

项目背景
公司内部封装了NLP通用算法的GRPC服务,比如文本情感识别、文本分类、实体识别等, 提供给大数据等其他部门实时调用。
RPC 服务的调用日志,通过Filebeat、Logstash 实时发送到Elasticsearch,现在需要通过对日志的调用情况实时统计分析,判断调用情况是否出现异常,并对异常情况能够实时告警。
业务场景分析
使用ES 的watcher 插件创建一个threshold alert, 设置预警规则,当一个时间周期内的数据量达到阈值, 就进行告警。
这种方案优点是,设置起来比较简单,只要设置query的条件,以及阈值就可以快速完成。 缺点是,这种方案比较适合粗粒度,并且阈值明确的情况下设置。
设想一下,如果要做到分钟级实时监控,并且对异常点进行告警通知,如果用规则来设置,很难满足这种场景。 针对这种场景,很容易想到,使用Machine Learning (ML)的方法,根据以往的数据变化趋势,来主动发现异常点,那就简单多了。
针对这种需求, 有很多解决方案,比如,把日志实时发送到KAFKA,再用FlinkML 来做机器学习,训练异常检测模型, 不过多讨论这种方案。 如题, 这里介绍一种更简单的方案,使用 ES Stack 提供的 ML 模块, 很容在ES Stack上快速体验AIOps。
实践经验
Requirements
- ELK 6.4.3
- Xpack Machine Learning
日志结构
{
"@timestamp": "2019-10-09T09:10:22.547Z",
"@version": "1",
"call_day": "20191009",
"call_hour": "2019100909",
"call_minute": "201910090910",
"call_time": "10-09 09:10:21.714317",
"cost": 0.004031,
"method": "Nlp.ContentCategory",
"month": "10",
"service_name": "mg",
"timestamp": "2019-10-09T09:10:22.547Z"
}
- @timestamp 日志写入时间,后面的时序统计就是依据这个时间字段
- cost 调用方法消耗时间,可以利用这个字段的平均值来预测方法耗时是否异常
- method 调用的方法
- service_name 调用的服务名称
目的
- 使用历史日志数据,训练异常检测模型,并找出异常的点
- 使用训练出来的模型,检测后面的实时日志数据,发现新的异常点,并进行告警
步骤
创建Job
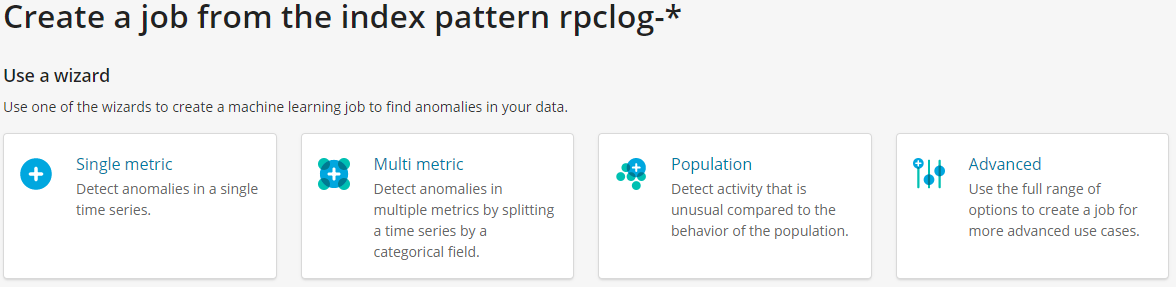
有四种创建ML Job的模式:
- 单指标模式:使用单一指标作为模型特征参数
- 多指标模式:使用多指标作为模型特征参数
- 种群分析模式:种群分析,找出不合群的点
- 高级模式:可以灵活的设置各种模型指标
为了简单起见,这里使用单一指标模式来创建ML Job
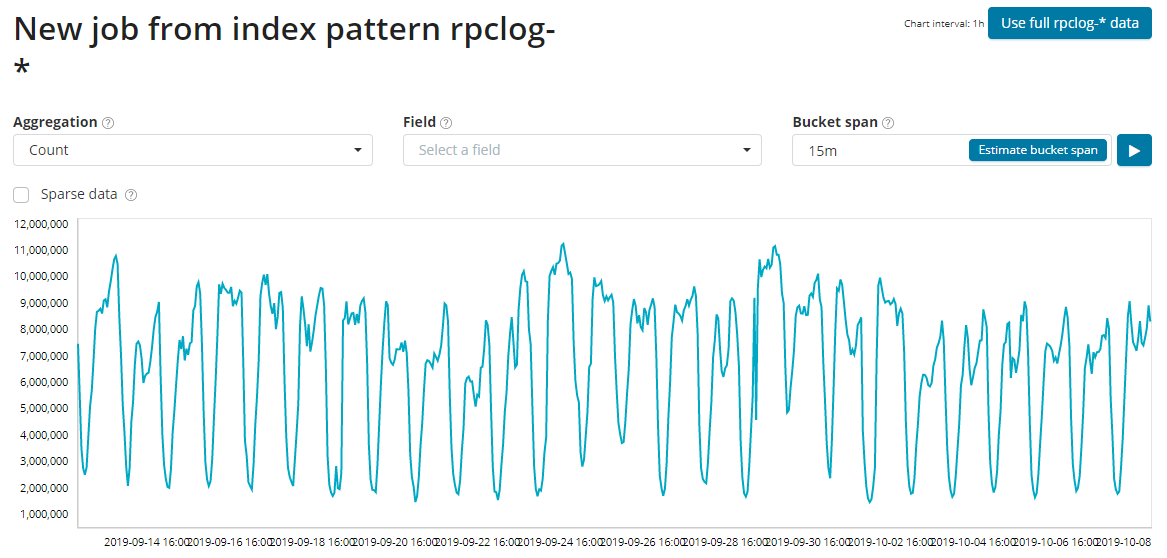
- 选择时间段,尽量选择足够长的时间段,提供足够多的数据喂给ML模型
- Aggregate: 聚合统计的方法,Count、High Count、Low Count、Mean、High Mean、Low Mean等,这里选择 Count方法, 表示统计特定时间窗口数据量,如果检测点的数据量超过模型计算值上下边界值的,都算作是异常点
- Bucket Span 统计的时间窗口大小
配置告警阈值
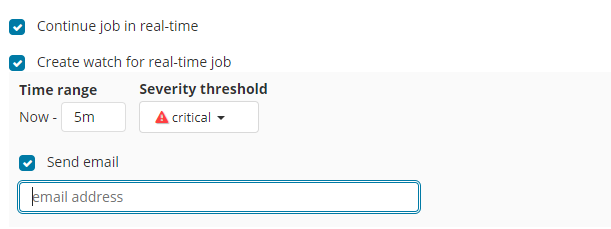
针对检测结果的严重程度进行邮件告警
查看检测结果

通过Anomaly Explorer 可以很容易找到异常的点
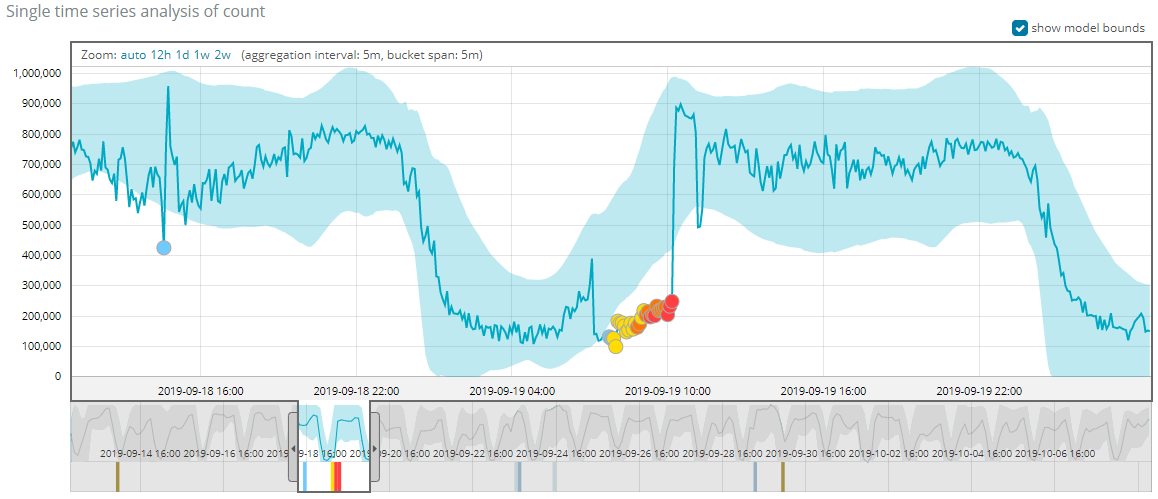
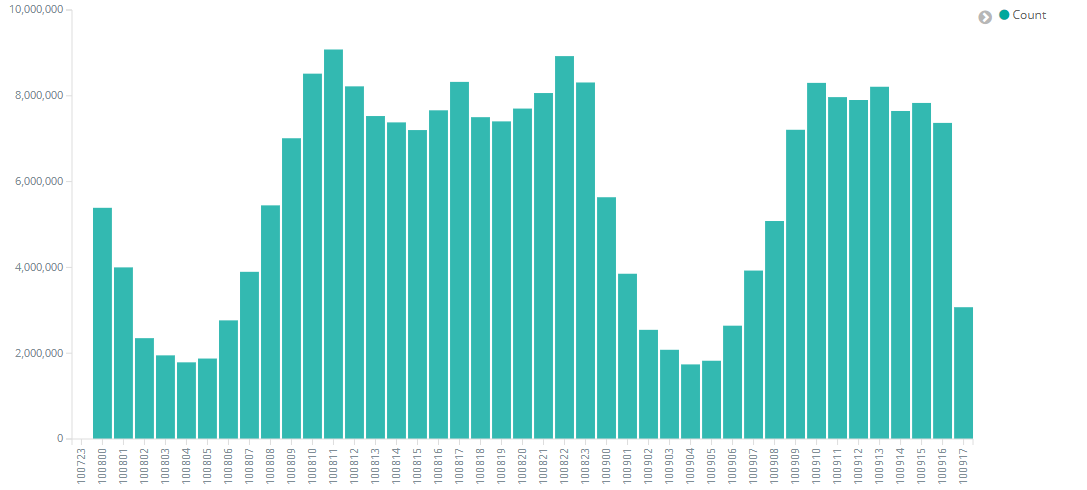
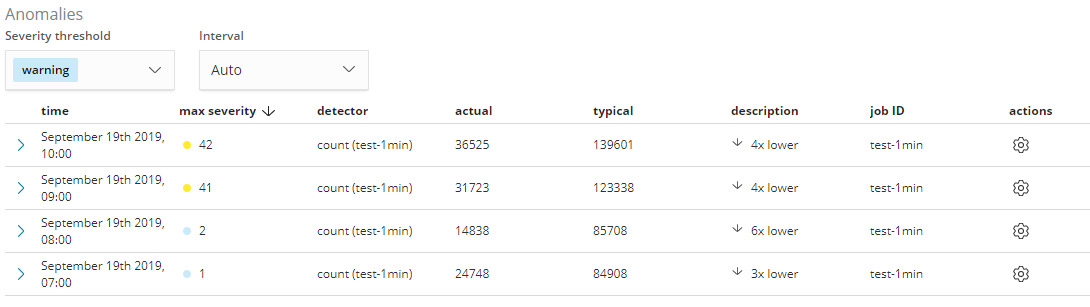
同时,通过Metric Viewer也很直观的查看异常周边的变化趋势,下面举例介绍一下,2019-09-19异常点的情况
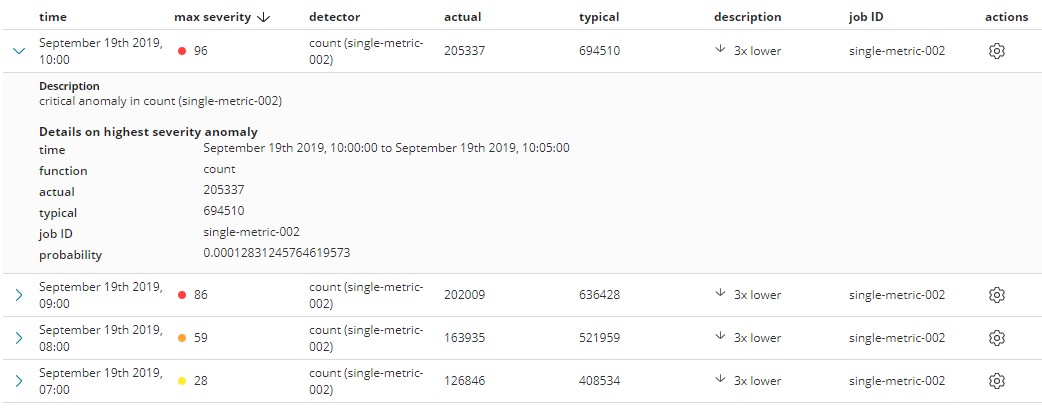
从上图可以看出,在10:00/09:00/08:00/07:00 分别检测出了不同程度的异常, 其中severity值的大小,表明了异常的严重程度,severity值越大,说明这个异常越偏离正常情况。
probability是事情发生的概率,值越小,这个事件发生的可能性越小,从而说明如果这个事件发生了,肯定是不寻常的,跟上面severity反应的情况也是自洽的。
typical 是典型值,就是根据以往数据学习的模型,预测这个时间段的数据量是应该是多少
actual 是实际值,是这个时间段的统计的真实数据量,如果跟typical差异越大,出现异常的可能性就越大
产生结果解释
上述的检测结果来自真实业务场景,在7点到10点之间的业务调用方出现异常,导致在7点到10点之间的RPC服务日志产生量减少。ML 通过对以往数据的特征的学习,对这个时间段的日志量进行预测,发现实际结果与预测结果不符合。 在10点以后,业务调用方恢复正常,预测的结果跟实际调用量也是相吻合,在最终的结果图上也是反映回到正常曲线。
Bucket Span 调优
Bucket (桶) ,在进行实时数据流分析的时候,使用桶来区分指定时间窗口的数据,桶的大小,反映了每个窗口的数据量的大小, 也就是每次给ML喂的数据量的大小。
上面的结果是对桶大小进行调优后的效果,选择的Bucket Span 是5min, 最初选择的Bucket Span是15min, 没有把异常点很好的检测出来。
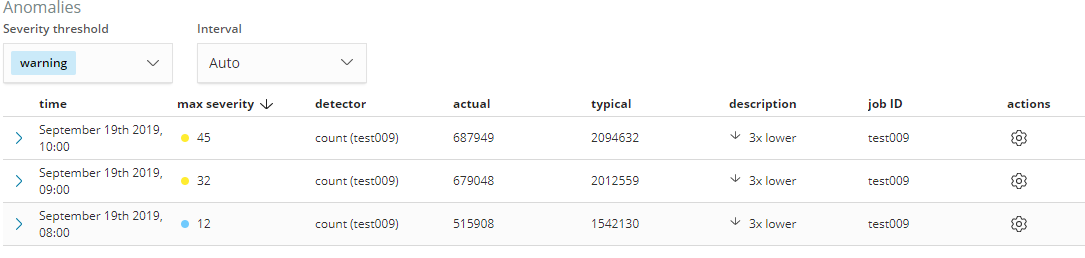
上图桶大小是15min,从图上可以看出来,没有把7点这个异常点检测出来,同时异常的重要程度不够。
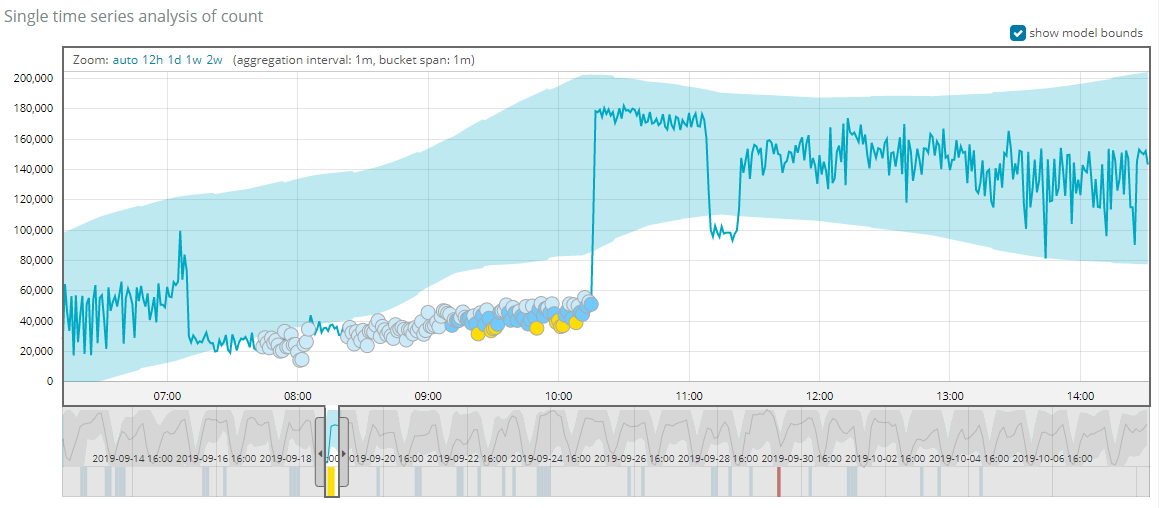
设置1min的效果,同样不能把异常点检测很好的出来,而且受到噪音的干扰比较大,检测到很多严重程度很低的小的异常点。
调优参考:
-
桶的大小不宜设置太小,如果太小,虽然喂给ML的数据变多,但是在很小的时间段内,数据的变化比较频繁,产生大量的噪音,不利于模型的学习。反之,如果桶的大小设置太大了,将会丢掉很多细节信息,而且可能导致喂给ML的数据量不足,甚至把某个异常点给丢掉了。桶的大小要根据业务场景来,如上的场景,想尽快发现调用的异常,在数据量比较充足的情况下,设置5min是比较合适的。当然,这也不是绝对的情况,需要不断地调整这个值的大小,找到合适的值。
-
ES ML 提供了一键预估(Estimate bucket span) Bucket大小,但是这个功能并不是很智能,不能完全依赖,还需要自己不断调试
-
尽量给ML喂更多充足的数据,数据量太少,ML不能很好的拟合数据,预测的结果也是不准确的
-
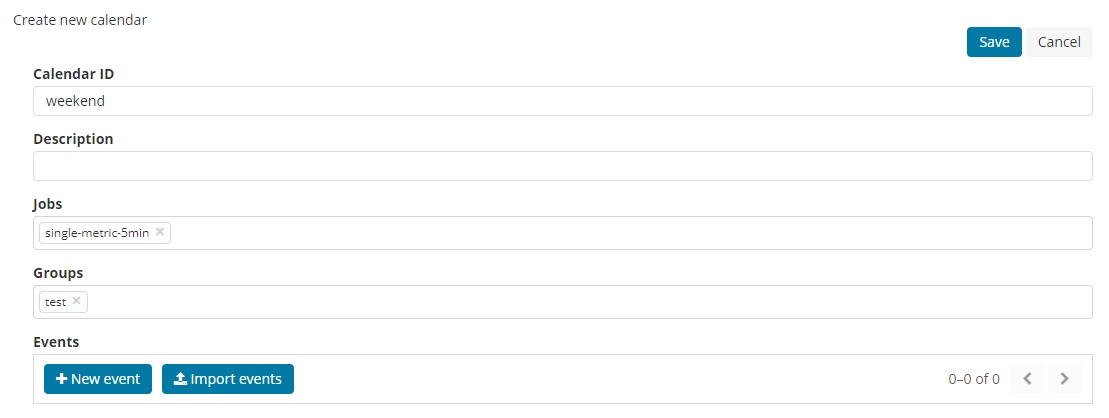
排除掉一些已知的“异常”数据,比如,周末的数据调用量下降很多,如果也直接喂给模型的话,会对预测结果产生干扰。好在,ES 提供了calendar功能,可以把特定时间段的移除,这个时间段的数据不算做异常。
-
使用多指标模式,选择更多的影响因子,使训练出来的模型更加健壮
-
由于数据不断变化,持续把更多更新的数据喂给模型,使其能够学习到新的特征,以适应新的数据
总结
一个完善的AIOps体系还有很多工作要做,上述只是整个体系中一小块,好在ES Stack现在越来越完善,下一步可以考虑把APM、Machine Learning整合起来,使用APM 对系统性能进行监控,使用ML对系统的各项指标进行建模,预测机器的使用趋势,并做到动态伸缩。
