。服务端程序代码不变,还是让线程睡眠5s如上面第二节截图所示
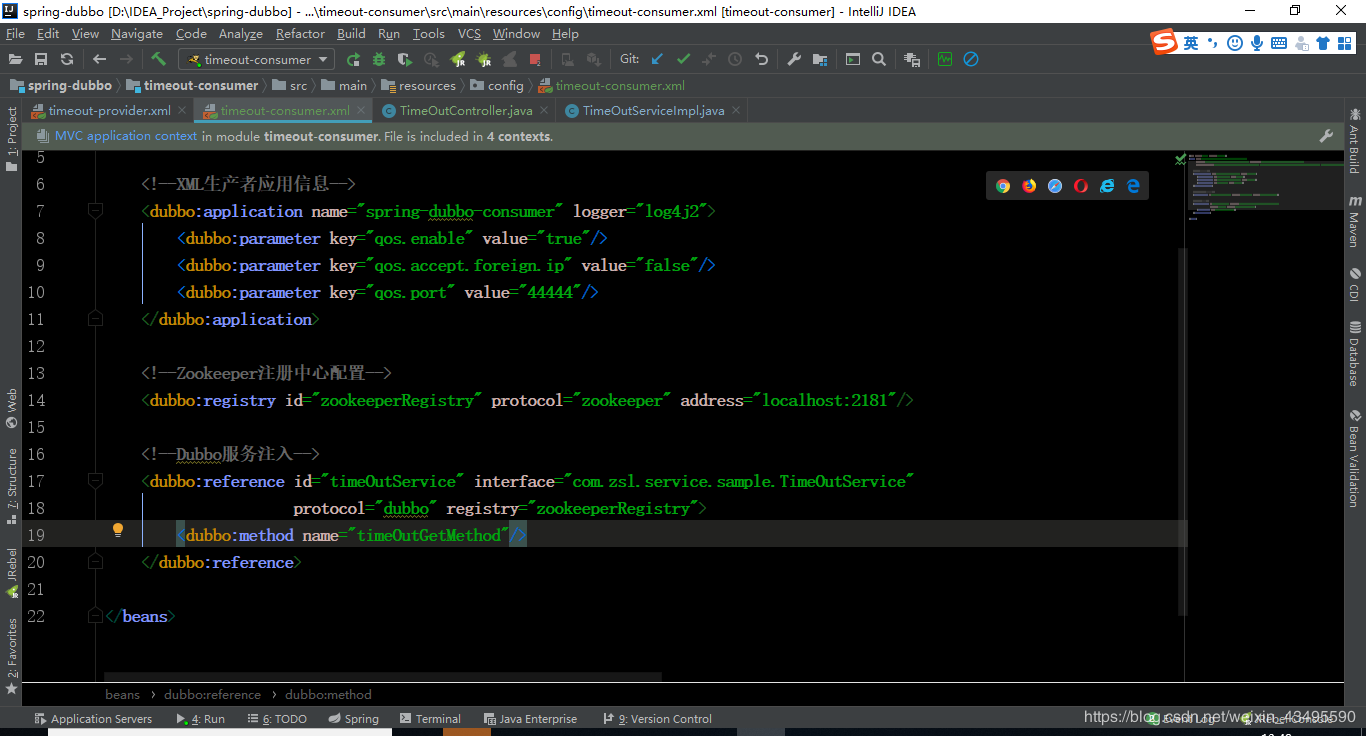
4.2 消费端配置
消费端配置1s的超时时长,注意这里不能说默认就是1s你还显示声明干嘛。你要不显示声明服务端显示声明就会按照服务端的配置时长操作的咯,注意这一点
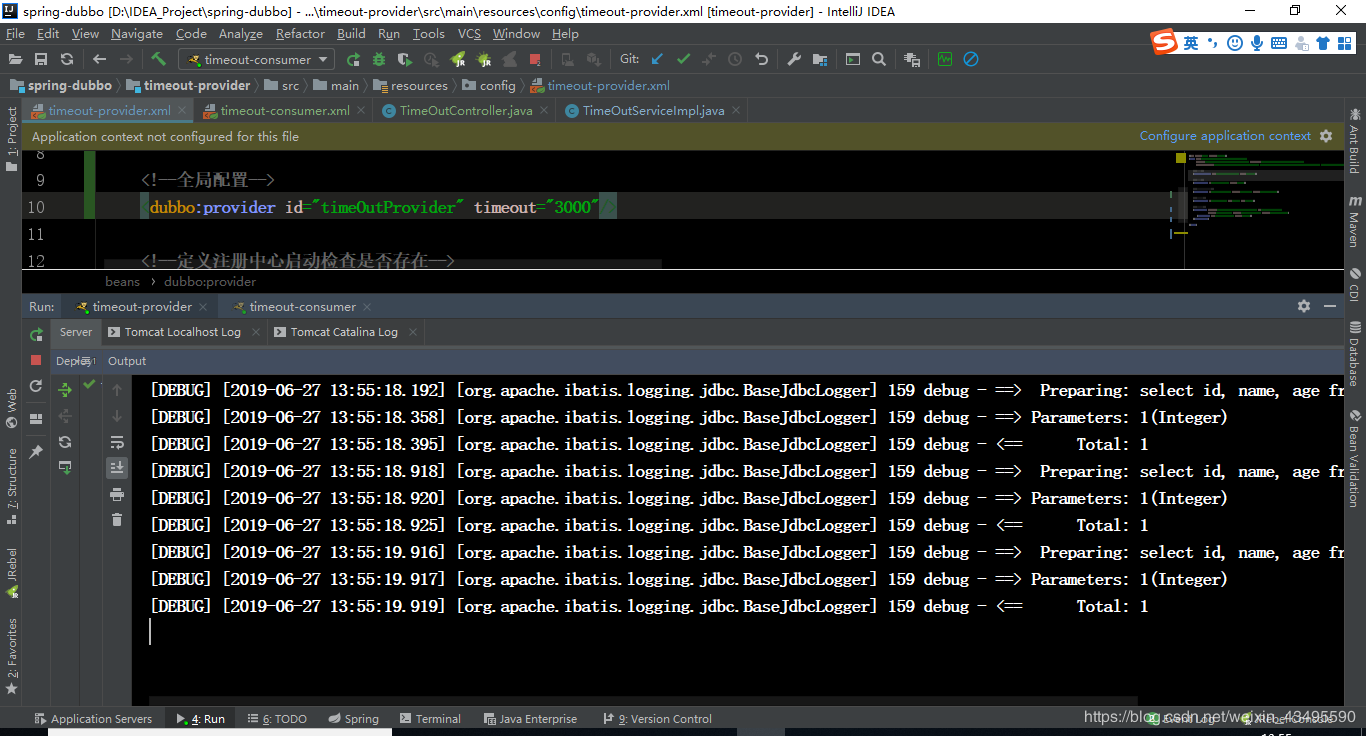
4.3 服务端执行结果
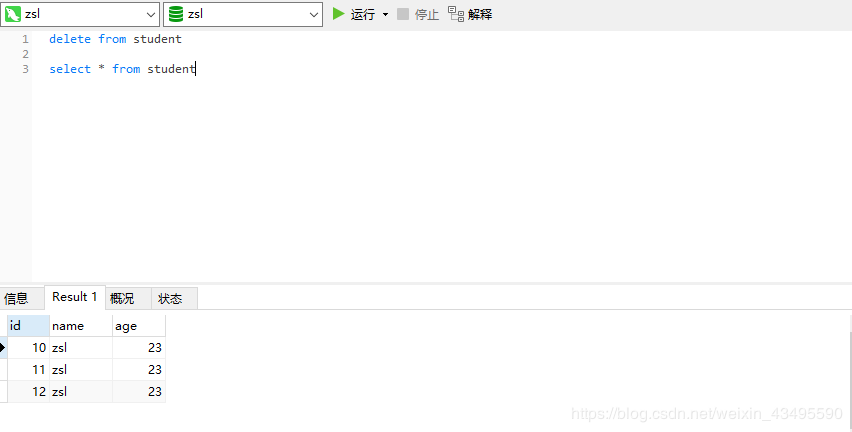
我的天,SQL日志打印三次。这不是重复执行三次的操作么?也就是说消费端发起了三次请求
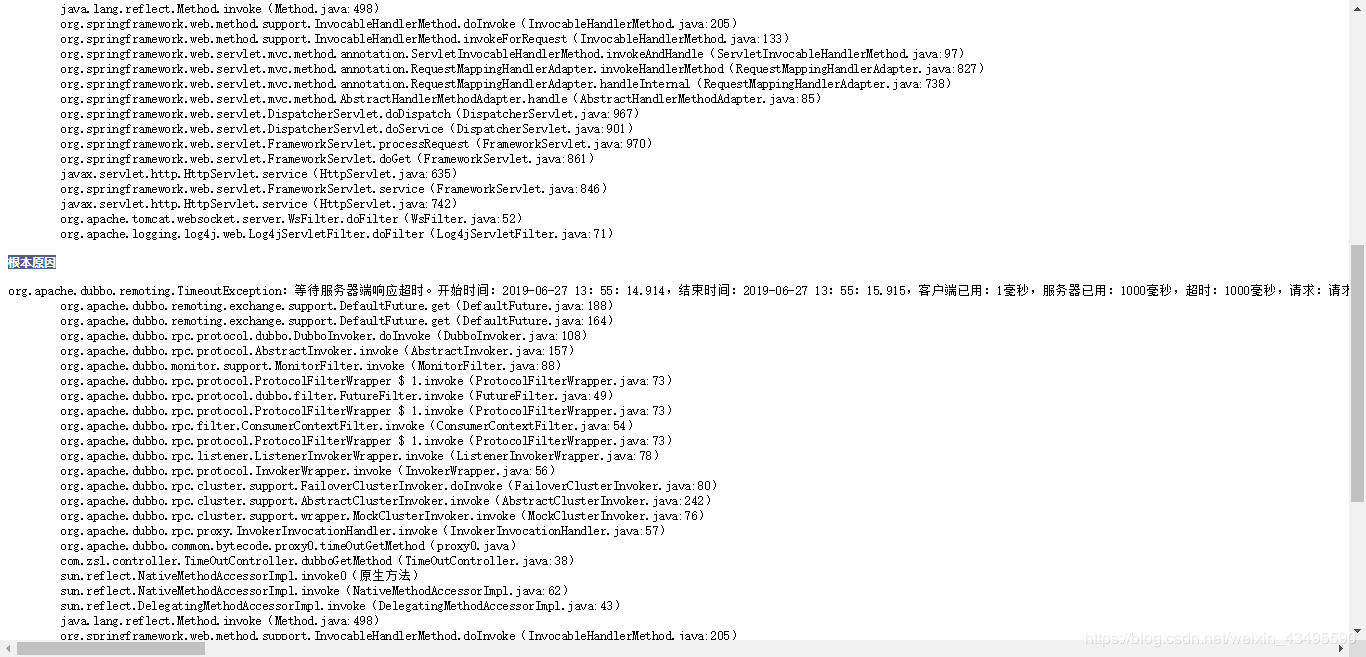
4.4 消费端返回结果
消费端还是以1s作为了超时时长,服务端每次执行都需要睡眠5s。也就是不管多少次请求都会超时异常不会得到结果
五:超时调优建议
5.1 服务端统一配置
分布式环境下不同的开发人员负责不同的项目模块或者是不同的功能,当使用RPC远程调用别人逻辑的时候作为调用方很多情况下并不知道该服务的具体执行情况。所以需要让服务端统一配置超时时长,避免出现消费端覆盖服务端配置而引发系列问题
5.2 数据修改关闭重试
回看一下第四节论证的问题,当出现超时异常的时候服务端可不会停下来,你客户端为了保证高可用一顿重试最后结果就是重复请求。当然如果是查询没问题,可以避免一些网络波动造成的超时异常,可以提升服务的可用性。但是如果是数据插入,如扣款、订单等操作,重复操作可不是一件好事情。下图展示当超时异常为关闭重试时数据重复的情况
六:总结
分布式系统确实让系统性能各方面都得到跨越阶级的提升,但是所带来的麻烦事儿确实不少。超时问题仅仅只是其中一个比较简单的问题,只要充分评估好业务时限设置相对的超时即可,当然根据业务类型设置不同的集群方式或者是失败重试的时候注意写操作关闭即可。祝福看到这里的同学技术高歌猛进,荡平一切来犯Bug。
