

晓查 一璞 发自 凹非寺
量子位 报道 | 公众号 QbitAI
“我要转PyTorch!”
看到1.3版本的新特性之后,有开发者在推特上喊。
今天是PyTorch开发者大会第一天,PyTorch 1.3率先公布。

新的版本不仅能支持安卓iOS移动端部署,甚至还能让用户去对手Google的Colab上调用云TPU。
不方便薅Google羊毛的国内的开发者,PyTorch也被集成在了阿里云上,阿里云全家桶用户可以更方便的使用PyTorch了。
此外还有一大波新工具,涉及可解释性、加密、以及关于图像语音的诸多功能。
又兼容又有新工具,怪不得有普通铁杆粉丝感叹:自己对Facebook开源库的“忠诚度”越来越高了。
牛逼!可能是个人感觉吧,Facebook比Google在开源库方面好多了,而且各方支持也是最好的。
React对比Angular,Pytorch对比Tensorflow。这就是其中两个例子,Facebook框架上市晚,但得到了强有力的支持,不断改进,而Google的框架虽然出来得早但没啥兼容升级,最终成为弃子。
我对Facebook开源库的“忠诚度”一直在增长。
PyTorch 1.3新功能
PyTorch 1.3带来了三个实验性的新功能。
命名张量
允许用户给张量维度命名,从而让张量更易用,这样就可以直接喊他们的名字,不用根据位置来跟踪张量维度。
升级之前,你需要在代码里写注释来给张量命名:
# Tensor[N, C, H, W]
images = torch.randn(32, 3, 56, 56)
images.sum(dim=1)
images.select(dim=1, index=0)升级之后,就直接能在代码里写了,这样可读性大大提高:
NCHW = [‘N’, ‘C’, ‘H’, ‘W’]
images = torch.randn(32, 3, 56, 56, names=NCHW)
images.sum('C')
images.select('C', index=0)另外,这项功能还能自动检查API是否被正确的使用,提升了安全性,还可以直接用名字来重新排列尺寸。
你可以这样命名:

也可以这样命名:

用align_to就可以重新排序:

是不是方便多了?
量化支持
开发ML应用程序时,有效利用服务器端和设备上的计算资源非常重要。
为了支持在服务器和边缘设备上进行更有效的部署,PyTorch 1.3现在支持用eager模式进行8位模型量化。所谓量化,是指降低精度执行计算和存储的技术。

当前处于实验性的量化功能包括对后训练量化(post-training quantization)、动态量化(dynamic quantization)和量化感知训练(quantization-aware training)的支持。它分别利用了x86和ARM CPU的FBGEMM和QNNPACK最新的量化内核后端,这些后端与PyTorch集成在一起,并且现在共享一个通用API。
具体的API文档可以参阅:
Quantization - PyTorch master documentationpytorch.orgFacebook提供了一个量化的实际案例供开发者参考:
https://pytorch.org/tutorials/advanced/dynamic_quantization_tutorial.htmlpytorch.org移动端
另外,为了在边缘设备上高效的运行机器学习,PyTorch 1.3支持端到端的工作流,从Python到部署在iOS和安卓端。

当然,这个功能还是早期实验版本,针对端到端做了优化,新版本重点在:
1、大小优化,根据用户需要构建级别优化和选择性编译。
2、提升了移动CPU和GPU上的性能。
3、高级API:扩展移动原生API,覆盖常用预处理、将机器学习合并到移动应用需要的集成任务,比如计算机视觉或者NLP的任务。
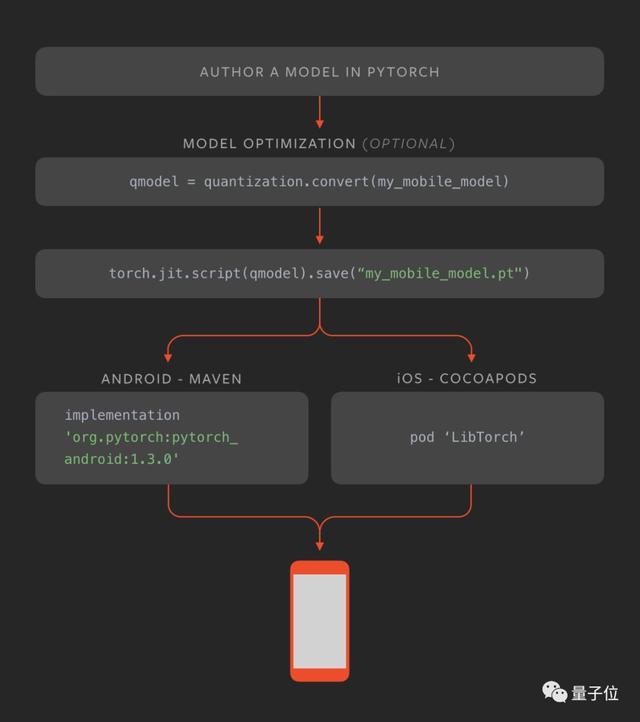
移动端部署细节:
PyTorchpytorch.org新工具
可解释性工具Captum
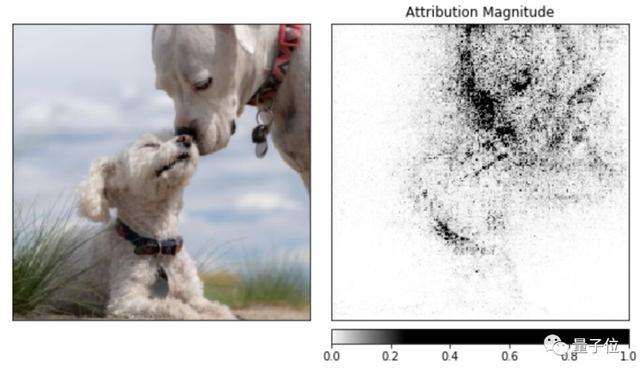
随着AI模型变得越来越复杂,开发用于模型可解释性的新方法变得越来越重要。为了满足这种需求,Facebook推出了Captum。
Captum可以帮助使用PyTorch的开发者了解为什么他们的模型生成某个特定输出。Captum提供了先进的工具来理解特定神经元和层如何影响模型做出的预测。
Captum的算法包括integrated gradients、conductance、SmoothGrad、VarGrad和DeepLift。
下面的案例展示了如何在预训练的ResNet模型上应用模型可解释性算法,然后通过将每个像素的属性叠加在图像上,使其可视化。
noise_tunnel = NoiseTunnel(integrated_gradients)
attributions_ig_nt, delta = noise_tunnel.attribute(input, n_samples=10, nt_type='smoothgrad_sq', target=pred_label_idx)
_ = viz.visualize_image_attr_multiple(["original_image", "heat_map"],
["all", "positive"],
np.transpose(attributions_ig_nt.squeeze().cpu().detach().numpy(), (1,2,0)),
np.transpose(transformed_img.squeeze().cpu().detach().numpy(), (1,2,0)), cmap=default_cmap,
show_colorbar=True)
了解更多:
加密工具CrypTen
通过基于云或机器学习即服务(MLaaS)平台的ML的实际应用提出了一系列安全和隐私挑战。
这些平台的用户可能不希望或是无法共享未加密数据,这使他们无法充分利用机器学习工具。为了应对这些挑战,机器学习社区正在探索各种成熟度不同的技术方法。这些包括同态加密(homomorphic encryption)、安全多方计算(secure multiparty computation)、可信执行环境(trusted execution environments)、设备计算(on-device computation)和差分隐私(differential privacy)。

为了更好地理解如何应用其中的某些技术,Facebook发布了CrypTen,这是一个新的基于社区的研究平台,用于推动隐私保护ML领域的发展。
CrypTen的更多细节:
https://ai.facebook.com/blog/crypten-a-new-research-tool-for-secure-machine-learning-with-pytorchai.facebook.com目前CrypTen已经在GitHub上开源:
facebookresearch/CrypTengithub.com多模AI系统工具
如今网上的数字内容通常不是单一形式,而是由多种形式共同组成,可能包含文本、图像、音频和视频。PyTorch提供了新的工具和软件库生态系统,来处理机器学习ML系统。
Detectron2
Detectron2是在PyTorch中实现的目标检测库。它以增强的灵活性帮助计算机视觉研究,并改善可维护性和可伸缩性,以支持在生产中的用例。

更多细节:
https://ai.facebook.com/blog/-detectron2-a-pytorch-based-modular-object-detection-library-ai.facebook.comGitHub:
facebookresearch/detectron2github.com
Fairseq的语音扩展
语言翻译和音频处理是系统和应用程序(例如搜索,翻译,语音和助手)中的关键组件。由于变压器等新架构的发展以及大规模的预训练方法的发展,最近在这些领域取得了巨大的进步。

Facebook已经扩展了Fairseq(语言翻译等seq2seq应用框架),包括对语音和音频识别任务的端到端学习的支持。fairseq的这些扩展可以加快对新语音研究的探索和原型开发。
GitHub:
pytorch/fairseqgithub.com云端支持
今天的开发者大会上,另一个激动人心的消息是,PyTorch宣布了对谷歌云TPU的全面支持,以及阿里云对PyTorch的集成。此外,PyTorch还将新增了对两家AI硬件的支持,扩展了了自己的硬件生态。
谷歌云TPU
在Facebook、Google和Salesforce的工程师共同努力下,新版的PyTorch加入对了云TPU支持,包括对超级计算机云TPU Pods的实验性支持。谷歌Colab还提供了对云TPU的PyTorch支持。
阿里云
阿里云的集成涉及PyTorch 1.x的一键式解决方案,数据科学Workshop notebook服务,使用Gloo/NCCL进行的分布式训练,以及与阿里巴巴IaaS(如OSS、ODPS和NAS)的无缝集成。
硬件生态扩展
除了主要的GPU和CPU合作伙伴之外,PyTorch生态系统还支持专用的机器学习加速器。比如英特尔不久前推出的NNP-I推理芯片、Habana Labs的AI处理器。
这两家公司分别在博客中展示了自家硬件对PyTorch Glow优化编译器的支持,使开发人员能够利用这些特定于市场的解决方案。
回馈AI社区
最后Facebook感谢AI社区对PyTorch生态做出的贡献,过去一段时间里,一些开发者的优秀开源项目让PyTorch框架受益。比如:
1、Mila SpeechBrain:多合一语音工具包
《Kaldi拜拜!PyTorch语音工具包SpeechBrain要来了,支持多种语音任务,实现最强水准》
2、SpaCy:用于NLP的高级软件库
3、HuggingFace PyTorch-Transformers:用于NLP的最新的预训练模型库。
《一个API调用27个NLP预训练模型:BERT、GPT-2全囊括,像导入NumPy一样容易》
4、PyTorch Lightning:一个类似Keras的ML库
《在PyTorch上用”Keras”,分布式训练开箱即用,告别没完没了的Debug》
最近,Facebook举行了首次在线的全球PyTorch夏季黑客马拉松,共有近1500名开发者参加了比赛。Facebook在今天公布了获奖项目,他们分别是:
1、Torchmeta:提供了PyTorch的扩展,简化PyTorch中元学习算法的开发。
2、Open-Unmix:使用PyTorch进行端到端音乐混合的系统。
3、Endless AI-Generated Tees:这是一家向全球售卖AI设计T恤的商店。他们使用由PyTorch构建的StyleGAN,接受现代艺术的训练。
— 完 —
量子位 · QbitAI
վ'ᴗ' ի 追踪AI技术和产品新动态
戳右上角「+关注」获取最新资讯↗↗
如果喜欢,请分享or点赞吧~比心❤
