

“..”处理函数 handle_dots
static inline int handle_dots(struct nameidata * nd, int type)
{
if (type == LAST_DOTDOT) {
if (nd->flags & LOOKUP_RCU) {
return follow_dotdot_rcu(nd);
}
else
return follow_dotdot(nd);
}
return 0;
}
这里只是针对 “..” 做处理;如果是 “.” 的话那就就代表的是当前路径,直接返回就好了。前面说过 do_filp_open 会首先使用 RCU 策略进行操作,如果不行再用普通策略。这里就可以看出只有 RCU 失败才会返回 -ECHILD 以启动普通策略。但是大家有没有发现,这里并没有对 follow_dotdot(rcu) 的返回值进行检查,为什么?这是因为 “..” 出现在路径里就表示要向“上”走一层,也就是要走到父目录里面去,而父目录一定是存在内存中而且对于当前的进程来说一定也是合法的,否则在读取父目录的时候就已经出错了。接着我们就来 “跟随 ..”。
static int follow_dotdot_rcu(struct nameidata * nd)
{
struct inode * inode = nd->inode;
//设置 nd 的根目录(nd.root)
if (!nd->root.mnt)
set_root_rcu(nd);
while (1) {
/*
如果当前路径就是预设根目录的话,就什么也不做直接跳出循环(
都已经到根目录了不退出还等啥呢,大家可以在根目录试试这个命令“cd ../../”,看看有什么效果)
*/
if (path_equal(&nd->path, &nd->root))
break;
// 当前路径不是预设根目录,但也不是当前文件系统的根目录,
// 那么向上走一层也是很简单的事,直接将父目录项拿过来就是了。
if (nd->path.dentry != nd->path.mnt->mnt_root) {
struct dentry * old = nd->path.dentry;
// 获得父目录
struct dentry * parent = old->d_parent;
unsigned seq;
inode = parent->d_inode;
seq = read_seqcount_begin(&parent->d_seq);
// 如果当前的 dentry 发生了改变(其他进程修改或者删除),就返回错误。
if (unlikely(read_seqcount_retry(&old->d_seq, nd->seq)))
return - ECHILD;
// 设置当前路径为它的父目录。
nd->path.dentry = parent;
nd->seq = seq;
//path_connected - Verify that a path->dentry is below path->mnt.mnt_root
if (unlikely(!path_connected(&nd->path)))
return - ENOENT;
break;
}
else {//到最后,当前路径一定是某个文件系统的根目录,往上走有可能就会走到另一个文件系统里去了。
struct mount * mnt = real_mount(nd->path.mnt);
// 获取父挂载描述符(mount)。
struct mount * mparent = mnt->mnt_parent;
// 获取挂载点。
struct dentry * mountpoint = mnt->mnt_mountpoint;
// 获取挂载点的索引节点。
struct inode * inode2 = mountpoint->d_inode;
// 获取 mountpoint->d_seq 序列锁的初始 count,用于多线程竞争。
unsigned seq = read_seqcount_begin(&mountpoint->d_seq);
// 使用全局序列锁 mount_lock 检查当前路径分量有没有发生改变。如果有,返回 -ECHILD
if (unlikely(read_seqretry(&mount_lock, nd->m_seq)))
return - ECHILD;
// 当前的文件系统是不是根文件系统,也就是 rootfs 文件系统。如果是则返回。
if (&mparent->mnt == nd->path.mnt)
break;
/* 现在我们知道当前路径分量处于挂载点 */
nd->path.dentry = mountpoint;
// 设置为父挂载描述符。
nd->path.mnt = &mparent->mnt;
inode = inode2;
nd->seq = seq;
}
}
// d_mountpoint 函数检查 dentry 的 d_flags 有没有设置 DCACHE_MOUNTED,即检查该目录
// 是否是挂载点。
while (unlikely(d_mountpoint(nd->path.dentry))) {// 如果是挂载点
struct mount * mounted;
// 在散列表中通过{父挂载描述符,名称}方式查找对应的挂载描述符。
mounted = __lookup_mnt(nd->path.mnt, nd->path.dentry);
// 检查期间挂载点是否有改变。
if (unlikely(read_seqretry(&mount_lock, nd->m_seq)))
return - ECHILD;
// 如果没有在散列表中找到,退出循环。
if (!mounted)
break;
// 现在更新为找到的文件系统的挂载描述符。
nd->path.mnt = &mounted->mnt;
// 现在更新为找到的文件系统的根目录,接着继续循环,如果根目录也为挂载点
// 那么继续找,直到找到一个根目录不为挂载点的文件系统。
nd->path.dentry = mounted->mnt.mnt_root;
inode = nd->path.dentry->d_inode;
nd->seq = read_seqcount_begin(&nd->path.dentry->d_seq);
}
nd->inode = inode;
return 0;
}
set_root_rcu(nd); 首先设置 nd 的根目录(nd.root),还记得我们在哪里设置过这个成员么?没错,在 path_init 函数里,如果是绝对路径的话就会把这个 nd.root 设置成当前进程的根目录(其实还可以在 do_file_open_root 里预设这个值,所以为了和系统根目录区分,我们称 nd.root 为预设根目录),但如果是相对路径的话,就没有对 nd.root 进行初始化。为啥要分两步走呢?还是因为效率问题,任何一个目录都是一种资源,根目录也不例外,要获取某种资源必定会有一定的系统开销(在这里就是顺序锁),况且很有可能辛辛苦苦获得了这个根目录资源却根本就用不上,造成无端的浪费,所以 Kernel 本着能不用就不用的原则不到万不得已绝不轻易占用系统资源。现在的情况是路径中出现了“..”,就说明需要向上走一层,也就有可能会访问根目录,所以现在正是获取根目录的时候。
接下来是一个 while 循环,这时就分了三种情况:
- 当前目录就是前面获取的预设根目录,那么什么都不做,退出。
- 当前目录不是预设根目录,但也不是当前文件系统的根目录,那么直接获取当前目录的父目录即可。
- 当前目录不是预设根目录,但它是当前文件系统的根目录,那么往上走就会跑到别的文件系统。
对于第三种情况,需要了解文件系统挂载相关知识,可以参考链接: Linux挂载文件系统
这里结合图片来解释该种情况: 这是一个关于 mount(挂载)的故事。在 Kernel 世界里,挂载是一项很了不起的特性,它可以将不同类型的文件系统组合成一个有机的整体,从使用者角度来看不同的文件系统并没有什么区别,那么 Kernel 是怎么做到呢?首先,Kernel 会为每个文件系统准备一个 mount 结构,然后再把这个结构加入到 vfs 这颗大树上就好了。这么一个小小的 mount 结构就这么神奇?请看图,一个 mount 中有三个很重要的成员,他们分别指向父 mount 结构(5)、本文件系统自己的根目录(6)和本文件系统的挂载点(7),前两个很好理解,那么挂载点是什么呢?简单地说挂载点就是父级文件系统的某个目录,一旦将某个文件系统挂载到某个目录上,这个目录就成了该文件系统的根目录了。并且该目录的标志位 DCACHE_MOUNTED 将被置位,这将表明这个目录已经是一个挂载点了,如果要访问这个目录的话就要顺着 mount 结构访问另一个文件系统了,原来的内容将变得不可访问(被隐藏了)。
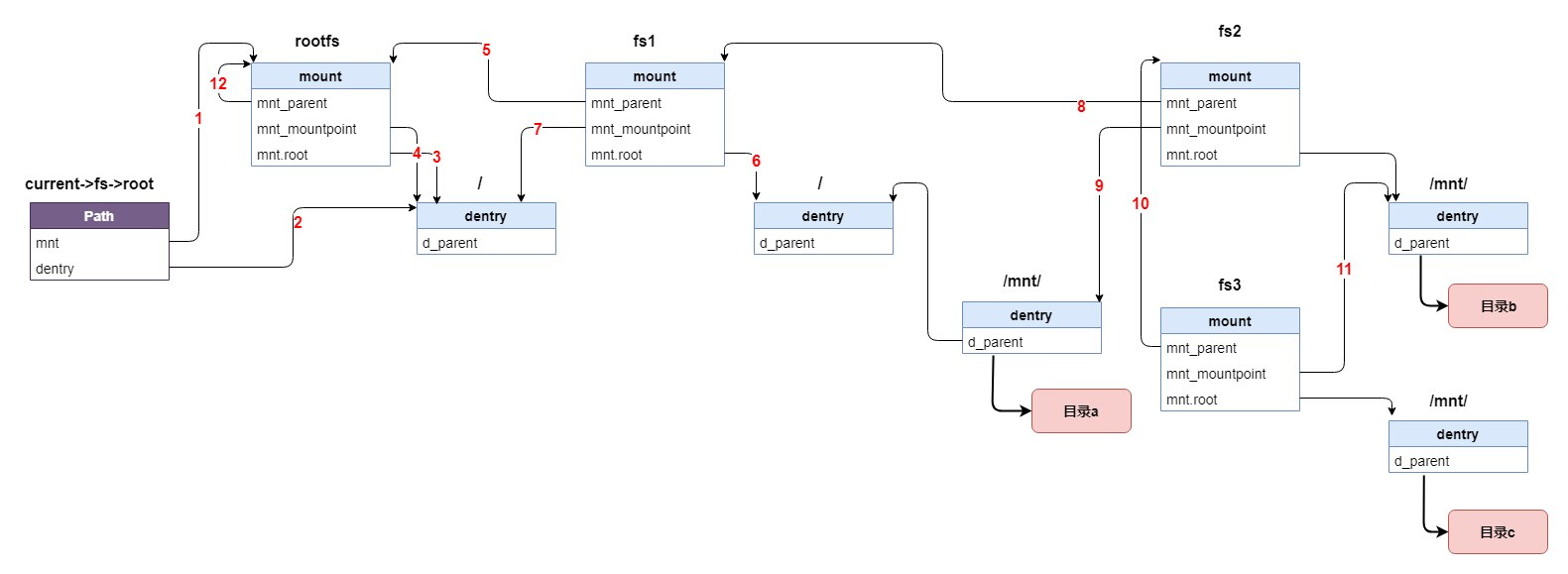
现在我们从图的左边讲起,带你一窥 mount 的风采。一个进程有一个叫 root 的 path 结构,它就是本进程的根目录(大多数情况下它就是系统根目录),root 中两个成员分别指向某个文件系统的 mount 结构(其实是指向类型为 vfsmoust 的 mount.mnt 但这样理解没问题)(1)和该文件系统的根目录(2),这个文件系统就是所谓根文件系统(在图中就是 rootfs)。由于它是根文件系统,所以它的父 mount 结构就是它自己(12)它的挂载点就是它自己的根目录(4)。但是 rootfs 只是一个临时的根文件系统,在 Kernel 的启动过程中加载完 rootfs 之后会紧接着解压缩 initramfs 到 rootfs 中,这里面包括了驱动以及加载真正的根文件系统的工具,Kernel 通过加载这些驱动、使用这些工具实现了挂载真正的根文件系统。之后 rootfs 将推出历史舞台,但作为文件系统的总根 rootfs 并不会被卸载。图中 fs1 就是所谓的真正的根文件系统,Kernel 把它挂载到了 rootfs 的根目录上(7),并且将它的父 mount 结构指向了 rootfs(5)。这时访问根目录的话就会直接访问到 fs1 的根目录,而 rootfs 就好像不存在了一样。
再看 fs1,他有一个子目录 “mnt/”,以及 “mnt/” 的子目录 “a”,此时路径 “/mnt/a/” 是可访问的。但现在我们还有另一个文件系统 fs2,我们把它挂载到“/mnt/”上会发生什么呢?首先 fs2 的父 mount 将指向 fs1(8),然后 fs2 的挂载点将指向 “/mnt/” 的dentry(9),同时 “mnt/” dentry 的 d_flags 的 DCACHE_MOUNTED 将被置位。此时路径 “/mnt/a/” 就不可访问了,取而代之的是 “/mnt/b/”。本着不怕麻烦的精神我们再折腾一下,把 fs3 也挂载到 “/mnt/” 上,这时和挂载 fs2 一样父 mount 将指向 fs2(10),但是挂载点应该指向哪里呢?答案是 fs2 的根目录(11)。这时“/mnt/b/”也消失了,我们只能看见“/mnt/c”了。这样整个结构就形成了一个挂载的序列,最后挂载的在序列末尾,Kernel 可以很容易的通过这个序列找到最初的挂载点和最终的文件系统。(图中几个 “/mnt” 目录的 dentry 是同一个 dentry,图中画了几个是为了方便作图。)
在顺序查找的情景下,当遇到一个目录时 Kernel 会判断这个目录是不是挂载点(检查 DCACHE_MOUNTED 标志位),如果是就要找到挂载到这个目录的文件系统,继而找到该文件系统的根目录,然后在判断这个根目录是不是挂载点,如果是那就再往下找直到某个文件系统的根目录不再是挂载点。反向查找也和顺序查找类似,把上面代码放这里,方便看:
static int follow_dotdot_rcu(struct nameidata * nd)
{
while(1){
...
else {//到最后,当前路径一定是某个文件系统的根目录,往上走有可能就会走到另一个文件系统里去了。
struct mount * mnt = real_mount(nd->path.mnt);
// 获取父挂载描述符(mount)。
struct mount * mparent = mnt->mnt_parent;
// 获取挂载点。
struct dentry * mountpoint = mnt->mnt_mountpoint;
// 获取挂载点的索引节点。
struct inode * inode2 = mountpoint->d_inode;
// 获取 mountpoint->d_seq 序列锁的初始 count,用于多线程竞争。
unsigned seq = read_seqcount_begin(&mountpoint->d_seq);
// 使用全局序列锁 mount_lock 检查当前路径分量有没有发生改变。如果有,返回 -ECHILD
if (unlikely(read_seqretry(&mount_lock, nd->m_seq)))
return - ECHILD;
// 当前的文件系统是不是根文件系统,如果是则返回。
if (&mparent->mnt == nd->path.mnt)
break;
/*
现在我们知道当前路径分量设置为挂载点目录,但仅仅这样做是不够的,
因为很有可能现在的这个目录也是该文件系统的根目录,所以继续循环。
*/
nd->path.dentry = mountpoint;
// 设置为父挂载描述符。
nd->path.mnt = &mparent->mnt;
inode = inode2;
nd->seq = seq;
}
...
}
...
}
当跳出这个 while(1) 循环时我们已经站在某个目录上了,一般来说这个目录就是我们想要的目标,而不会是一个挂载点,但也有例外。请看 while(1) 循环中第一个 if 和最后那个 else 中的那个 if,想必大家已经发现了,当遇到(预设)根目录的时候会直接退出循环,而这时我们的位置就相当于站在图中 rootfs 的根目录上,这显然不是我们想要的,我们想要站在 fs1 的根目录上。这就需要接下来的循环,再顺着 mount 结构往下走。
static int follow_dotdot_rcu(struct nameidata * nd)
{
...
// d_mountpoint 函数检查 dentry 的 d_flags 有没有设置 DCACHE_MOUNTED,即检查该目录
// 是否是挂载点。
while (unlikely(d_mountpoint(nd->path.dentry))) {// 如果是挂载点
struct mount * mounted;
// 在散列表中通过{父挂载描述符,名称}方式查找对应的挂载描述符。
mounted = __lookup_mnt(nd->path.mnt, nd->path.dentry);
// 检查期间挂载点是否有改变。
if (unlikely(read_seqretry(&mount_lock, nd->m_seq)))
return - ECHILD;
// 如果没有在散列表中找到,退出循环。
if (!mounted)
break;
// 现在更新为找到的文件系统的挂载描述符。
nd->path.mnt = &mounted->mnt;
// 现在更新为找到的文件系统的根目录,接着继续循环,如果根目录也为挂载点
// 那么继续找,直到找到一个根目录不为挂载点的文件系统。
nd->path.dentry = mounted->mnt.mnt_root;
inode = nd->path.dentry->d_inode;
nd->seq = read_seqcount_begin(&nd->path.dentry->d_seq);
}
...
}
static inline bool d_mountpoint(const struct dentry *dentry)
{
return dentry->d_flags & DCACHE_MOUNTED;
}
d_mountpoint() 就是检查标志位 DCACHE_MOUNTED,然后在某个散列表中查找属于这个挂载点的 mount 结构,如果找到了(如果某个目录既是挂载点但又没有任何文件系统挂载在上面那就说明这个目录可能拥有自动挂载的属性),就往下走一层,走到挂载文件系统的根目录上,然后再回到 while (unlikely(d_mountpoint(nd->path.dentry))) 再判断、查找、向下走,周而复始直到某个非挂载点。
对于非 RCU 模式的 follow_dotdot() 函数,流程是一样的,只不过同步的手段不一样而已,这里就不描述了。
挂载描述符缓存介绍
这里提下 __lookup_mnt 挂载描述符查找函数:
/*
* find the first mount at @dentry on vfsmount @mnt.
* call under rcu_read_lock()
*/
struct mount *__lookup_mnt(struct vfsmount *mnt, struct dentry *dentry)
{
struct hlist_head *head = m_hash(mnt, dentry);
struct mount *p;
// 遍历哈希表。
hlist_for_each_entry_rcu(p, head, mnt_hash)
if (&p->mnt_parent->mnt == mnt && p->mnt_mountpoint == dentry)
return p;
return NULL;
}
/**
* hlist_for_each_entry_rcu - iterate over rcu list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*
* This list-traversal primitive may safely run concurrently with
* the _rcu list-mutation primitives such as hlist_add_head_rcu()
* as long as the traversal is guarded by rcu_read_lock().
*/
#define hlist_for_each_entry_rcu(pos, head, member) \
for (pos = hlist_entry_safe (rcu_dereference_raw(hlist_first_rcu(head)),\
typeof(*(pos)), member); \
pos; \
pos = hlist_entry_safe(rcu_dereference_raw(hlist_next_rcu(\
&(pos)->member)), typeof(*(pos)), member))
那么是在哪里把挂载描述符加入到哈希表中,添加函数为:
static void __attach_mnt(struct mount *mnt, struct mount *parent)
{
hlist_add_head_rcu(&mnt->mnt_hash,
m_hash(&parent->mnt, mnt->mnt_mountpoint));
list_add_tail(&mnt->mnt_child, &parent->mnt_mounts);
}
/*
* vfsmount lock must be held for write
*/
static void commit_tree(struct mount *mnt)
{
struct mount *parent = mnt->mnt_parent;
struct mount *m;
LIST_HEAD(head);
struct mnt_namespace *n = parent->mnt_ns;
BUG_ON(parent == mnt);
list_add_tail(&head, &mnt->mnt_list);
list_for_each_entry(m, &head, mnt_list)
m->mnt_ns = n;
list_splice(&head, n->list.prev);
n->mounts += n->pending_mounts;
n->pending_mounts = 0;
//添加到哈希表中。
__attach_mnt(mnt, parent);
touch_mnt_namespace(n);
}
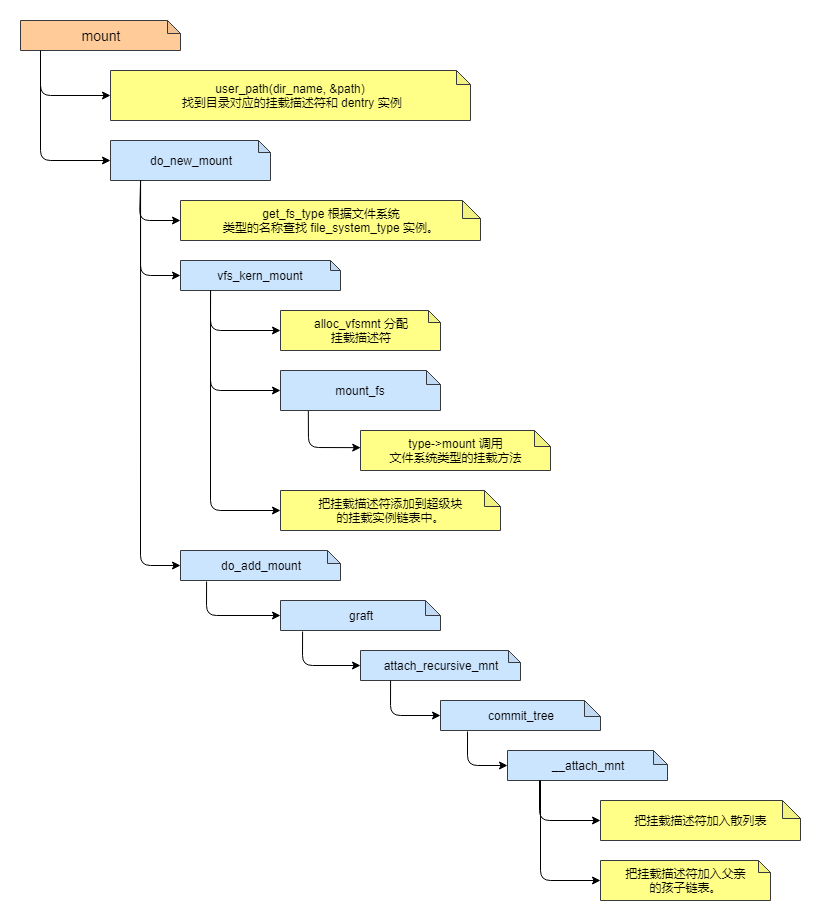
Linux挂载文件系统 里面介绍了系统调用 mount 的流程,其中会调用到 commit_tree 函数。下面是流程图:
dentry 查找
当对“.”和“..”处理完成后就直接返回进入下一个子路径循环了,但如果当前子路径不是“.”或“..”呢?
static int walk_component(struct nameidata * nd, int flags)
{
...
err = lookup_fast(nd, &path, &inode, &seq);
if (unlikely(err)) {
if (err < 0)
return err;
err = lookup_slow(nd, &path);
if (err < 0)
return err;
seq = 0; /* we are already out of RCU mode */
err = -ENOENT;
if (d_is_negative(path.dentry))
goto out_path_put;
}
...
}
在 Kernel 中任何一个常用操作都会有两套以上的策略,其中一个是高效率的相对而言另一个就是系统开销比较大的。比如在上面的代码中就能直观的发现 Kernel 会首先尝试 fast(lookup_fast) ,如果失败了才会启动 slow(lookup_slow)。其实在我们当前的场景中不止这两种策略,别忘了在这里还有 rcu-walk 和 ref-walk,现在我们先简单介绍一下 Kernel 在这里进行 “路径行走” 的策略,让大家有一个感性认识,然后再进入这几个函数中进行理性分析。首先 Kernel 会在 rcu-walk 模式下进入 lookup_fast 进行尝试,如果失败了那么就尝试就地转入 ref-walk,如果还是不行就回到 do_filp_open 从头开始。Kernel 在 ref-walk 模式下会首先在内存缓冲区查找相应的目标(lookup_fast),如果找不到就启动具体文件系统自己的 lookup 进行查找(lookup_slow)。注意,在 rcu-walk 模式下是不会进入 lookup_slow 的。如果这样都还找不到的话就一定是是出错了,那就报错返回吧,这时屏幕就会出现喜闻乐见的“No such file or directory”。
我们这就进入 lookup_fast,看看它到底有多快。
/*
* It's more convoluted than I'd like it to be, but... it's still fairly
* small and for now I'd prefer to have fast path as straight as possible.
* It _is_ time-critical.
*/
static int lookup_fast(struct nameidata * nd,
struct path * path, struct inode * *inode,
unsigned * seqp)
{
struct vfsmount * mnt = nd->path.mnt;
struct dentry * dentry, *parent = nd->path.dentry;
int need_reval = 1;
int status = 1;
int err;
/*
* Rename seqlock is not required here because in the off chance
* of a false negative due to a concurrent rename, we're going to
* do the non-racy lookup, below.
*/
if (nd->flags & LOOKUP_RCU) {
unsigned seq;
bool negative;
// 首先调用 __d_lookup_rcu 在内存中的某个散列表里通过字符串比较查找目标 dentry,
// 如果找到了就返回该 dentry
dentry = __d_lookup_rcu(parent, &nd->last, &seq);
// 如果没有找到就跳转到 unlazy。在这里会使用 unlazy_walk 就地将查找模式切换到
// ref-walk 如果还不行就只好返回到 do_filp_open 从头来过。
if (!dentry)
goto unlazy;
/*
* This sequence count validates that the inode matches
* the dentry name information from lookup.
*/
*inode = d_backing_inode(dentry);
negative = d_is_negative(dentry);
// 检查期间 dentry 有没有发生改变。
if (read_seqcount_retry(&dentry->d_seq, seq))
return - ECHILD;
/*
* This sequence count validates that the parent had no
* changes while we did the lookup of the dentry above.
*
* The memory barrier in read_seqcount_begin of child is
* enough, we can use __read_seqcount_retry here.
*/
// 这个序列号用来验证这期间父目录的 dentry 没有发生改变,内存屏蔽在孩子调用的
// read_seqcount_begin 中已被设置了(也就是前面调用的 read_seqcount_begin)
// 所以这里调用没有内存屏蔽的 __read_seqcount_retry 函数。
if (__read_seqcount_retry(&parent->d_seq, nd->seq))
return - ECHILD;
*seqp = seq;
// 某些文件系统需要进行有效性验证,比如网络文件系统,服务端的数据已经更新了,但是
// 客户端保存的是以前的数据。一般来说本地文件系统不需要进行有效性验证,比如 EXT4 文件系统。
if (unlikely(dentry->d_flags & DCACHE_OP_REVALIDATE)) {
status = d_revalidate(dentry, nd->flags);
// 有效性验证失败。
if (unlikely(status <= 0)) {
// 返回 -ECHILD 表示遇到了 rcu-walk 模式无法处理的问题。
if (status != -ECHILD)
need_reval = 0;
goto unlazy;
}
}
/*
* Note: do negative dentry check after revalidation in
* case that drops it.
* 在有效性验证后再次做 negative dentry 检测。
*/
if (negative)
return - ENOENT;
path->mnt = mnt;
path->dentry = dentry;
// 有可能当前目录是挂载点,或者自动挂载点等 “伪目标”,所以我们这里要跨过。
if (likely(__follow_mount_rcu(nd, path, inode, seqp)))
return 0;
//跑到这里表示需要切换到 ref-walk 模式进行查找。
unlazy:
if (unlazy_walk(nd, dentry, seq))
return - ECHILD;
}
else {
dentry = __d_lookup(parent, &nd->last);
}
// 如果还是没有找到 dentry,那么返回 1 ,接着在 walk_component 函数中进行 lookup_slow。
if (unlikely(!dentry))
goto need_lookup;
if (unlikely(dentry->d_flags & DCACHE_OP_REVALIDATE) && need_reval)
status = d_revalidate(dentry, nd->flags);
if (unlikely(status <= 0)) {
if (status < 0) {
dput(dentry);
return status;
}
d_invalidate(dentry);
dput(dentry);
goto need_lookup;
}
if (unlikely(d_is_negative(dentry))) {
dput(dentry);
return - ENOENT;
}
path->mnt = mnt;
path->dentry = dentry;
// 处理按照某种方式管理的目录(自动挂载工具 autofs 管理这个目录的跳转,挂载点或自动挂载点。
err = follow_managed(path, nd);
if (likely(!err))
*inode = d_backing_inode(path->dentry);
return err;
need_lookup:
return 1;
}
首先调用 __d_lookup_rcu 在内存中的某个散列表里通过字符串比较查找目标 dentry,如果找到了就返回该 dentry;如果没找到就需要跳转到 unlazy 标号处,在这里会使用 unlazy_walk 就地将查找模式切换到 ref-walk,如果还不行就只好返回到 do_filp_open 从头来)。
如果顺利找到了目标 dentry 则还需要进行一系列的检查确保在我们做读取操作的期间没有人对这些结构进行改动。然后就是更新临时变量 path,为啥不更新 nd 呢?别忘了 nd 是很有脾气的,挂载点和符号链接人家都看不上,非真正目录不嫁。而这个时候还不知道这个目标是不是一个挂载点,如果是挂载点则还需要沿着被挂载的 mount 结构走到真正的目标上;退一步来说,就算这个目标不是挂载点,但它要是具备自动挂载特性呢;再退一步来说,它是不是符号链接我们也不知道,所以现在先不忙着更新 nd。紧接着就通过 __follow_mount_rcu 跨过挂载点这些“伪目标”,这个函数和上一篇里 follow_dotdot_rcu 的第二部分很相似我们就不深入进去了,有兴趣的同学结合代码自己研究一下就好了。
/*
* Try to skip to top of mountpoint pile in rcuwalk mode. Fail if
* we meet a managed dentry that would need blocking.
*/
static bool __follow_mount_rcu(struct nameidata * nd, struct path * path,
struct inode * *inode, unsigned * seqp)
{
// 和 follow_dotdot_rcu 一样开始死循环。
for (; ; ) {
struct mount * mounted;
/*
* Don't forget we might have a non-mountpoint managed dentry
* that wants to block transit.
*/
// 是否设置了 DCACHE_MANAGE_TRANSIT 标志,如果设置了,则调用 dentry 的 d_manage
// 函数来托管这个 dentry 的处理。
switch (managed_dentry_rcu(path->dentry))
{
// 如果调用者的路径查找处于 RCU 模式。这种模式下是不允许睡眠,所以
// 调用者被要求离开该函数并且返回 `-ECHILD`
case - ECHILD:
default:
return false;
// d_manage 函数返回 `-EISDIR` 告诉当前路径查找忽略 `d_automount` 或者其他任何挂载。
case - EISDIR:
return true;
//返回 0表示让挂起的客户端继续执行
case 0:
break;
}
if (!d_mountpoint(path->dentry))
return ! (path->dentry->d_flags & DCACHE_NEED_AUTOMOUNT);
mounted = __lookup_mnt(path->mnt, path->dentry);
if (!mounted)
break;
path->mnt = &mounted->mnt;
path->dentry = mounted->mnt.mnt_root;
nd->flags |= LOOKUP_JUMPED;
*seqp = read_seqcount_begin(&path->dentry->d_seq);
/*
* Update the inode too. We don't need to re-check the
* dentry sequence number here after this d_inode read,
* because a mount-point is always pinned.
*/
*inode = path->dentry->d_inode;
}
return ! read_seqretry(&mount_lock, nd->m_seq) && ! (path->dentry->d_flags & DCACHE_NEED_AUTOMOUNT);
}
如果一切顺利返回 0,请参考上面 walk_component 的代码,如果返回 0 就表示在 rcu-walk 模式下是不会启动 lookup_slow 的。
static int lookup_fast(struct nameidata * nd,
struct path * path, struct inode * *inode,
unsigned * seqp)
{
...
//跑到这里表示需要切换到 ref-walk 模式进行查找。
unlazy:
if (unlazy_walk(nd, dentry, seq))
return - ECHILD;
}
else {
dentry = __d_lookup(parent, &nd->last);
}
// 如果还是没有找到 dentry,表示内存中还没有读入这个目标,那么返回 1 。
// 接着在 walk_component 函数中进行 lookup_slow。
if (unlikely(!dentry))
goto need_lookup;
if (unlikely(dentry->d_flags & DCACHE_OP_REVALIDATE) && need_reval)
status = d_revalidate(dentry, nd->flags);
if (unlikely(status <= 0)) {
if (status < 0) {
dput(dentry);
return status;
}
d_invalidate(dentry);
dput(dentry);
goto need_lookup;
}
if (unlikely(d_is_negative(dentry))) {
dput(dentry);
return - ENOENT;
}
path->mnt = mnt;
path->dentry = dentry;
// 处理按照某种方式管理的目录(自动挂载工具 autofs 管理这个目录的跳转,
// 挂载点或自动挂载点)。
err = follow_managed(path, nd);
if (likely(!err))
*inode = d_backing_inode(path->dentry);
return err;
need_lookup:
return 1;
}
结合 walk_component 的代码来看,我们发现只有在 lookup_fast 返回值大于 0 的时候才会启动 lookup_slow,而在 lookup_fast 里面我们看到只有一种情况返回值会大于 0,那就是 dentry 为 NULL 的情况下会返回 1。也就是说启动 lookup_slow 的先决条件就是内存中还没有读入这个目标。接下来的代码已经切换到了 ref-walk 模式中,但其处理方式和 rcu-walk 差不多,结合 rcu-walk 部分的讲解自己研究一下吧。需要提一句的就是 follow_managed,这个函数会检查当前 dentry 是否是个挂载点,如果是就跟下去(的确和 rcu-walk 差不多,是吧),不过这个函数还会检查另外两个特性 DCACHE_MANAGE_TRANSIT 和 DCACHE_NEED_AUTOMOUNT,可以参考链接:
Linux虚拟文件系统
Linux路径查找
接下来看看 look_show 是如何工作的,代码如下:
/* Fast lookup failed, do it the slow way */
static int lookup_slow(struct nameidata * nd, struct path * path)
{
struct dentry * dentry, *parent;
parent = nd->path.dentry;
BUG_ON(nd->inode != parent->d_inode);
mutex_lock(&parent->d_inode->i_mutex);
dentry = __lookup_hash(&nd->last, parent, nd->flags);
mutex_unlock(&parent->d_inode->i_mutex);
if (IS_ERR(dentry))
return PTR_ERR(dentry);
path->mnt = nd->path.mnt;
path->dentry = dentry;
return follow_managed(path, nd);
}
看到这里大家就一定会明白为什么是 slow 了,互斥锁(mutex)是有可能引起进程阻塞的,而在 lookup_fast 里面没有使用任何可能导致进程睡眠的操作,这将导致 lookup_slow 的效率远远低于 lookup_fast。还不仅仅如此,我们继续看看 __lookup_hash:
static struct dentry * __lookup_hash(struct qstr * name,
struct dentry * base, unsigned int flags) {
bool need_lookup;
struct dentry * dentry;
dentry = lookup_dcache(name, base, flags, &need_lookup);
if (!need_lookup)
return dentry;
return lookup_real(base->d_inode, dentry, flags);
}
/*
* This looks up the name in dcache, possibly revalidates the old dentry and
* allocates a new one if not found or not valid. In the need_lookup argument
* returns whether i_op->lookup is necessary.
* 在 decache 中查找 name 对应的 dentry。可能需要验证这个“老”的 dentry,如果没有发现或者这个
* “老”的 dentry 已经无效了,那么需要分配一个新的 dentry。通过参数 need_lookup 来决定是否需要
* 调用 i_op->lookup。
*
* dir->d_inode->i_mutex must be held
*/
static struct dentry * lookup_dcache(struct qstr * name, struct dentry * dir,
unsigned int flags, bool * need_lookup) {
struct dentry * dentry;
int error;
*need_lookup = false;
dentry = d_lookup(dir, name);
// 如果在 decahe 中找到 dentry。
if (dentry) {
// 是否需要重新验证。
if (dentry->d_flags & DCACHE_OP_REVALIDATE) {
error = d_revalidate(dentry, flags);
if (unlikely(error <= 0)) {
if (error < 0) {
dput(dentry);
return ERR_PTR(error);
}
else {
d_invalidate(dentry);
dput(dentry);
dentry = NULL;
}
}
}
}
if (!dentry) {
// 分配一个 dentry,这里只是分配了内存,还没有绑定 inode,
// 所以该 dentry 为 negative dentry。
dentry = d_alloc(dir, name);
if (unlikely(!dentry))
return ERR_PTR(-ENOMEM);
// need_lookup 设置为 true 之后将会调用 lookup_real。
*need_lookup = true;
}
return dentry;
}
/*
* Call i_op->lookup on the dentry. The dentry must be negative and
* unhashed.
*
* dir->d_inode->i_mutex must be held
*/
static struct dentry * lookup_real(struct inode * dir, struct dentry * dentry,
unsigned int flags) {
struct dentry * old;
/* Don't create child dentry for a dead directory. */
if (unlikely(IS_DEADDIR(dir))) {
dput(dentry);
return ERR_PTR(-ENOENT);
}
old = dir->i_op->lookup(dir, dentry, flags);
if (unlikely(old)) {
dput(dentry);
dentry = old;
}
return dentry;
}
lookup: called when the VFS needs to look up an inode in a parent directory. The name to look for is found in the dentry. This method must call d_add() to insert the found inode into the dentry. The "i_count" field in the inode structure should be incremented. If the named inode does not exist a NULL inode should be inserted into the dentry (this is called a negative dentry). Returning an error code from this routine must only be done on a real error, otherwise creating inodes with system calls like create(2), mknod(2), mkdir(2) and so on will fail. If you wish to overload the dentry methods then you should initialise the "d_dop" field in the dentry; this is a pointer to a struct "dentry_operations". This method is called with the directory inode semaphore held
lookup:当 VFS 需要在父目录中查找 inode 时调用。从 dentry 中获取需要查找的名称。该方法必须调用 d_add() 将发现的 inode 插入到 dentry 中。在 inode 结构中,“i_count” 字段应该递增。如果命名的 inode 不存在,一个 NULL 的 inode应该插入到 dentry (这称为 negative dentry)。必须只在一个真正的错误发生时这个子程序才返回一个错误代码,否则就会用系统调用来创建 inodes, 比如 create(2)、mknod(2)、mkdir(2) 等等。如果您希望重载该 dentry 方法,那么您应该在 dentry 中初始化 “d_dop” 字段;这是一个指向 struct “dentry_operation” 的指针。该方法的调用需要获取该目录的 inode 信号量(i_lock)。
请先看 dentry = lookup_dcache(name, base, flags, &need_lookup);,大家可能会奇怪:不是在内存中没找到才进来的吗,怎么这里又去内存中找一遍?别忘了,上一级函数使用了互斥锁,这将有可能导致进程睡眠,也就有可能恰好有人在我们睡觉的时候这个目标加载进了内存,所以这里需要检查一下,而且反正是在内存中查找,不会太费事的。要是真找到了呢,那就撞大运了,高高兴兴的返回吧,要还是没有就只好自己动手丰衣足食老老实实的启动 lookup_real ,从真正的文件系统上读取吧。lookup_real 我们就不深入进去了,在里面主要是调用了具体文件系统自己的 lookup 函数去完成工作,而这些函数很有可能会启动文件系统所在设备的驱动程序,从真正的设备上读取(例如硬盘)数据,所以就更慢了,这才是名副其实的 “lookup_slow”。lookup_slow 剩下的工作和 fast 差不多,这里就不重复了。接着看 walk_component 函数:
static int walk_component(struct nameidata * nd, int flags)
{
...
//这种情况处于解析链接最后一个分量,释放当前已解析完的符号链接。
if (flags & WALK_PUT)
put_link(nd);
// 符号链接处理。
err = should_follow_link(nd, &path, flags & WALK_GET, inode, seq);
if (unlikely(err))
return err;
// 到这一步可以真正地更新 nd 结构了。
path_to_nameidata(&path, nd);
nd->inode = inode;
nd->seq = seq;
return 0;
out_path_put:
path_to_nameidata(&path, nd);
return err;
}
当走到这里的时候 nd 还是指向父级目录,但 path 已经指向子目录项了,这时只需确定该目录项是一个正常的目录,就可以更新 nd 然后继续下一个子目录项(path_to_nameidata)。但如果真是一个符号链接呢?在 should_follow_link 函数中需要先切换到 ref-walk 模式,然后返回 1,让 link_path_walk 接着处理这个符号链接。问题来了,为什么要切换到 ref-walk 模式呢?这是因为在处理符号链接的时候需要调用具体文件系统自己的处理函数,而在这些函数里很有可能会因为申请系统资源导致的进程阻塞,我们知道 rcu-walk 期间是禁止阻塞的,所以在这里需要先退出 rcu-walk 模式,因为 rcu-walk 模式是不允许睡眠或者阻塞。
下一篇解释符号链接处理流程。
