

1、事件还原
昨天下午,收到一个504的告警,显然这是一个超时告警。当时由于手头有其他事情,没在意,就只是瞄了一眼,但是引起告警的方法很熟悉,是我写的,第一反应有点诧异。
诧异之后,继续处理手头的工作。
一小时过后,又收到同样的告警,显然不是偶尔,肯定是哪儿出问题了,于是开始排查。
报警的接口是一个Controller层ControllerA的getControllerAMethod接口,其调用了多个微服务,并最终拼装结果数据进行返回。出问题的是ServiceM,ServiceM服务里的getServiceMMethod方法逻辑也很简单,主要是两次数据库查询,从MySQL数据库取到数据并返回给调用方。
调用链如下图所示
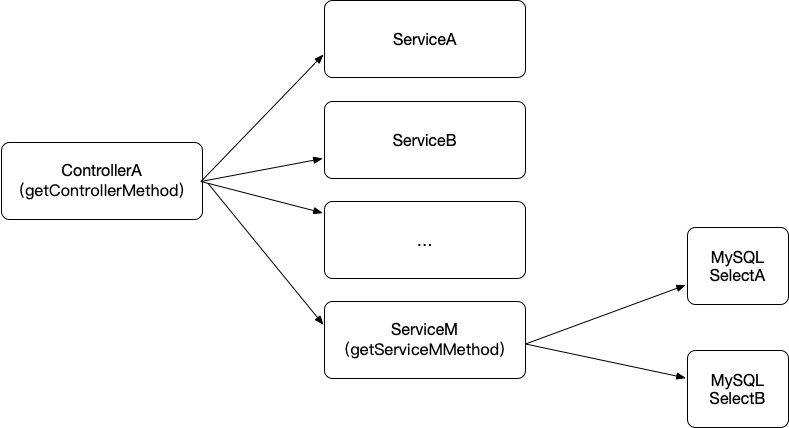
2、环境介绍
**语言:**Go
**DB:**MySQL
**数据库交互:**database/sql(公司在此基础上做了一些定制和封装,本质还是database/sql)
下面开始介绍这个问题的具体排查过程。
3、本能反应:从sql语句入手
拿到告警,从告警信息和对应的日志详情信息来看,属于超时问题。
第一反应是查看sql语句是否是慢查询(虽然打心里知道这个可能性极低),sql语句很简单,形如
select a, b, c from tableA where a in (a1,a2,a3)
不看执行计划也知道是可以命中索引的。
但还是看了下执行计划和真实的执行情况,分析结果和响应时间都相当可观,没有任何问题。
本能反应的排查就是这么索然无味,开始下一步排查。
4、上游排查:是否context时间耗尽
既然是超时问题,有可能是上游超时,也可能是下游超时,第一步排查已经排除了下游因为慢查询导致超时的可能性。
那会不会是上游超时呢?显然是有可能的,毕竟我们知道Go的context可以一路传递下去,所有服务调用都共用设置的总的时间额度。
而且从上图可以发现ServiceM也是在上游接口的最后一步,所以如果上面的服务占用耗时过多,就会导致ServiceM的时间额度被压缩的所剩无几。
但是从日志排查可以发现,在ServiceM层看getServiceMethod方法对应sql查询几乎都是几十毫秒返回。
从这个情况来看,不像是因为上游时间不够导致的超时。
5、下游初步排查:rows成主要怀疑对象
既然上游时间额度充足,那问题还是大概率出在下游服务接口上。
于是开始仔细阅读getServiceMMethod方法代码,下面是代码功能的伪代码实现
rows, err = db.query(sql1)
if err != nil {
...
}
defer rows.Close()
for rows.Next() {
rows.scan(...)
}
rows, err = db.query(sql2)
if err != nil {
...
}
defer rows.Close()
for rows.Next() {
rows.scan(...)
}
看完代码,开始有点小兴奋,我想没错了,大概就是这个rows的问题了。
在《Go组件学习——database/sql数据库连接池你用对了吗》这篇我主要介绍了有关rows没有正常关闭带来的坑。所以开始联想是否是因为在遍历rows过程中没有正确关闭数据库连接,造成连接泄露,以至于后面的查询拿不到连接导致超时。
原因我已经分析的清清楚楚,但是具体是哪一步除了问题呢,唯一能想到的是这里两次查询使用的是同一个rows对象,是不是某种情况导致在前一次已经关闭了连接而下一次查询直接使用了关闭的连接而导致超时呢?
此时报警开始越来越频繁,于是将这里两次查询由原来的一个rows接收改为使用两个rows分别接收并关闭,然后提交代码,测试通过后开始上线。
6、短暂的风平浪静
代码上线后,效果立竿见影。
告警立马停止,日志也没有再出现超时的信息了,一切又恢复到了往日的平静,这让我坚信,我应该是找到原因并解决问题了吧。
回到家后,心里还是有些不踏实,从11点开始,我拿出电脑,开始各种模拟、验证和还原告警的原因。
7、三小时后,意识到风平浪静可能是假象
从11点开始,一直到两点,整整三个小时,我不但没有找到原因,反而发现我的解决方式可能并没有解决问题。
因为出问题的代码并不复杂,如上所示,即只有两个Select查询。
于是我写了一段一样的代码在本地测试,跑完后并没有出现超时或者拿不到连接的情况。甚至,我将maxConn和IdleConn都设置为1也无不会出现超时。
除非,像文章《Go组件学习——database/sql数据库连接池你用对了吗》里说的一样,在row.Next()过程中提前退出且没有rows.Close()语句,才会造成下一次查询拿不到连接的情况,即如下代码所示
func oneConnWithRowsNextWithError() {
db, _ := db.Open("mysql", "root:rootroot@/dqm?charset=utf8&parseTime=True&loc=Local")
db.SetMaxOpenConns(1)
rows, err := db.Query("select * from test where name = 'jackie' limit 10")
if err != nil {
fmt.Println("query error")
}
i := 1
for rows.Next() {
i++
if i == 3 {
break
}
fmt.Println("close")
}
row, _ := db.Query("select * from test")
fmt.Println(row, rows)
}
但是原来的代码是有defer rows.Close()方法的,这个连接最终肯定是会关闭的,不会出现内存泄露的情况。
这一刻,我想到了墨菲定律(因为没有真正解决问题,问题还回再次出现)。
于是,我又开始扒源码,结合日志,发现一条重要线索,就是很多查询任务都是被主动cancel的。没错,这个cancel就是context.Timeout返回的cancel(这段代码是我司在database/sql基础上丰富的功能)。
cancel触发的条件是执行database/sql中的QueryContext方法返回了err
// QueryContext executes a query that returns rows, typically a SELECT.
// The args are for any placeholder parameters in the query.
func (db *DB) QueryContext(ctx context.Context, query string, args ...interface{}) (*Rows, error) {
var rows *Rows
var err error
for i := 0; i < maxBadConnRetries; i++ {
rows, err = db.query(ctx, query, args, cachedOrNewConn)
if err != driver.ErrBadConn {
break
}
}
if err == driver.ErrBadConn {
return db.query(ctx, query, args, alwaysNewConn)
}
return rows, err
}
第一反应还是上游时间不够,直接cancel context导致的,但是这个原因我们在前面已经排除了。
于是把这段代码一直往下翻了好几层,还一度怀疑到我们自研代码中的一个参数叫QueryTimeout是否配置过小,但是去看了一眼配置(这一眼很重要,后面会说),发现是800ms,显然是足够的。
带着越来越多的问题,我心不甘情不愿的去睡觉了。
8、墨菲定律还是显灵了
今天下午一点,我又收到了这个熟悉的告警,该来的总会来的(但是只收到一次告警)。
前面说了,这个cancel可能是一个重要信息,所以问题的原因是没跑了,肯定是因为超时,超时可能是因为拿不到连接。
因为getServiceMMethod已经排查一通了,并没有连接泄露的情况,但是其他地方会不会有泄漏呢?于是排查了ServiceM服务的所有代码,对于使用到rows对象的代码检查是否有正常关闭。
排查后,希望破灭。
到此为止,我打心里已经排除了是连接泄露的问题了。
期间,我还问了我们DBA,因为我翻了下日志,今天上午8点左右有几条查询都在几百毫秒,怀疑是DB状态异常导致的。DBA给我的回复是数据库非常正常。
我自己也看了监控,DB的状态和往日相比没有什么流量异常,也没有连接池数量的大起大落。
同事说了前几天上了新功能,量比以前大,于是我也看了下新功能对应的代码,也没发现问题。
9、准备"曲线救国"
我想要的根本原因还没有找到,于是开始想是否可以通过其他方式来规避这个未知的问题呢。毕竟解决问题的最好方式就是不解决(换另一种方式)。
准备将ServiceM方法的超时时间调大。
也准备在ServiceM服务的getServiceMMethod方法添加缓存,通过缓存来抵挡一部分请求量。
行吧,就到此为止,明天先用这两招试试看。
于是,我准备站起来活动活动,顺便在脑海里盘点下这个告警的来龙去脉。
10、灵机一动,我找到了真相
上游告警,下游超时 ->
排除上游时间不够 ->
排除下游rows未关闭 ->
排除数据库状态不稳定 ->
确定是下游超时 ->
怀疑是拿不到连接 ->
拿不到连接,拿不到连接, 拿不到连接
于是又去翻数据库参数配置,刚上面是为了翻QueryTimeout参数,依稀记得这里的连接池设置不大。翻到配置看了下,idleConn=X,maxConn=Y。
再去看了一眼getServiceMMethod方法的QPS监控,我觉得我找到了真相。
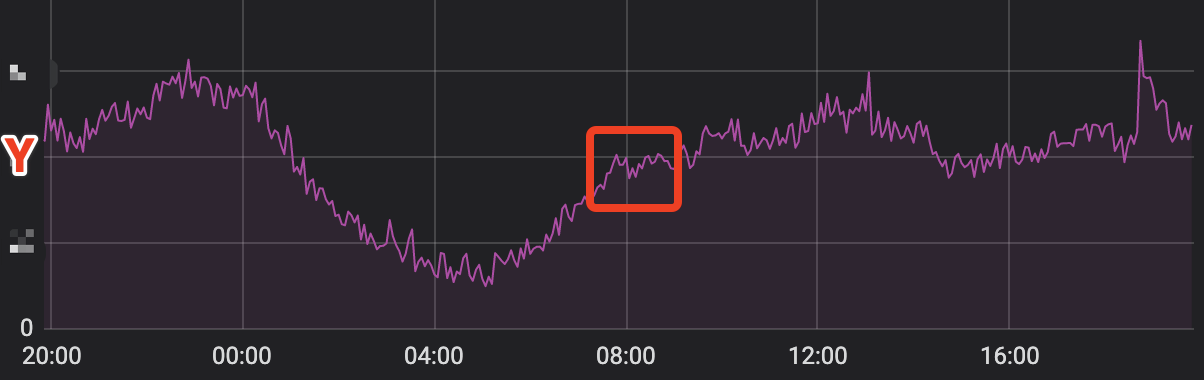
从凌晨到早上八点,QPS一直在上升,一直到8点左右,突破Y,而maxConn=Y。
所以应该是超过maxConn,导致后面的查询任务拿不到连接只能等待,等待到超时时间后还是没有拿到连接,所以触发上面说的cancel,从而也导致在上游看到的超时告警都是ServiceM的getServiceMMethod执行了超时时间,因为一直在等待。
那么为什么图中有超过Y的时候没有一直报警呢,我理解应该是这期间有其他任务已经执行完查询任务将连接放回连接池,后面来的请求就可以直接使用了,毕竟还会有一个超时时间的等待窗口。
那么为什么之前没有出现这种报警呢,我理解是之前量比较小,最近同事上线了新功能,导致该接口被调用次数增加,才凸显了这个问题。
11、总结
其实,最后原因可能很简单,就是量起来了,配置的连接数显得小了,导致后来的查询任务拿不到连接超时了。
但是这个超时横跨Controller层到Service以及最底层的DB层,而每一层都可能会导致超时,所以排查相对比较困难。
下面是一些马后炮要点
- 最近改动的代码需要格外重视。如果以前长时间没有告警,最近上完新代码告警了,大概率和上线有关系(本次超时其实和新上线代码也有关系,虽然代码本身没有问题,但是新上线后流量变大了)
- 善用工具。用好监控和日志等系统工具,从中找出有用的线索和联系。
- 自上而下排查并追踪。针对不好定位的bug,可以按照一定顺序比如调用顺序依次检查、验证、排除,直到找到原因。
个人公众号JackieZheng,欢迎关注~

