

Time: 2019.09.14
本文首发于 www.f1renze.me/ 转载请注明出处!
混淆矩阵(Confusion Matrix)
如无特殊说明,文中提到的分类皆指二分类任务
在了解 ROC 之前,先得了解什么是 Confusion Matrix (It really confused me when I see it first time. XD)。实际上混淆矩阵能够帮助我们了解分类任务模型的偏好性,如正判(True)较多或误判(False)较多,或是更多预测为 Positive / Negative (取决于 threshold 取值)。
更专业地说它被用于机器学习分类任务的性能度量,即衡量模型泛化能力的评价标准。
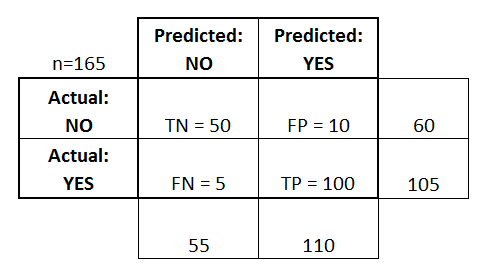
Confusion Matrix 由 4 个术语组成,我们现在把分类问题假设为医生诊断病人是否患流感:
-
True Positive (TP)
若病人实际上患了流感且医生确诊为流感,称为 TP。
-
True Negative (TN)
若病人未患流感且医生诊断该病人未患流感,称为 TN。
-
False Positive (FP)
若病人未患流感但被误诊为已患流感,称为 FP,又称 “Type I error”。
-
False Negative (FN)
若病人患流感但被误诊为未患流感,称为 FN,又称 “Type II error”。
所以实际上 Confusion Matrix 并不难理解,T / F 表示模型预测值与实际值是否符合,P / N 表示模型预测的类别。
由 Confusion Matrix 延伸的几个指标
-
Accuracy ,精度,最常用的指标。
表示分类预测正确的样本数占总体样本的比例。
(TP + TN) / (TP + FP + TN + FN) -
Recall,又称查全率。
表示所有实际为 Positive 类别的样本中被预测准确的概率。
Recall = TP / (TP + FN) -
Precision,又称查准率。
表示所有被预测为 Positive 的样本中预测准确的概率。
Precision = TP / (TP + FP)一般来说 Precision 高时 Recall 会偏低,反之 Recall 高时 Precision 偏低,所以需要引入 F-Score 来比较不同模型的性能。
-
F-Score,又称 F1-score。
为 Precision 和 Recall 的调和平均值,值越接近 1 越好,反之越接近 0 越差。
F-Score = 2*(Recall * Precision) / (Recall + Precision)
回到上文中诊断流感的例子来说明这几个指标。
若 Accuracy 为 90%,表示用此模型预测时,每10个样本里有9个预测正确,1个预测错误。
若 Precision 为 80%,表示用此模型预测时,每10个被判断为患流感的例子中就有2例误诊。
若 Recall 为 70%,表示用此模型预测时,每10个实际患流感的病人中就有3个病人会被告知没有患流感。
所以在这个应用场景中我们更看重的是 Recall,而 F-Score 的一般形式 Fβ 能表示模型对于 Precision / Recall 的不同偏好。
β = 1 时为标准的 F1;β > 1 时 Recall 有更大影响,0 < β < 1 时 Precision 有更大影响。
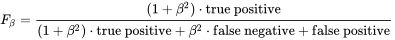
什么是 ROC 曲线?
由于分类器分类过程实际上是为样本计算出预测概率,根据概率与事先定义的 threshold (通常为 0.5)进行比较,若大于 threshold 为正例(Positive),反之为反例(Negative)。若根据预测概率对测试集样本进行排序,预测概率值最大的样本即为最可能为正例的样本,预测概率值最小的样本即为最可能为反例的样本。
在不同的应用场景下采取不同的 threshold 能得到更符合预期的结果,以上文中诊断流感的场景来看,由于我们更重视 Recall,故采取较低的 threshold 会降低患流感病人被认为健康的概率(然后导致更多的误诊,逃);但若在商品推荐系统中,为了尽可能少打扰用户,更希望推荐的商品是用户更感兴趣的,此时我们更看重 Precision,故调高 threshold 更符合期望。
因此排序质量决定了分类器在不同任务下的期望泛化性能的好坏,而 ROC 曲线能够很好地表示总体情况下分类器的泛化性能。典型的 ROC 曲线以 False Positive Rate 为 x 轴,True Positive Rate 为 y 轴,定义如下:
- TPR / Recall
TPR = TP / (TP + FN) - FPR
FPR = FP / (TN + FP)
ROC 曲线绘制原理 根据 n 个测试样本计算出的预测概率排序,轮询将每个预测值设置为 threshold 并计算此时的 TPR & FPR 为 (x, y) 坐标,拟合 n 个坐标点形成的曲线即为 ROC 曲线。
什么是 AUC
AUC 的全称是 Area Under Curve,顾名思义其为 ROC 曲线下的面积,不同的 AUC 值表示模型区分不同样本的能力。
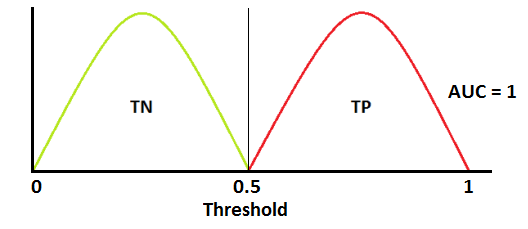
理想情况下,模型将样本完全区分为2类,此时 ROC 曲线如下所示,AUC = 1。
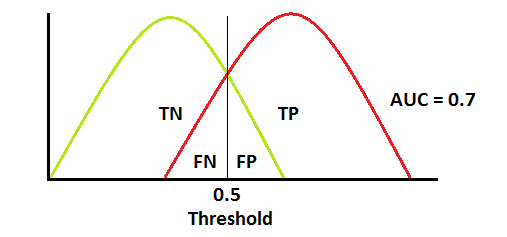
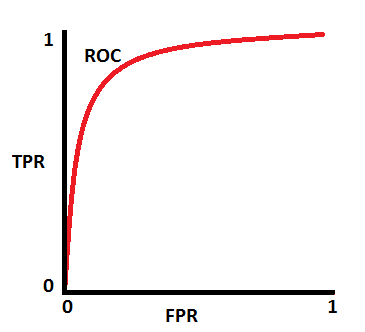
大多数时候 ROC 曲线是下图这样的,曲线整体接近左上方;AUC = 0.7 表示 70% 的样本会被正确分类,于此同时也有 FN 和 FP 的样本。
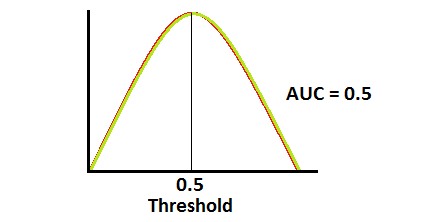
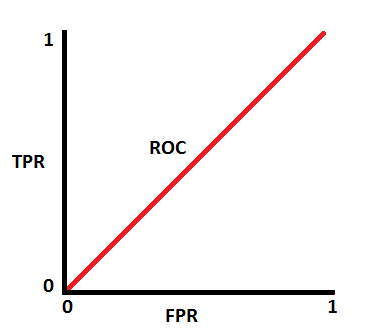
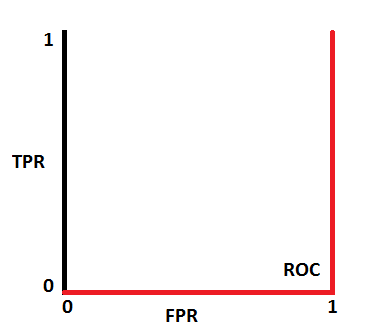
ROC 曲线处于对角线时 AUC = 0.5,表示模型很可能有问题,因为其区分类型的能力与随机无异。
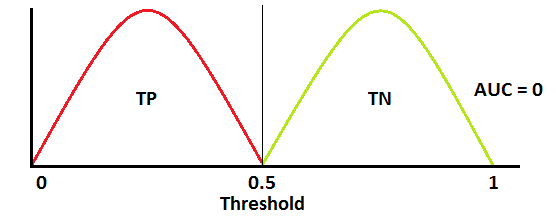
AUC 低于 0.5 甚至接近 0 时,未必是一件坏事,说明模型将样本类型区分反了,若此时将 1 - 概率的值置为新的概率,AUC就接近 1 了!(别问我为啥知道)
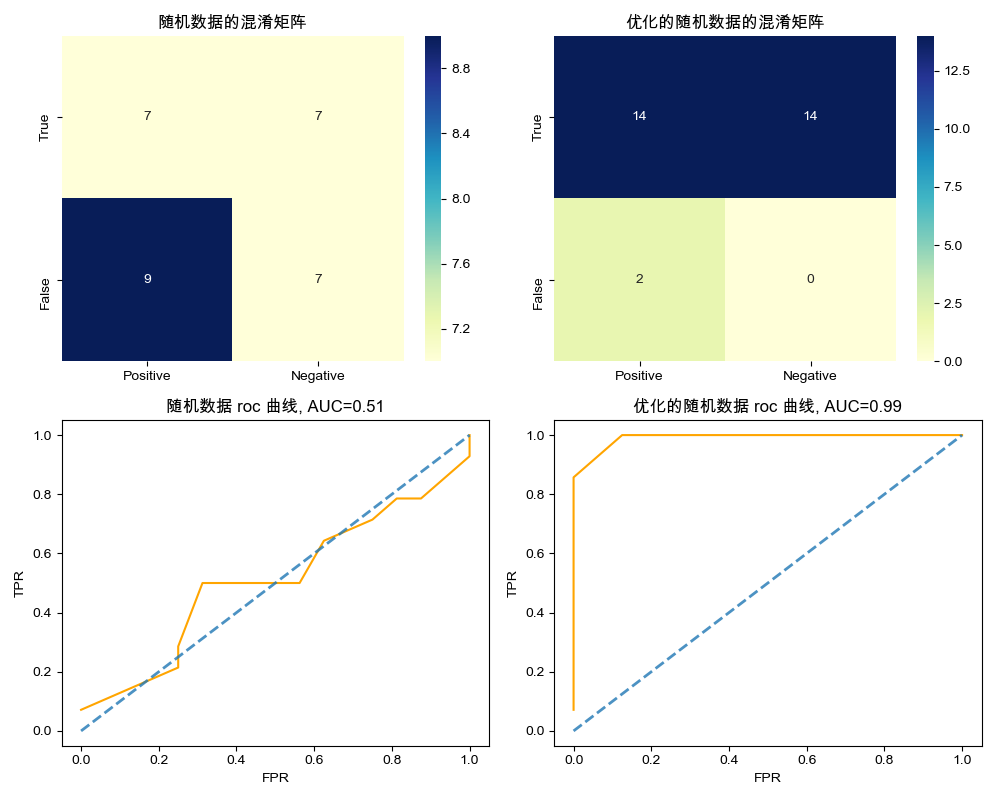
Python 实现
代码地址:gist.github.com/F1renze/6ae…
如下图所示:
延伸阅读
- 西瓜书第二章
- Wikipedia
- AUC 段落图片引用
