

本项目来自实验楼《楼+ 数据分析与挖掘实战》第6期学员 Miss_candy。《楼+数据分析与挖掘实战》是实验楼以满足数据分析或数据挖掘初级工程师职位需求而定制的课程内容。包含 35 个实验,20 个挑战,5 个综合项目,1 个大项目。6 周时间,让你入门数据分析与挖掘。
数据读取
数据是在2019-08-27日取得的,08-28~08-29号的酒店价格,酒店价格会随着旅游淡旺季有浮动变化,目前大连属于季节转换的交界处,价格水平趋于合理但仍比正常水平偏高。
import pandas as pd
import jieba
from tqdm import tqdm_notebook
from wordcloud import WordCloud
import numpy as np
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings('ignore')
df = pd.read_csv('https://s3.huhuhang.com/temporary/b1vzDs.csv')
df.shape
输出:
(2475, 7)
数据清洗
#获取的数据会有重复的情况,首先根据酒店的名字将一项,将名称完全相同的项从数据表中删除
df = df.drop_duplicates(['HotelName'])
df.info()
输出:
<class 'pandas.core.frame.DataFrame'>
Int64Index: 2219 entries, 0 to 2474
Data columns (total 7 columns):
Unnamed: 0 2219 non-null int64
index 2219 non-null int64
HotelName 2219 non-null object
HotelLocation 2219 non-null object
HotelCommentValue 2219 non-null float64
HotelCommentAmount 2219 non-null int64
HotelPrice 2219 non-null float64
dtypes: float64(2), int64(3), object(2)
memory usage: 138.7+ KB
经过删除重复项后,获得的酒店信息包含2219条有效信息, 其中5列有效信息分别为:
- “HotelName” 酒店名称
- “HotelLocation” 酒店所在位置的区命
- “HotelCommentValue” 酒店在评分
- “HotelCommentAmount" 酒店已获得的评价条数
- "HotelPrice" 酒店的最低价格
由于一部分酒店由于新开业(或其他途径原因),暂时没有评分数(没有评分数的酒店在数据获取的过程中赋值”0“),因此,我们将这部分数据单独取出来,作为new_hotel数据集,用于后续的一些分析和预测。
df_new_hotel = df[df["HotelCommentValue"]==0].drop(['Unnamed: 0'], axis=1).set_index(['index'])
df_new_hotel.head()
输出
对于已有评分的酒店,也从原始数据集中分离出来,用于分析和建模。
df_in_ana = df[df["HotelCommentValue"]!=0].drop(["Unnamed: 0", "index"], axis=1)
df_in_ana.shape
输出:
(1669, 5)
数据分析
import matplotlib.pyplot as plt
import matplotlib
import seaborn as sns
%matplotlib inline
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
sns.distplot(df_in_ana['HotelPrice'].values)
输出:
<matplotlib.axes._subplots.AxesSubplot at 0x7f7353b9c240>
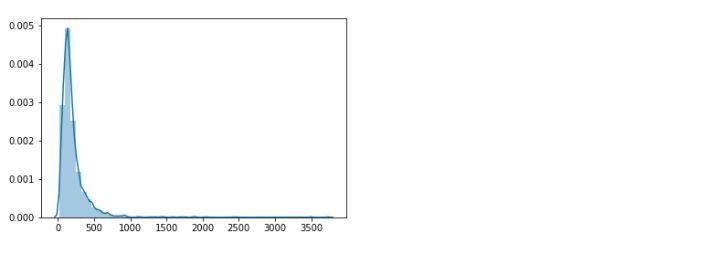
通过对酒店价格的分布情况进行可视化,大概可知, 大部分的酒店价格集中在500元/晚以下,其中以200-300元/每晚的价格最为集中;500元/晚以上的酒店就不怎么多了。 因此,这里根据价格分布以及实际的物价水平,将酒店根据价格情况划分为以下几个等级:
- ”廉价“型酒店,每晚价格低于100元
- "经济“型酒店,每晚价格在100-300元
- ”舒适“型酒店,每晚价格在300-500元
- ”高端“型酒店,每晚价格在500-1000元
- "奢华“型酒店,每晚价格在1000元以上
df_in_ana['HotelLabel'] = df_in_ana["HotelPrice"].apply(lambda x: '奢华' if x > 1000 else \
('高端' if x > 500 else \
('舒适' if x > 300 else \
('经济' if x > 100 else '廉价'))))
划分之后,先来大概了解一下不同类型的酒店的数量占比情况:
hotel_label = df_in_ana.groupby('HotelLabel')['HotelName'].count()
plt.pie(hotel_label.values, labels=hotel_label.index, autopct='%.1f%%', explode=[0, 0.1, 0.1, 0.1, 0.1], shadow=True)
输出:
([<matplotlib.patches.Wedge at 0x7f735196bf28>,
<matplotlib.patches.Wedge at 0x7f7351974978>,
<matplotlib.patches.Wedge at 0x7f735197d358>,
<matplotlib.patches.Wedge at 0x7f735197dcf8>,
<matplotlib.patches.Wedge at 0x7f73519096d8>],
[Text(1.0995615668223722, 0.0310541586125, '奢华'),
Text(0.8817809341165916, 0.813917922292212, '廉价'),
Text(-1.1653378183544278, -0.28633506441395257, '经济'),
Text(0.9862461234793722, -0.6836070391108557, '舒适'),
Text(1.1898928807304072, -0.15541857156431768, '高端')],
[Text(0.5997608546303848, 0.016938631970454542, '0.9%'),
Text(0.5143722115680117, 0.47478545467045696, '21.9%'),
Text(-0.679780394040083, -0.16702878757480563, '62.0%'),
Text(0.5753102386963004, -0.3987707728146658, '11.0%'),
Text(0.6941041804260709, -0.09066083341251863, '4.1%')])

从饼图的结果可知,有超过50%的酒店是经济型的,21.9%的酒店则属于廉价型,高端和奢华型的比例相应较少,比较符合旅游城市的一般定位。
下面再来了解一下酒店的地理位置分布情况:
from pyecharts import Map
map_hotel = Map("大连酒店区域分布图", width=1000, height=600)
hotel_distribution = df_in_ana.groupby('HotelLocation')['HotelName'].count().sort_values(ascending=False)
hotel_distribution = hotel_distribution[:8]
h_values = list(hotel_distribution.values)
district = list(hotel_distribution.index)
map_hotel.add("", district, h_values, maptype='大连', is_visualmap=True,
visual_range=([min(h_values), max(h_values)]),
visual_text_color="#fff", symbol_size=20, is_label_show=True)
map_hotel.render('dalian_hotel.html')
在这里,由于从网站获取位置信息时,部分酒店的位置信息本身填写并不规范,导致获取得到的信息呈现一定的差异化,由于这些差异化的信息并不方便进行统一的规划,并且其所占比例不大,因此在sort之后处于比较靠后的位置,我们只截取靠前的8个主要区域的信息,可以看到,对于目前已经收集到酒店,大部分的酒店位于沙河口区,金州区,与大连主要景点的分布直接相关,比如知名的星海广场,跨海大桥位于沙河口区,金石滩以及发现王国则位于金州区。(实际上,高新园区在map上并没有对应的内容,因为它不属于行政区域,而是作为甘井子区和沙河口区交接处的一个技术开发区,其占比对沙河口区和甘井子区都没有影响, 并不妨碍我们对数据进行分析)。
大连酒店区域分布图
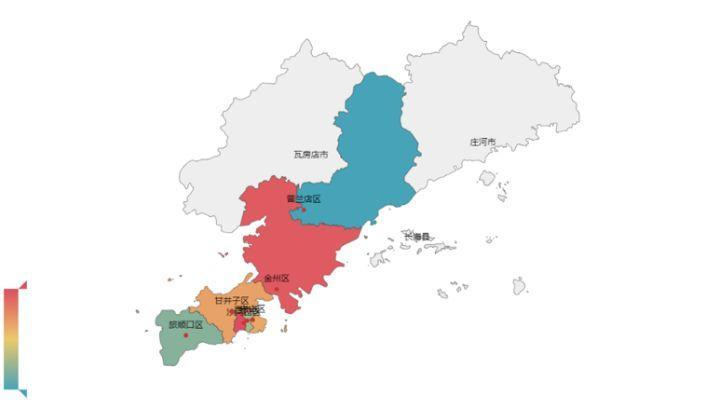
大连是一个旅游城市,不同行政区(地理位置),酒店的定位和水平应该也是不相同的,因此,了解各种档次的酒店在不同区域的分布是一个很有意思的问题:
hotel_distribution = df_in_ana.groupby('HotelLocation')['HotelName'].count().sort_values(ascending=False)
hotel_distribution = hotel_distribution[:8]
hotel_label_distr = df_in_ana.groupby([ 'HotelLocation','HotelLabel'])['HotelName'].count().sort_values(ascending=False).reset_index()
in_use_district = list(hotel_distribution.index)
hotel_label_distr = hotel_label_distr[hotel_label_distr['HotelLocation'].isin(in_use_district)]
fig, axes = plt.subplots(1, 5, figsize=(17,8))
hotel_label_list = ['高端', '舒适', '经济', '奢华', '廉价']
for i in range(len(hotel_label_list)):
current_df = hotel_label_distr[hotel_label_distr['HotelLabel']==hotel_label_list[i]]
axes[i].set_title('{}型酒店的区域分布情况'.format(hotel_label_list[i]))
axes[i].pie(current_df.HotelName, labels=current_df.HotelLocation, autopct='%.1f%%', shadow=True)
通过各种档次酒店在不同地区的分布情况可知,各类型酒店在沙河口区、金州区以及中山区都是优势分布的,比较有趣的是,奢华型酒店在旅顺口区是没有分布的,这种类型的酒店除了在沙河口区比较集中之外,还在中山区占有相当大的比例,这和历史地理原因有很大的关系,大连人常说,中山区是传说中的”富人区“,许多商务型出行的人会把住地选在中山区,也促进的这一地区在高端、奢华系酒店的投入增长。
除了对酒店价格(档次)的要求之外,我们在出行定酒店时也会考虑酒店的评价情况,评分越高,评价越多的,我们会更倾向于预订,因此,针对有评分的数据集,我们来看一看大连这些酒店的情况。
首先根据评分情况结合消费者对评分的一般认知,对于酒店进行一下标注:
- 4.6分以上的为”超棒“
- 4.0-4.6分的为”还不错“
- 3.0-4.0分的为“一般般”
- 3.0分以下的为“差评”
df_in_ana['HotelCommentLevel'] = df_in_ana["HotelCommentValue"].apply(lambda x: '超棒' if x > 4.6 \
else ('还不错' if x > 4.0 \
else ('一般般' if x > 3.0 else '差评' )))
根据评分等级和酒店档次聚类,我们对数据进行可视化。
hotel_label_level = df_in_ana.groupby(['HotelCommentLevel','HotelLabel'])['HotelName'].count().sort_values(ascending=False).reset_index()
fig, axes = plt.subplots(1, 5, figsize=(17,8))
for i in range(len(hotel_label_list)):
current_df = hotel_label_level[hotel_label_level['HotelLabel'] == hotel_label_list[i]]
axes[i].set_title('{}型酒店的评分情况'.format(hotel_label_list[i]))
axes[i].pie(current_df.HotelName, labels=current_df.HotelCommentLevel, autopct='%.1f%%', shadow=True)
由各类型酒店的评价分布情况可知, 差评主要出现在廉价型酒店和经济型酒店,而其中以廉价型酒店为差评重灾区,对于每晚最低价格300以上的舒适型,高端型和奢华型酒店,基本没有差评的出现,也印证了“钱花在哪哪就好“的一般认知,其中以奢华型酒店的好评(”超棒“)比例最高。评价”超棒“的比例并没有随着酒店档次的升高而提高,对于高端型酒店,其”超棒“评价的比例相对价格更低的舒适型酒店反而有所下降,原因也许是人们对酒店价格所对应的服务期待值大于酒店实际能够提供的服务水平,一方面提醒消费者不要盲目认为贵就是好,一方面提醒酒店,有多少能耐就做多少能耐对应的事,价格虚高不可取。
酒店清单
根据目前的内容,我们可以制作一份”种草清单“和”防踩雷清单“:
”种草清单“主要收集各档次酒店中评价好,评价条数多(多人检验,符合要求),价格相应合理的酒店名单,供各种不同出行需求的朋友选择; ”防踩雷清单“则主要收集差评酒店,提醒大家不要勇于”试错“”碰运气“。
种草清单
# 廉价酒店
df_pos_cheap = df_in_ana[(df_in_ana['HotelLabel']=='廉价') \
& (df_in_ana['HotelCommentValue']> 4.6) \
& (df_in_ana['HotelCommentAmount']> 500)].sort_values(by=['HotelPrice'], ascending=False)
df_pos_cheap
输出:
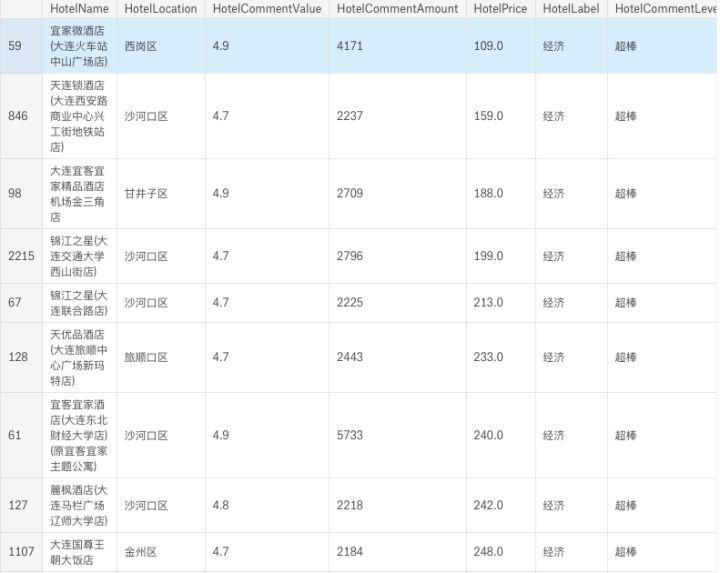
# 经济型酒店
df_pos_economy = df_in_ana[(df_in_ana['HotelLabel']=='经济') \
& (df_in_ana['HotelCommentValue']> 4.6) \
& (df_in_ana['HotelCommentAmount']> 2000)].sort_values(by=['HotelPrice'])
df_pos_economy
输出:
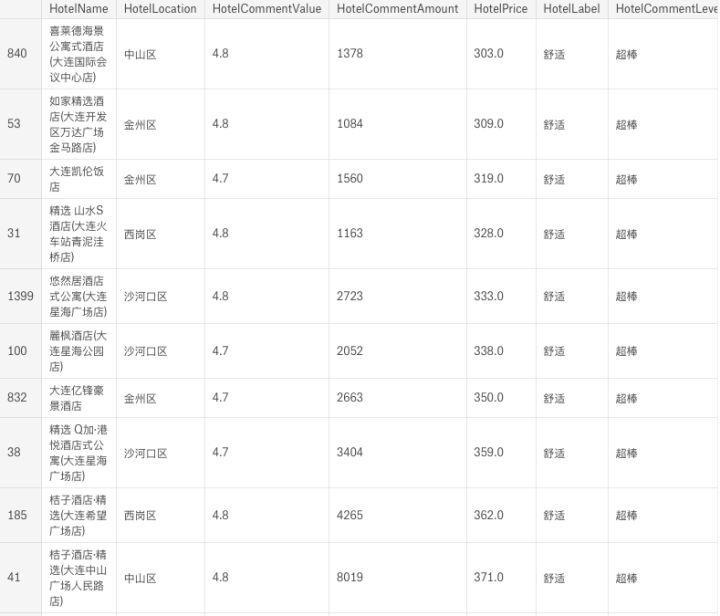
# 舒适型酒店
df_pos_comfortable = df_in_ana[(df_in_ana['HotelLabel']=='舒适') \
& (df_in_ana['HotelCommentValue']> 4.6) \
& (df_in_ana['HotelCommentAmount']> 1000)].sort_values(by=['HotelPrice'])
df_pos_comfortable
输出:
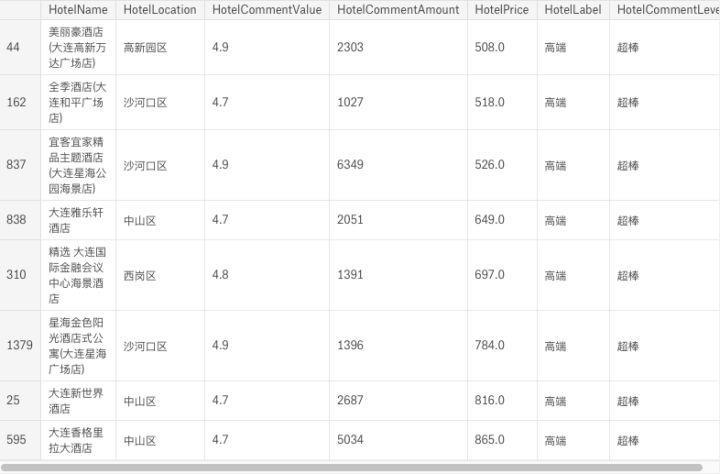
# 高端酒店
df_pos_hs = df_in_ana[(df_in_ana['HotelLabel']=='高端') \
& (df_in_ana['HotelCommentValue']> 4.6) \
& (df_in_ana['HotelCommentAmount']> 1000)].sort_values(by=['HotelPrice'])
df_pos_hs
输出:
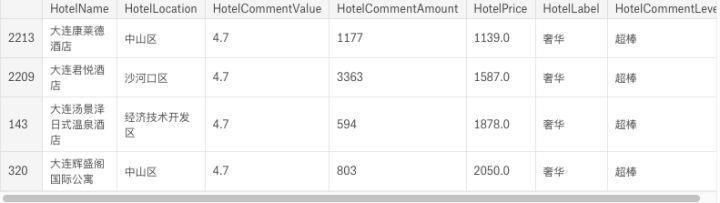
# 奢华酒店
df_pos_luxury = df_in_ana[(df_in_ana['HotelLabel']=='奢华') \
& (df_in_ana['HotelCommentValue']> 4.6) \
& (df_in_ana['HotelCommentAmount']> 500)].sort_values(by=['HotelPrice'])
df_pos_luxury
输出:
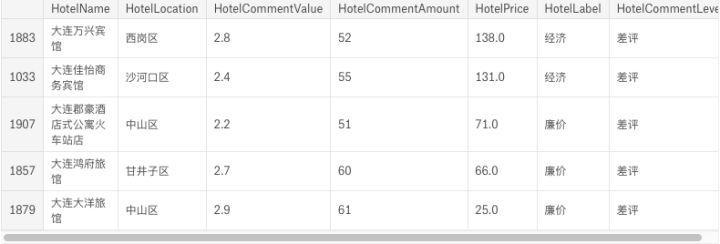
雷区清单
df_neg = df_in_ana[(df_in_ana['HotelCommentValue'] < 3.0) \
& (df_in_ana['HotelCommentAmount'] > 50)].sort_values(by=['HotelPrice'], ascending=False)
df_neg
输出:
酒店名字的科学
对于处于比较极端的酒店类型,比如很贵很贵的高端型酒店,一般是走商务典雅大气风格,名字听起来就会觉得很”贵“; 而便宜一些的,依靠价格走流量的,针对学生或经济基础比较差的人群,名字要么走小清新的路子,要么就简单粗暴,一听就是”划算“,我们通过词云来验证一下,这个理论对于大连地区的酒店是否符合。
wget -nc "http://labfile.oss.aliyuncs.com/courses/1176/fonts.zip"
unzip -o fonts.zip
from wordcloud import WordCloud
def get_word_map(hotel_name_list):
word_dict ={}
for hotel_name in tqdm_notebook(hotel_name_list):
hotel_name = hotel_name.replace('(', '')
hotel_name = hotel_name.replace(')', '')
word_list = list(jieba.cut(hotel_name, cut_all=False))
for word in word_list:
if word == '大连' or len(word) < 2:
continue
if word not in word_dict:
word_dict[word] = 0
word_dict[word] += 1
font_path = 'fonts/SourceHanSerifK-Light.otf'
wc = WordCloud(font_path=font_path, background_color='white', max_words=1000,
max_font_size=120, random_state=42, width=800, height=600, margin=2)
wc.generate_from_frequencies(word_dict)
return wc
为了保证绘制词云的数据量充足,这里不按照原来的酒店档次划分标准来选取数据,而是选择价格低于150的酒店和高于500的酒店,作为两个相对极端的类型,看看他们在起名上有没有什么典型的区别。
part1 = df_in_ana[df_in_ana['HotelPrice'] <= 150]['HotelName'].values
part2 = df_in_ana[df_in_ana['HotelPrice'] > 500]['HotelName'].values
fig, axes = plt.subplots(1, 2, figsize=(15, 8))
axes[0].set_title('价格较低酒店的名字词云')
axes[0].imshow(get_word_map(part1), interpolation='bilinear')
axes[1].set_title('价格较高酒店的名字词云')
axes[1].imshow(get_word_map(part2), interpolation='bilinear')
输出:
<matplotlib.image.AxesImage at 0x7f73515c1908>
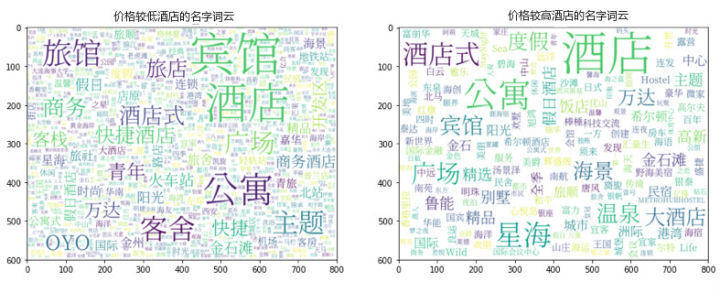
从结果来看,两类酒店的店名词云还是有明显差异的。 价格低廉的酒店,名字中出现”客舍“, ”主题“,”青年“,”快捷酒店“,”旅馆“, ”旅店“等次的频率较高,符合我们对这类酒店的定位认知; 高端的酒店,名字中包含”星海“,”海景“,”温泉“,”广场“的频率较高,由于大连比较知名的地标是沙河口区的星海广场,附近的酒店(特别是高档酒店),非常喜欢在名字中体现”星海“这个词,除了突出地理位置之外,似乎也能通过这个词给酒店增加一些格调。另外,高端酒店似乎不太喜欢给自己起名字叫”xx宾馆“,更喜欢叫”酒店“或”酒店式公寓“。 比较疯狂的一点是,无论是便宜一些的酒店,还是贵一点的酒店,都很喜欢”公寓“这个词。这似乎也是目前酒店事业发展的一种趋势。
看名识酒店
名字作为人或事物的一种象征,由它引起的第一印象是非常重要的,我们刚刚分析了比较极端的酒店类型在名字上的特点,在一定程度上,可以根据名字在判断酒店是否处于一定的档次,”三岁看一生”,对于刚刚开始运行,没有评分的小白酒店,我们可以根据对其价格的预测结果判断一下酒店的定价方案是否符合其定位,之前我们分析了不同档次酒店的评价特点,结合这些已知结果,大概的了解一下这些小白酒店是否具有标价虚高,或者是否值得我们当一次小白鼠,走一条“发现之路”。 不过这里面另外涉及到一个问题,新开的酒店因为环境和时代原因,在起名字的策略上会和之前的酒店产生差异,这种差异在建模预测的过程中会产生比较显著的影响,因此,这里我们只是利用学习过的方法,做一个有趣的实验,结果不会准确,但过程是很有趣的:)
df_in_ana['HotelPrice'].median()
输出:
156.0
通过前面的词云分析和已有评价的酒店的价格中位数,我们将价格150设为划分阈值,价格低于150元/晚的酒店,标注为1,而高于这个价格的,标注为0,这样的划分方式,使得两部分的数据量基本均衡,也在一定程度上体现出酒店名称的差异。
df_in_ana['PriceLabel'] = df_in_ana['HotelPrice'].apply(lambda x:1 if x <= 150 else 0)
df_new_hotel['PriceLabel'] = df_new_hotel['HotelPrice'].apply(lambda x:1 if x <= 150 else 0)
# 设定分词方式
def word_cut(x):
x = x.replace('(', '') # 去掉名称中出现的()
x = x.replace(')', '')
return jieba.lcut(x)
#设置训练集和测试集
x_train = df_in_ana['HotelName'].apply(word_cut).values
y_train = df_in_ana['PriceLabel'].values
x_test = df_new_hotel['HotelName'].apply(word_cut).values
y_test = df_new_hotel['PriceLabel'].values
训练集包含1669条信息,标注为1的数据共790条, 测试集包含550条信息,标注为1的数据共195条。
# 通过Word2Vec方法建立词向量浅层神经网络模型,并对分词之后的酒店名称进行词向量的求和计算
from gensim.models import Word2Vec
import warnings
warnings.filterwarnings('ignore')
w2v_model = Word2Vec(size=200, min_count=10)
w2v_model.build_vocab(x_train)
w2v_model.train(x_train, total_examples=w2v_model.corpus_count, epochs=5)
def sum_vec(text):
vec = np.zeros(200).reshape((1, 200))
for word in text:
try:
vec += w2v_model[word].reshape((1, 200))
except KeyError:
continue
return vec
train_vec = np.concatenate([sum_vec(text) for text in tqdm_notebook(x_train)])
# 构建神经网络分类器模型,并使用training data对模型进行训练
from sklearn.externals import joblib
from sklearn.neural_network import MLPClassifier
from IPython import display
model = MLPClassifier(hidden_layer_sizes=(100, 50, 20), learning_rate='adaptive')
model.fit(train_vec, y_train)
# 绘制损失变化曲线,监控损失函数的变化过程
display.clear_output(wait=True)
plt.plot(model.loss_curve_)
输出:
[<matplotlib.lines.Line2D at 0x7f73400b8198>]
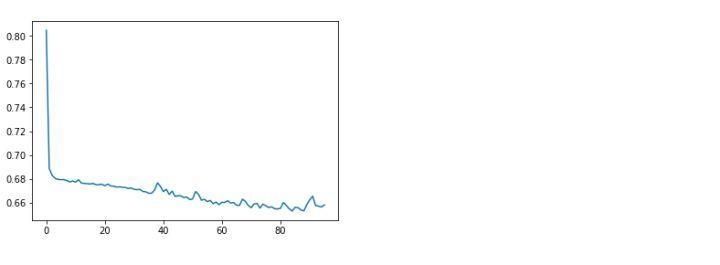
ps:因为数据量少,且数据本身所包含的信息相对不足,在这里,训练的结果并不太好。
# 之后对测试集进行词向量求和
test_vec = np.concatenate([sum_vec(text) for text in tqdm_notebook(x_test)])
# 用训练好的模型进行预测, 将结果倒入测试用表中
y_pred = model.predict(test_vec)
df_new_hotel['PredLabel'] = pd.Series(y_pred)
# 建模预测的结果
from sklearn.metrics import accuracy_score
accuracy_score(y_pred, y_test)
输出:
0.6163636363636363
实际上,预测的准确率只有60%左右,是一个相当不理想的结果,我们将数据展开,主要的原因在哪里。
new_hotel_questionable = df_new_hotel[(df_new_hotel['PriceLabel'] ==0) & (df_new_hotel['PredLabel']==1)]
new_hotel_questionable = new_hotel_questionable.sort_values(by='HotelPrice', ascending=False)
new_hotel_questionable
输出:
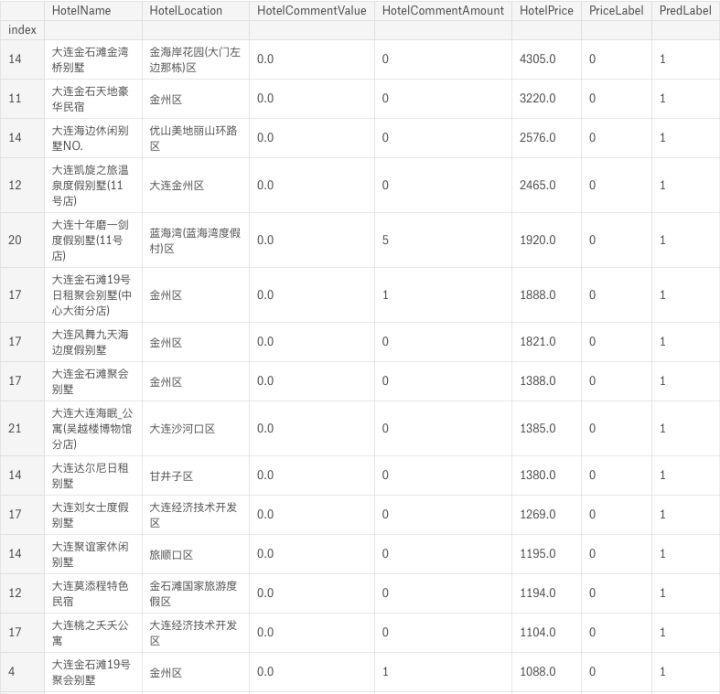
分歧比较明显的结果显示,很多新开的酒店,特别是价格很高的,都是“别墅”类型的度假型酒店,这一类型在已经评价的数据集中体现并不明显,建模的分类器对其不敏感,错分的可能就会大大增加。
plt.figure(figsize=(15, 7))
plt.imshow(get_word_map(new_hotel_questionable['HotelName'].values), interpolation='bilinear')
输出:
<matplotlib.image.AxesImage at 0x7f7333b06d68>
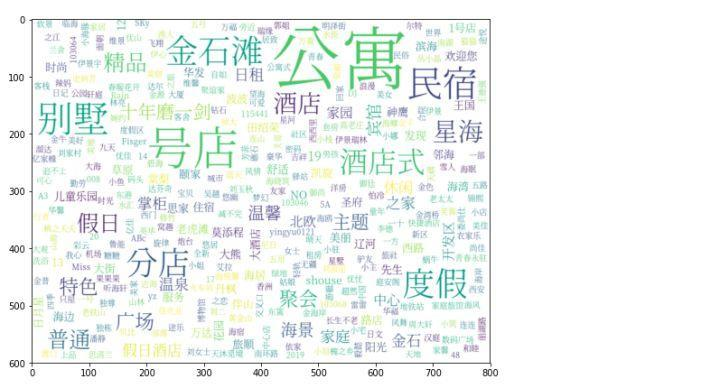
绘制词云来看新开的酒店们,其在名称上与建模所用的数据集相比,增加了一些原来没有的词,比如“号店”,“分店”,“别墅”等,导致预测的准确率下降。
认识新酒店
除开对名字方面的认识,我们还可以了解一下新开的这些酒店在地理位置的分布和均价的变化上有什么体现。
new_hotel_distri = df_new_hotel.groupby('HotelLocation')['HotelName'].count().sort_values(ascending=False)[:7]
plt.pie(new_hotel_distri.values, labels=new_hotel_distri.index, autopct='%.1f%%', shadow=True)
输出;
([<matplotlib.patches.Wedge at 0x7f7333ae1240>,
<matplotlib.patches.Wedge at 0x7f7333ae1c50>,
<matplotlib.patches.Wedge at 0x7f7333ae9630>,
<matplotlib.patches.Wedge at 0x7f7333ae9fd0>,
<matplotlib.patches.Wedge at 0x7f7333af29b0>,
<matplotlib.patches.Wedge at 0x7f7333afd390>,
<matplotlib.patches.Wedge at 0x7f7333afdd30>],
[Text(0.4952241217848982, 0.9822184427113841, '金州区'),
Text(-1.0502523061308453, 0.32706282801144143, '甘井子区'),
Text(-0.7189197652449374, -0.8325589295300148, '沙河口区'),
Text(0.10878704263418966, -1.0946074087794706, '旅顺口区'),
Text(0.6457239222346646, -0.8905282793117135, '中山区'),
Text(0.9702662169179598, -0.5182503915171803, '西岗区'),
Text(1.0890040760087287, -0.1551454879665377, '普兰店区')],
[Text(0.2701222482463081, 0.5357555142062095, '35.1%'),
Text(-0.5728648942531882, 0.17839790618805892, '20.1%'),
Text(-0.39213805376996586, -0.4541230524709171, '16.8%'),
Text(0.059338386891376174, -0.597058586606984, '9.0%'),
Text(0.35221304849163515, -0.4857426978063891, '7.8%'),
Text(0.5292361183188871, -0.2826820317366438, '6.6%'),
Text(0.5940022232774883, -0.08462481161811146, '4.5%')])
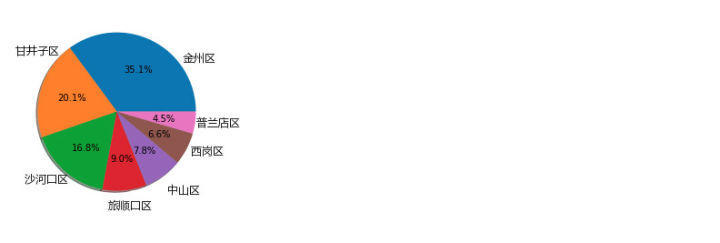
由饼图可以发现,有超过30%的新酒店选择了金州区,沙河口区作为老牌的酒店扎堆地,只有16%的从业者将新店选择在这里。
df_new_hotel['HotelLabel'] = df_new_hotel["HotelPrice"].apply(lambda x: '奢华' if x > 1000 \
else ('高端' if x > 500 \
else ('舒适' if x > 300 \
else('经济' if x > 100 \
else '廉价'))))
new_hotel_label = df_new_hotel.groupby('HotelLabel')['HotelName'].count()
plt.pie(new_hotel_label.values, labels=new_hotel_label.index, autopct='%.1f%%', explode=[0, 0.1, 0.1, 0.1, 0.1], shadow=True)
输出:
([<matplotlib.patches.Wedge at 0x7f7333abbdd8>,
<matplotlib.patches.Wedge at 0x7f7333a44828>,
<matplotlib.patches.Wedge at 0x7f7333a4d208>,
<matplotlib.patches.Wedge at 0x7f7333a4dba8>,
<matplotlib.patches.Wedge at 0x7f7333a59588>],
[Text(1.0859612910752763, 0.17518011955161772, '奢华'),
Text(0.6137971106588083, 1.0311416522218948, '廉价'),
Text(-1.1999216970224413, 0.01370842860376746, '经济'),
Text(0.46080283077562195, -1.1079985339111122, '舒适'),
Text(1.1494416996723409, -0.3446502271207151, '高端')],
[Text(0.5923425224046961, 0.09555279248270056, '5.1%'),
Text(0.3580483145509714, 0.6014992971294385, '22.7%'),
Text(-0.6999543232630907, 0.007996583352197684, '44.0%'),
Text(0.26880165128577943, -0.6463324781148153, '18.9%'),
Text(0.6705076581421987, -0.20104596582041712, '9.3%')])

除了适合大多数出行者会选择的经济实惠的低价酒店外,高端奢华型酒店的投入比例在新开酒店中也有明显的提高,结合前面对新开酒店的词云分析,越来越多的酒店从业者投入了高端酒店的建设,以别墅型度假酒店为主要体现,体现出人们对品质和更加舒适的出行体验的的追求。
价格上,也有一些比较有趣的结果:
df2 = df_new_hotel.groupby('HotelLabel')['HotelPrice'].mean().reset_index()
df1=df_in_ana.groupby('HotelLabel')['HotelPrice'].mean().reset_index()
price_change_percent = (df2['HotelPrice'] - df1['HotelPrice'])/df1['HotelPrice'] * 100
plt.title('新开各档次酒店均价变化')
plt.bar(df1['HotelLabel'] ,price_change_percent, width = 0.35)
plt.ylim(-18, 18)
for x, y in enumerate(price_change_percent):
if y < 0:
plt.text(x, y, '{:.1f}%'.format(y), ha='center', fontsize=12, va='top')
else:
plt.text(x, y, '{:.1f}%'.format(y), ha='center', fontsize=12, va='bottom')
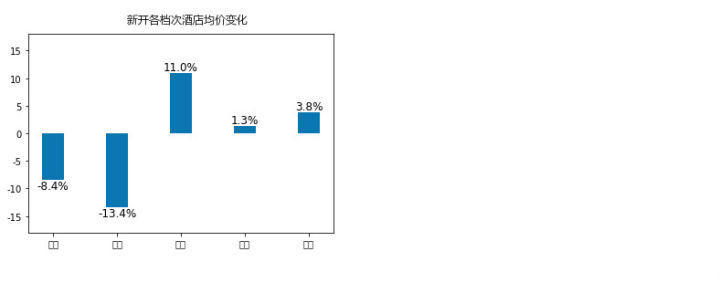
新开酒店相对于已有评价的老牌酒店来说,均价的变化表现在:
- 奢华和廉价型酒店的均价均有下降
- 中间型酒店,包括经济型, 舒适性和高端型酒店,均价有所上涨
两个极端等级的酒店均以“降低身价”的方式获得关注度来博取入住率,以获得长足的发展, 而中间型酒店,以改变经营理念,顺应时代潮流等方式获得涨价的资本,只是其最终的发展效果仍取决于旅客对其的认同。
总结
本次实验以大连地区的酒店作为分析数据,挖掘了包括价格情况、区域分布情况等信息,提供了已有评价的酒店的“种草清单”和“防踩雷清单”(妈妈再也不用担心有朋友来大连烦恼定酒店的问题啦!),进行酒店店名的词云分析,挖掘了店名和酒店档次的相关性,并建立分类模型,预测新开的、没有评价的酒店的店名是否与其定价标准相适宜,同时挖掘了新开酒店的区域分布和档次分布情况,对比了其与已有评价酒店的均价变化,侧面了解了一些大连旅游事业发展的情况的思路。由于数据量少,且酒店店名的命名方式与区域、时代环境等有较强的相关性,建模预测部分的效果并不好,但学习了这些内容,将其应用在不同的方面来加深对其的认识也是一件有趣的事情。
