

谢安生(化名),末流985本科,非科班。18年10月零基础学的大数据,错过了秋招,但在春招拿了招商银行,光大银行,浪潮等国企大数据开发offer。
他是我学习群里的一个小伙伴,也是一个曾经在面试前一晚半夜3点打我电话问我问题的男人。。(后台回复"加群**",加入学习群)
部分offer
以下为正文,答案由我重新整理:
目录:
北京柠檬微趣
途牛
光大银行·光大科技
悠易互通
乐言科技
多益网络
招商银行·招银网络科技
浪潮集团
①北京柠檬微趣
**
以下为两道方案题,觉得很有意思,记录一下。
一次计算各时区的DAU
假设有最近48小时的数据,如何一次性计算24个时区各自的DAU,而不是计算24次。
分析:
考虑用pipeline,在进入管道前对数据按时区进行“分类”,然后将数据放入管道,在管道内一次计算,求聚合值。
**
一些整数数据分布的存储在多台机器上,每台20TB,需要求这些数的平均数。请简述计算方法和数据流。
分析:
20TB,数据量过于庞大,则需要考虑使用中间件。类比mysql的mycat,利用中间件对过于庞大的数据进行维护等操作。
微信视频面试,感觉有一点点随意。两个面试官,特别和蔼,全程主动权在我手上(就算是我不会的问题,也被我带着转移到我会的问题上,基本没有打断过。)总共面了40分钟,其中MR流程我就跟他们讲了近20分钟(结合项目、举例、又从快排/归并排序扯到各种排序算法的比较,分区分组又拓展到数据倾斜问题……总之全程被我带着跑,一直说我会的。)
二次总结:面试官不打断不一定代表认为你答得好,可能他性格就是那样。答得不好以及不会的回答面试官还是看在眼里的,所以硬实力还是最关键的。
记录几个我答的不是很好的问题:
这个问题是最常被问到的问题之一,因为一个问题可以牵扯出很多数据结构的知识,很考验功底,建议有时间自己琢磨总结一下。画一画、理一理自己的回答思路线。
参考答案:
http://www.cnblogs.com/chenssy/p/3521565.html
https://www.cnblogs.com/holyshengjie/p/6500463.html
**
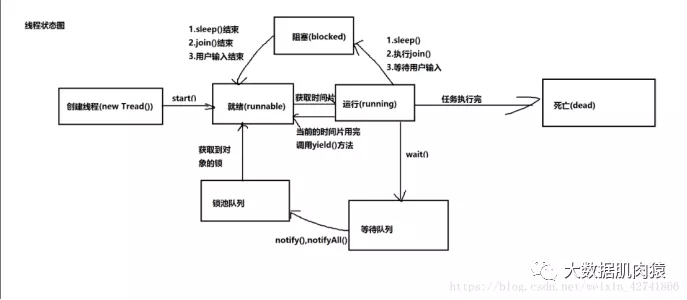
创建线程(new Thread)、就绪(runnable)、运行(running)、阻塞(blocked)、等待队列、锁池队列、死亡(dead)
事务的特性、事务的隔离级别
事务的特性
原子性:
指事务是一个不可分割的工作单位,事务中的操作要么都发生,要么都不发生。
一致性:
事务必须使数据库从一个一致性状态变换到另外一个一致性状态。转账前和转账后的总金额不变。
隔离性:
事务的隔离性是多个用户并发访问数据库时,数据库为每一个用户开启的事务,不能被其他事务的操作数据所干扰,多个并发事务之间要相互隔离。
持久性:
指一个事务一旦被提交,它对数据库中数据的改变就是永久性的,接下来即使数据库发生故障也不应该对其有任何影响。
脏读:
脏读是指在一个事务处理过程里读取了另一个未提交的事务中的数据。
不可重复读:
不可重复读是指在对于数据库中的某个数据,一个事务范围内多次查询却返回了不同的数据值,这是由于在查询间隔,被另一个事务修改并提交了。
虚读(幻读):
幻读是事务非独立执行时发生的一种现象。例如事务T1对一个表中所有的行的某个数据项做了从“1”修改为“2”的操作,这时事务T2又对这个表中插入了一行数据项,而这个数据项的数值还是为“1”并且提交给数据库。而操作事务T1的用户如果再查看刚刚修改的数据,会发现还有一行没有修改,其实这行是从事务T2中添加的,就好像产生幻觉一样,这就是发生了幻读。
幻读和不可重复读都是读取了另一条已经提交的事务(这点就脏读不同),所不同的是不可重复读查询的都是同一个数据项,而幻读针对的是一批数据整体(比如数据的个数)。
现在来看看MySQL数据库为我们提供的四种隔离级别:
①Serializable (串行化):可避免脏读、不可重复读、幻读的发生。
②Repeatable read (可重复读):可避免脏读、不可重复读的发生。
③Read committed (读已提交):可避免脏读的发生。
④Read uncommitted (读未提交):最低级别,任何情况都无法保证。
以上四种隔离级别最高的是Serializable级别,最低的是Read uncommitted级别,当然级别越高,执行效率就越低。像Serializable这样的级别,就是以锁表的方式(类似于Java多线程中的锁)使得其他的线程只能在锁外等待,所以平时选用何种隔离级别应该根据实际情况。在MySQL数据库中默认的隔离级别为Repeatable read (可重复读)。
在MySQL数据库中,支持上面四种隔离级别,默认的为Repeatable read (可重复读);而在Oracle数据库中,只支持Serializable (串行化)级别和Read committed (读已提交)这两种级别,其中默认的为Read committed级别。
我说公众号、csdn(且自己也有专栏)、极客时间、知识星球、github……
面试采取的是多对多形式(国企常见形式,我个人表现时间应该8分钟都不到),我们那一组6个人(还是想吐槽一下,6个人,其中3个名校研究生,除了我,清一色北科、北邮、北理名校的,我emmm,国企真抢手)。
先是轮流自我介绍(指定1分钟,说主讲项目和实习经历),我开始时被“一分钟”吓到了(我自我介绍准备的是3分钟!),最终,我“文理兼修”的特性都忘记讲了。(血的教训!!!赶紧准备下1分钟版本自我介绍!)
然后是挨个问问题(部分问题有问其它人的看法)。
面试官比较犀利,问问题的时候,说偏了或者啰嗦了会直接打断你。
表中有很多重复的数据,怎么去重?
我答的distinct、group by(我还巴拉巴拉说这两者的区别,一个跑内存一个是快排思想……被打断)、然后还说到MR项目中求uuid的去重个数,有在reduce端用set集合进行去重,count值即为set.size()……面试官接着问,还有吗?没人答了。
事后百度补充答案:
**
返回结果集分区内行的序列号,每个分区的第一行从1开始。
而且推荐使用row_number(),对某一字段(tel)排序后分区去重,这样避免了其对不相干字段的数据干扰,影响数据处理的效率。
举例:
| SELECT tel, linkname, certificateno, certificatetype, modifytime FROM orderinfo WHERE deleted = 'F' AND paystatus = 'payed' AND createtime >= todate('2017-04-23', 'yyyy-MM-dd') AND createtime < todate('2017-04-24', 'yyyy-MM-dd') AND row_number() over(PARTITION BY tel ORDER BY tel DESC) = 1 |
|---|
建立临时表,利用hive的collect_set进行去重。
| create table if not exists tubutest ( name1 string, name2 string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE; select from ods.wdtest; 1 1 1 1 1 2 1 2 1 3 2 3 2 3 2 4 select name1,collectset(name2) from tubutest group by name1; name1 c1 1 ["2","3"] 2 ["2","4"] create view ods.wdtestView as select name1,collect_set(name2) as name2 from ods.wdtest group by name1; select from ods.wdtestview; name1 name2 1 ["2","3"] 2 ["2","4"] select name1, name2 from tubuview LATERAL VIEW explode(name2) tubuview as name2; A,collect_set完成把多行转化成一行的功能。 B,explode完成把一行转化成多列的功能。 而lateral view主要是辅助explode进行使用,来完成类似去重的功能。 |
|---|
没有复习到这个问题(悔!!!),只是简单答了几句话,比如一个是处理离线的一个处理实时,spark跑内存……
答案整理:
https://blog.csdn.net/zx8167107/article/details/79086864
1. Spark把运算的中间数据存在内存中,迭代计算效率更高;MR的中间结果需要落地,需要保存到磁盘。
2. Spark有更高的容错性,它通过弹性分布式数据集RDD来实现高效容错,shuffle之前的计算错误可以找到父RDD重新计算即可;而MR如果出错只能从头重新计算。
3. Spark更加通用,提供了transformation和action两类算子,另外还有流式处理streaming、图计算GraphX等;而MR只提供map和reduce两种操作。
4. Spark对性能要求较高,通常需要根据不同的业务场景进行调优;而MR对性能的要求相对较低,运行更稳定,适合长期后台运行。
二次总结:快速记忆,物数网传会表应(“武术网传会表演”)。最重要的是第四层和第七层,TCP/UDP,HTTP要有大概概念。
https://www.cnblogs.com/wxgblogs/p/5641643.html
1.物理层:
原始比特流传输,一些物理接口,比如网卡、网线、集线器、中继器、调制解调器。
2.数据链路层:
将原始比特流转换成逻辑传输线路,比如网桥、交换机。
3.网络层:
控制子网的运行,如逻辑编址、分组传输、路由选择。具体表现,路由器。
4.传输层:
接受上一层的数据,在必要时将数据进行分割,并将这些数据交给网络层,且保证这些 数据段有效到达对端。TCP传输控制协议,UDP用户数据报协议。
5.会话层:
不同机器上的用户之间建立及管理会话。
6.表示层:
信息的语法语义以及它们的关联,如加密解密、转换翻译、压缩解压缩。
7.应用层:
各种应用程序协议。如HTTP超文本传输协议、FTP文本传输协议、SMTP简单邮件传输 协议、POP3邮局协议第三版。
进程和线程通信方式?实际开发中,在哪些地方用上了,请说出具体场景?
每个进程有自己的地址空间,进程间的通信一般通过操作系统的公共区进行。
线程可以看作是轻量级的进程,同一进程中的线程属于同一地址空间,所以可以直接通信,而且可以共享全局变量和内存。总之,线程之间共享数据特别容易,这是它的优点,也由此带来了同步、异步、互斥的问题。
总结:**
线程通信,共享地址空间和数据空间,不必通过操作系统。
进程通信,需要通过操作系统,分为单机版和网络通信(通过socket)。
进程通信方式:
管道(pipe):
管道是一种半双工的通信方式,数据只能单向流动,而且只能在具有亲缘关系的进程间 使用。亲缘关系一般指父子进程关系。
有名管道(namedpipe):
允许无亲缘关系的进程的通信。
信号量(semophore):
信号量是一个计数器,用来控制多个进程对共享资源的访问。类比锁机制。
消息队列(messagequeue):
消息队列是有消息的链表,存放在内核中并由消息队列标识符标识。消息队列克服了信 号传递信息少、管道只能承载无格式字节流以及缓冲区大小受限等缺点。
信号(sinal):
用于通知接收进程某个事件已经发生。
共享内存(shared memory):
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但 多个进程都可以访问。共享内存是最快的IPC方式,它是针对其他进程间通信方式运 行效率低而专门设计的。它往往与其他通信机制,如信号量配合使用,来实现进程间 的同步和通信。
套接字(socket):
用于不同机器间的进程通信。
线程通信方式:
锁机制:包括互斥锁、条件变量、读写锁。
互斥锁提供了以排他方式防止数据结构被并发修改的方法。
读写锁允许多个线程同时读共享数据,而对写操作是互斥的。
条件变量可以以原子的方式阻塞进程,直到某个特定条件为真为止。对条件的测试是 在互斥锁的保护下进行的。条件变量始终与互斥锁一起使用。
信号量机制(Semaphore):
包括无名线程信号量和命名线程信号量
信号机制(Signal):
类似进程间的信号处理。
线程间的通信目的主要是用于线程同步,所以线程没有像进程通信中的用于数据交换的 通信机制。
**
以下为个人整理的回答思路。(不一定正确,有时间可以自行阅读源码总结)
Spark分区主要分为三部分,1.读取文件(textFile);2.shuffle过程;3.输出文件。
1. 读取文件
会根据你设置的分区数量a进行计算。
计算逻辑为:文件总的大小除以设置的分区a,
若得到的值大于128MB,则按128MB一个分区(有冗余),依次填满128MB的分区,直至所有文件读取完。
若得到的值小于128MB,则按设置的分区a。
2. shuffle过程
根据Partitioner,即RDD的分片函数。当前Spark中实现了两种类型的分片函数,一个是基于哈希的HashPartitioner,另外一个是基于范围的RangePartitioner。只有对于key-value的RDD,才会有Partitioner,非key-value的RDD的Parititioner的值是None。Partitioner函数不但决定了RDD本身的分片数量,也决定了parent RDD Shuffle输出时的分片数量。
3. 输出文件
默认按照Partitioner分区,也可以自定义分区个数,coalesce(1)。
面试官是个超级“直接”的人,
不让自我介绍,上来就问,然后各种问题都一针见血,我们互相get不到对方的点,他想要的是直接说方案,而我总是先说思路/分析。总之,就是完全不在一个频道上。后来他也直接说了,他们小公司要的就是直接能干活的人,哪怕是应届生也要求很高,不像大公司一样愿意花三年五年去培养你(只要你基础好),毕竟小公司的生存环境摆在那。
所以最终GG,总之就是他们公司在以社招的要求招应届生,所以完全不匹配。
ps:虽然和面试官不在一个频道上,但是他的一些话还是想记录一下。
“面试时你总是拐弯抹角,不会的问题也往自己会的问题上去转移问题,会被你带着跑的面试官说明水平也不怎么样,其实你们就是在互相忽悠,最终入职,那糊弄的只是客户。”(因为他是一个超直接的人,所以对“不会的问题往会的问题上引”这种面试技巧特别反感。总结:遇到“直接”的面试官,该说不会就说不会,毕竟有些人就是喜欢高效沟通)
“如果你想去大公司,就多复习基础;如果去小公司,就多了解一些问题的解决方案,让人家相信你来就能直接干活。”
问题:
1.数据量特别大的情况下(例如10g、100g、1t)如何用mr实现全局排序?
2.flatmap算子的理解,flat原理,返回类型?(iterator)
https://www.cnblogs.com/airnew/p/9595385.html
方式一:
reduce数量只设置为1个。缺点:没有用到集群的优势,速度慢。
方式二:
自定义分区类partition,按照key值进行分区。
例如:将排序key值为1-1000的数据,使用两个分区,将1-500的key发送到partition1,将501-1000的key发送到partition2。
缺点:1、当数据量大时会出现OOM。2、会出现数据倾斜。
方式三(推荐):
利用TotalOrderPartitioner类。(hive的order by底层也是该方法)
补充:该方法基本原理和方法二类似,只是不再是手动粗糙的进行分区,而是先通过采样,分析数据的分布特征,根据数据的具体特征进行合理的分区(片)。
flatmap算子的理解,flat原理,返回类型?(iterator?)
https://blog.csdn.net/DPnice/article/details/80093370
flatMap其实就是将RDD里的每一个元素执行自定义函数f,这时这个元素的结果转换成iterator**,最后将这些再拼接成一个新的RDD,也可以理解成原本的每个元素由横向执行函数f后再变为纵向。画红部分一直在回调,当RDD内没有元素为止。
⑤乐言科技
hive的metastore的三种模式
https://www.cnblogs.com/snowbook/p/5886438.html
Hive中metastore(元数据存储)的三种方式:
1. 内嵌Derby方式:
这个是Hive默认的启动模式,一般用于单元测试,这种存储方式有一个缺点:在同一 时间只能有一个进程连接使用数据库。
2. Local方式
例如本地mysql:创建好用户:hive;database:hive。
ps:需要把mysql的驱动包copy到目录HOME>/lib中
如果是第一次需要执行初始化命令:schematool -dbType mysql -initSchema
配置完成后就可在shell中以CLI的方式访问hive进行操作验证。
3.Remote方式
以Mysql数据库(192.168.6.77)为例:创建好用户:hive;database:hivemeta。Remote方式需要分别配置服务端和客户端的配置文件。
hive metastore服务端启动命令:
hive --service metastore -p
如果不加端口默认启动:hive --service metastore,则默认监听端口是:9083
介绍一下flume及Kafka
flume和Kafka也超级重要,多次被问到。毕竟大数据,对数据的“流转”还是很看重的。
flume各组件的作用必须了解,
参见https://www.cnblogs.com/zhangyinhua/p/7803486.html
Flume的一些核心概念
Client:Client生产数据,运行在一个独立的线程。
Event:一个数据单元,消息头和消息体组成。(Events可以是日志记录、avro对象等。)
Flow:Event从源点到达目的点的迁移的抽象。
Agent:一个独立的Flume进程,包含组件Source、Channel、Sink。(Agent使用JVM运行Flume。每台机器运行一个agent,但是可以在一个agent中包含
多个sources和sinks。)
Source:数据收集组件。(source从Client收集数据,传递给Channel)
Channel:中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接sources和sinks,这个有点像一个队列。)
Sink:从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
Agent结构
Flume运行的核心是Agent。Flume以agent为最小的独立运行单位。一个agent就是一个JVM。它是一个完整的数据收集工具,含有三个核心组件,分别是
source、channel、sink。通过这些组件,Event可以从一个地方流向另一个地方,如下图所示。
Kafka内容较多,建议自行复习总结。
kafka的重要组件(重要)
Producer:
生产者负责将数据传入Kafka,比如flume、java后台服务、logstash
生产者可以有多个,并且可以同时往一个topic中写数据,也可以同时往一个partition中传入数据。
每个生产者都是一个独立的进程,而且单个生产者就具有分发数据的能力。
一个生产者可以同时往多个topic中分发数据。(一般不会这么操作)
Kafka cluster:
Kafka由多个broker组成,一个broker作为一个实例(节点)
Kafka集群可以保存多种类型的数据,是由多个topic进行分类的
一个topic其实就是一个队列
每个topic可以创建一个或多个partition,partition的数量是可以更改的
每个partition是由多个segment组成的,segment的大小是相同的,默认的是1G
topic中的数据是有多副本机制的,原始数据和副本数据不会在同一个节点上(所以若只有一个节点,副本数为3,也并不会在同一个节点上存3份)
Consumer group:
消费者负责拉取数据,比如:streaming、storm、java服务
消费者组中可以存在多个consumer,在stream中,一个consumer作为一个线程
新增或减少consumer数量会触发负载均衡,目的是减少部分broker压力,提高Kafka的吞吐量
一个consumer group可以消费多个分区的数据
一个分区的数据最多在同一个时刻被一个consumer消费
在同一个consumer group中,数据是不可以重复消费(若想要重复消费,可以修改group名,或者设置Kafka集群映射,或者手动调整已经变化了的偏移量)
此外,Kafka的Receiver和Direct方式、如何保证数据不丢失等问题也很重要。
streaming消费kafka的两种方式Receiver/Direct优缺点
https://blog.csdn.net/weixin_42741866/article/details/87893677
Kafka的消息传递语义(重要,若问Kafka基本必问),换种问法,Kafka怎么保持数据的一致性(怎么保证数据0丢失)?
1.幂等写入(idempotent writes)
需要设置好唯一主键等,比如用redis、mysql
再比如每次往一个目录覆盖写数据,这样主键不容易获取。
一次语义:幂等写入
当获取到数据后,先写到mysql,再保存offset,如果在写到mysql数据后,在保存offset之前宕机,重启作业后也不会影响一次语义,因为会在mysql重复更新。
注:在软件开发领域,幂等写入即为同样的请求被执行一次与连续执行多次的效果是一样的,服务器的状态也是一样的,实际上就是接口的可重复调用(包括时间和空间上两个维度)。
2.事务控制
保证数据和offset在同一个事务里面,比如用mysql,这样需要事务存储的支持。
3.自己实现Exactly-once,offset和数据绑定保存等。
**
**
⑥多益网络
**
40分钟左右视频面试。
面试官挺和善的,不过问的问题挺多的。记录几个答的不是很好的问题。
hive join的类别(方式)?
二次总结:第一想法是内连接外连接全连接,但只答这个的话还表现的水平较低,建议了解以下三种join方式。
http://www.cnblogs.com/raymoc/p/5323824.html
参考官网链接https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Joins
Hive的三种join方式:
Common/Shuffle/Reduce Join(正常/一般情况)、
Map Join(大小表join、不等值join、结合union all)、
SMB(Sort-Merge-Buket) Join(大表join大表)。
Common/Shuffle/Reduce Join(正常/一般情况)
Reduce Join在Hive中也叫Common Join或Shuffle Join
如果两边数据量都很大,它会进行把相同key的value合在一起,正好符合我们在sql 中的join,然后再去组合。
Map Join(大小表join、不等值join、结合union all)
1) 大小表连接:
如果一张表的数据很大,另外一张表很少(<1000行),那么我们可以将数据量少的那张表放到内存里面,在map端做join。
Hive支持Map Join,用法如下
2) 需要做不等值join操作(a.x < b.y或者a.x like b.y等)
这种操作如果直接使用join的话语法不支持不等于操作,hive语法解析会直接抛出错误
如果把不等于写到where里会造成笛卡尔积,数据异常增大,速度会很慢。甚至会任务无法跑成功~
根据mapjoin的计算原理,MapJoin会把小表全部读入内存中,在map阶段直接拿另外一个表的数据和内存中表数据做匹配。这种情况下即使笛卡尔积也不会对任务运行速度造成太大的效率影响。
而且hive的where条件本身就是在map阶段进行的操作,所以在where里写入不等值比对的话,也不会造成额外负担。
3)MAPJOIN结合UNIONALL
某些情况下join特别慢,可以观察数据,取出特殊(数据特别多的)字段范围放在一组,并使用mapjoin与维表关联,放入内存中,除此之外的数据存入另一组,使用普通join,最后union all放到一起。
设置:
当然也可以让hive自动识别,把join变成合适的Map Join如下所示
注:当设置为true的时候,hive会自动获取两张表的数据,判定哪个是小表,然后放在内存中
SMB(Sort-Merge-Buket) Join(大表join大表)
大致原理:大表join大表时,SMB join会根据(自动)相同的字段进行类似分区分桶的操作,将大表拆成更小一点的表再进行join。
设置(默认是false):
对一组数据频繁插入删除,选哪种数据结构?
我说的链表,因为链表相对于数组来说,更适合插入删除。然后面试官提示说可以用最小堆。
最小堆。https://blog.csdn.net/qq_37934101/article/details/80955984
给定一个长度为n的数组,求前k大的元素?
若是求第K大的元素,可以考虑用快排的思想,A[0…p-1]、A[p]、A[p+1…n-1]。
取一个中间点A[p],使A[p]前面的数都比A[p]小,A[p]后面的数都比A[p]大,
若p+1=K,则A[p]就是要求解的元素;若K>p+1,则在A[p+1…n-1]中递归查找;若K
但要求是要求前K大的元素,参见博客(暂时未懂):
https://blog.csdn.net/frankingly/article/details/52645179
⑦招商银行·招银网络科技
**
一面:
25分钟左右电话面试,问的问题很常规。只记得一个问题(当时没理解面试官意思):
hive运行的环境?
面试官应该想问的是hive环境的搭建。大体就是1.Hadoop集群环境;2.元数据管理配置。
参见博客https://blog.csdn.net/qq_41851454/article/details/79807733以及此文档上文”乐言科技-hive的meta store的三种模式”。
二面:
问的基本是大数据的知识,基本没有新的问题。比较轻松通过了。
三面:
是个秃头大叔(应该是技术总监级别的人物),各种怼成绩单、怼专业,然后手撕三道算法题。(凉)
1. 有10G的数据,2G内存,取中位数。
2. 给你一个字符串(可能很长),字符串包含数字和字母,要求将字符串里的字母反转,但数字不动。
3. 一个整型数组a,一个数key,求数组a中所有相加等于key的子数组。(注:注意子集概念。可能有负数。)
⑧浪潮集团
多对多,群面,4个面试官,我那组7个应聘者。除了我,其余6个都是研究生,不过没有竞争关系,7个人都是不同的岗位。
1分钟自我介绍,然后面试官针对简历问了几个问题,分配到每个人的时间可能就3分钟左右。
浪潮的面试,感觉就是大概评估一下你的潜力,对技能考量没有太深。
比如,就简单问了下我的项目,问项目还主要问我mysql和redis是怎么用的,都不太算是大数据的问题。(感觉4个面试官好像没有一个懂大数据的)
最后有问我想留在北京的原因,我说1.北京就业机会多;2.还年轻,想在大城市闯闯;3.女朋友希望我去大城市。
记录一个面试官问另一位面试者的问题,感觉很新颖,回去搜索一下:
远程通讯(比如ssh),底层是通过什么包进行的?
SSH认证过程如下:
· Client将自己的公钥存放在Server上,追加在文件authorizedkeys中。
· Server端接收到Client的连接请求后,会在authorizedkeys中匹配到Client的公钥pubKey,并生成随机数R,用Client的公钥对该随机数进行加密得到pubKey(R)
,然后将加密后信息发送给Client。
· Client端通过私钥进行解密得到随机数R,然后对随机数R和本次会话的SessionKey利用MD5生成摘要Digest1,发送给Server端。
· Server端会也会对R和SessionKey利用同样摘要算法生成Digest2。
· Server端会最后比较Digest1和Digest2是否相同,完成认证过程。
然而,面试官要问的应该不是这个(至今没懂面试官意思),个人理解问题思路,面试官应该想问的是远程通讯原理。
比如RPC的IO通讯框架主要有1.Java nio(基本弃用);2.基于mina(曾经火热,现在更新缓慢);3.基于netty,最常用,如阿里的HSF、dubbo等。底层主要以传输socket为主,例如Hadoop中存储client对象时,用socket factory作为hash key,存储结构为hashMap 。
--end--
