

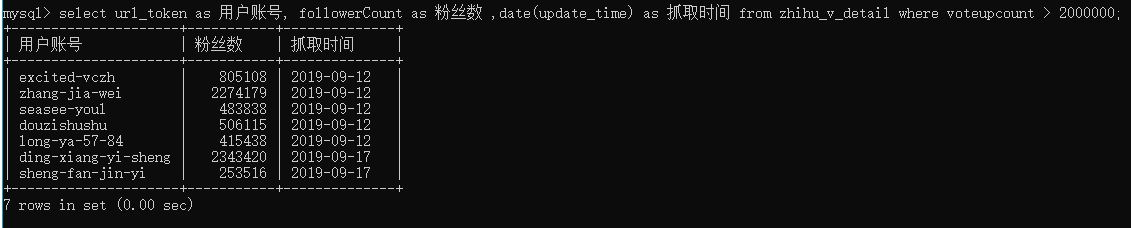
国庆假期花了一些时间,首次尝试并玩转 grafana,这几天继续不断优化和完善,如今看着自己的成果,相当满意。——逐步接近我想要的理想后台啦。
需求是不停歇的。今天我又给自己发掘了一些新需求,比如变量、筛选框之类,都收集下来等有空继续玩。编程学习的过程中,对于自己尚未尝试的新技能点,本能直觉会感到困难,但动手经验告诉我:莫慌,用起来就懂了,瞧我自己每次都能很快上手吖。——善于让自己在学习的过程中感受良好,并确实持续进步,自我激励是一个特别实用的软技能。
然后我想着不妨把这几天玩转 grafana 时用到的进阶版的 sql 语句整理出来。所谓进阶版,是针对我个人的 sql 能力啦,确切地讲,是指在我之前的笔记中未曾出现、且玩转 grafana 中我确实反复用到的。整理自己刚刚反复实践的新知识点,能很好地巩固新知。完成这件事,方能安心进入下一个阶段向未知冲刺。
之前写了一篇笔记,记录自己是为什么要玩 grafana ,以及如何在 24 H做到被工程师称赞,文中提及我把工程师已经实现的 sql语句拷贝下来,拆解为元知识点,然后逐个理解:它是什么功能,如何用,然后直接用起来试试效果。
举个实例来拆解元知识点
在本篇笔记中,我也先举一个实例用作知识点拆解,如下,该述语句的作用是:统计每天具有学习行为的用户数。注:学习行为其实包含多种具体的行为,分布在两个表中。
with data as(
select
date(created_at) as time,
user_id
from user_comments
union all
select
date(created_at) as time,
user_id
from user_activities
)
select
time,
count(distinct user_id) as 每日学习用户数
from data
group by time
order by time
注意:sql 对大小写、换行、缩进之类都不敏感,这是和 python不同的地方。上面之所以要换行和缩进,只是为了易读性。
这一条 sql 语句看着挺长,其实是两个部分。as 前面的 data 是数据的名字,我们自定义的,后面B部分的from 数据源就是它。被 with data as() 括起来的A部分,用于生成数据,相当于先做一次检索统计得到一些数据命名为 data ,然后再对 data 进行检索统计。
with data as (【语句块A】)
【语句块B】
可嵌套的 with data as()
短时间用 with data as() 用的比较多时,我就揣测:这玩意儿能嵌套吗?一试果然可行。嵌套只是让它看上去复杂点,本质没啥变化。如下所示,语句块 A 的数据源是原始数据,语句块 B 的数据源是 data,语句块 C 的数据源是 datax。
with datax as(
with data as (【语句块A】)
【语句块B】
)
【语句块C】
实战中,我最多用过3层嵌套,且偶尔为之;双层嵌套用的多一些。而单层则相当常用。
用union合并数据行
上方实例被 with data as() 括起来的部分,其实是两个表满足条件的数据合并。抽象一下如下。
【语句块X】
union all
【语句块Y】
处理表格数据的合并时,细分有以下三个情形:
- 把多列或多行的数据,合并为单列或单行的数据
- 把A表的数列,与B表的数列合并起来
- 把A表的数行,与B表的数行合并起来
union 处理的是基于行的合并。举例来说,如果语句块X的结果为a行,语句块Y的结果为b行,则通过union all 合并后的结果将有(a+b)行。而用 union 的结果是取a和b的并集,即a、b中都存在的数据行只保留一份。
相对应的,在pandas 通过 pd.concat() 的axis参数就能处理行、列的不同方式合并,还真是简约吖。
函数data()与as别名
上方举例中,语句块X 和Y大体上是蛮基础的语句。但依然出现了我之前没有用过的方法。
date(created_at) as time,和count(distinct user_id) as 每日学习用户数这两个片段中,as之前是表达式语句,as之后是该语句运算结果的别名。date()方法是把复杂的时间数据简化为年月日的日期数据。超高频使用。count(distinct user_id)则表示:对user_id去重,然后统计user_id个数。超高频使用。
类似count()和sum()都是高频使用的基础函数。不过数据统计中,更常用到累加。语句是定番组合,就不再单独罗列啦:
sum(兑换用户数) over (order by 兑换日期 asc rows between unbounded preceding and current row) as 累计用户数
而count(1),count(*)和 count(column_name) 在不同情况下,运行效率不同。鉴于我暂时没有写出性能最好的sql语句之觉悟,暂不深究啦。
各种情况下的去重
上面提及distinct ,如何使用distinct 倒不复杂;复杂的是需求,对数据指标的定义要理解准确;不同的数据指标,对去重有不同的要求。
情境A:不去重。
虽然count的是user_id,但这个数据其实并不是每天留言的用户数,而是每天留言的条数。
select
date(created_at) as time,
count(user_id) as 每日留言条数
from
user_comments
group by
time
order by
time
情境B:当日去重。
在当天内去重,跨天不去重。用户在某一天有多条留言,最终也只能为当天留言用户数贡献计数1
select
date(created_at) as time,
count(distinct user_id) as 每日留言用户数
from
user_comments
group by
time
order by
time
情境C:历史累积去重。
有过留言行为的累计用户数,则在全时段内去重。只要该用户曾有过留言行为,则计数1,不再重复计数。
select
count(distinct user_id) as 留过言的用户总数
from
user_comments
情境D:每日和历史累积同时去重。
假设我们想知道每日新增的留言用户数,即如果该用户以前曾留言则不计数,否则在首次留言当天计数1,这个情境比前面三种复杂点,但同样相当高频使用。
with data as (
select
distinct on (user_id) user_id,
date(created_at) as time
from
user_comments
)
select
time,
count(user_id) as 每日新增留言用户数,
count(user_id) over (order by time asc rows between unbounded preceding and current row) as 累积留言用户总数
from data
group by time,user_id
order by time
几个常见的小知识点
limit指定显示多少条数据。换言之,没有这个条件,就表示要显示查询结果的所有数据。我之前不知道这个知识点时,有时不小心直接在命令行提示符中查看某个表,会一下子打印很多很多行,以至于一直下翻都不见底……而在数据后台中,通常配合排序功能,用来显示“排行榜”数据。比如,学习次数排行榜、兑换总额排行榜之类。
select * from table_name limit 50;
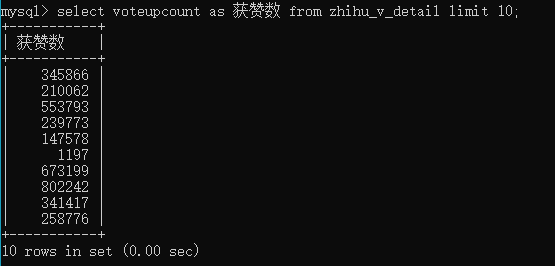
order by 指定数据按哪些字段排序,默认顺序,可用desc倒序。
select * from table_name order by column_name;
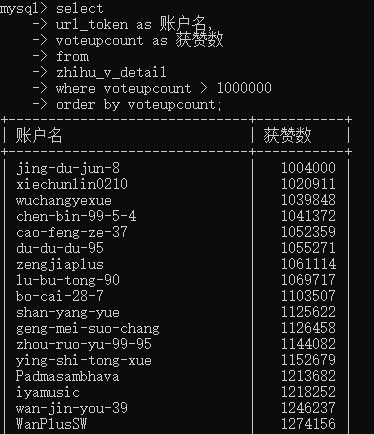
group by指定数据按哪些字段分组,很多报表按日统计。前面举例中无形中也用了该方法数次,就不单独举例啦。
多表联合查询
最后说明下,相对复杂的多表查询。从多个表格、或表格和自定义数据源如data中合并查询。一个相对简单的实例如下,根据输入变量 user_name 从 users_extra 查询到 user_id,然后用 user_id 去user_activities 表查询。
with data as(
select user_id,user_name from users_extra where user_name = '$user_name'
)
select
count(1) as 学习行为次数
from
user_activities,data
where
user_activities.user_id = data.user_id
这种联合查询必要的条件是,多个数据源可以通过某个字段对应起来。更复杂的例子,其实都可以动用拆解的方式,拆解为更单元的知识点。这里就不展开啦。
顺便说,上面的 user_name = '$user_name' 语句是 grafana 中用于调用自定义变量,实现后可支持下拉框筛选。这也是刚开始写这篇文章时,我提到的新需求,结果文章修修改改写完时,这个需求竟然被我实现了。还真是快!
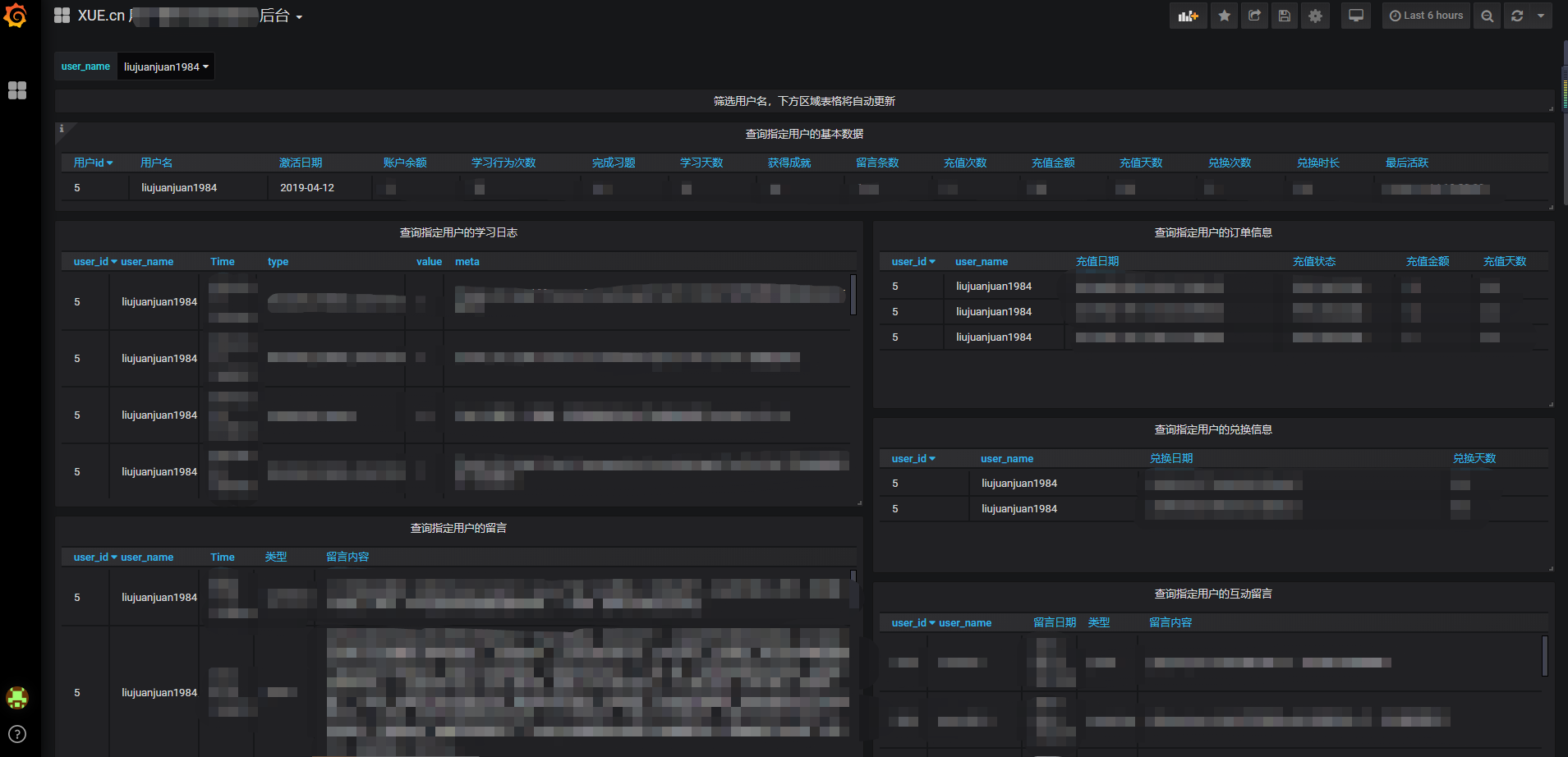
小结
如果某天你和我一样开始接触一点进阶、复杂的sql语句或其它技能,千万别慌,找一些现成的实例(比如收藏我这篇笔记)来消化,逐块拆解为元知识点,然后再把它们拼装结合用起来,你会发现:也不过如此嘛。
这个过程多像玩儿积木吖!好玩好玩!
如果这篇笔记帮到了你,一定要留言告诉我吖;这将鼓励我整理和分享更多。欢迎掘金的各位工程师XDJM们指正文中知识点错误。
