

一、概念
声音:这里的声音是指通过麦克风会产生一连串的电压变化,可以得到许多[-1,1]之间的数字。如果想要播放,需转换成pcm格式
PCM:pcm格式通过三个参数来描述【采样频率、采样位数、声道数】,从网上找到一张图:
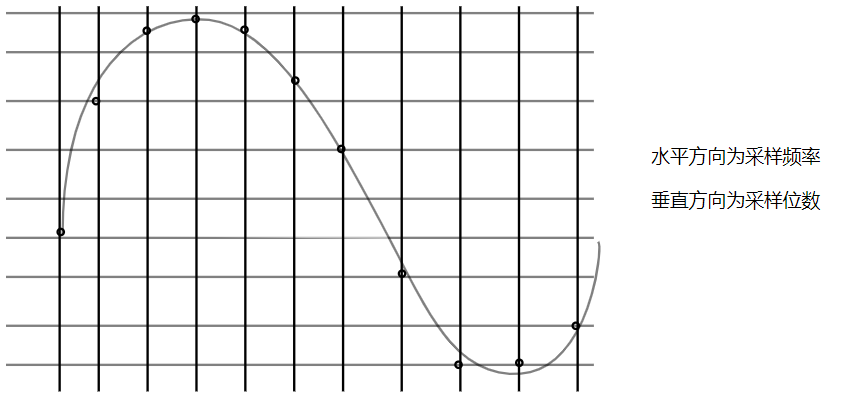
pcm的核心思想水平和垂直分割成若干小块,然后用这些坐标上的点近似的描述一个波(声音)
输入采样频率:指麦克风收集声音的频率,因为麦克风需要将波形的声音转换成[-1,1]的信号,用它来指定在单位时间内收集多少个样本
输出采样频率:单位时间内播放多少个采样,一般保持与输入采样频率一致
二、实践场景
下面实现一个demo,通过google浏览器打开电脑麦克风,利用webrtc相关api录音,然后转换成pcm、wav格式,并且用audio标签进行播放,用cavans画出音域图,大致流程如下:
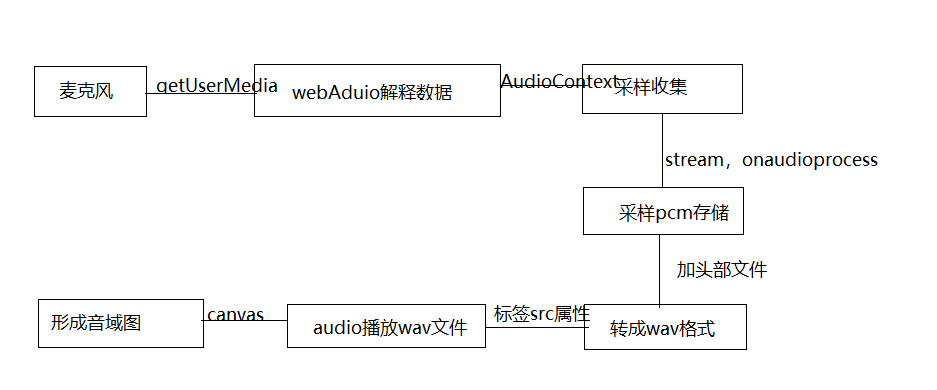
三、实现步骤
1、获取麦克风权限
这里使用的是 navigator.getUserMedia 方法,当然如果只是用谷歌浏览器,可以不用兼容处理,主要结构代码如下
navigator.getUserMedia = navigator.getUserMedia || navigator.webkitGetUserMedia || navigator.mozGetUserMedia || navigator.msGetUserMedia
navigator.getUserMedia({
audio: true // 这里面有video 和 audio 两个参数,视频选择video
}, (stream) => {
<!--这个stream 就是采集pcm数据的音源-->
}, (error) => {
console.log(error)
})
2、pcm数据获取
下面就用 window.AudioContext进行解析麦克风信息,重点用到createMediaStreamSource、createScriptProcessor、onaudioprocess三个方法,具体结构代码如下
<!--首先new一个AudioContext对象,作为声源的载体 -->
let audioContext = window.AudioContext || window.webkitAudioContext
const context = new audioContext()
<!--将声音输入这个对像,stream 就是上面返回音源-->
let audioInput = context.createMediaStreamSource(stream)
<!--创建声音的缓存节点,createScriptProcessor方法的第二个和第三个参数指的是输入和输出都是声道数,第一个参数缓存大小,一般数值为1024,2048,4096,这里选用4096-->
let recorder = context.createScriptProcessor(config.bufferSize, config.channelCount, config.channelCount) // 这里config是自定义,后面会附带源码
<!--此方法音频缓存,这里audioData是自定义对象,这个对象会实现wav文件转换,缓存pcm数据等-->
recorder.onaudioprocess = (e) => {
audioData.input(e.inputBuffer.getChannelData(0))
}
但是在获取的过程中要有个触发点,比如说本实践的demo最终效果图如下:
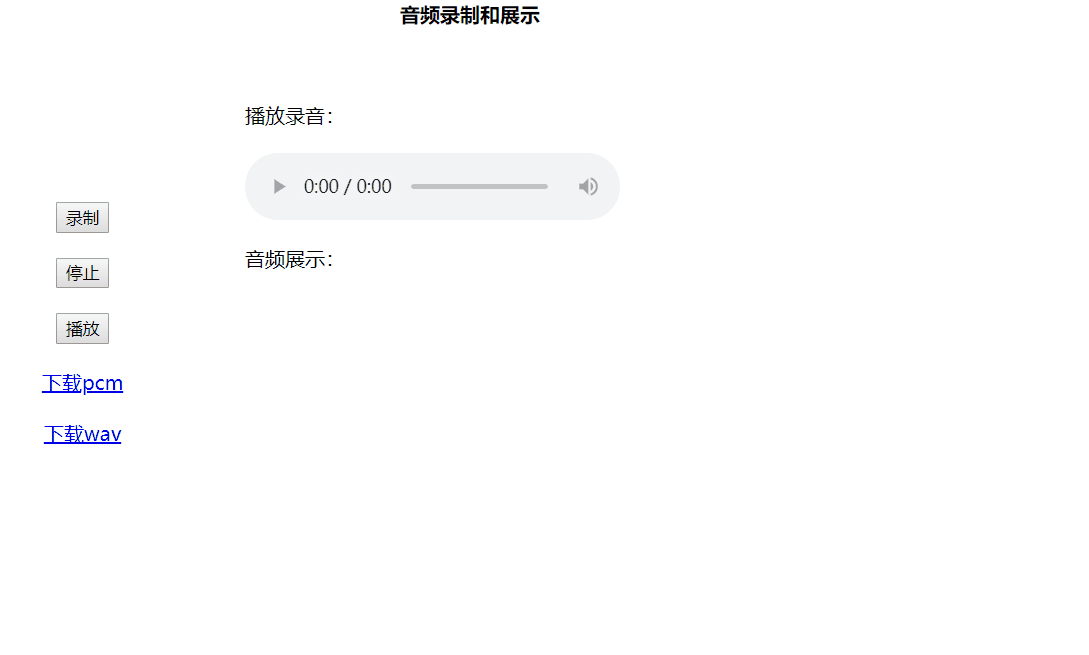
所以在录音的过程中,通过点击gif图中的录制按钮,通过点击事件(onclick)触发下面的两行代码,如果不是点击的时候(也可以是其他事件)触发该代码,onaudioprocess方法将接收不到你在打开麦克风权限后所录得音源信息
audioInput.connect(recorder) //声音源链接过滤处理器
recorder.connect(context.destination) //过滤处理器链接扬声器
链接完成后,createScriptProcessor的onaudioprocess方法可以持续不断的返回采样数据,这些数据范围在[-1,1]之间,类型是Float32。现在要做的就是将它们收集起来,将它转成pcm文件数据。
3、audioData定义
首先定义个 audioData 对象,用来处理数据,整体结构如下,具体见下面源码:
let audioData = {
size: 0, //录音文件长度
buffer: [], //录音缓存
inputSampleRate: context.sampleRate, //输入采样率
inputSampleBits: 16, //输入采样数位 8, 16
outputSampleRate: config.sampleRate, //输出采样率
oututSampleBits: config.sampleBits, //输出采样数位 8, 16
input: function(data) { // 实时存储录音的数据
},
getRawData: function() { //合并压缩
},
covertWav: function() { // 转换成wav文件数据
},
getFullWavData: function() { // 用blob生成文件
},
closeContext: function(){ //关闭AudioContext否则录音多次会报错
},
reshapeWavData: function(sampleBits, offset, iBytes, oData) { // 8位采样数位
},
getWavBuffer: function() { // 用于绘图wav格式的buffer数据
},
getPcmBuffer: function() { // pcm buffer 数据
}
}
根据上面的gif图:
a、第一步点击录制会执行章节 1、获取麦克风权限 和 2、pcm数据获取 对应流程, 然后onaudioprocess方法中调用audioData对象input方法,用来存储buffer数据;
b、点击“下载pcm”标签,会依次执行audioData对象getRawData、getPcmBuffer方法,但是下载的是txt文件,并非是pcm文件,由于不知道如何在js环境将txt文件转成pcm文件,所以本人在将txt文件下载下来后直接手动修改了拓展名,当然此修改后的文件是可以播放的,操作流程如下
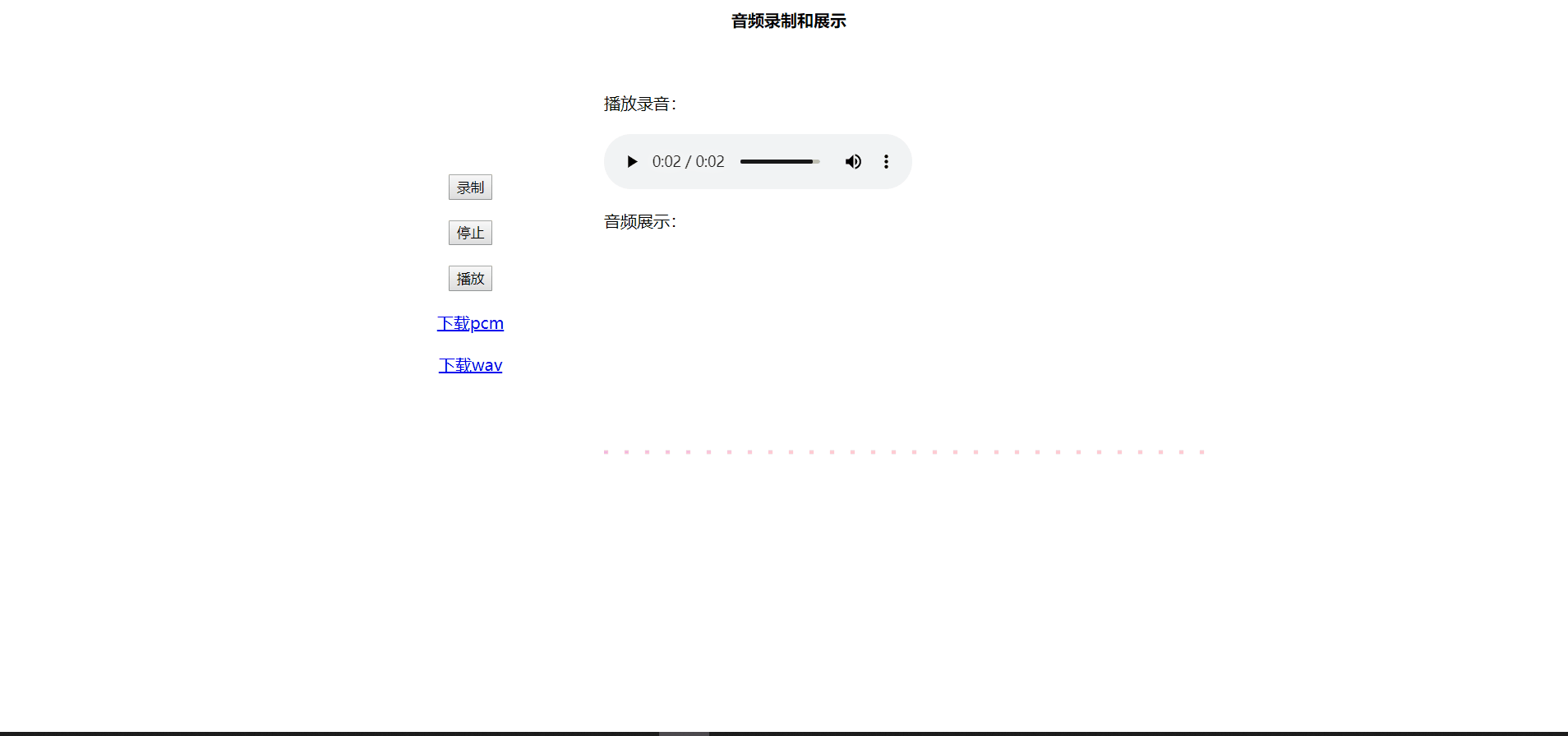
4、pcm转wav
pcm是没有头信息的,只要增加44个字节的头信息即可转换成wav,头信息都是固定的,直接用即可,借用网上千篇一律的代码片段
let writeString = function (str) {
for (var i = 0; i < str.length; i++) {
data.setUint8(offset + i, str.charCodeAt(i))
}
}
// 资源交换文件标识符
writeString('RIFF'); offset += 4
// 下个地址开始到文件尾总字节数,即文件大小-8
data.setUint32(offset, 36 + dataLength, true); offset += 4
// WAV文件标志
writeString('WAVE'); offset += 4
// 波形格式标志
writeString('fmt '); offset += 4
// 过滤字节,一般为 0x10 = 16
data.setUint32(offset, 16, true); offset += 4
// 格式类别 (PCM形式采样数据)
data.setUint16(offset, 1, true); offset += 2
// 通道数
data.setUint16(offset, config.channelCount, true); offset += 2
// 采样率,每秒样本数,表示每个通道的播放速度
data.setUint32(offset, sampleRate, true); offset += 4
// 波形数据传输率 (每秒平均字节数) 单声道×每秒数据位数×每样本数据位/8
data.setUint32(offset, config.channelCount * sampleRate * (sampleBits / 8), true); offset += 4
// 快数据调整数 采样一次占用字节数 单声道×每样本的数据位数/8
data.setUint16(offset, config.channelCount * (sampleBits / 8), true); offset += 2
// 每样本数据位数
data.setUint16(offset, sampleBits, true); offset += 2
// 数据标识符
writeString('data'); offset += 4
// 采样数据总数,即数据总大小-44
data.setUint32(offset, dataLength, true); offset += 4
// 写入采样数据
data = this.reshapeWavData(sampleBits, offset, bytes, data)
5、数据转音域图
转成音域图重点用到AudioContext中的createAnalyser方法,它可以将音波分解,具体步骤如下:
window.audioBufferSouceNode = context.createBufferSource() //创建声源对象
audioBufferSouceNode.buffer = buffer /声源buffer文件流
gainNode = context.createGain() //创建音量控制器
gainNode.gain.value = 2
audioBufferSouceNode.connect(gainNode) //声源链接音量控制器
let analyser = context.createAnalyser() //创建分析器
analyser.fftSize = 256
gainNode.connect(analyser) //音量控制器链接分析器
analyser.connect(context.destination) //分析器链接扬声器
然后拿 analyser.frequencyBinCount 数据用canvas进行绘制,主要代码如下:
let drawing = function() {
let array = new Uint8Array(analyser.frequencyBinCount)
analyser.getByteFrequencyData(array)
ctx.clearRect(0, 0, 600, 200)
for(let i = 0; i < array.length; i++) {
let _height = array[i]
if(!top[i] || (_height > top[i])) {//帽头落下
top[i] = _height
} else {
top[i] -= 1
}
ctx.fillRect(i * 20, 200 - _height, 4, _height)
ctx.fillRect(i * 20, 200 - top[i] -6.6, 4, 3.3)//绘制帽头
ctx.fillStyle = gradient
}
requestAnimationFrame(drawing)
}
四、源码地址
源码github地址:audio
