

Elasticsearch系列开坑啦,入门总是愉快的,学一学再放弃啊。
Apache Lucene简介
Lucene基本概念
Apache Lucene是ElasticSearch使用的全文检索库。了解Lucene之前,需要先了解一些概念:
- 文档:索引和搜索到主要数据载体,它包含一个或多个字段,存放将要写入索引或从索引搜索出来的数据
- 字段:文档的一个片段,是一个K-V结构
- 词项:搜索时的一个单位,代表文本中的某个词
- 词条:词项在字段中的一次出现,包括词项的文本、开始和结束的位移以及类型
- 倒排索引:倒排索引可以快速获取包含某个单词的文档。倒排索引由两部分组成:单词词典和倒排文件
- 单词词典:单词词典是由文档集合中出现过的所有单词构成的字符串集合,单词词典内每条索引项记载单词本身的一些信息以及指向「倒排列表」的指针
- 倒排列表:倒排列表记载了出现过某个单词的所有文档的列表以及该单词在文档中的位置,每条记录称为一个倒排项(Posting)
- 倒排文件:所有单词的倒排列表往往顺序存在磁盘的某个文件,这个文件称为倒排文件
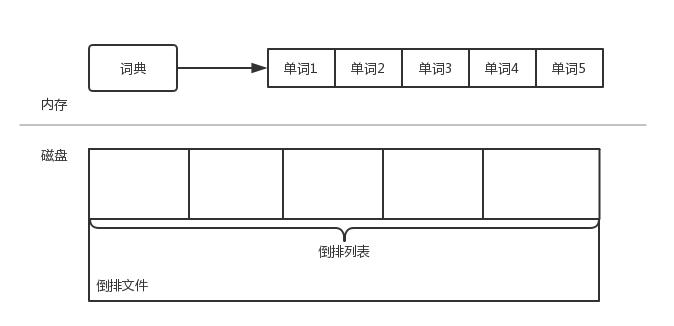
其中最重要的是倒排索引,为了方便理解,我们看一个简单的例子。
假设这里有三句话:
T[0] = "it is what it is"
T[1] = "what is it"
T[2] = "it is a banana"
倒排索引通常有两种表现形式:
- inverted file index{词项,词项所在文档ID}
"a" : {2}
"banana" : {2}
"is" : {0, 1, 2}
"it" : {0, 1, 2}
"what" : {0,1}
- full inverted index{词项,(词项所在文档ID,在具体文档中的位置)}
"a" : {(2, 2)}
"banana" : {(2, 3)}
"is" : {(0, 1), (0, 4), (1, 1), (2, 1)}
"it" : {(0, 0), (0, 3), (1, 2), (2, 0)}
"what" : {(0, 2), (1, 0)}
Lucene查询语言
在了解了Lucene的一些基本概念之后,还需要了解Lucene的查询语言。一个查询通常被分割为词项和操作符,词项可以是单个词或短语。操作符包括:
- AND:文档同时包含AND两边的词项时才返回
- OR:文档包含OR两边的词项中任意一个时就返回
- NOT:不包含NOT操作符后面的词项
- +:只有包含+操作符后面词项的文档才会返回。例如,查询+lucene apache表示必须包含lucene,apache可包含可不包含
- -:匹配的文档不能出现-操作符后的词项
- 冒号:查询title:elasticsearch表示要查询所有在title字段中包含词项elastisearch的文档
- 通配符(?/*):?匹配任意一个字符,*匹配任意多个字符(出于性能考虑,通配符不能作为词项的第一个字符)
- ~:用于Lucene中的模糊查询,~后面跟的整数值确定了近似词项与原始词项的最大编辑距离。例如查询boy~2,那么boy和boys这两个词项都能匹配,用于短语时,则表示词项之间可以接受的最大距离
- ^:用于对词项进行加权
- 花括号:表示范围查询
对于一些特殊字符的查询,我们通常使用反斜杠进行转义。
Elasticsearch基本概念
了解了Lucene的基本概念以后,我们回到正题,再来看一下Elasticsearch的一些基本概念,可能和Lucene有一些重复,不过还是有一些Elasticsearch特有的属性。
- **索引(index):**数据存储在索引中,可以向索引写入文档或者从索引读取文档,Elasticsearch的索引可能由一个或多个Lucene索引构成。
- **文档(document):**文档由字段构成,每个字段有它的字段名以及一个或多个字段值
- **映射(mapping):**用于存储元信息,这些元信息决定了如何将输入文本分割为词条,哪些词条应该被过滤掉等
- **类型(type):**每个文档都有与之对应的类型,同一类型下的文档数据结构通常保持一致,不同文档可以有不同的映射。但是在Elasticsearch7以后已经删除了这个概念
- **节点(node):**集群中每个ES实例都称作一个节点
- **集群(cluster):**在生产环境中,我们的数据量和查询压力可能超过了单机负载,因此需要多个节点协同处理
- **分片(shard):**ES会将数据散落到多个Lucene索引上。这些Lucene索引称为分片。ES会自动进行分片处理
- **副本(replica):**ES会为每个分片创建冗余的副本,一方面分摊请求压力,另一方面是为了保证数据不会丢失。ES支持在任意时间点添加或移除副本
Elasticsearch的启动过程
当Elasticsearch启动时,它使用广播技术来发现同一集群内的其他节点,集群中会有一个节点被选为master节点。master节点负责管理集群状态,并在集群中节点数量变化时做出反应。但从用户角度来看,master节点与其他节点没有什么区别,命令可以发送的任意节点执行。
master节点会检查所有分片,决定哪些分片为主分片。主分片确定以后,集群状态为黄色,此时可以接收查询。然后master节点会决定是否要对各个分片创建副本,副本也没有问题以后,集群状态变为绿色。
Elasticsearch的集群状态分为3种:
- 绿色:一切完好
- 黄色:所有数据都可用,但有些分片没有分配副本
- 红色:有些数据不可用
关于Elasticsearch的启动过程,后面还会有更加深入的讨论。
敬请期待。
