

序
作为iOS开发,程序崩溃犹如家常便饭,秉着没有崩溃也要制造崩溃的原则
我每天都吃的很饱
但学艺不精的我经常有这样的困扰,每次崩溃都定位到一堆 类似
movq $0x0, 0xc7a(%rip) 的天书里面,慌乱的我 只能狂点下一步
逃离这些洪水猛兽
是谁悄然无声打开了 Always Show Disassembly 这扇大门?
但三过家门而又不入,也并非我的性格
著名的学者 沃滋基说过:克服困难最好的解决方式 ,就是不克服
于是 我把门关上了
初识汇编
垃圾桶汇编法 顾名思义 就是 我不懂汇编,但我也要和垃圾桶一样会装
虽然我不知道movq是什么意思,但我知道move
move 的意思,没错是 飘逸
至于q,管它 q不q 的,哎我的e呢?
突然想到我的孤儿索没有了e ,还怎么快乐的move
我很愤怒
决定浅入了解一下这个东西
汇编语言
汇编语言:(assembly language) 是一种用于 电子计算机、微处理器、微控制器,或其他可编程器件的低级语言 -
维基百科
简单来说,我们平时写的代码都是 高级语言,计算机不理解高级语言,就像你吃饭不吃塑料包装一样,你吃的是里面的东西
汇编语言是二进制指令的 文本形式,计算机会把 我们的代码 转换为 汇编语言,汇编语言 通过机器指令 还原成 二进制代码,也就是所谓的 0 1,计算机就可以执行了。
每一个 CPU 的 机器指令不同,所以对应的汇编语言也不同。
寄存器
为什么需要了解寄存器?
因为汇编语言 的数据存储 与寄存器和内存 息息相关
一般来说,数据是放在内存中的,CPU 计算的时候就去内存里拿数据,但是
CPU 的运算速度 > 内存的运算速度
就仿佛
你吃饭的速度 > 食堂大妈打菜的速度
你受不了,大妈受得了吗?
所以CPU 自带了一级,二级缓存,相当于大妈让她儿子给你送饭
问题是这个中间层还是慢且不稳定
CPU 缓存的数据地址是 不固定的,意味着你点了份 西红柿盖浇饭,让店员给你送到座位上,店员找了半个小时,发现你坐在别人店里
...

所以CPU 有了寄存器,来存储频繁使用的数据。CPU 通过寄存器 跟 内存 间接交换数据
寄存器都有自己的名称(如 rax ,rdx等)
你说你坐在C区21号,店员还不是分分钟把饭塞到你嘴里,质问你:喂,你还要饭吗?
所以CPU 会去 指定名称的 寄存器拿数据,这样速度就不快了嘛
天下武功,唯快不破。
所以为什么需要寄存器,因为它的读写速度够快
内存
说到底,寄存器依旧是一个暂存区,只是一个中间站,真正存储数据,操作数据的还是内存。
以下是内存分布图:
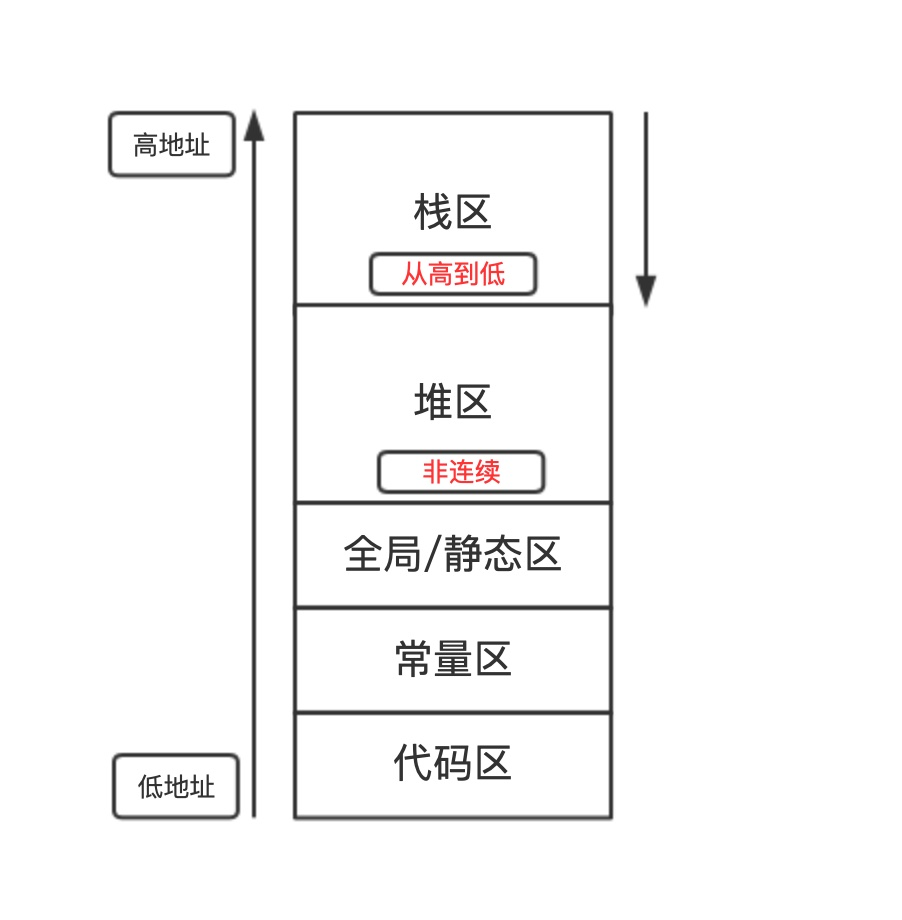
这里简单介绍一下堆栈
-
堆heap- 分配方式:alloc,速度相对栈比较慢,容易产生内存碎片
- 管理方式: 程序员,ARC下面,堆区的分配和释放基本也是系统操作
- 地址分布:从低到高,非连续
- 大小:取决于计算机系统的有效的虚拟空间
- 作用:动态分配内存,存储变量,延长生命周期
-
栈stack- 一端进行插入和删除操作的特殊线性表
- 分配方式: 系统,速度比较快
- 管理方式: 系统,不受程序员控制
- 地址分布:从高到低,连续
- 大小:栈顶的地址和容量是系统决定
- 生命周期:出了作用域就会释放
- 入栈出栈:
先进后出,类似羽毛球筒,先放入的羽毛球,总是最后才能拿到
在Linux 下,iterm2 敲下ulimit -a,可以看到栈分配的默认大小为 8192 ,也就是 8M
-t: cpu time (seconds) unlimited
-f: file size (blocks) unlimited
-d: data seg size (kbytes) unlimited
-s: stack size (kbytes) 8192
汇编语言
因为是iOS开发,所以就只稍微了解了 AT&T 汇编 的皮毛
虽然看起来会枯燥一点,但是理解这些比较常用的寄存器,对汇编代码的理解就会有质的飞跃
之前你是门外汉
现在好歹算个半个汇编人
今天的你比昨天更博学了

iOS 模拟器、MAC OS、Linux : AT&T汇编 ;
iOS 真机: ARM 汇编
x86-64中,AT&T 中常用的 寄存器有 16种:
- %rax、%rbx、%rcx、%rdx、%rsi、%rdi、%rbp、%rsp
- %r8、%r9、%r10、%r11、%r12、%r13、%r14、%r15
常用寄存器
AT&T 常用寄存器介绍:
%rax:常作为函数返回值。
一般来说,为了向后兼容,64位的寄存器会兼容32的寄存器,32和64可以一起使用
64位: 8个字节 ,以 r 开头; 32位: 4个字节,以e 开头,看图
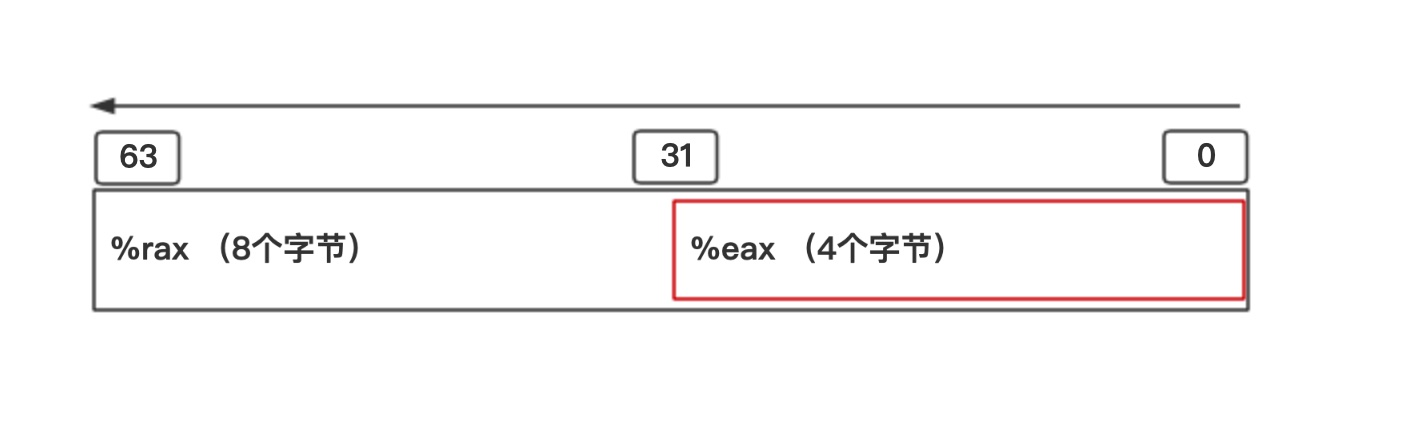
在64位的寄存器 rax中,为了兼容分配了较低的32位,也就是4个字节 给了 eax。基本上,汇编出现的eax 就是 代表rax,eax是 rax 的一部分,其他 部分寄存器同理
%rdi、%rsi、%rdx、%rcx、%r8、%r9: 常作为函数参数
r8,r9 这种32位的表示法,通常在后面加d,如r8d,r9d
%rip: 指令指针,存储CPU 即将执行的指令地址
- 解释一下rip
即将执行: 下一条执行
指令地址: 开头的那一串 0x100...
截取2句汇编:
7 -- 0x100000a64 <+20>: movq $0x1, 0x719(%rip)
8 -- 0x100000a6f <+31>: movl %edi, -0x34(%rbp)
第7行中的 0x719(%rip) 中的 rip 就是指令指针,即将执行的 地址 就是 第8行 开头的那个地址0x100000a6f
所以这里rip 的地址就是 0x100000a6f,有了rip 的地址
一般来说
0x719(%rip) 就是 0x719 + %rip地址
-0x719(rip) 就是 %rip - 0x719
栈相关
%rbp: 栈基址指针也称为帧指向,指向栈底
%rsp: 栈指针,指向栈顶
常用指令
一些比较常见的我能理解的指令
| 中文 | AT&T | 翻译 |
|---|---|---|
| 立即数 | $0x1 | 立即数就是常量,前面加$表示 |
| 寻址 mov | movq $0x1, %rdi | 将 1 赋值给 寄存器 rdi,从左往右 |
| 内存赋值 lea | leaq %rbp,%rax | 将rbp的 内存地址值 赋给 rax |
| 异或 xor | xorl %eax, %eax | 将eax 清0,自己异或自己 |
| 跳转 jmp | jmp 0x80001 | 跳转到函数地址为0x80001的地址 |
| 间接跳转 *() | jmp *(%rax) | rax是个内存地址,*(rax) 是拿到rax地址里的值 |
| 函数调用 call | callq 0x80001 | 调用 0x80001的地址的函数,一般配合retq |
那么这个q 是干什么的呢 ?callq ,leaq ,movq 都有q?
-
这里的q 是 代表字节大小
- b-byte 字节,操作位宽 1个字节
- w-word ,2个字节
- l-long ,4个字节
- q-quadword,8个字节
q意味着,寄存器操作的数据类型 需要占用的 操作位宽,当然这根据你的 数据类型决定
所以上面那句代码
movq $0x1, 0x719(%rip)
意思是,立即数 1 寻址 (0x719 + %rip),并赋值。将 1 赋值给 (0x719 + 0x100000a6f) 这个地址,操作位宽是8 个字节
读取寄存器
介绍几个 lldb 的常用指令,可以方便我们查阅 寄存器的值
register read/格式: 读取寄存器的值
register read/x rax // 读取寄存器 rax 里面的值
x:16进制
f:浮点
d:10进制
register write修改寄存器的值
(lldb) register read/x rax
rax = 0x0000000000000003
(lldb) register write rax 4 // 修改为4
(lldb) register read/x rax
rax = 0x0000000000000004
- x/数量-格式-字节大小: 读取内存中的值
x/4xg 0x1000002
// 将 0x1000002 地址的值,以8个字节的格式,分成4份,16进制 展示
// 这里是展示 和 上面的操作不太一样,g 表示8个字节
b - byte 1字节
h - half word 2字节
w - word 4字节
g - giant word 8字节
🐷:如果数据的值不够分成4份,剩下的字节以0 补齐
栈帧
帧,在电影中指每一张画面,一种平均单位
栈帧:站着的帧,画面立体了起来,不单单是一个角度,里面包含了很多信息
包含了
每一次
* 函数调用涉及的相关信息
局部变量、函数返回地址、函数参数等
我们都知道,函数的调用是会在栈上分配内存的,分配多少取决于函数的参数和局部变量
那么一个函数的占用的内存大小,函数的返回地址,我们就需要保存起来,这就用到了栈帧
- 为什么需要保存函数的信息?
因为函数运行完毕 ,在栈上需要释放内存,以及继续执行上一层代码,我们需要上一层函数的返回地址,在本次函数执行完毕后,恢复父函数的栈帧结构
想象这样一个场景
类比一下接力赛中,4位选手
栈顶 1 -> 2 -> 3 -> 4 栈底,每一位选手都要在拿到接力棒后,才会开跑
那么 1号选手,就需要保存2号选手的信息,他不需要知道 3号 和 4号
下一个接棒者 长什么样?身上的号码牌?站在哪里?
1 号选手结束之后, 赛场队伍就只剩 2 -> 3 -> 4,此时焦点就集中在2号选手
选手跑步 -> 函数调用
选手信息 -> 栈帧保存的信息
视线焦点 -> 栈指针,指向当前选手
只有我们清楚了下一位的接棒人(在栈中对应上一层函数),我们才能在本次结束之后找到正确的位置,继续执行流程
至于信息的保存者? 取决于寄存器的标识 Caller Save 和 Callee Save
当子函数调用的时候,也会用到父函数的寄存器,可能会存在覆盖寄存器的值。
* Caller Save,调用者保存
父函数调用子函数之前,将寄存器的值保存一份,这样子函数就可以随意覆盖
* Callee Save,被调用者保存
父函数不保存,交由子函数 保存和恢复 寄存器的值
例子
我们简单的建立一个 命令行 工程,打开汇编 Always Show Disassembly
用 Swift 写出以下代码
func test() -> Int {
var a = 3
a = a + 1
return a
}
-> test() // 断点指向test,run
程序运行起来,我们可以看到 ,程序断点在 test 函数调用的地方
zzz`main:
0x100000bc0 <+0>: pushq %rbp
0x100000bc1 <+1>: movq %rsp, %rbp
0x100000bc4 <+4>: subq $0x20, %rsp
0x100000bc8 <+8>: movl %edi, -0x4(%rbp)
0x100000bcb <+11>: movq %rsi, -0x10(%rbp)
-> 0x100000bcf <+15>: callq 0x100000bf0 ; zzz.test() -> Swift.Int at main.swift:189
0x100000bd4 <+20>: xorl %edi, %edi
0x100000bd6 <+22>: movq %rax, -0x18(%rbp)
0x100000bda <+26>: movl %edi, %eax
0x100000bdc <+28>: addq $0x20, %rsp
0x100000be0 <+32>: popq %rbp
0x100000be1 <+33>: retq
我们控制台 用
si 进入 test 函数内部
可以看到 test 内部的汇编代码,参考下面的图,说一说我的理解
zzz`test():
-> 0x100000bf0 <+0>: pushq %rbp
0x100000bf1 <+1>: movq %rsp, %rbp
0x100000bf4 <+4>: movq $0x0, -0x8(%rbp)
0x100000bfc <+12>: movq $0x3, -0x8(%rbp)
0x100000c04 <+20>: movq $0x4, -0x8(%rbp)
0x100000c0c <+28>: movl $0x4, %eax
0x100000c11 <+33>: popq %rbp
0x100000c12 <+34>: retq
- 借图,侵删
子函数调用时,调用者与被调用者的栈帧结构
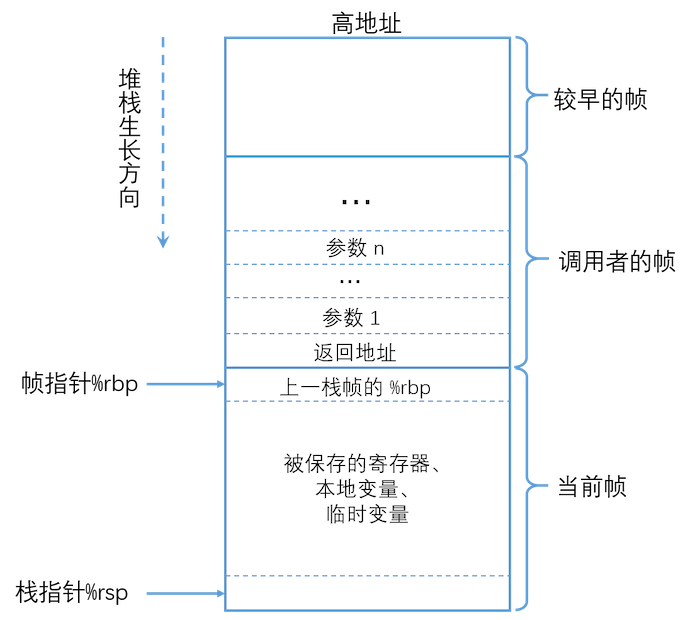
分析
test 函数 一进来,就执行了下面两句代码
-> 0x100000bf0 <+0>: pushq %rbp
0x100000bf1 <+1>: movq %rsp, %rbp
一开始,test 函数 就进行了 压栈
pushq %rbp
压栈的是父函数 main函数的 栈帧指针 %rbp
% rbp指向的返回地址, 是main 函数 调用完 test ,应该回到哪里的地址,也就是当前函数test 调用开始时 栈的位置
而此时 test 函数的 %rbp ,相当于是新的%rbp
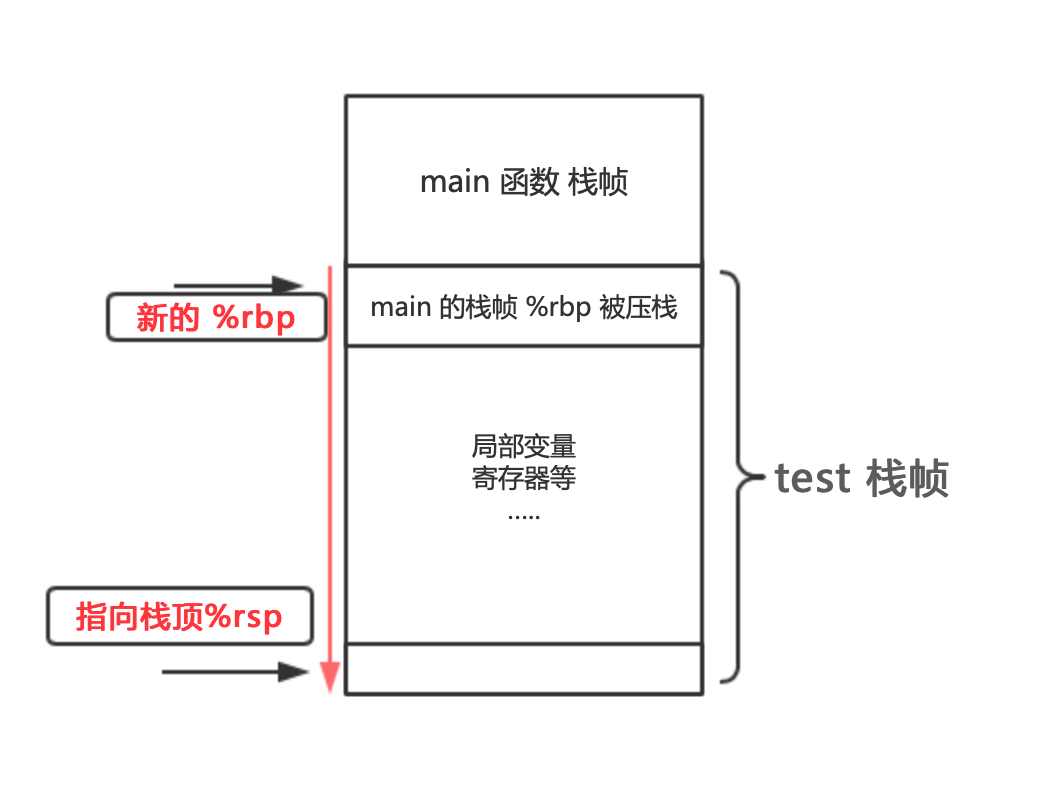
然后通过
movq %rsp, %rbp
将%rsp 也 指向 %rbp,test 栈帧 的初始位置
因为%rsp 总是指向新的元素,所以在被 一些局部变量等 填充之后,来到了栈顶
函数的调用: 栈帧被创建 -> 填充 -> 销毁
接着
0x100000bf4 <+4>: movq $0x0, -0x8(%rbp)
0x100000bfc <+12>: movq $0x3, -0x8(%rbp)
0x100000c04 <+20>: movq $0x4, -0x8(%rbp)
将 立即数 0 ,赋值给 %rbp - 0x8的 8个字节 的内存空间 用于初始化
后面又将 参数3,覆盖,以及计算+1 的值 继续覆盖,这里应该是省略了 +1 的操作
接着
movl $0x4, %eax
前面说过,%rax 通常作为返回值,%eax 是 %rax 的32位表示,将 立即数4赋值给 %eax作为返回值
这里用到了movl 和 %eax,是因为 int类型 占用4个字节,只需要 4个字节即可,所以用到了 %rax 的 较低的 32位
`
到这里我们就得到了 test函数的 返回值 4
再来
0x100000c11 <+33>: popq %rbp
0x100000c12 <+34>: retq
前有 push ,后就有pop,将test 中的寄存器 %rbp 从栈中弹出,恢复调用前的 rbp,而
retq 等价于 popq %rip,前面说过rip 代表着 下一条指令
将%rip 指令指针,从新指回 test 函数调用后的 下一条 指令,这样程序就可以继续运行了
此时的 内存分布
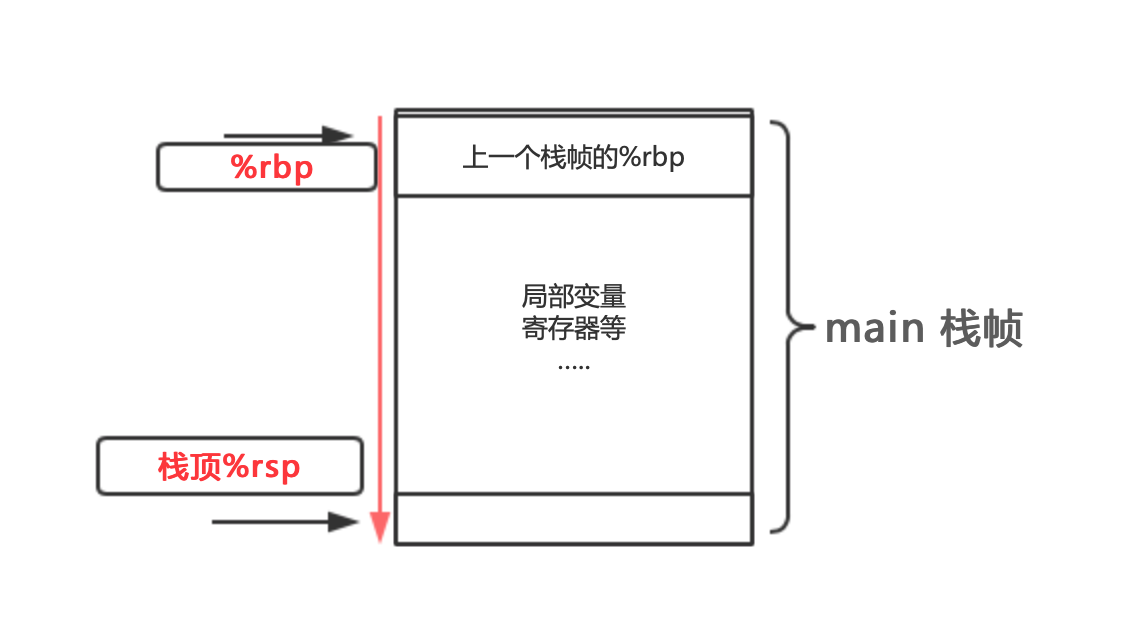
而 test 函数的内存空间,随着作用域的结束,就被释放了
到底为止,我们就简单的理解了 test 函数 a + 1的 汇编过程
结
虽然是简单的一个加法,但是却是我们入门的好盆友
相信看完此篇,此时的你必定热血沸腾,心潮澎湃
忍不住
想把门关上
...
由于我的理解也不够深,认知有限
如果有错误的理解,还请指正
谢谢
结
下一篇
