介绍
作为Elastic Stack 的核心,Elasticsearch 是一个分布式、RESTful 风格的搜索和数据分析引擎,本次主要用于存储业务数据和基于业务日志进行数据统计分析。
目标
本次目标是搭建个人项目所使用的小型es高可用环境,目前需要使用es的服务有些部署在美国的服务器,有些部署在国内的服务器,带宽延迟各不相同,为了保证应用连接es延迟最小,计划同时在美国和中国都部署节点,不同区域的应用连接不同的节点
基础环境
本次配置全局使用真实服务器,服务器配置如下
| 名称 | CPU | 内存 | 系统 | Docker版本 | 磁盘大小 | 区域 |
|---|---|---|---|---|---|---|
| es01 | 1 | 2G | CentOS 7 | 19.03.1 | 40 G | 亚洲 |
| es02 | 1 | 2G | CentOS 7 | 19.03.1 | 20G | 美洲 |
| es03 | 4 | 4G | CentOS 7 | 19.03.1 | 36G | 美洲 |
| es04 | 1 | 2G | CentOS 7 | 19.03.1 | 50G | 亚洲 |
所有服务器部署的es版本均为:6.6.2
从表中可见内存和磁盘都不大,如果是公司项目配置肯定比这个好很多,但对于个人使用来说足够了,至于为什么是需要4台而不是3台在最后搭建完成后会进行分析
部署前准备
就算使用了Docker容器,elasticsearch仍然不像普通镜像那么简单启动,es对虚拟内存敏感,因此服务器必须是内核虚拟化KVM架构,不支持OpenVZ虚拟,参考官方说明
Production modeedit
The
vm.max_map_countkernel setting needs to be set to at least262144for production use. Depending on your platform:
Linux
The
vm.max_map_countsetting should be set permanently in /etc/sysctl.conf:$ grep vm.max_map_count /etc/sysctl.conf vm.max_map_count=262144To apply the setting on a live system type:
sysctl -w vm.max_map_count=262144macOS with Docker for Mac
The
vm.max_map_countsetting must be set within the xhyve virtual machine:$ screen ~/Library/Containers/com.docker.docker/Data/vms/0/ttyJust press enter and configure the
sysctlsetting as you would for Linux:sysctl -w vm.max_map_count=262144
按照指引设置内存参数
$ sudo sysctl -w vm.max_map_count=262144
前置知识
裂脑事件
Elasticsearch牺牲了一致性,以确保可用性和分区容错。其背后的原因是短期的不良行为比短期的不可用性问题少。换句话说,当群集中的Elasticsearch节点无法复制对数据的更改时,它们将继续为应用程序提供服务。当节点能够复制其数据时,它们将尝试聚合副本并实现最终的一致性。
Elasticsearch通过选举主节点来解决之前的问题,主节点负责数据库操作,例如创建新索引,在群集节点周围移动分片等等。主节点与其他节点主动协调其操作,确保数据可以由非主节点汇聚。
在某些情况下,先前的机制可能会失败,从而导致裂脑事件。当Elasticsearch集群分为两个区块时,若每个区块都有一个节点都认为它们是主节点,因为主节点将在数据上独立工作,数据一致性就会丢失。因此,节点将对相同的查询做出不同的响应。这将会是灾难性的事件,因为来自两个主节点的数据无法自动重新加入,并且需要相当多的手动工作来纠正这种情况。
节点部署
3个主节点节点均使用docker-compose命令部署,需要自行安装好相关环境
version: '2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:6.6.2
container_name: es01
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "discovery.zen.ping.unicast.hosts=es2.xxx.com,es3.xxx.com,es4.xxx.com"
- "discovery.zen.minimum_master_nodes=2"
- "network.publish_host=es1..xxx.com"
- "node.name=es01-XXX"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
ports:
- 9200:9200
- 9300:9300
networks:
- fjyesnet
mem_limit: 1g
networks:
fjyesnet:
其他节点配置均相同,修改服务发现域名配置即可,放行防火墙部分不再赘述,需要可以查看我以前发的文章
非主节点配置只需加入node.master=false配置即可
version: '2'
services:
es01:
image: docker.elastic.co/elasticsearch/elasticsearch:6.6.2
container_name: es04
environment:
- cluster.name=docker-cluster
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- "discovery.zen.ping.unicast.hosts=es2.xxx.com,es3.xxx.com,es1.xxx.com"
- "discovery.zen.minimum_master_nodes=2"
- "network.publish_host=es4..xxx.com"
- "node.name=es04-XXX"
- "node.master=false"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- ./elasticsearch/data:/usr/share/elasticsearch/data
ports:
- 9200:9200
- 9300:9300
networks:
- fjyesnet
mem_limit: 1g
networks:
fjyesnet:
参数解析
-
discovery.zen.ping.unicast.hosts配置广播地址,用于节点发现,此处配置的是指向其他节点IP的域名地址,该域名在任何节点均可以被访问 -
discovery.zen.minimum_master_nodes配置主节点最小数量,该参数十分重要,用于防止脑裂(split-brain)事件的发生。原理:前面提到了脑裂事件发生的原因,而避免的方法就是保证至少3个节点可靠地工作,因为一个或两个节点不能形成多数投票,这也是为什么选择使用4个节点并将该值配置为2,确保分布式环境还可以随机宕机一个节点以保证不会出现脑裂问题,因此第4个节点最好配置为无法成为主节点的slave节点。而若仅配置为3个节点的高可用状态,其实是一种“伪高可用”,此时随机宕机一个节点将可能发生“脑裂”问题,2个节点的es环境无法进行主节点的选举,并且可能出现独立的分块。
-
network.publish_host用于提供其他节点服务发现的主机名,默认为本地主机名映射为IP的地址,但由于使用容器提供服务发现,并且不在同一个网段,故需要手工指定 -
mem_limit容器内存限制为1G
节点数量与配置的主节点数对应关系
Master nodes |
minimum_master_nodes |
备注 |
|---|---|---|
| 1 | 1 | |
| 2 | 1 | 如果另一个节点宕机,集群将停止工作! |
| 3 | 2 | |
| 4 | 3 | |
| 5 | 3 | |
| 6 | 4 |
对可能产生疑问的解释
1.当前docker-compose已经更新到3.7了为什么还使用2这个老版本?
原因:最新文档地址,官方文档指出3.x版本已经不再支持mem_limit参数
Note: This replaces the older resource constraint options for non swarm mode in Compose files prior to version 3 (
cpu_shares,cpu_quota,cpuset,mem_limit,memswap_limit,mem_swappiness), as described in Upgrading version 2.x to 3.x.
但对小内存机器以及数据量不会非常的大的环境,内存限制参数尤为重要,经过实测,空载或者小负载(1000 doc)以下的es节点内存占用大约为1.5G左右,故各环境限制为1G不会影响性能,不仅如此,es官方提供的部署文档使用的也是2.2版本
2.当前Elasticsearch已经更新到7.3了为什么还使用6.6这个老版本?
原因:7.x版本目前尚有许多外部服务不能兼容,例如graylog,并且Spring官方组件暂时也只能兼容到6.x的版本,所以综合考虑使用6.x的最新版6.6.2
graylog官方文档
Caution
Graylog 3.x does not work with Elasticsearch 7.x!
Spring官方文档
Compatibility Matrix
Spring Data Elasticsearch Elasticsearch 3.2.x (not yet released) 6.8.1 3.1.x 6.2.2 3.0.x 5.5.0 2.1.x 2.4.0 2.0.x 2.2.0 1.3.x 1.5.2
3.一般高可用不是部署3个节点就足够了吗,为什么要4个节点?
原因:本次总共部署了3个主节点和一个非主节点,即4个都是数据节点,但只有3个参与选举。如果仅部署3个节点,那么3个都必须为主节点,此时若其中一个主节点宕机,那么不满足选举“至少3个节点可靠地工作”的条件,故新增多一个冗余数据节点,其不能竞选为主节点,但能对节点竞选做出响应,依然满足条件,详细算法可以参考Raft协议的实现原理
节点启动
使用docker-compose命令启动即可
$ docker-compose up -d
这种直接启动的方式会报文件夹无访问权限的错误,需要在命令执行后手动赋予文件夹访问权限
$ chmod 777 -R elasticsearch/
$ chown 1000:1000 -R elasticsearch/
若此时es容器已经停止则再执行一次启动命令即可
部署结果
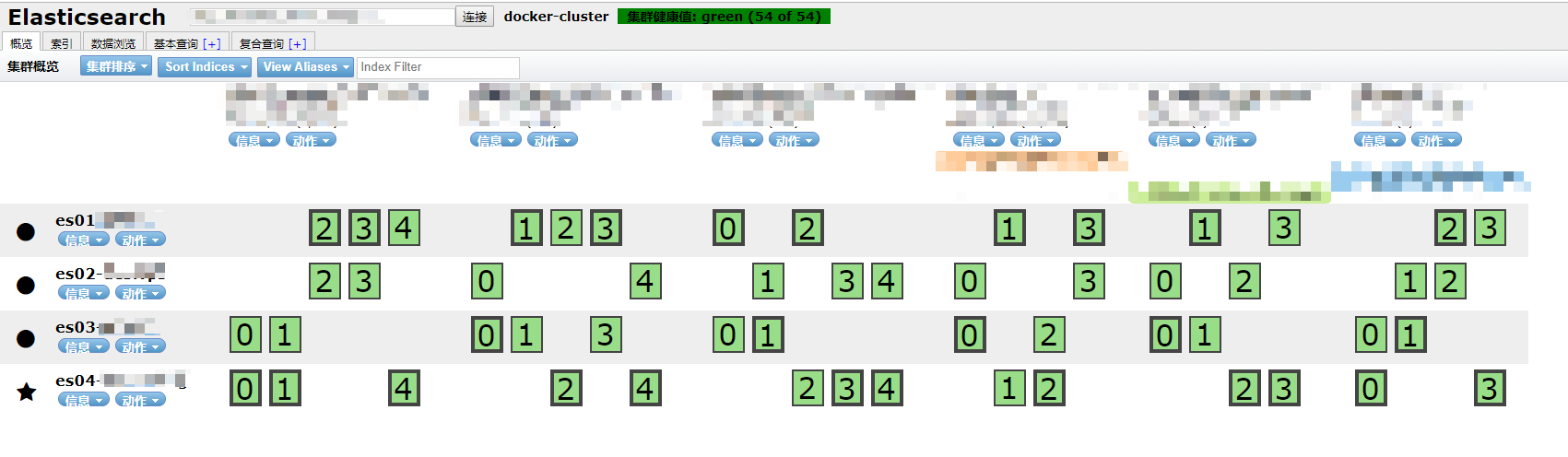
使用chrome插件elasticsearch-head连接任意一个节点查看情况
4节点在线,接入业务系统后各节点情况如下图。
注意所有索引副本数都要是2或者3,否则都无法实现高可用效果
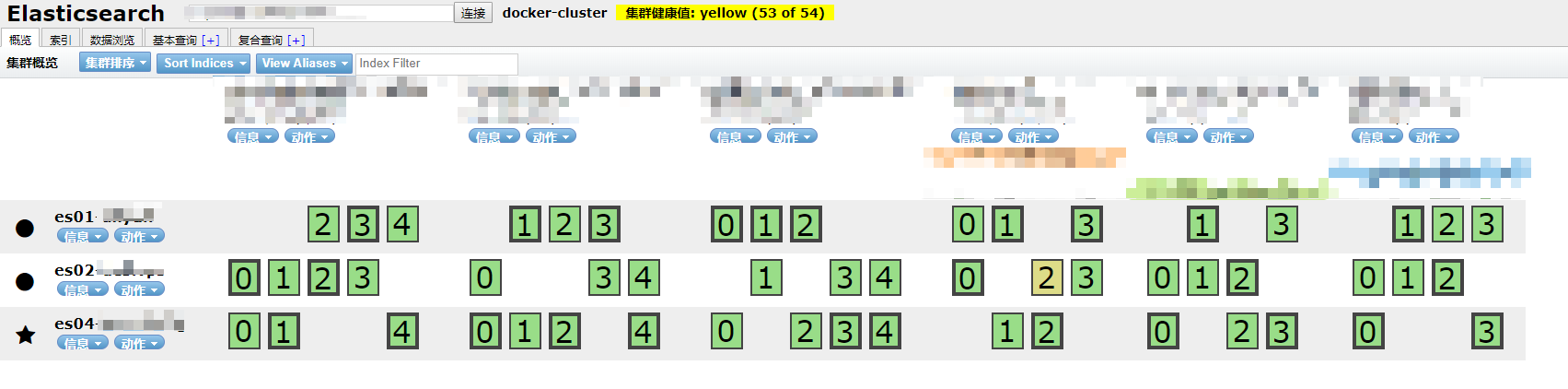
由于网络问题或者服务器问题导致其中一个节点下线,es会自动对各个节点的副本重新路由,此时集群颜色为黄色,仍然可用,稍等片刻会实现最终一致性
若此时主节点下线,整个集群会立刻重新选举出新的主节点并路由各个分片,保证24小时服务都处在可用状态
橙色表示尚未路由完成,但所有索引数据均可用
注意
若某些索引的副本数设置为1,则当某个节点宕机且其刚好存储该索引的副本,则整个集群的状态将立刻变成红色,意思是数据丢失
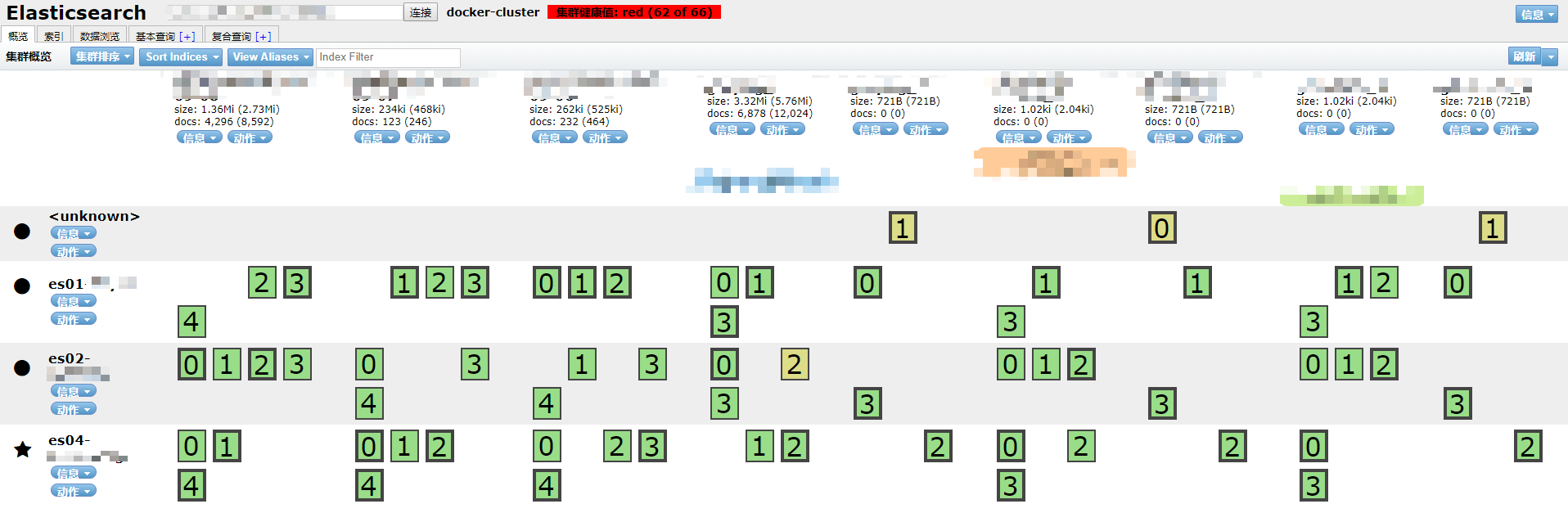
灰色表示已经下线的分片并且无法被重新路由