

符号链接处理
/*
* Do we need to follow links? We _really_ want to be able
* to do this check without having to look at inode->i_op,
* so we keep a cache of "no, this doesn't need follow_link"
* for the common case.
*/
static inline int should_follow_link(struct nameidata * nd, struct path * link,
int follow, struct inode * inode, unsigned seq)
{
// 判断是否是符号链接类型
if (likely(!d_is_symlink(link->dentry)))
return 0;
// follow = flags & WALK_GET 这里为true。
if (!follow)
return 0;
/* make sure that d_is_symlink above matches inode */
if (nd->flags & LOOKUP_RCU) {
// 如果当前为 rcu-walk 模式,期间 dentry 发生了改变,也就是无效了,
// 那么返回 - ECHILD,退出 rcu-walk 模式。
if (read_seqcount_retry(&link->dentry->d_seq, seq))
return - ECHILD;
}
// 把 link 保存到 nd->stack,有可能需要 stack 的扩容处理。
return pick_link(nd, link, inode, seq);
}
static int pick_link(struct nameidata * nd, struct path * link,
struct inode * inode, unsigned seq)
{
int error;
struct saved * last;
// 如果当前路径中已包含的符号链接数量(嵌套层次)超过了 MAXSYMLINKS = 40。
if (unlikely(nd->total_link_count++ >= MAXSYMLINKS)) {
path_to_nameidata(link, nd);
// 返回错误
return - ELOOP;
}
// 当前为 ref-walk 模式
if (! (nd->flags & LOOKUP_RCU)) {
if (link->mnt == nd->path.mnt)
mntget(link->mnt); //增加挂载描述符 mount 的引用
}
// 检查是否需要进行扩容 stack。 初始使用大小为 2。
error = nd_alloc_stack(nd);
if (unlikely(error)) {
// 需要退出 rcu-walk 模式,使用 ref-walk 模式处理符号链接。
if (error == -ECHILD) {
// 使用 ref-walk 模式处理符号链接,如果处理失败,返回 -ECHILD,那么返回给 walk_component
// 函数处理,walk_component 函数再返回给 link_path_walk 函数处理。link_path_walk 再返回给
// path_openat,最后本次 open 操作失败。
if (unlikely(unlazy_link(nd, link, seq)))
return - ECHILD;
// 在 ref-walk 模式下再次进行扩容。
error = nd_alloc_stack(nd);
}
// 如果 ref-walk 模式下扩容再次失败,表示当前内存不够用。这时释放 link,返回错误。
if (error) {
path_put(link);
return error;
}
}
// 保存符号链接信息到 stack 相关信息。先使用 nd->depth 的值(从 0 开始),再进行 ++ 操作。
last = nd->stack + nd->depth++;
last->link = *link;
last->cookie = NULL;
last->inode = inode;
last->seq = seq;
// 返回 1,返回给 link_path_walk 函数处理。if (err) {...},取出符合链接指向的路径,继续 for 循环处理。
return 1;
}
// 增加 mnt 的引用计数,如果是 SMP 模式,那么给对应 CPU 的本地变量加 1,如果是单处理器模式
// 先禁止进程抢占再对变量加 1,然后恢复抢占。
struct vfsmount *mntget(struct vfsmount *mnt)
{
if (mnt)
mnt_add_count(real_mount(mnt), 1);
return mnt;
}
static inline int nd_alloc_stack(struct nameidata * nd)
{
// 如果已记录符号链接的深度(嵌套深度)不为 2。返回 0;
if (likely(nd->depth != EMBEDDED_LEVELS))
return 0;
// 在 set_nameidata 函数中 p->stack = p->internal;也就是初始的 stack 是指向 internal 数组。
if (likely(nd->stack != nd->internal))
return 0;
// 当 nd->depth == 2 && nd->stack == nd->internal,当已保存的符号链接个数超过 2 个时候
// 进行扩容。
return __nd_alloc_stack(nd);
}
static int __nd_alloc_stack(struct nameidata * nd)
{
struct saved * p;
if (nd->flags & LOOKUP_RCU) {
// GFP_ATOMIC 表示调用者不能睡眠并且保证分配会成功。它可以访问系统预留的内存,
// 这个标志通常使用在中断处理程序、下半部、持有自旋锁或者其他不能睡眠的地方,
// 这里为 RCU 模式,所以不能睡眠。 大小为:可以用来保存 40 个符号链接的信息。
p = kmalloc(MAXSYMLINKS * sizeof(struct saved), GFP_ATOMIC);
// 内存分配失败,返回 -ECHILD,以退出 rcu-walk。
if (unlikely(!p))
return - ECHILD;
}
else {
// GFP_KERNEL 内核分配内存最常用的标志之一。它可能会被阻塞,即分配过程可能会睡眠。
p = kmalloc(MAXSYMLINKS * sizeof(struct saved), GFP_KERNEL);
// 内存分配失败,返回 -ENOMEM,表示内存过低。
if (unlikely(!p))
return - ENOMEM;
}
// 把以前 nd->internal 保存的内容保存到新分配的内存中。
memcpy(p, nd->internal, sizeof(nd->internal));
// 指向新分配的 stack。
nd->stack = p;
return 0;
}
从本质上来讲符号链接就是一个路径字符串,这和硬连接有着本质上的区别。而且对于创建目录的链接,硬连接有着严格的限制(比如普通用户就不允许创建目录的硬连接),但是符号链接就没有那么多的限制,用户可以随意创建目录的链接,甚至可以创建一个链接的死循环(比如:a->b;b->c;c->a)。既然不限制创建各式各样的符号链接,那么在读取的时候就需要格外小心了,Kernel 设置了限制:MAXSYMLINKS,它的值是 40 表示当前待处理符号链接的最大数量(嵌套层次不能超过 40)。
接下来看 link_path_walk 函数对符号链接的处理,主要代码如下:
/*
* Name resolution.
* This is the basic name resolution function, turning a pathname into
* the final dentry. We expect 'base' to be positive and a directory.
*
* Returns 0 and nd will have valid dentry and mnt on success.
* Returns error and drops reference to input namei data on failure.
*/
static int link_path_walk(const char * name, struct nameidata * nd)
{
for(;;){
...
if (err) {
// 获取符号链接指向的目标(路径)
const char * s = get_link(nd);
// 判断 get_link 是否返回错误。
if (IS_ERR(s))
return PTR_ERR(s);
err = 0;
// 如果指向的路径为空,释放当前符号链接,跳过不处理。
if (unlikely(!s)) {
/* jumped */
put_link(nd);
}
else {
// 否则保存当前剩余部分的路径,例如:“a/b/c/d.txt”,其中 “b” 是当前处理的符号链接,那么需要保存 “c/d.txt”。
nd->stack[nd->depth - 1].name = name;
// 把接下来要处理的路径设置为符号链接指向的路径。例如:“b” 指向 “e/f”,那么 name 设置为 “e/f”。
name = s;
continue;
}
}
// 检查是否是目录
if (unlikely(!d_can_lookup(nd->path.dentry))) {
if (nd->flags & LOOKUP_RCU) {
if (unlazy_walk(nd, NULL, 0))
return - ECHILD;
}
return - ENOTDIR;
}
}
}
static __always_inline const char * get_link(struct nameidata * nd)
{
// 获取保存的符号链接。
struct saved * last = nd->stack + nd->depth - 1;
struct dentry * dentry = last->link.dentry;
struct inode * inode = last->inode;
int error;
const char * res;
if (! (nd->flags & LOOKUP_RCU)) {
// 更新符号链接的访问时间。
touch_atime(&last->link);
// 因为我门刚刚从 rcu-walk 模式切换过来,而 rcu-walk 是不允许抢占的,所以现在需要看看
// 刚才有没有想要抢占但又抢占失败的进程,如果有的话就让人家先运行,毕竟我们现在是 ref-walk 模式,
// 不是那么着急的,这就是 cond_resched 所做的。
cond_resched();
}
else if (atime_needs_update(&last->link, inode)) {// 判断是否需要更新访问时间
// 如果需要,那么退出 rcu-walk 模式,unlazy_walk 尝试使当前的 nd->path,nd->root,dentry
// 在 ref-walk 模式下有效。
if (unlikely(unlazy_walk(nd, NULL, 0)))
return ERR_PTR(-ECHILD);
touch_atime(&last->link);
}
error = security_inode_follow_link(dentry, inode, nd->flags & LOOKUP_RCU);
if (unlikely(error))
return ERR_PTR(error);
// LAST_BIND 在跟踪符号链接时使用,而该符号链接的组件还没有被处理。
nd->last_type = LAST_BIND;
res = inode->i_link;
if (!res) {
if (nd->flags & LOOKUP_RCU) {
if (unlikely(unlazy_walk(nd, NULL, 0)))
return ERR_PTR(-ECHILD);
}
// 调用 inode 的 follow_link 方法获取符号链接指向的路径。
res = inode->i_op->follow_link(dentry, &last->cookie);
if (IS_ERR_OR_NULL(res)) {
last->cookie = NULL;
return res;
}
}
// 这里的处理跟 path_init 函数里面的处理差不多,处理绝对路径,设置 nd->path 为文件系统的根目录。
if (*res == '/') {
if (nd->flags & LOOKUP_RCU) {
struct dentry * d;
if (!nd->root.mnt)
set_root_rcu(nd);
nd->path = nd->root;
d = nd->path.dentry;
nd->inode = d->d_inode;
nd->seq = nd->root_seq;
if (unlikely(read_seqcount_retry(&d->d_seq, nd->seq)))
return ERR_PTR(-ECHILD);
}
else {
if (!nd->root.mnt)
set_root(nd);
path_put(&nd->path);
nd->path = nd->root;
path_get(&nd->root);
nd->inode = nd->path.dentry->d_inode;
}
// LOOKUP_JUMPED 意味着选择当前 dentry 不是因为它的名称正确,而是出于其他原因。
// 当跟随“..” 时就会发生这种情况。跟随一个符号链接跳转到 “/”(这里就是这种情况),
// 通过挂载点时 或访问 /proc/$PID/fd/$FD 符号链接。
nd->flags |= LOOKUP_JUMPED;
while (unlikely(* ++res == '/'));
}
if (! *res) // 如果该符号链接只是指向 “/” 的符号链接,那么返回 NULL。
res = NULL;
return res;
}
follow_link: called by the VFS to follow a symbolic link to the inode it points to. Only required if you want to support symbolic links. This method returns the symlink body to traverse (and possibly resets the current position with nd_jump_link()). If the body won't go away until the inode is gone, nothing else is needed; if it needs to be otherwise pinned, the data needed to release whatever we'd grabbed is to be stored in void * variable passed by address to follow_link() instance.
follow_link: VFS 调用 follow_link 来跟踪指向 inode 的符号链接。仅当您希望支持符号链接时才需要。这个方法返回要跟随的符号链接的内容(可能使用 nd_jump_link() 重置当前位置)。如果内容不会在inode消失之前消失,则不需要其他任何;如果需要以其他方式固定它,为了将来可以释放这些获取的数据,我们把它将存储在 void ** 类型的变量中,该变量通过传址方式传递给 follow_link()。
put_link: called by the VFS to release resources allocated by follow_link(). The cookie stored by follow_link() is passed to this method as the last parameter; only called when cookie isn't NULL.
VFS 调用 put_link 来释放 follow_link 分配的资源。cookie 参数就是传个 follow_link 函数的 void ** 类型变量。只有当 cookie 不为空的时候才调用该函数。
到这里基本全部分析完 link_path_walk 函数,假设此时我们已经处于路径中的最后一个分量,该分量有可能是个常规的目录,也有可能是个符号链接,不管何种情况 link_path_walk 函数返回 0,退出自身的 for( ; ; ) 循环。接下来调用 do_last函数解析最后一个分量。
struct file * path_openat(struct nameidata * nd,
const struct open_flags * op, unsigned flags) {
...
while (! (error = link_path_walk(s, nd)) && (error = do_last(nd, file, op, &opened)) > 0) {
nd->flags &= ~(LOOKUP_OPEN | LOOKUP_CREATE | LOOKUP_EXCL);
s = trailing_symlink(nd);
if (IS_ERR(s)) {
error = PTR_ERR(s);
break;
}
}
...
}
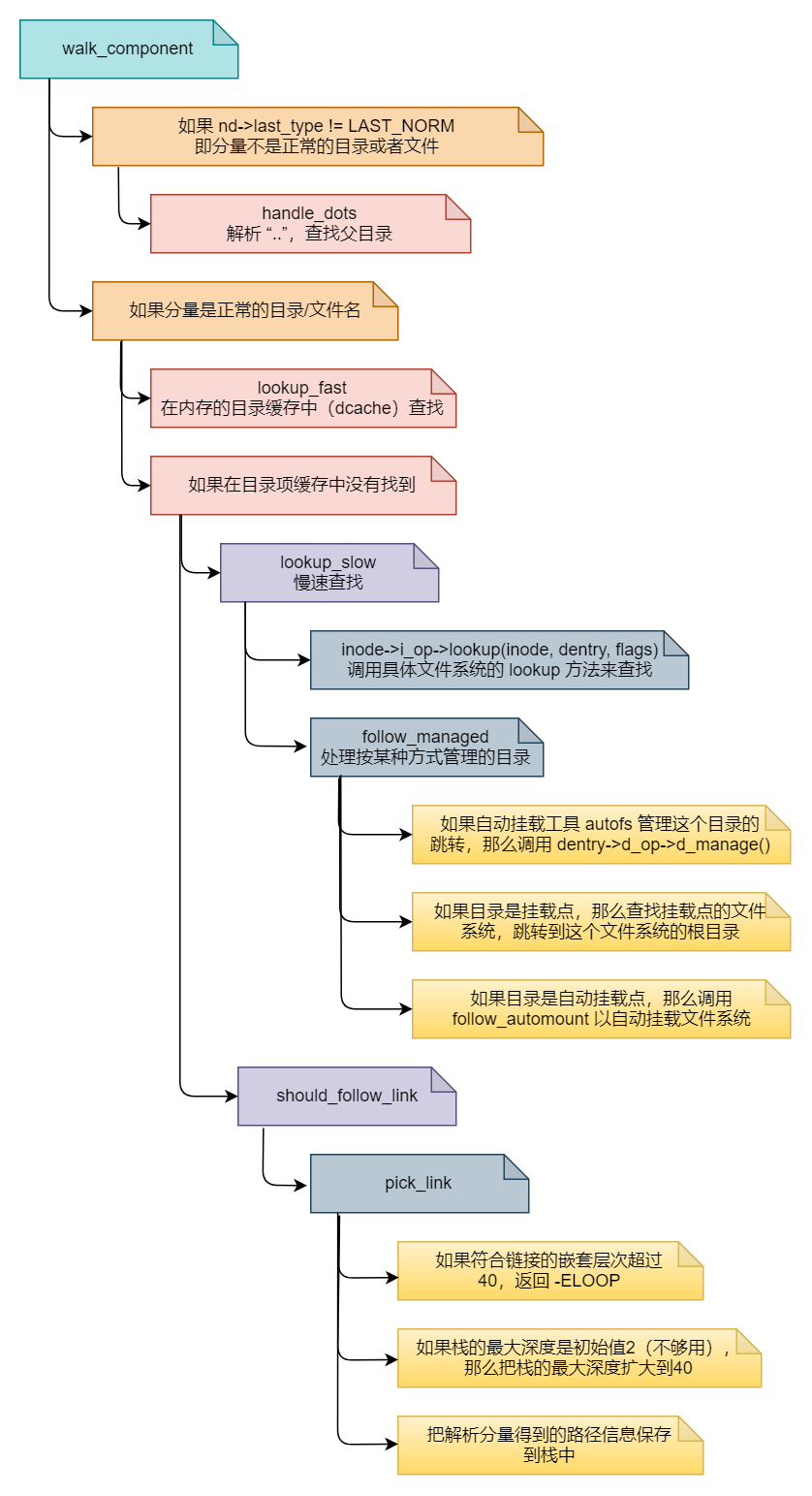
我们现在只是顺着路径走到了最终目标所在的目录,对最终目标还没有进行任何处理,甚至连这个最终目标到底存不存在我们都不知道。这一切都会交给 do_last 来完成,如果一切顺利它会填充 file 结构并返回 0;如果返回值大于 0(其实还是 1,为什么是“还是”?回头看看 walk_component 你就明白了),那就表明这个最终目标是一个符号链接且需要跟随这个符号链接,那么就要进入 while 循环的主体来顺着符号链接找到真正目标(还有一种情况是虽然最终目标是一个符号链接但我们只想得到这个符号链接本身,也不会进入这个循环)。符号链接的处理我们应该很熟悉了,只不过因为是最终目标所以增加了一些对标志位的判断和处理,大家理解这段代码应该不会有什么问题,下面是函数 walk_component 的流程图:
接下来我们就要进入 do_last 了,首先快速浏览一遍这个函数,它有 200 多行,而且遍地是 if,到处是 goto,谁第一次看到它都会发懵,根本就无从下手。但是只要我们抓住本质,一切事物都有规律可循,比如这个 do_last,可以说它是既复杂又简单。说它复杂是因为这里面进行了大量的标志位的检查,这些标志位是用户传进来指示 Kernel 需要打开什么样的文件、打开这些文件的模式以及怎么打开这些文件的,这些标志位总共有二十几个而且还相互影响相互制约,盘根错节的能不复杂吗?说它简单,那是和 link_path_walk 相比,在逻辑上和结构上相对简单,虽然这里也会遇到诸如跟随“..”、跟随符号链接、跟随挂载点,但这都是我们熟悉的老朋友了,没有什么新奇的东西。
既然 do_last 的复杂之处是在于对各个标志位的判断,那么我们至少需要了解设置这些标志位的目的,这可以参考 Linux 最权威的文档——man 手册有关 open 的内容。我们把这个手册当成指路牌,也可以看前面的 open 系统调用篇一。它可以引导我们理解 do_last 里对这些标志位的操作。其实用户设置的标志位并不是原封不动的传递进来,大家应该还记得在 do_sys_open 里会调用 build_open_flags 对这些标志位进行预处理和分装,所以我们可能还需要参考这个函数。
事情是这样的话我们的 do_last 之行就不能像之前一样沿着代码一步一步边走边看了,如果那样的话我们很快就会迷失在 flag 的海洋之中,而且也会使我们本来愉快的旅行变得枯燥乏味。现在让我们用一种全新的方式游览 do_last 吧,我称之为“情景模式”。在情景模式中我们假设了几个 open 应用的场景,然后在我们想像的场景之中看看都有哪些标志位起到了怎样的作用。
【场景一】open(pathname, O_RDONLY)
使用只读方式打开一个文件,这应该是最简单的 open 应用了。我们先来看看 build_open_flags 是怎么包装 O_RDONLY 的,
这个函数前面已经分析过了,这里我们只关注 O_RDONLY 的部分:
static inline int build_open_flags(int flags, umode_t mode, struct open_flags *op)
{
...
op->mode = 0; // 没有创建文件,所以 mode 设置为 0;
...
acc_mode = MAY_OPEN | ACC_MODE(flags);
...
op->open_flag = flags;
...
op->intent = flags & O_PATH ? 0 : LOOKUP_OPEN;
...
op->lookup_flags = lookup_flags;
return 0;
}
经过我们的简化,build_open_flags 和 O_RDONLY 相关的就剩这么三行了。我记得第一天说过,mode 代表文件权限只有在新建文件的时候才会用到,咱们当前的情景显然不是创建文件,所以先将 mode 置零。接下来设置访问模式 acc_mode 这个东西主要用来进行权限检查,把宏 ACC_MODE 展开后这一行其实就是这样:acc_mode = MAY_OPEN | MAY_READ,其意思也很明白,那就是对于目标文件我们至少需要打开和读取的权限。最后是判断标志位中 O_PATH 有没有被设置,如果没有就将 intent 加上 LOOKUP_OPEN,intent 用来标记我们对最终目标想要做什么操作(intent 字面意思就是“意图”),所以在以后我们会看到这里暂存的 op->intent 会在 do_last 里重出江湖。
/*
* Handle the last step of open()
*/
static int do_last(struct nameidata * nd,
struct file * file, const struct open_flags * op,
int * opened)
{
...
nd->flags &= ~LOOKUP_PARENT;
nd->flags |= op->intent;
...
if (! (open_flag & O_CREAT)) {
// 判断 last.name 是否以 “/” 结尾。
if (nd->last.name[nd->last.len])
nd->flags |= LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
/* we _can_ be in RCU mode here */
error = lookup_fast(nd, &path, &inode, &seq);
if (likely(!error))
goto finish_lookup;
if (error < 0)
return error;
BUG_ON(nd->inode != dir->d_inode);
}
...
}
LOOKUP_PARENT 实在 patn_init 的时候设置的,当时我们的目标是找到最终文件的父目录,但现在我们要找的就是最终文件,所以需要将这个标志位清除,紧接着 intent 重现江湖。很明显我们当前的情况不是创建文件,所以会进入这个 if (! (open_flag & O_CREAT)),这里有个熟面孔 lookup_fast,看到老朋友就是高兴。还记得 lookup_fast 执行结构有几种情况么?如果返回 0,则表示成功找到;返回 1,表示内存中没有,需要 lookup_real;返回小于 0,则表示需要从当前 rcu-walk 转到 ref-walk。那现在我们先看看返回 1 的情况。
/*
* Handle the last step of open()
*/
static int do_last(struct nameidata * nd,
struct file * file, const struct open_flags * op,
int * opened)
{
...
inode_lock_shared(dir->d_inode);
error = lookup_open(nd, &path, file, op, got_write, opened);
inode_unlock_shared(dir->d_inode);
if (error <= 0) {
if (error)
goto out;
if ((*opened & FILE_CREATED) || !S_ISREG(file_inode(file)->i_mode))
will_truncate = false;
audit_inode(nd->name, file->f_path.dentry, 0);
goto opened;
}
/*
* If atomic_open() acquired write access it is dropped now due to
* possible mount and symlink following (this might be optimized away if
* necessary...)
*/
if (got_write) {
mnt_drop_write(nd->path.mnt);
got_write = false;
}
// 处理按某种方式管理的目录(自动挂载工具 autofs 管理这个目录的跳转、挂载点、或自动挂载点)
error = follow_managed(&path, nd);
if (unlikely(error < 0))
return error;
if (unlikely(d_is_negative(path.dentry))) {
path_to_nameidata(&path, nd);
return -ENOENT;
}
/*
* create/update audit record if it already exists.
*/
audit_inode(nd->name, path.dentry, 0);
if (unlikely((open_flag & (O_EXCL | O_CREAT)) == (O_EXCL | O_CREAT))) {
path_to_nameidata(&path, nd);
return -EEXIST;
}
seq = 0; /* out of RCU mode, so the value doesn't matter */
inode = d_backing_inode(path.dentry);
...
}
lookup_fast 返回 1 的话程序会接着往下执行。现在的程序已经肯定不在 rcu-walk 模式里了(为什么?),所以可以使用各种有可能引起进程阻塞的锁来占有相应的资源了。接下来是一个新朋友 lookup_open,说是新朋友其实是新瓶装旧酒,因为它和 lookup_slow很像,都是先使用 lookup_dcache 在内存中找,如果不行就启动 lookup_real 在具体文件系统里面去找,当它成功返回时会将 path 指向找到的目标。
/*
* Look up and maybe create and open the last component.
*
* Must be called with i_mutex held on parent.
*
* Returns 0 if the file was successfully atomically created (if necessary) and
* opened. In this case the file will be returned attached to @file.
* 如果自动创建(如果需要)并打开文件成功,则返回0。在这种情况下,将 file 描述符通过参数 @file 返回。
* Returns 1 if the file was not completely opened at this time, though lookups
* and creations will have been performed and the dentry returned in @path will
* be positive upon return if O_CREAT was specified. If O_CREAT wasn't
* specified then a negative dentry may be returned.
*
* 如果此时文件还没有完全打开,则返回1,但是已经执行了查找和创建,如果指定了O_CREAT,
* 则返回的 @path 参数的dentry为positive。如果没有指定O_CREAT,则可能返回一个 negative dentry。
*
* An error code is returned otherwise.
*
* FILE_CREATE will be set in @*opened if the dentry was created and will be
* cleared otherwise prior to returning.
*
* 如果创建了dentry, FILE_CREATE将设置在@*open中,否则在返回之前将被清除。
*/
static int lookup_open(struct nameidata * nd, struct path * path,
struct file * file,
const struct open_flags * op,
bool got_write, int * opened)
{
struct dentry * dir = nd->path.dentry;
struct vfsmount * mnt = nd->path.mnt;
struct inode * dir_inode = dir->d_inode;
struct dentry * dentry;
int error;
bool need_lookup;
*opened &= ~FILE_CREATED;
dentry = lookup_dcache(&nd->last, dir, nd->flags, &need_lookup);
if (IS_ERR(dentry))
return PTR_ERR(dentry);
/* Cached positive dentry: will open in f_op->open */
if (!need_lookup && dentry->d_inode)
goto out_no_open;
if ((nd->flags & LOOKUP_OPEN) && dir_inode->i_op->atomic_open) {
return atomic_open(nd, dentry, path, file, op, got_write,
need_lookup, opened);
}
if (need_lookup) {
BUG_ON(dentry->d_inode);
dentry = lookup_real(dir_inode, dentry, nd->flags);
if (IS_ERR(dentry))
return PTR_ERR(dentry);
}
/* Negative dentry, just create the file */
if (!dentry->d_inode && (op->open_flag & O_CREAT)) {
umode_t mode = op->mode;
if (!IS_POSIXACL(dir->d_inode))
mode &= ~current_umask();
/*
* This write is needed to ensure that a
* rw->ro transition does not occur between
* the time when the file is created and when
* a permanent write count is taken through
* the 'struct file' in finish_open().
* 为了确保在创建文件和通过 finish_open() 中的 “struct file” 执行永久写计数之间不会发生 rw->ro 转换,
* 需要执行这个写操作。
*/
if (!got_write) {
error = -EROFS;
goto out_dput;
}
*opened |= FILE_CREATED;
error = security_path_mknod(&nd->path, dentry, mode, 0);
if (error)
goto out_dput;
// 调用 inode 的 i_op->create 创建文件。
error = vfs_create2(mnt, dir->d_inode, dentry, mode,
nd->flags & LOOKUP_EXCL);
if (error)
goto out_dput;
}
out_no_open:
path->dentry = dentry;
path->mnt = nd->path.mnt;
return 1;
out_dput:
dput(dentry);
return error;
}
atomic_open: called on the last component of an open. Using this optional method the filesystem can look up, possibly create and open the file in one atomic operation. If it cannot perform this (e.g. the file type turned out to be wrong) it may signal this by returning 1 instead of usual 0 or -ve . This method is only called if the last component is negative or needs lookup. Cached positive dentries are still handled by f_op->open(). If the file was created, the FILE_CREATED flag should be set in "opened". In case of O_EXCL the method must only succeed if the file didn't exist and hence FILE_CREATED shall always be set on success.
atomic_open:在 open 操作的最后一个组件时被调用。使用这种可选方法,文件系统可以在一个原子操作中实现查找、创建和打开文件。如果它不能执行这个(例如,文件类型被证明是错误的),它可能通过返回 1 而不是通常的 0 或 -ve 来发出信号。只有当最后一个组件为 negative 或需要查找时才调用此方法。缓存的 positive dentry 仍然由 f_op->open() 处理。如果文件已经创建,FILE_CREATED 标志应该设置在 “open”中。在 O_EXCL 的情况下,该方法只有在文件不存在时才必须成功,因此 FILE_CREATED 应该始终设置为成功。
接下来是 follow_managed 它也算是老朋友吧,之前我们简单介绍过的。再往下走,我们来到了 finish_lookup:
finish_lookup:
if (nd->depth)
put_link(nd);
error = should_follow_link(nd, &path, nd->flags & LOOKUP_FOLLOW, inode, seq);
if (unlikely(error))
return error;
if ((nd->flags & LOOKUP_RCU) || nd->path.mnt != path.mnt) {
path_to_nameidata(&path, nd);
}
else {
save_parent.dentry = nd->path.dentry;
save_parent.mnt = mntget(path.mnt);
nd->path.dentry = path.dentry;
}
nd->inode = inode;
nd->seq = seq;
/* Why this, you ask? _Now_ we might have grown LOOKUP_JUMPED... */
这里是 lookup_fast 返回 1 和返回 0 的交汇点。这时就需要更新 nd 了,但这个交汇点有两个来源也就是说现在有可能还在 rcu-walk 模式当中,所以还需要分情况处理一下。请注意这个 if 的第二个条件 nd->path.mnt != path->mnt,什么情况下会出现这两个 mnt 不相等呢?还记得 nd 的脾气吗,当遇到挂载点的时候 nd 会原地踏步,只有 path 才大无畏的向前走。既然两个 mnt 不一样了,那么更新 nd 前也许要放弃原先占有的结构,这就是 path_to_nameidata 所做。接下来就要彻底告别 rcu-walk 了:
static inline void path_to_nameidata(const struct path * path,
struct nameidata * nd)
{
// 如果为 ref-walk 模式,那么释放计数引用。(这个模式下会获取 dentry 和 mnt 的引用)
if (! (nd->flags & LOOKUP_RCU)) {
dput(nd->path.dentry);
if (nd->path.mnt != path->mnt)
mntput(nd->path.mnt);
}
nd->path.mnt = path->mnt;
nd->path.dentry = path->dentry;
}
接下来调用 complete_walk 来结束 rcu-walk 模式。
finish_open:
error = complete_walk(nd);
/**
* complete_walk - successful completion of path walk
* @nd: pointer nameidata
*
* If we had been in RCU mode, drop out of it and legitimize nd->path.
* Revalidate the final result, unless we'd already done that during
* the path walk or the filesystem doesn't ask for it. Return 0 on
* success, -error on failure. In case of failure caller does not
* need to drop nd->path.
*/
static int complete_walk(struct nameidata * nd)
{
struct dentry * dentry = nd->path.dentry;
int status;
// 如果还处于 RCU 模式,那么退出该模式,并使用 unlazy_walk 验证 nd->path 的有效性。
if (nd->flags & LOOKUP_RCU) {
if (! (nd->flags & LOOKUP_ROOT))
nd->root.mnt = NULL;
if (unlikely(unlazy_walk(nd, NULL, 0)))
return - ECHILD;
}
// 如果没有设置 LOOKUP_JUMPED 标志,返回 0;
if (likely(! (nd->flags & LOOKUP_JUMPED)))
return 0;
// 如果不需要再进行
if (likely(! (dentry->d_flags & DCACHE_OP_WEAK_REVALIDATE)))
return 0;
// called when the VFS needs to revalidate a "jumped" dentr
status = dentry->d_op->d_weak_revalidate(dentry, nd->flags);
if (status > 0)
return 0;
if (!status)
status = -ESTALE;
return status;
}
参考 vfs.txt 文档的 d_weak_revalidate 函数说明:
d_weak_revalidate: called when the VFS needs to revalidate a "jumped" dentry. This is called when a path-walk ends at dentry that was not acquired by doing a lookup in the parent directory. This includes "/", "." and "..", as well as procfs-style symlinks and mountpoint traversal.
d_weak_revalidate:当 VFS 需要重新验证 “jumped” 的 dentry 时调用。当路径查找结束时获取的 dentry (路径最后一个分量)不是通过在父目录中进行查找获得的。这包括 "/","." 和 "..",以及 procfs-style 符号链接和碰到挂载点时。
In this case, we are less concerned with whether the dentry is still fully correct, but rather that the inode is still valid. As with d_revalidate, most local filesystems will set this to NULL since their dcache entries are always valid.
在这种情况下,我们不太关心 dentry 是否仍然完全正确,而是关心 inode 是否仍然有效。与 d_revalidate一样,大多数本地文件系统将该值设置为 NULL,因为它们的 dcache 条目总是有效的。
This function has the same return code semantics as d_revalidate.
这个函数具有与d_revalidate相同的返回代码语义。
d_weak_revalidate is only called after leaving rcu-walk mode.
该函数只有在离开 rcu_walk 模式的时候才会被调用。
告别 rcu-walk 其实很简单,最主要的就是调用 unlazy_walk,之后就会重新启动进程抢占,本进程就有可能被切换出去,这样的话当前 CPU 就会经过 quiescent state,当所有 CPU 都经过了自己的 quiescent state 之后,在 rcu-walk 期间的变更才会被更新。接着如果当前不是 LOOKUP_JUMPED,就会直接返回。这个 LOOKUP_JUMPED 在哪里会被设置呢?其实我们之前遇到了很多次设置 LOOKUP_JUMPED 的地方,比方说遇到“..”的时候、遇到挂载点的时候、符号链接是绝对路径的时候,它们的共同点就是有可能会跨越(jump)文件系统。如果的确跨越了文件系统也很简单,检查一下当前 dentry 需不需要验证(DCACHE_OP_WEAK_REVALIDATE),大部分情况是不需要,所以这段代码咱们也省略了,有兴趣的同学请查阅 Kernel 源代码。
接下来终于要真正“打开”这个文件了:
finish_open_created:
error = may_open(&nd->path, acc_mode, open_flag);
if (error)
goto out;
BUG_ON(*opened & FILE_OPENED);
/* once it's opened, it's opened */
error = vfs_open(&nd->path, file, current_cred());
if (!error) {
*opened |= FILE_OPENED;
}
else {
if (error == -EOPENSTALE)
goto stale_open;
goto out;
}
...
out:
if (unlikely(error > 0)) {
WARN_ON(1);
error = -EINVAL;
}
if (got_write)
mnt_drop_write(nd->path.mnt);
path_put(&save_parent);
return error;
may_open 就是权限和标志位的检查,咱们就懒得进去看了。vfs_open 会真正打开这个我们期待已久的目标文件,里面主要是利用该文件系统自己的 file_operations.open 来填充 file 结构。如果一切顺利 vfs_open 返回 0,然后释放占用的资源之后就大功告成可以返回了。
/**
* vfs_open - open the file at the given path
* @path: path to open
* @file: newly allocated file with f_flag initialized
* @cred: credentials to use
*/
int vfs_open(const struct path *path, struct file *file,
const struct cred *cred)
{
struct inode *inode = vfs_select_inode(path->dentry, file->f_flags);
if (IS_ERR(inode))
return PTR_ERR(inode);
file->f_path = *path;
return do_dentry_open(file, inode, NULL, cred);
}
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *),
const struct cred *cred){
static const struct file_operations empty_fops = {};
int error;
f->f_mode = OPEN_FMODE(f->f_flags) | FMODE_LSEEK |
FMODE_PREAD | FMODE_PWRITE;
...
open = f->f_op->open;
...
return 0;
}
【场景二】open(pathname, O_PATH)
使用 O_PATH 将不会真正打开一个文件,而只是准备好该文件的文件描述符,而且如果使用该标志位的话系统会忽略大部分其他的标志位。特别是如果配合使用 O_NOFOLLOW,那么遇到符号链接的时候将会返回这个符号链接本身的文件描述符,而非符号链接所指的对象。
咱们还是先看看 build_open_flags 针对 O_PATH 做了什么手脚:
static inline int build_open_flags(int flags, umode_t mode, struct open_flags *op)
{
int lookup_flags = 0;
int acc_mode;
/*
* Clear out all open flags we don't know about so that we don't report
* them in fcntl(F_GETFD) or similar interfaces.
*/
flags &= VALID_OPEN_FLAGS;
...
op->mode = 0;
...
else if (flags & O_PATH) {
/*
* If we have O_PATH in the open flag. Then we
* cannot have anything other than the below set of flags
*/
flags &= O_DIRECTORY | O_NOFOLLOW | O_PATH;
acc_mode = 0;
}
...
op->intent = flags & O_PATH ? 0 : LOOKUP_OPEN;
...
if (flags & O_DIRECTORY)
lookup_flags |= LOOKUP_DIRECTORY;
if (!(flags & O_NOFOLLOW))
lookup_flags |= LOOKUP_FOLLOW;
op->lookup_flags = lookup_flags;
return 0;
}
首先在 else if 分支中,这里进行了一个“与”操作,这就将除了 O_DIRECTORY 和 O_NOFOLLOW的其他标志位全部清零了,这就忽略了其他的标志位。在 open 的说明中还有一个标志位 O_CLOEXEC 也受到 O_PATH 的保护,但是这个标志位不允许在用户空间直接设置,所以 build_open_flags 一开始就把它干掉了。另外 O_PATH 本身连一个真正的打开操作都不是就跟别提创建了,所以 mode 当然要置零了。既然不会打开文件那么也就和 LOOKUP_OPEN 无缘了。接下来就是处理一下受 O_PATH 保护两个标志位。注意,如果没有设置 O_NOFOLLOW 的话遇到符号链接是需要跟踪到底的。其实就算设置了 O_NOFOLLOW,我们还会看到在 do_last 里还有一次补救的机会,那就是路径名以 “/” 结尾的话也会跟踪符号链接到底的。
/*
* Handle the last step of open()
*/
static int do_last(struct nameidata * nd,
struct file * file, const struct open_flags * op,
int * opened)
{
...
if (! (open_flag & O_CREAT)) {
// 判断 last.name 是否以 “/” 结尾,如果是则设置 LOOKUP_FOLLOW 表示需要跟随符号链接。
if (nd->last.name[nd->last.len])
nd->flags |= LOOKUP_FOLLOW | LOOKUP_DIRECTORY;
/* we _can_ be in RCU mode here */
error = lookup_fast(nd, &path, &inode, &seq);
if (likely(!error))
goto finish_lookup;
if (error < 0)
return error;
BUG_ON(nd->inode != dir->d_inode);
}
...
retry_lookup:
...
mutex_lock(&dir->d_inode->i_mutex);
error = lookup_open(nd, &path, file, op, got_write, opened);
mutex_unlock(&dir->d_inode->i_mutex);
...
error = follow_managed(&path, nd);
...
finish_lookup:
if (nd->depth)
put_link(nd);
// 如果设置了 LOOKUP_FOLLOW 那么就跟随符号链接。当然最后返回一个符号链接也是 OK 的。
error = should_follow_link(nd, &path, nd->flags & LOOKUP_FOLLOW, inode, seq);
...
if ((nd->flags & LOOKUP_RCU) || nd->path.mnt != path.mnt) {
path_to_nameidata(&path, nd);
}
else {
save_parent.dentry = nd->path.dentry;
save_parent.mnt = mntget(path.mnt);
nd->path.dentry = path.dentry;
}
...
finish_open:
error = complete_walk(nd);
...
// should_follow_link 返回 0,也就是没有设置 LOOKUP_FOLLOW(不跟随符号链接),
// 但是如果是设置了 O_PATH,那么即使是符号链接也是 OK 的,继续往下执行。
if (unlikely(d_is_symlink(nd->path.dentry)) && ! (open_flag & O_PATH)) {
error = -ELOOP;
goto out;
}
...
finish_open_created:
error = may_open(&nd->path, acc_mode, open_flag);
if (error)
goto out;
BUG_ON(*opened & FILE_OPENED);
/* once it's opened, it's opened 如果一切正常返回 0*/
error = vfs_open(&nd->path, file, current_cred());
if (!error) {
*opened |= FILE_OPENED;
}
opened:
error = open_check_o_direct(file);
...
}
这里即使是返回符号链接也是 OK 的,我们来看看什么情况下符号链接是 OK 的?首先必须是 O_PATH,也就是我们假设的场景;同时还需要没有设置 LOOKUP_FOLLOW。在 build_open_flags 我们已经见过了一次设置 LOOKUP_FOLLOW 的地方,这里就是前面所说的补救的地方。也就是说只要路径名最后一个字符 + 1 是 “/”(这里不为 “/0” 就为“/”,为什么?不明白的可以回头看看 link_path_walk 的代码),那就表示如果这个最终目标是符号链接的话就要跟随。
接下来 lookup_open 就不用说了吧,当它返回的时候 path 会站上最终目标 nd 没变,接着更新 nd,接着判断即使是符号链接也 OK,如果不行,则返回错误。最后调用 vfs_open,在 vfs_open 中会调用 do_dentry_open:
static int do_dentry_open(struct file *f,
struct inode *inode,
int (*open)(struct inode *, struct file *),
const struct cred *cred)
{
...
if (unlikely(f->f_flags & O_PATH)) {
f->f_mode = FMODE_PATH;
f->f_op = &empty_fops;
return 0;
}
...
}
为啥 O_PATH 不会真正打开一个文件,看到这里大家就明白了吧,这里的代码很简单,一切尽在不言中了。当从 vfs_open 返回时,file 结构体几乎就是空的,只有 file.f_path 成员指向了这个文件,就连 f_op 都是空的。这或许就是 O_PATH 使用说明中一开始阐述的那两个目的具体表现吧。好像这个 O_PATH 情景比上一个 O_RDONLY 还要简单,那我们就再假设一个情景。
【场景三】open(pathname, O_WRONLY | O_CREAT | O_EXCL, S_IRUSR | S_IWUSR)
在这个场景中我们希望创建一个新文件(O_CREAT),并赋予该文件用户可读(S_IRUSR)和用户可写(S_IWUSR)的权限,然后以只写(O_WRONLY)的方式打开这个文件。O_EXCL 在这里保证该文件必须被创建,如果该文件已经存在则失败返回。
这些标志位的作用已经解释得很清楚了,现在来看看 build_open_flags:
static inline int build_open_flags(int flags, umode_t mode, struct open_flags *op)
{
int lookup_flags = 0;
int acc_mode;
/*
* Clear out all open flags we don't know about so that we don't report
* them in fcntl(F_GETFD) or similar interfaces.
*/
flags &= VALID_OPEN_FLAGS;
if (flags & (O_CREAT | __O_TMPFILE))
op->mode = (mode & S_IALLUGO) | S_IFREG;
|
...
/* Must never be set by userspace */
flags &= ~FMODE_NONOTIFY & ~O_CLOEXEC;
...
acc_mode = MAY_OPEN | ACC_MODE(flags);
op->open_flag = flags;
...
op->acc_mode = acc_mode;
op->intent = flags & O_PATH ? 0 : LOOKUP_OPEN;
if (flags & O_CREAT) {
op->intent |= LOOKUP_CREATE;
if (flags & O_EXCL)
op->intent |= LOOKUP_EXCL;
}
...
return 0;
}
由于是创建一个新文件,所以 mode 就不能丢弃了,在这里 mode 就是 “S_IRUSR | S_IWUSR”。然后在我们的情境中, acc_mode 将被设置成 “MAY_OPEN | MAY_WRITE”。最后 intent 也被设置成了相应的查询模式 “LOOKUP_OPEN”。接着还是 do_last:
static int do_last(struct nameidata * nd,
struct file * file, const struct open_flags * op,
int * opened)
{
...
else {
/* create side of things */
/*
* This will *only* deal with leaving RCU mode - LOOKUP_JUMPED
* has been cleared when we got to the last component we are
* about to look up
*/
error = complete_walk(nd);
if (error)
return error;
audit_inode(nd->name, dir, LOOKUP_PARENT);
/* trailing slashes? */
if (unlikely(nd->last.name[nd->last.len]))
return - EISDIR;
}
retry_lookup:
if (op->open_flag & (O_CREAT | O_TRUNC | O_WRONLY | O_RDWR)) {
error = mnt_want_write(nd->path.mnt);
if (!error)
got_write = true;
/*
* do _not_ fail yet - we might not need that or fail with
* a different error; let lookup_open() decide; we'll be
* dropping this one anyway.
*/
}
mutex_lock(&dir->d_inode->i_mutex);
error = lookup_open(nd, &path, file, op, got_write, opened);
mutex_unlock(&dir->d_inode->i_mutex);
...
}
首先会调用 complete_walk 告别 rcu-walk 模式,然后会判断这个最终目标是不是以 “/” 结尾,如果是的话就表示最终目标是一个目录那就返回 “- EISDIR” 并报错 “Is a directory”。随后,如果本次操作是有可能“写入”的,那就需要取得当前文件系统的写权限,但是注释上写的很明白,就算现在获取写权限失败也不要急着返回,因为首先现在只是“有可能”会“写入”,其次我们可能会因为别的原因失败,所以现在先不理会这次的 fail,让 lookup_open 来决定这一切吧。
接着就是 lookup_open,我们进去看看:
static int lookup_open(struct nameidata * nd, struct path * path,
struct file * file,
const struct open_flags * op,
bool got_write, int * opened)
{
...
*opened &= ~FILE_CREATED;
dentry = lookup_dcache(&nd->last, dir, nd->flags, &need_lookup);
if (IS_ERR(dentry))
return PTR_ERR(dentry);
/* Cached positive dentry: will open in f_op->open */
if (!need_lookup && dentry->d_inode)
goto out_no_open;
if ((nd->flags & LOOKUP_OPEN) && dir_inode->i_op->atomic_open) {
return atomic_open(nd, dentry, path, file, op, got_write,
need_lookup, opened);
}
if (need_lookup) {
BUG_ON(dentry->d_inode);
dentry = lookup_real(dir_inode, dentry, nd->flags);
if (IS_ERR(dentry))
return PTR_ERR(dentry);
}
/* Negative dentry, just create the file */
if (!dentry->d_inode && (op->open_flag & O_CREAT)) {
umode_t mode = op->mode;
if (!IS_POSIXACL(dir->d_inode))
mode &= ~current_umask();
/*
* This write is needed to ensure that a
* rw->ro transition does not occur between
* the time when the file is created and when
* a permanent write count is taken through
* the 'struct file' in finish_open().
*/
if (!got_write) {
error = -EROFS;
goto out_dput;
}
*opened |= FILE_CREATED;
error = security_path_mknod(&nd->path, dentry, mode, 0);
if (error)
goto out_dput;
// struct dentry * dir = nd->path.dentry; 指的是当前要创建 dentry 的父目录的 dentry,
// 所以是调用父目录 dentry 的 inode_operations.create。
error = vfs_create2(mnt, dir->d_inode, dentry, mode, nd->flags & LOOKUP_EXCL);
if (error)
goto out_dput;
}
out_no_open:
path->dentry = dentry;
path->mnt = nd->path.mnt;
return 1;
out_dput:
dput(dentry);
return error;
}
这里我们需要关注一个局部变量:opened,首先会清除改变量的 “FILE_CREATED” 位,如果该文件的确不存在的话会被重新赋上 “FILE_CREATED”,表示这个文件是这次创建的。最后,vfs_create2 会调用具体文件系统的 inode_operations.create 函数真正创建这个文件。
create: called by the open(2) and creat(2) system calls. Only required if you want to support regular files. The dentry you get should not have an inode (i.e. it should be a negative dentry). Here you will probably call d_instantiate() with the dentry and the newly created inode
create:由 open(2) 和 creat(2) 系统调用调用。只有当你想支持普通文件时才需要。你得到的 dentry 不应该有一个 inode(即它应该是一个 negative dentry)。在这里,您可能会使用 dentry 和新创建的 inode 调用d_instantiate()
d_instantiate: add a dentry to the alias hash list for the inode and updates the "d_inode" member. The "i_count" member in the inode structure should be set/incremented. If the inode pointer is NULL, the dentry is called a "negative dentry". This function is commonly called when an inode is created for an existing negative dentry.
d_instantiate:为 inode 的 alias 散列表添加一个 dentry,并更新 “d_inode” 成员。inode 结构中的 “i_count” 成员应该 set/incremented
如果 inode 指针为空,则 dentry 称为 “negative dentry”。当为现有的 negative dentry 创建 inode 时,通常会调用此函数。
/**
* d_instantiate - fill in inode information for a dentry
* @entry: dentry to complete
* @inode: inode to attach to this dentry
*
* Fill in inode information in the entry.
*
* This turns negative dentries into productive full members
* of society.
*
* NOTE! This assumes that the inode count has been incremented
* (or otherwise set) by the caller to indicate that it is now
* in use by the dcache.
*/
void d_instantiate(struct dentry *entry, struct inode * inode)
{
BUG_ON(!hlist_unhashed(&entry->d_u.d_alias));
if (inode)
spin_lock(&inode->i_lock);
__d_instantiate(entry, inode);
if (inode)
spin_unlock(&inode->i_lock);
security_d_instantiate(entry, inode);
}
EXPORT_SYMBOL(d_instantiate);
static void __d_instantiate(struct dentry *dentry, struct inode *inode)
{
unsigned add_flags = d_flags_for_inode(inode);
spin_lock(&dentry->d_lock);
// 添加到 alias 散列表。
if (inode)
hlist_add_head(&dentry->d_u.d_alias, &inode->i_dentry);
raw_write_seqcount_begin(&dentry->d_seq);
// 设置 dentry 的 inode.
__d_set_inode_and_type(dentry, inode, add_flags);
raw_write_seqcount_end(&dentry->d_seq);
spin_unlock(&dentry->d_lock);
fsnotify_d_instantiate(dentry, inode);
}
static inline void __d_set_inode_and_type(struct dentry *dentry,
struct inode *inode,
unsigned type_flags)
{
unsigned flags;
// 在这里设置
dentry->d_inode = inode;
flags = READ_ONCE(dentry->d_flags);
flags &= ~(DCACHE_ENTRY_TYPE | DCACHE_FALLTHRU);
flags |= type_flags;
WRITE_ONCE(dentry->d_flags, flags);
}
在篇三中,在 “lookup_slow -> __lookup_hash -> lookup_dcache” 中调用了 d_alloc:dentry = d_alloc(dir, name); 前面说了这里只是分配了dentry 的内存还没有绑定 inode,所以是个 “negative dentry”,在这里我们创建文件的时候调用了 d_instantiate 来进行了绑定,到这里才算真正完成了创建 dentry。 好了,回到 do_last:
static int do_last(struct nameidata * nd,
struct file * file, const struct open_flags * op,
int * opened)
{
...
if (*opened & FILE_CREATED) {
/* Don't check for write permission, don't truncate */
open_flag &= ~O_TRUNC;
will_truncate = false;
acc_mode = MAY_OPEN;
path_to_nameidata(&path, nd);
goto finish_open_created;
}
...
if (unlikely((open_flag & (O_EXCL | O_CREAT)) == (O_EXCL | O_CREAT))) {
path_to_nameidata(&path, nd);
return - EEXIST;
}
...
finish_open_created:
error = may_open(&nd->path, acc_mode, open_flag);
if (error)
goto out;
BUG_ON(*opened & FILE_OPENED);
/* once it's opened, it's opened */
error = vfs_open(&nd->path, file, current_cred());
if (!error) {
*opened |= FILE_OPENED;
}
else {
if (error == -EOPENSTALE)
goto stale_open;
goto out;
}
...
}
这里有两个地方用到了局部变量 opened,首先如果这个文件就是本次新建的,那么就要清除 “O_TRUNC” 位。“O_TRUNC” 用来将打开的文件长度“截断”为零,其实就是将文件清空,因为我们是新建的文件所以这个标志位显然是没用的了。既然已经成功的创建了新文件,那么写权限也没必要检查了,然后直接跳转到标号 finish_open_created 处完成打开。如果这个文件本来就存在呢?这时会检查 “O_EXCL” 和 “O_CREAT” 两个标志位,因为 “O_EXCL” 标志位要求必须创建成功,所以这里就会返回 “File exists” 错误。最后 may_open 检查相应的权限,然后 vfs_open 完成打开操作,这两个函数我们已经看过了,这里就不深入了。
到此,终于分析完了系统调用 open。
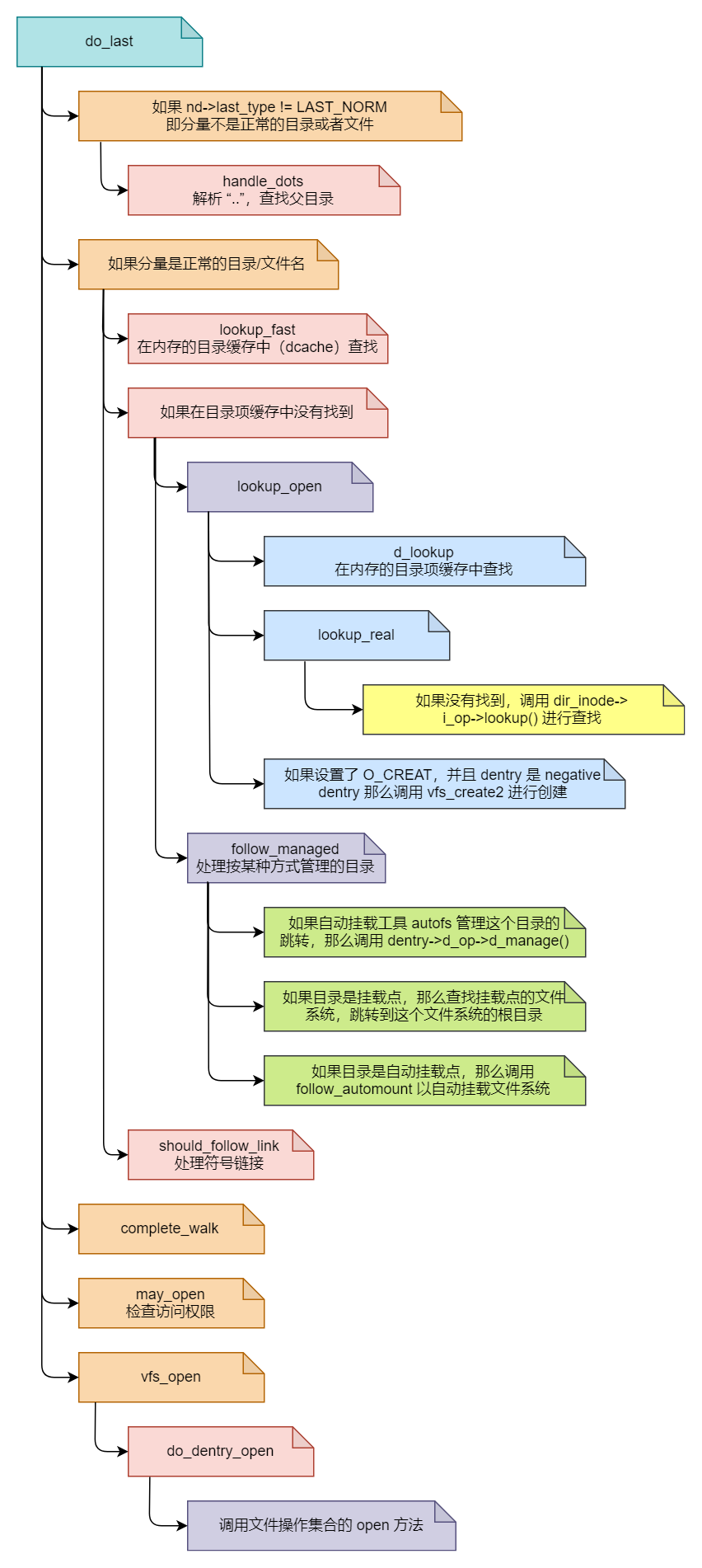
最后献上 do_last 的流程图:
前前后后看文档,博客,看书,写这个系列花了快一个月的时间,这里我主要参考了:
走马观花: Linux 系统调用 open 七日游 系列文章,可以说博客中大部分是摘抄过来了的,只是使用了 Linux 内核 4.4 版本的源码作为修改。
其次就是 Linux 源码“Documentation/filesystems” 目录下的 vfs.txt,autofs.txt 等文档。
最后就是这本 《Linux 内核深度解析》 余华兵 这本书。
