

简介
在 Java 中很多工具类都在使用 CAS(Compare And Set)用以提升并发的效率以及数据的准确性质。
- concurrent 和 concurrent.atomic 下面的很多 AtomicInteger 等类
- concurrent.locks 包下面的 ReentrantLock 、WriteLock 等
- 其它
对于大部分人来说,最常见的应该就是使用 AtomicXXX、以及在使用 Lock 相关的子类 的时候我们知道他们的底层运用了 CAS,也知道 CAS 就是传入一个更新前得期待值(expect)和一个需要更新的值(update),如果满足要求那么执行更新,否则的话就算执行失败,来达到数据的原子性。
我们知道 CAS 肯定用某一种方式在底层保证了数据的原子性,它的好处是
- 不必做同步阻塞的挂起以及唤醒线程这样大量的开销
- 将保证数据原子性的这个操作交给了底层硬件性能远远高于做同步阻塞挂起、唤醒等操作,所以它的并发性更好
- 可以根据 CAS 返回的状态决定后续操作来达到数据的一致性,比如 increment 失败那就一值循环直到成功为止(下文会讲)等等
首先来看一个错误的 increment()
private int value = 0;
public static void main(String[] args) {
Test test = new Test();
test.increment();
System.out.println("期待值:" + 100 * 100 + ",最终结果值:" + test.value);
}
private void increment() {
for (int i = 0; i < 100; i++) {
new Thread(() -> {
for (int j = 0; j < 100; j++) {
value++;
}
}).start();
}
}
输出:期待值:10000,最终结果值:9900
可以发现输出的结果值错误,这是因为 value++ 不是一个原子操作,它将 value++ 拆分成了 3 个步骤 load、add、store,多线程并发有可能上一个线程 add 过后还没有 store 下一个线程又执行了 load 了这种重复造成得到的结果可能比最终值要小。
当然在这里加
volatile int value也是没有用的因为 32 位的 int 操作本身就是原子的,而且 volatile 也没有办法让这 3 个操作原子性执行,它只能禁止某个指令重排序来保证其对应的内存可见,如果是long 等 64 位操作类型的可以加上 volatile,因为在 32 位的机器上写操作可能会被分配到不同的总线事务上去操作(可以想象成分成了 2 步操作,第一步操作前 32 位后一步操作后 32 位),而总线事务的执行是由总线仲裁决定的不能保证它的执行顺序(相当于前者加了 32 位可能就切换到其它的地方执行了,比如直接就读取了,那么数据的读取就只读取到了写入一半的值)
使用 CAS 来保证 increment() 正确
我们知道关于 CAS 的操作基本上都封装在 Unsafe 这个包里面,但是由于 Unsafe 不允许我们外部使用,它认为这是一个不安全的操作,比如如果直接使用 Unsafe unsafe = Unsafe.getUnsafe(); 就会抛出 Exception in thread "main" java.lang.SecurityException: Unsafe。
我们查看下源代码,原来是因为它做了校验
public static Unsafe getUnsafe() {
Class var0 = Reflection.getCallerClass();
if (!VM.isSystemDomainLoader(var0.getClassLoader())) {
throw new SecurityException("Unsafe");
} else {
return theUnsafe;
}
}
所以我们可以通过反射来调用它(当然实际操作中不建议这么使用,此处为了演示方便)
public class Test {
// value 的内存地址,便于直接找到 value
private static long valueOffset = 0;
{
try {
// 这个内存地址是和 value 这个成员变量的值绑定在一起的
valueOffset = getUnsafe().objectFieldOffset
(Test.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
private int value;
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
Test test = new Test();
test.increment();
}
private void increment() throws NoSuchFieldException, IllegalAccessException {
Unsafe unsafe = getUnsafe();
for (int i = 0; i < 100; i++) {
new Thread(() -> {
for (int j = 0; j < 1000; j++) {
unsafe.getAndAddInt(this, valueOffset, 1);
}
}).start();
}
System.out.println("需要得到的结果为: " + 100 * 1000);
System.out.println("实际得到的结果为: " + value);
}
// 反射获取 Unsafe
private Unsafe getUnsafe() throws NoSuchFieldException, IllegalAccessException {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
return (Unsafe) field.get(null);
}
}
这下我们就能从输出中看到结果是正确的了
CAS 底层的实现原理
我们继续探讨, getAndAddInt 调用了 unsafe.compareAndSwapInt(Object obj, long valueOffset, int expect, int update) 这个方法在 Hotspot 到底是如何实现的,我们发现调用的是 native 的 unsafe.compareAndSwapInt(Object obj, long valueOffset, int expect, int update),我们翻看 Hotspot 源码发现在 unsafe.cpp 中定义了这样一段代码
UNSAFE_ENTRY(jboolean, Unsafe_CompareAndSwapInt(JNIEnv *env, jobject unsafe,
jobject obj, jlong offset, jint e, jint x))
UnsafeWrapper("Unsafe_CompareAndSwapInt");
oop p = JNIHandles::resolve(obj);
jint* addr = (jint *) index_oop_from_field_offset_long(p, offset);
return (jint)(Atomic::cmpxchg(x, addr, e)) == e;
UNSAFE_END
从中我们可以看到它是使用了 Atomic::cmpxchg(x, addr, e) 这个操作来完成的,在不同的底层硬件会有不一样的代码 Hotspot 向上帮我们屏蔽了细节。这个实现方法在 solaris,windows,linux_x86 等都有不一样的实现方法,我们用我们最常见的服务器 linux_x86 来说,它的实现代码如下
inline jint Atomic::cmpxchg (jint exchange_value, volatile jint* dest,
jint compare_value) {
int mp = os::is_MP();
__asm__ volatile (LOCK_IF_MP(%4) "cmpxchgl %1,(%3)"
: "=a" (exchange_value)
: "r" (exchange_value), "a" (compare_value), "r" (dest), "r" (mp)
: "cc", "memory");
return exchange_value;
}
从以上代码可以看出几点
- Hotspot 直接调用底层汇编来实现对应的功能
__asm__表示的是后续是一段汇编代码volatile此处的 volatile 和 Java 中的有些区别,这里使用用以告诉编译器不再对这段代码进行汇编优化LOCK_IF_MP表示的是如果操作系统是多核的那么就需要加锁来保证其原子性cmpxchgl就是汇编中的比较并且交换
从这里就能看出来,CAS 底层也是在用锁来保证其原子性的。在 Intel 早期的实现中是直接将总线锁住,这样导致其它没有获得总线事务访问权的处理器无法执行后续的操作,性能会极大的降低。
后续 Intel 对其进行了优化升级,在 x86 处理器中可以只需要锁定 特定的内存地址,那么其它处理器也就可以继续使用总线来访问内存数据了,只不过是如果其它总线也要访问被锁住的内存地址数据时会阻塞而已,这样来大幅度的提升了性能。
但是思考一下以下几点问题的
- 并发量非常高,可能导致都在不停的争抢该值,可能导致很多线程一致处于循环状态而无法更新数据,从而导致 CPU 资源的消耗过高
- ABA 问题,比如说上一个线程增加了某个值,又改变了某个值,然后后面的线程以为数据没有发生过变化,其实已经被改动了
JAVA8 对于 CAS 的优化
当然 ABA 的问题可以使用增加版本号来控制,每次操作版本号 + 1,版本号变更了说明值就被改过一次了,在 Java 中 AtomicStampedReference 这个类提供了这种问题的解决方案。
而对于说第一个问题来说在 Java8 中也有了对应的优化,Java 8 中提供了一些新的工具类用以解决这种问题,如下

我们挑一个来看,其它都是类似的
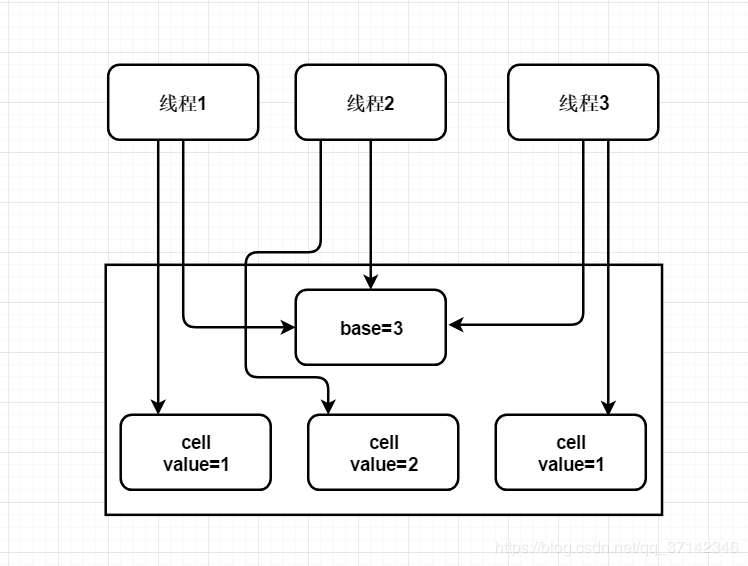
它的原理主要采用CAS分段机制与自动分段迁移机制,最开始是在 base 上面进行 CAS 操作,后续并发线程过多,那么就将这大量的线程分配到 cells 数组中去,每个数组的线程单独去执行累加操作,最终再合并结果
总结
可以看到跟做直接做同步挂起或者唤醒线程相比如果能够合理的使用 CAS 进行操作的话或者是将其二者合并使用,那么在并发性能上能够提升一个量级
- 对于像 ReentrantLock 之类的都是使用的将同步阻塞 + CAS 这种方式来实现高性能的锁,比如 ReentrantLock 中 tryAcuqire() 如果使用 CAS 未能获取到对应的锁,那么就将其放入阻塞队列,等待后续的唤醒
- 比如自旋锁在指定的次数通过 CAS 都未能获取到锁的话就挂起进入阻塞队列等待被唤醒
- 比如使用 AtomicInteger 进行自增的时候就会一值不停的轮询判断更新,直到操作成功为止
- 使用轮询 CAS 处理而不嵌入阻塞挂起和唤醒的话,它的优势就是在于能够快速响应用户请求减少资源消耗,因为线程的挂起和唤醒涉及到用户态内核态的调用又涉及到线程“快照”数据的相关保存,对于响应和资源消耗是又慢又高,不过我们也需要考虑在 CPU 轮询上的开销,所以可以将二者一定程度上的融合在一起使用。
- 所以理解 CAS 还是非常重要的
参考: JAVA 中的 CAS
