

前言
相信排序对于每一个程序员来说都不会陌生,很可能你学的第一个算法就是排序,尤其冒泡排序大家可能都是信手拈来,但是当从学校走入了职场之后,这些经典的排序已经慢慢淡出了我们的视线,因为在日常开发中,高级语言已经帮我们封装好了排序算法,比如 C 语言中 qsort(),C++ STL 中的 sort()、stable_sort(),还有 Java 语言中的 Collections.sort(),这些算法无疑是写得非常好的,但是我们作为有追求的程序员,对这些经典的排序算法还是有必要了解得更透彻一点。
本章,我们一起来探讨一下三个经典排序算法:冒泡、选择和插入排序。
思考
我们都知道,在分析一个算法的好坏的时候,我们第一反应就是分析它们的时间复杂度,好的算法时间复杂度自然会低,此外,空间复杂度也是衡量它们好坏的标准,好的算法的确也会在空间复杂度上做的比较好。
诚如上述,时间复杂度、空间复杂度基本是衡量算法的标准,但是对于排序算法来说,我们需要考虑更多,那么还有什么因素会影响排序算法的好坏呢?
影响因素
带着问题,下面我们一起从以下方面探讨排序算法的优势和劣势。
1.时间复杂度
最好、最坏、平均时间复杂度
一般我们所说的时间复杂度都是平均时间复杂度,但是如果需要细分,时间复杂度还分最好情况、最坏情况和平均情况的时间复杂度,所以我们需要通过这三种情况来分析排序算法的执行效率分别是什么。
时间复杂度的系数、常数和低阶
我们知道(平均)时间复杂度反应的是当n非常大的时候的一个增长趋势,这时候它的系数、常数、低阶往往都会被我们忽略掉。但是当我们排序的数据只有100、1000或者10000时,它们就不能被我们忽略掉了。
比较次数和交换次数
进行排序时,我们往往需要进行比较大小和交换位置,当我们比较执行效率的时候,这些数据也需要考虑进去。
2.空间复杂度
算法的内存消耗可以通过空间复杂度来表示,这里有个概念,我们称空间复杂度为O(1)的排序算法为原地排序算法。
3.排序算法的稳定性
排序算法的稳定性是指,在排序过程中,值相同的元素间的相对位置跟排序前的相对位置是一样的。举个例子,排序前一个数组为{3, 2, 1, 2', 4},我们用2'来区分第二个2和第一个2,假如是稳定的排序算法,它的结果一定是这样{1, 2, 2', 3, 4},而如果不稳定的算法,它的结果有可能是这样{1, 2', 2, 3, 4}。
为什么我们要强调稳定性呢?举个例子,假如我们需要排序一个订单,需要按照时间和价格进行升序排序,首先会先将所有订单按时间升序排序,然后再进行价格的升序排序,假如价格排序不是一个稳定的排序,那么订单的时间就有可能不会按升序排列,所以在特定情况下,排序算法的稳定性是一个比较重要的考虑因素。
冒泡排序
我们先从冒泡排序开始分析。
冒泡排序原理是让相邻的两个元素进行比较,看是否满足大小关系,如果不满足则交换位置,每一次冒泡会让一个元素放到属于它的位置,然后进行n轮冒泡,即完成冒泡排序。
举个例子,假如我们需要对数组{5,4,3,1,8,2}进行升序排序,那么第一轮冒泡后,8就冒泡到了最后一个位置,因为它是最大值。
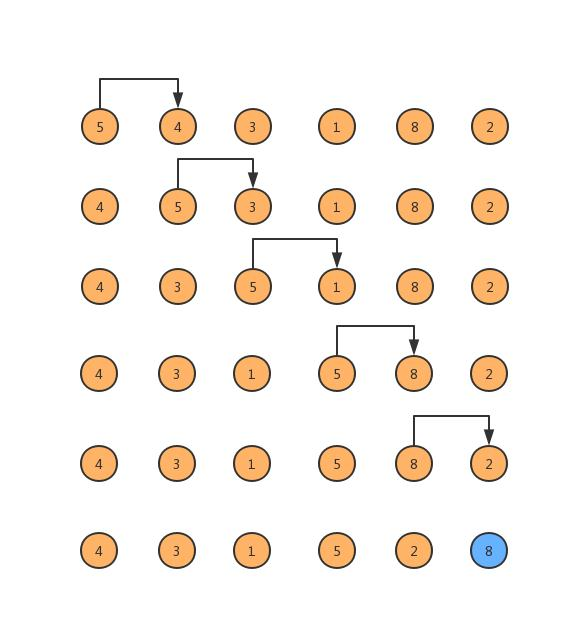
如此重复6轮,如下图所示,即可将数组的每一个元素冒泡到自己的位置,从而完成排序。
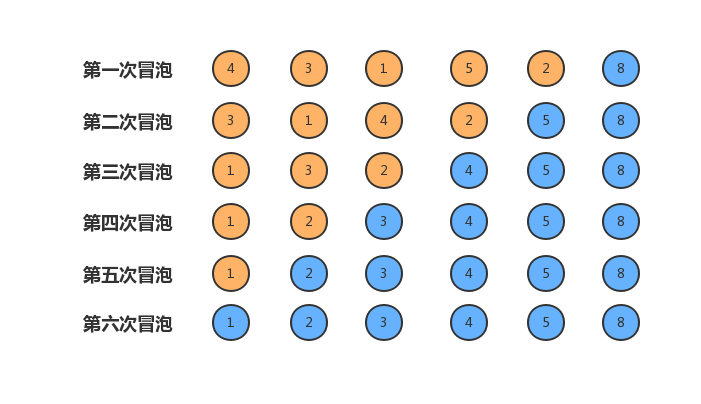
当然,这是没有经过优化的冒泡排序,事实上当数组不再进行数据交换时,我们就可以直接退出,因为此时已经是有序数组。具体代码如下:
public void bubbleSort(int[] a, int n) {
if (n <= 1) return;
for (int i = 0; i < n; ++i) {
// 退出冒泡的标志
boolean flag = false;
for (int j = 0; j < n - i - 1; ++j) {
if (a[j] > a[j+1]) {
// 交换
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
// 表示有数据交换
flag = true;
}
}
// 没有数据交换,提前退出
if (!flag)
break;
}
}
结合上述代码,我们总结冒泡排序的特性。
1.时间复杂度
当数组是有序时,那么它只要遍历它一次即可,所以最好时间复杂度是O(n);如果数据是逆序时,这时就是最坏时间复杂度O(n^2),那么平均时间复杂度怎么算呢?
计算平均时间复杂度会比较麻烦,因为涉及到概率论定量分析,所以可以用以下方法来计算,以上面排序数组为例子,先来理解一下下面的概念:
- 有序度:有序度是指一个数组有序数对的个数,例如上面数组为排序前有序数对为(4,5),(4,8),(3,5),(3,8),(1,5),(1,2),(1,8),(5,8),(2,8),所以有序度是9。
- 满有序度:满有序度是指一个数组处于有序状态时的有序数对,还是上面数组排序完成后的有序数对有15个,用等差数列求和,得出求满有序度的通用公式为n(n-1)/2。
- 逆序度:逆序度正好和有序度相反,所以上面数组对应的值是15-9=6,即逆序度=满有序度-有序度。
理解了这三个概念后,我们就可以知道,其实将数组排序就是有序度增加,逆序度减小的过程,所以我们排序的过程其实也是求逆序度大小的过程。
那么我们就可以计算冒泡排序的平均时间复杂度了,最好情况下,逆序度是0,最坏情况下,逆序度是n(n-1)/2,那么平均时间复杂度就取中间值,即n(n-1)/4,所以简化掉系数、常数和低阶后,平均时间复杂度为O(n^2)。
2.空间复杂度
由于冒泡排序只需要常量级的临时空间,所以空间复杂度为O(1),是一个原地排序算法。
3.稳定性
在冒泡排序中,只有当两个元素不满足条件的时候才会需要交换,所以只有后一个元素大于前一个元素时才进行交换,这时的冒泡排序是一个稳定的排序算法。
选择排序
选择排序的原理是从未排序部分选择最小的一个元素放到已排序部分的后一个位置,最后使得数组有序的过程。
跟冒泡排序一样,我们分析选择排序时也是对数组{5,4,3,1,8,2}进行排序,整个排序过程如下图所示。
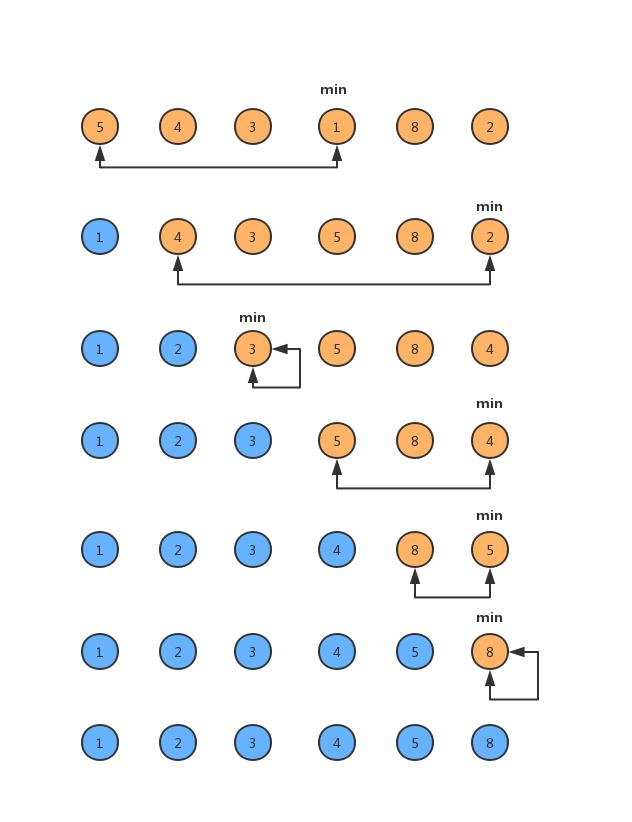
经过6次循环,完成了数组排序,具体实现代码如下:
public static int[] SelectSort(int[] array) {
for(int i = 0;i < array.length; i++) {
int index = i;
for(int j = i; j < array.length ;j++) {
// 找出每一轮的最小值
if(array[j] < array[index]) {
index = j;
}
}
// 和已排序部分的后一个位置进行交换
int temp = array[i];
array[i] = array[index];
array[index] = temp;
}
return array;
}
通过上面的排序过程图和代码对选择排序进行分析。
1.时间复杂度
选择排序的最好情况时间复杂度、最坏情况和平均情况时间复杂度都是O(n^2)。因为原数组无论是否有序,进行排序时都是需要每一个元素对进行比较,当比较完成后还要进行一次交换,所以每一种情况的时间复杂度都是O(n^2)。
2.空间复杂度
因为只需要用到临时空间,所以是一个原地排序算法,空间复杂度为O(1)。
3.稳定性
如下图所示,我们排序{5,5',1},得知排序后两个5的位置已经交换,所以不是稳定排序。
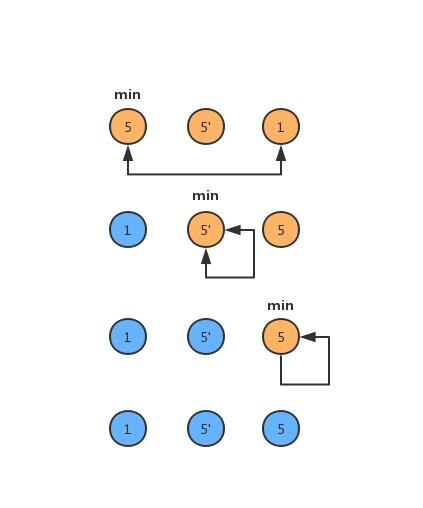
插入排序
先想一下,当我们往有序数组里面插入一个元素,并且使得它插入后保持数组的有序性,我们应该如何操作呢?如下图。
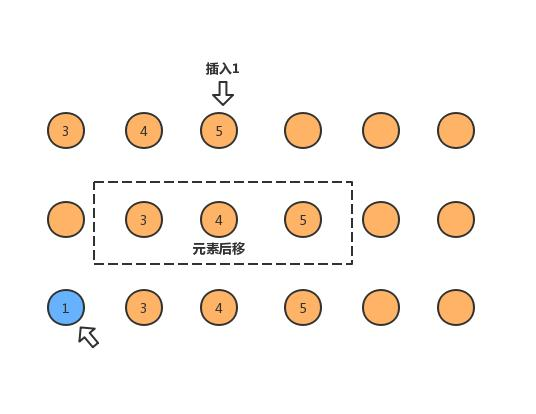
插入排序就是上面图示的操作,从无序数组中拿到一个元素,然后往有序数组里面寻找它的位置,然后插入,有序数组元素加一,无序数组减一,直至无序数组的长度为0。
同上两个排序算法一样,我们使用插入排序对数组{5,4,3,1,8,2}进行排序,流程如下图所示。
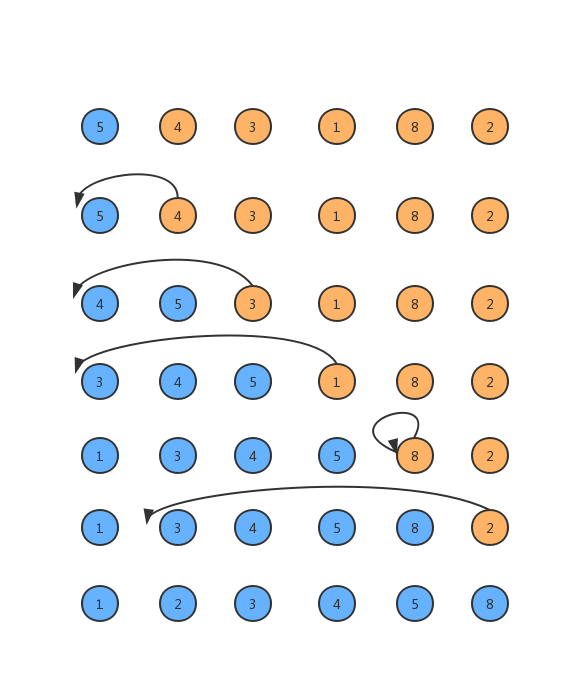
如上述流程可以知道,每一次从无序数组中抽第一个元素,缓存起来,然后在从已排序的最后一个元素开始比较,当该元素大于已排序元素,已排序元素后移一位,直到遇到比他小的元素,然后在比他小的元素的后一个位置插入缓存起来的元素,这样已排序数组增加一个元素,未排序数组减少一个元素,直至结束。
综上,可以得知算法如下:
public void insertSort(int[] arr, int n) {
if (n <= 0) {
return;
}
for (int i = 0; i < n; i++) {
int temp = arr[i];
// 从有序数组的最后一个元素开始往前找
int j=i-1;
while(j>=0) {
if (arr[j] > temp) {
// 如果当前元素大于temp,则后移
arr[j+1] = arr[j];
j--;
} else {
// 如果当前元素小于temp,说明temp比前面所有都要大
break;
}
}
// 插入
arr[j+1] = temp;
}
}
通过上面的排序过程图和代码对插入排序进行分析。
1.时间复杂度
最好时间复杂度为当数组为有序时,为O(n);最坏时间复杂度为当数组逆序时,为O(n^2)。已知,往一个有序数组插入一个元素的平均时间复杂度为O(n),那么进行了n次操作,所以平均时间复杂度为O(n^2)。
2.空间复杂度
插入排序为原地排序,所以空间复杂度为O(1)。
3.稳定性
插入排序每一次插入的位置都会大于或者等于前一个元素,所以为稳定排序。
三者比较
经过上述对三个时间复杂度均为O(n^2)的算法进行分析,可以知道它们的差异如下表所示:
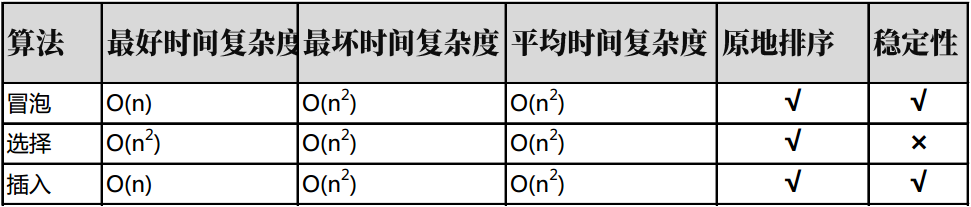
通过对比可以看到,冒泡和插入排序都是优于选择排序的,但是插入排序往往会比冒泡排序更容易被选择使用,这是为什么呢?
虽然说冒泡和插入在时间复杂度、空间复杂度、稳定上表现都是一样的,但是我们别忽略了一个事情,我们求出来的时间复杂度是忽略了系数、常数和低阶参数的,回看代码我们知道,冒泡和插入在进行交换元素的时候分别是如下这样的,假如一次赋值操作耗时为K,那么冒泡排序执行一次交换元素就需要3K时间,而插入排序只需要K。
// 冒泡排序交换元素
int tmp = a[j];
a[j] = a[j+1];
a[j+1] = tmp;
// 插入排序交换元素
arr[j+1] = arr[j];
当然,这只是理论分析,当我用我自己的机器,分别用冒泡和插入算法对10000个同样的数组(每个数组200个元素),进行排序,冒泡排序耗时490ms,插入排序耗时8ms,所以可见插入排序由于每次比较的耗时比较短,所以整体来说耗时也会比冒泡要少。
总结
虽然这三种排序的复杂度较高,达到O(n^2),冒泡和选择排序也不可能使用到应用实践中去,都只能停留在理论研究上,而插入排序还是以其原地排序和稳定性能够在某些特定的场景中使用。
