

前言
由于不可抗逆之因素,在金九银十的后半段开始求职。 面试的确可以驱动学习,驱动知识的归类整理。 以此文记录面试过程中遇到的题目,仅供分享,不喜勿喷。
js
js 事件循环
简述js事件循环?
简答:
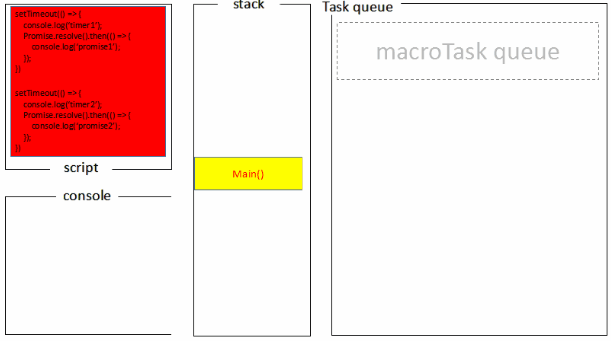
首先,由于js是单线程,所有任务需要排队。又为了避免因IO慢等原因导致的阻塞,任务被分成了“同步任务sync”和“异步任务async”。
其次,
1.同步任务都在主线程上执行,形成一个“执行栈”(后进先出)。
2.主线程之外,还存在一个“任务队列”(先进先出)。异步任务有了运行结果后,就会将回调函数放置在任务队列中。
3.一旦调用栈清空,就会读取“任务队列”的回调函数到栈内等待主线程的执行
这是循环的三步骤。
然后,重点要说明的是,任务队列分为宏任务队列和微任务队列,
每当调用栈清空的时候,先去读取微任务队列的所有微任务(例:Promise.then),再去读取宏任务队列的宏任务(例:setTimeout)。
每执行完一个宏任务后,都需检查微任务队列是否为空,如果为空,则执行下一个宏任务,否则,将会先把微任务队列的微任务全部读取执行完。
宏任务:script,setTimeout,setImmediate,promise中的executor
微任务:promise.then,process.nextTick
进一步: 个人理解QAQ
去食堂打饭,只排了一队,窗口的阿姨问你要什么啊?
1.如果你只要一个叉烧和烧鸭的双拼饭(已经做好了放在窗口),阿姨直接打好饭递给了你,然后下一个;
2.如果你要腊肉炒饭(需要现场炒),阿姨会把这个需求告诉专门做炒饭的阿叔,然后让你在旁边等,不要影响下一位同学打饭;
3.阿叔把饭炒好了,递给了阿姨,阿姨此时正在给另外一个同学打双拼,她也会先把手上的双拼打完递给那位同学,才会把腊肉炒饭递给你;
4.但是辛苦的阿叔除了做炒饭之外呢,还需要做手抓饼。如果你不幸因为打赌输了需要帮傻_b舍友带一个或几个手抓饼。善良的阿叔会在炒完你的饭之后把手抓饼也一起给做了,再去做下一份炒饭。
这个场景里,打饭的队伍是“主线程”执行栈,打双拼饭是“同步任务”,做炒饭、做手抓饼是“异步任务”,做好的炒饭是“宏任务”,做好的手抓饼是“微任务”;
参考链接:
Tasks, microtasks, queues and schedules
推荐阅读:
js 原生手写
要求手写!(部分人(也就是我)从jquery开始写页面,再到用vue,往往会不重视或者已经忘记原生怎么写的了)
示例:
- document.querySelector("h2, h3").style.backgroundColor = "red";
- document.getElementById("demo");
- document.getElementsByTagName("P"); ......
参考链接:
js 原型链
简答:
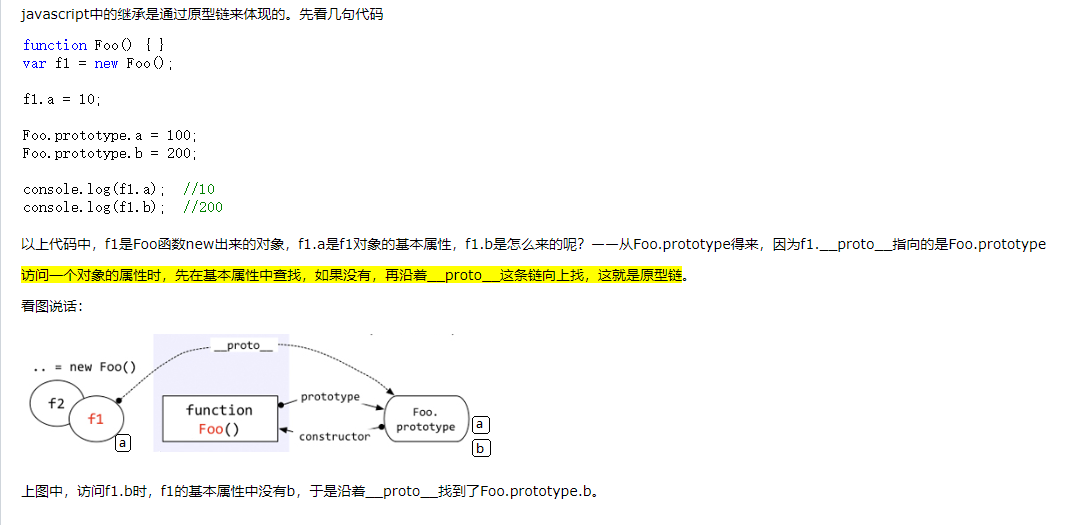
为了实现“继承”这个常用面向对象语言中最基本的概念,javaScript 基于原型链做出了实现。
访问一个对象的属性时,先在基本属性中查找,如果没有,在沿着隐式原型_proto_这条链向上找
(因为obj._proto_===obj.constructor.prototype,对象的隐式原型_proto_等于构造这个对象的函数的显示原型prototype)
进一步:
1.object instanceof constructor ,instanceof 运算符用来检测 constructor.prototype 是否存在于参数 object 的原型链上
2.基本类型(Undefined、Null、Boolean、Number 和 String)、引用类型(Object、Array 和 Function)
3.一切(引用类型)都是对象,对象是属性的集合Object本质上是由一组无序的名值对组成的
4.对象都是通过函数创建的
5.每个函数function都有一个prototype,即原型。每个对象都有一个__proto__,可成为隐式原型,指向创建该对象的函数的prototype(这句话不理解,请先背下来)
Function.prototype.__proto__ === Object.prototype
obj.__proto__=== Object.prototype //Object.prototype
确是一个特例——它的__proto__指向的是null,切记切记!
几乎所有 JavaScript 中的对象都是位于原型链顶端的 Object 的实例。
参考链接:
闭包原理
简答:
闭包是函数和声明该函数的词法环境的组合。- MDN
在这样的词法环境下,阻止变量回收机制对变量的回收,可以访问函数内部作用域的变量。
function init() {
var name = "Mozilla"; // name 是一个被 init 创建的局部变量
function displayName() { // displayName() 是内部函数,一个闭包
alert(name); // 使用了父函数中声明的变量
}
displayName();
}
init();
进一步
- 回收机制
function a(){
var i=0;
function b(){
alert(++i);
}
return b;
}
var c=a();
c();
在Javascript中,如果一个对象不再被引用,那么这个对象就会被GC回收。如果两个对象互相引用,而不再被第3者所引用,那么这两个互相引用的对象也会被回收。因为函数a被b引用,b又被a外的c引用,这就是为什么函数a执行后不会被回收的原因。(来源:百科)
- 闭包优劣
优:
① 可以读取函数内部的变量
② 让这些变量的值始终保持在内存中,不会在f1调用后被自动清除。
劣:
① 使得函数中的变量都被保存在内存中,内存消耗很大,所以不能滥用闭包,否则会造成网页的性能问题。
实际遇到
let r=[]
for (let i=0;i<5;i++) {
let index=i+1
let res_all=vm.$apid.allService(100,1,index).then((val)=>{//allService(100,1,1) size,current,serviceType
let res=val.data.data.records
r[i] = res.map(item => {
return {
name: item.serviceName,
key: item.serviceId,
icon: vm.$store.state.myBaseUrl+vm.$store.state.devUrl+item.imgUrl,
cat: index
}
})
console.log(r)
})
}//循环请求异步问题
参考链接:
推荐阅读:
特注:闭包、作用域、原型链、js数据类型,将在学习过程中的某一个点融合在一起,这是js的“最基本”!
addEventListener 循环绑定
面试题:addEventListener 循环绑定,如何改进下面的代码能正确实现?有几种方法?
<a>1</a><a>2</a><a>3</a>
var elems = document.getElementsByTagName('a');
for (var i = 0; i < elems.length; i++) {
elems[i].addEventListener('click', function (e) {
e.preventDefault();
alert('I am link #' + i);
}, 'false');
};
// 这个代码是错误的,因为变量i从来就没被locked住
// 相反,当循环执行以后,我们在点击的时候i才获得数值
// 因为这个时候i操真正获得值
// 所以说无论点击那个连接,最终显示的都是I am link #3(如果有3个a元素的话)
解决1:用闭包解决
var elems = document.getElementsByTagName('a');
for (var i = 0; i < elems.length; i++) {
elems[i].addEventListener('click', (function (num) {
return function(e){
e.preventDefault();
alert('I am link #' + num);
}
})(i), 'false');
};
//因为i相对匿名函数是外面的变量,就把循环绑定的时候,将i的值传入到匿名函数内,
就可以了。因此需要在匿名函数(事件函数)外包裹一个匿名函数, 并立即执行。
解决2:把var换成let
var elems = document.getElementsByTagName('a');
for (let i = 0; i < elems.length; i++) {
elems[i].addEventListener('click', function (e) {
e.preventDefault();
alert('I am link #' + i);
}, 'false');
};
//var 命令的变量提升机制,var 命令实际只会执行一次。
//而 let 命令不存在变量提升,所以每次循环都会执行一次,声明一个新变量(但初始化的值不一样)。
//for 的每次循环都是不同的块级作用域,
//let 声明的变量是块级作用域的,所以也不存在重复声明的问题。
let生命变量的for循环里,每个匿名函数实际上引用的都是一个新的变量
解决3:没用到闭包解决
var elems = document.getElementsByTagName('a');
for (var i = 0; i < elems.length; i++) {
elems[i].num = i;
elems[i].addEventListener('click', function (e) {
e.preventDefault();
alert('I am link #' + this.num);
}, 'false');
};
参考文献:
变量提升
面试题:
(function(){
console.log(a)//undefined
var a=1;
})()
(function(){
console.log(a)//报错: Cannot access 'a' before initialization
let a=1;
})()
(function(){
{let a=1}
console.log(a)//报错:a is not defined
})()
简答:
js 有变量提升和函数提升,指的是用 var声明变量 或用 function 函数名(){ } 声明的,会在 js预解析 阶段提升到顶端;(es6的let 和 const 不会提升)其次,函数提升优先级 高于 变量提升
webpack
webpack 打包原理
简答:
官网:
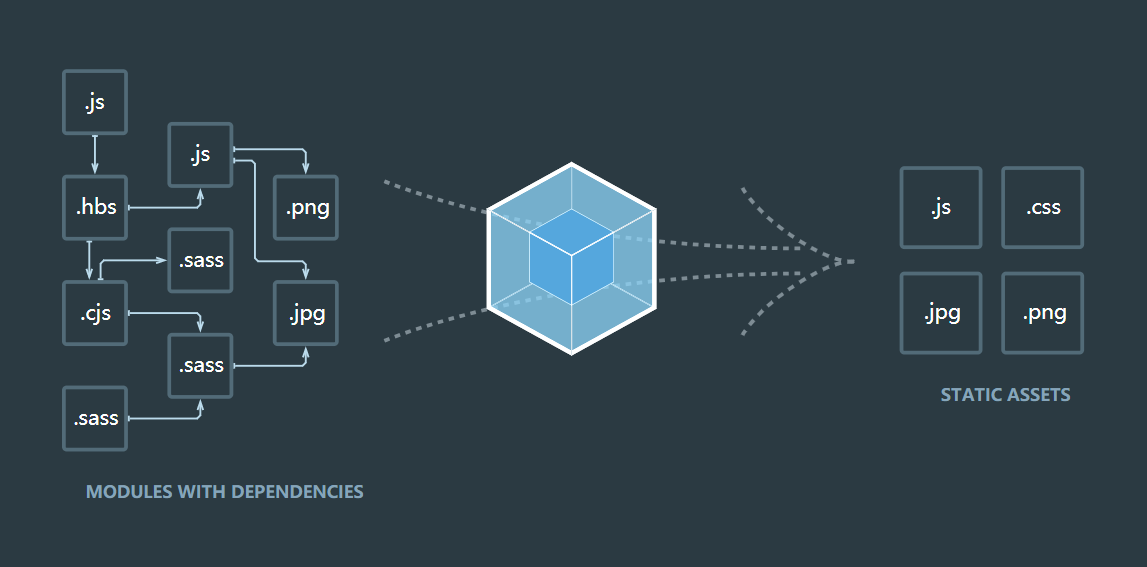
本质上,Webpack 是一个现代 JavaScript 应用程序的静态模块打包器(module bundler)。
当 Webpack 处理应用程序时,它会递归地构建一个依赖关系图(dependency graph),其中包含应用程序需要的每个模块,然后将所有这些模块打包成一个或多个 bundle
记忆点:静态模块打包器、依赖关系图、bundle
从前端工程化角度看(“前端工程化”是加分项):
Webpack等类似工具是前端工程化工具。前端工程化是把前端开发工作带入到更加系统和规范体系的一系列过程。这个过程会包括源代码的预编译、模块处理、代码压缩等构建方面的工作。
Webpack的“一切皆模块”以及“按需加载”两大特性使得它更好地服务于工程化。
记忆点:预编译、代码压缩、模块处理、、按需加载
进一步:
Webpack 主要在打包中处理了下面这些问题:
1.从入口文件开始分析整个应用的依赖树
2.将每个依赖模块包装起来,并放到一个数组中等待调用
3.实现模块加载的方法,并提供到模块执行的环境中,使得模块间可以互相调用
4.将执行入口文件的逻辑放在一个立即执行函数表达式中
- e.g. webpack.config.js
module.exports = {
// 配置打包选项 development开发环境
mode: 'development', // production 生产环境
// 指定入口文件:要打包的文件
entry: './src/js/index.js',
// 指定输出文件:打包之后的文件
output: {
path: path.resolve(__dirname, 'dist'),
filename: 'main.min.js'
},
// 配置资源的加载器 loader
module: {
rules: [
// 配置js的加载器(把ES6转化为ES3/5代码)
{
test: /\.jsx?$/,
loader: 'babel-loader',
//打包除这个文件之外的文件
exclude: path.join(__dirname, './node_modules'),
//打包包括的文件
include: path.join(__dirname, './src')
},
// 配置css的加载器
{
// 匹配.css结尾的文件
test: /\.css$/,
// 配置css文件的加载器,处理顺序:从右向左
use: ['style-loader', 'css-loader']
},
// 配置less的加载器
{
test: /\.less$/,
use: ['style-loader', 'css-loader', 'less-loader']
}
]
},
// 配置插件
plugins: [
new CleanWebpackPlugin(),
// 动态生成html
new HtmlWebpackPlugin({
title: '测试标题',
template: 'index.html'
})
],
// 配置实时预览环境
devServer: {
contentBase: path.join(__dirname, 'dist'),
port: 5000
}
}
参考链接:
推荐阅读:
webpack 配置多页面应用
简答:
用webpack构建多页应用可以有2种思路,
1.多页面单配置。主要把entry和plugins中的html-webpack-plugin进行改造即可。
2.多页面多配置。多页面单配置的优点在于,不同页面可以共享相同代码,容易实现长缓存。缺点主要是随着项目的日渐庞大,打包速度会有明显下降。
e.g. 多entry,修改plugin
var webpack = require('webpack');
const path = require('path')
const HtmlWebpackPlugin = require('html-webpack-plugin');
const ExtractTextPlugin = require("extract-text-webpack-plugin");
const CleanWebpackPlugin = require('clean-webpack-plugin');
module.exports = {
// 配置入口
entry: {
about: './src/pages/about/about.js',
contact: './src/pages/contact/contact.js'
},
// 配置出口
output: {
path: __dirname + "/dist/",
filename: 'js/[name]-[hash:5].js',
publicPath: '/',
},
module: {
loaders: [
//解析.js
{
test: '/\.js$/',
loader: 'babel',
exclude: path.resolve(__dirname, 'node_modules'),
include: path.resolve(__dirname, 'src'),
query: {
presets: ['env']
}
},
// css处理
{
test: /\.css$/,
loader: 'style-loader!css-loader'
},
// less处理
{
test: /\.less$/,
loader: 'style-loader!css-loader!less-loader'
},
// 图片处理
{
test: /\.(png|jpg|gif|svg)$/,
loader: 'file-loader',
query: {
name: 'assets/[name]-[hash:5].[ext]'
},
},{
test: /\.(htm|html)$/i,
use:[ 'html-withimg-loader']
}
]
},
plugins: [
new ExtractTextPlugin(__dirname + '/assert/css/common.less'),
// minify:{
// removeComments: true,//删除注释
// collapseWhitespace:true//删除空格
// }
new HtmlWebpackPlugin({
filename: __dirname + '/dist/about.html',
inject: 'head',
template: 'html-withimg-loader!'+__dirname + "/src/pages/about/about.html",
chunks: ['about'],
inlineSource: '.(js|css)$'
}),
new HtmlWebpackPlugin({
inject: 'head',
filename: __dirname + '/dist/contact.html',
template: __dirname + "/src/pages/contact/contact.html",
chunks: ['contact'],
inlineSource: '.(js|css)$'
}),
//设置每一次build之前先删除dist
new CleanWebpackPlugin(
['dist/*', 'dist/*',],  //匹配删除的文件
{
root: __dirname,           //根目录
verbose: true,           //开启在控制台输出信息
dry: false           //启用删除文件
}
)
],
// 起本地服务,我起的dist目录
devServer: {
contentBase: "./dist/",
historyApiFallback: true,
inline: true,
hot: true,
host: '192.168.1.107',//我的局域网ip
}
}
进一步: 单页面应用与多页面应用的区别
| 单页面应用(SinglePage Web Application,SPA) | 多页面应用(MultiPage Application,MPA) | |
|---|---|---|
| 组成 | 一个外壳页面和多个页面片段组成 | 多个完整页面构成 |
| 资源共用(css,js) | 共用,只需在外壳部分加载 | 不共用,每个页面都需要加载 |
| 刷新方式 | 页面局部刷新或更改 | 整页刷新 |
| url 模式 | a.com/#/pageone a.com/#/pagetwo |
a.com/pageone.html a.com/pagetwo.html |
| 用户体验 | 页面片段间的切换快,用户体验良好 | 页面切换加载缓慢,流畅度不够,用户体验比较差 |
| 转场动画 | 容易实现 | 无法实现 |
| 数据传递 | 容易 | 依赖 url传参、或者cookie 、localStorage等 |
| 搜索引擎优化(SEO) | 需要单独方案、实现较为困难、不利于SEO检索 可利用服务器端渲染(SSR)优化 | 实现方法简易 |
| 试用范围 | 高要求的体验度、追求界面流畅的应用 | 适用于追求高度支持搜索引擎的应用 |
| 开发成本 | 较高,常需借助专业的框架 | 较低 ,但页面重复代码多 |
| 维护成本 | 相对容易 | 相对复杂 |
参考链接:
vue
双向绑定原理
简答:
Vue内部通过Object.defineProperty方法属性拦截的方式,把data对象里每个数据的读写转化成getter/setter,当数据变化时通知视图更新。
具体说一下Object.defineProperty:
Object.defineProperty() 方法会直接在一个对象上定义一个新属性,或者修改一个对象的现有属性, 并返回这个对象。
Object.defineProperty(obj, prop, descriptor)
obj:要在其上定义属性的对象。
prop:要定义或修改的属性的名称。
descriptor:将被定义或修改的属性描述符。
进一步:
Object.defineProperty()具体实现:
//这段代码太重要了,请记住!
let hr={
skill:'',
experience:''
}
Object.defineProperty(hr, 'skill', {
get(){
console.log('必备技能:')
return '不放鸽子'
},
set(newVal){
console.log('经验要求:')
}
})
//读:
console.log(hr.skill)
//写:
hr.skill='五年起步'
控制台打印
必备技能:
不放鸽子
经验要求:
"五年起步"
发布订阅模式
现在已经可以检测到数据的读和写,然后就需要通知视图的更新了.
这里是典型的发布订阅模式,在这个模式下:数据是发布者(Observer),依赖对象是订阅者(Watcher),他们需要一个中间人来传递,那就是订阅器(Dep)。
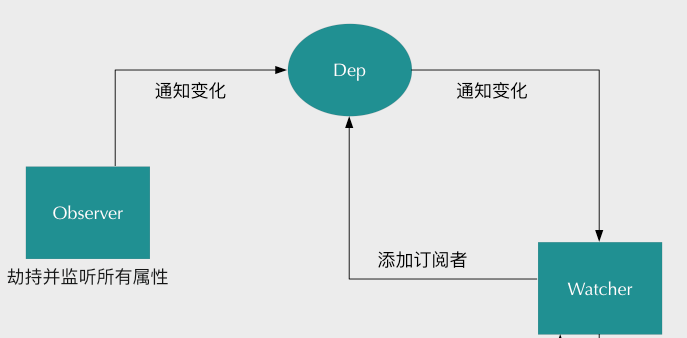
总结:实现数据的双向绑定,首先要对数据进行劫持监听,所以我们需要设置一个监听器Observer,用来监听所有属性。如果属性发生变化了,就需要告诉订阅者Watcher看是否需要更新。因为订阅者Watcher是有很多个,所以我们需要有一个消息订阅器Dep来专门收集这些订阅者,然后在监听器Observer和订阅者Watcher之间进行统一管理。
附:从这张生命周期图看数据和视图在何时双向更新
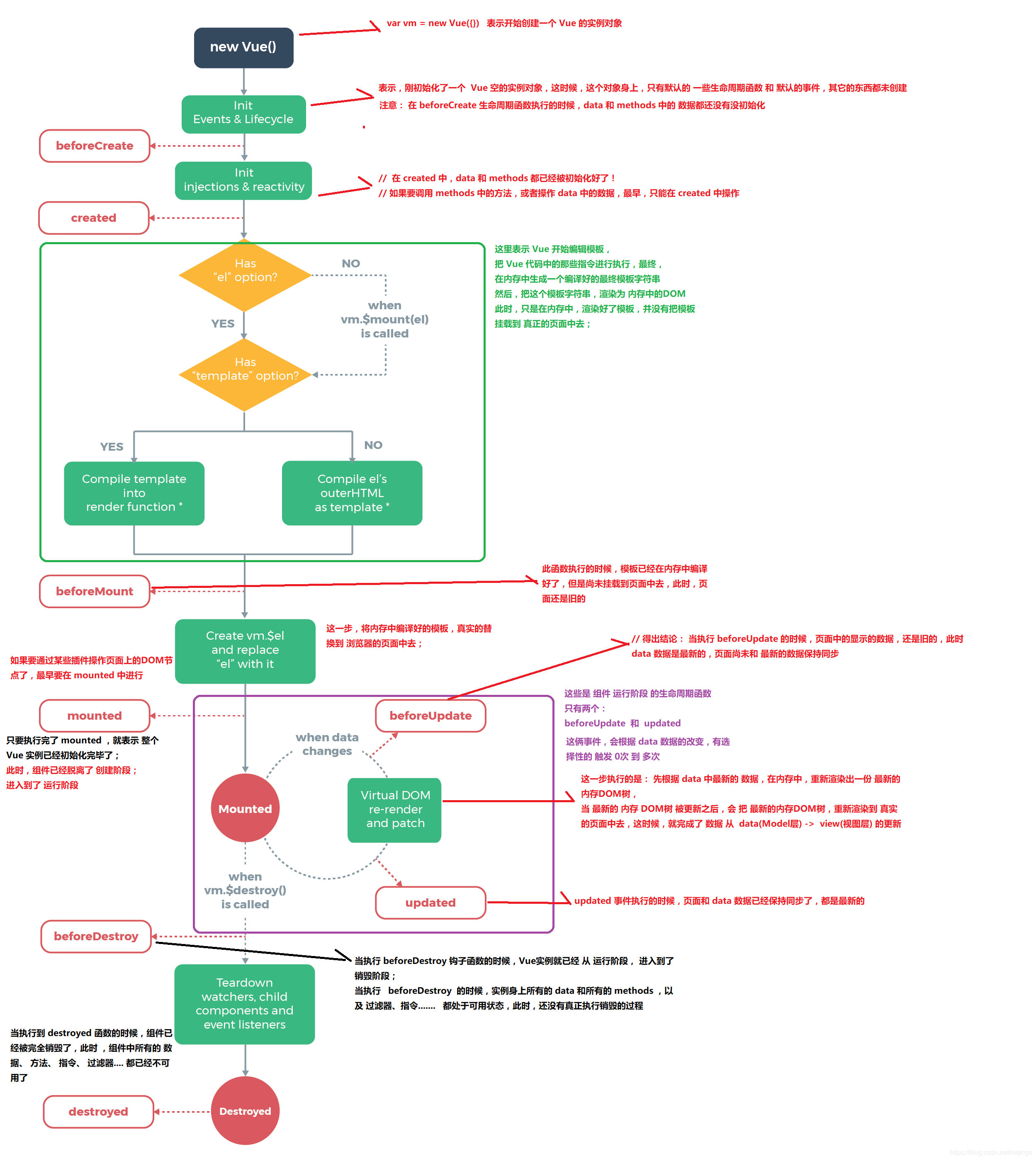
参考链接:
推荐阅读:
v-for key
简答:
-
在写v-for的时候,都需要给元素加上一个key属性
-
key的主要作用就是用来提高渲染性能的!
-
key属性可以避免数据混乱的情况出现 (如果元素中包含了有临时数据的元素,如果不用key就会产生数据混乱)
特注:
当 v-if 与 v-for 一起使用时,v-for 具有比 v-if 更高的优先级,这意味着 v-if 将分别重复运行于每个 v-for 循环中。 所以,不推荐v-if和v-for同时使用!
$nextTick
$nextTick 是在下次 DOM 更新循环结束之后执行延迟回调用,在修改数据之后使用nextTick,则可以在回调中获取更新后的
怎么理解:看下面这个例子就豁然开朗
DOM:
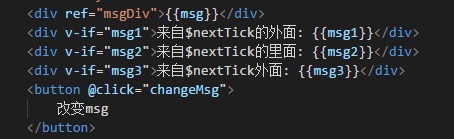
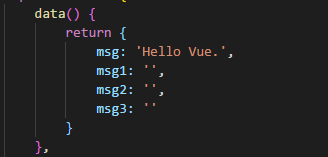
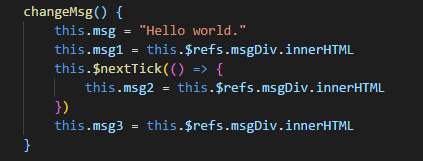
触发changeMsg后:

可以看到,msg已经变成了Hello world,在changeMsg()方法中,先修改msg的值成为‘Hello world’,然后通过拿到dom的值再依次修改msg1、msg2、msg3的值,此时修改得到的msg1依然是‘hello vue’,this.$nextTick中修改得到的msg2则是‘hello world’,msg3依然是‘hello vue’,也就是说,在changeMsg()方法触发后,修改了msg的值,但是此时再通过dom取到的值还未改变,所以可以知道:
vue响应式的改变一个值以后,此时的dom并不会立即更新,如果需要在数据改变以后立即通过dom做一些操作,可以使用$nextTick获得更新后的dom。
参考链接:
虚拟DOM
简答:
虚拟 DOM 的实现原理主要包括以下 3 部分:
用 JavaScript 对象模拟真实 DOM 树,对真实 DOM 进行抽象; diff 算法 — 比较两棵虚拟 DOM 树的差异; pach 算法 — 将两个虚拟 DOM 对象的差异应用到真正的 DOM 树。
推荐阅读
浏览器
浏览器缓存
简答:
浏览器的缓存是为了性能的优化,通过重复调用本地缓存,减少Http请求这样的方式,达到减少延迟、减少带宽、降低网络负荷的作用。
-
过程:浏览器发请求,访问缓存,无缓存结果,发起HTTP请求,返回结果和缓存,存放缓存
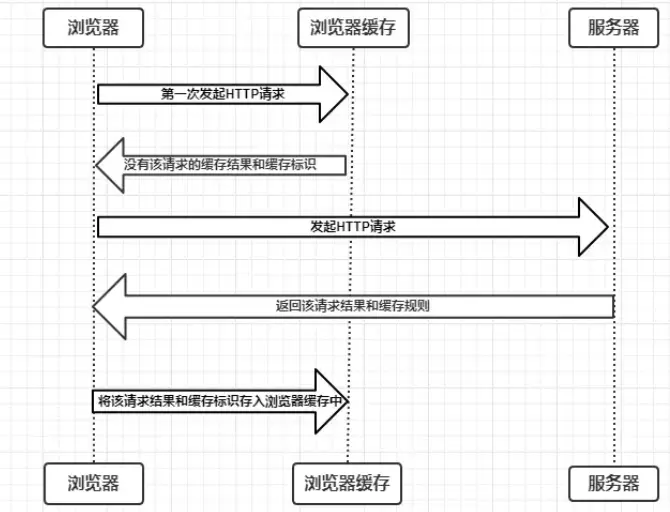
-
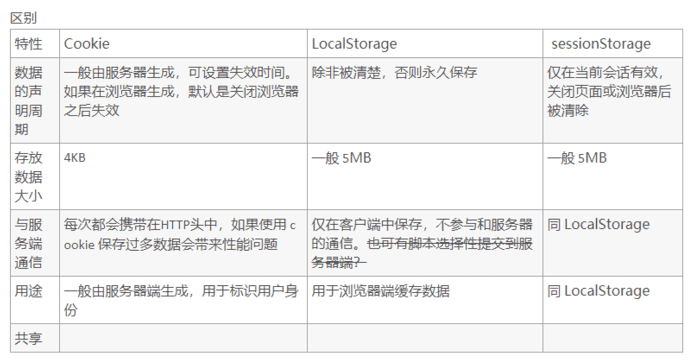
缓存类型有:cookie、LocalStorage、sessionStorage
进一步:
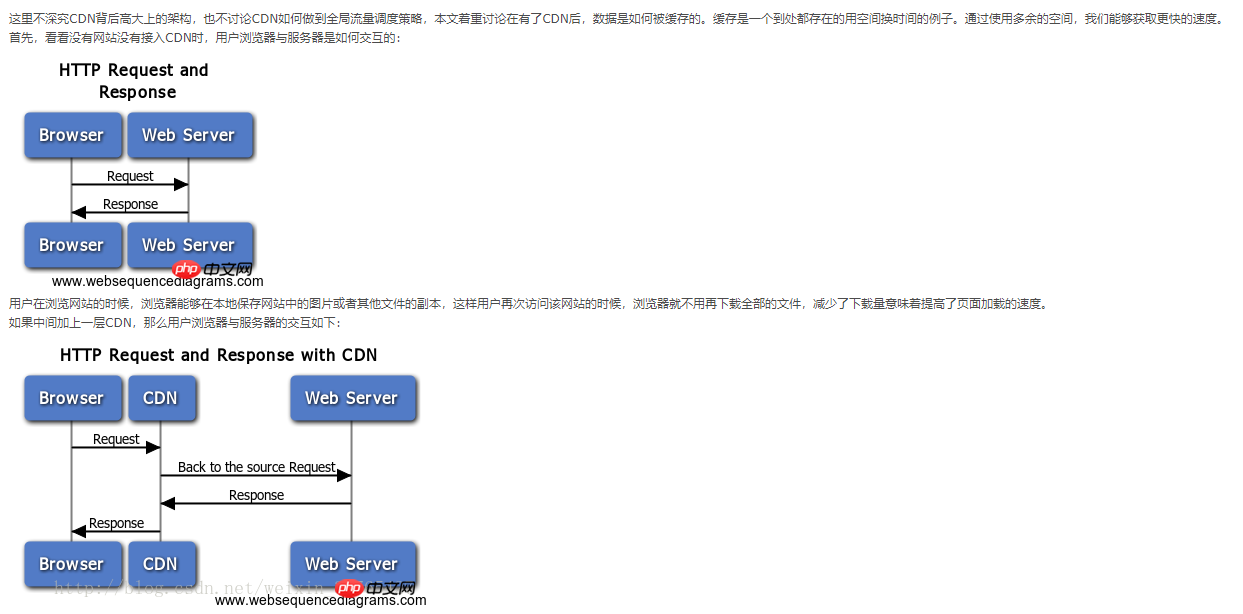
- CDN 缓存
客户端直接从源站点获取数据,当服务器访问量大时会影响访问速度,进而影响用户体验,且无法保证客户端与源站点间的距离足够短,适合传输数据。
CDN解决的正是如何将数据快速可靠地从源站点传递到客户端,通过CDN对数据的分发,用户可以从一个距离较近的服务器获取数据,而不是源站点,从而达到快速访问、且能减少源站点负载压力的目的。
参考链接:
从输入URL到页面加载发生了什么
简答:
1.DNS解析 2.TCP连接 3.发送HTTP请求 4.服务器处理请求并返回HTTP报文 5.浏览器解析渲染页面 6.连接结束
性能优化
简答:
优化方法,结合雅虎军规35条标准,可以大致分为这么6类(非严格,有按自己的理解整理):
| 分类名 | 内容 |
|---|---|
| 网络 | 1.减少请求大小和次数;2.减少DNS查找,避免重定向;3.是异步请求可缓存;4.预加载、延迟加载、按需加载;5.减少Dom数量等; |
| 服务 | 1.使用CDN;2.Gzip组件压缩;3.配置Etag;4.尽早刷新Buffer等; |
| 缓存 | 1.减小Cookie;2.CDN缓存; |
| CSS/JavaScript | 1.Css放上面,Js放下面,避免阻塞;2.压缩Css、Js;3.减少Dom访问操作;4.减少重绘,避免回流; |
| 图片 | 1.压缩图片;2.用iconfont;3.用雪碧图; |
| 其它 | 1.控制组件大小;2.使用预编译语言,打包成模块,按需加载; |
参考链接:
前端安全
简答:
xss: 跨站脚本攻击(Cross Site Scripting)是最常见和基本的攻击 WEB 网站方法,攻击者通过注入非法的 html 标签或者 javascript 代码,从而当用户浏览该网页时,控制用户浏览器。
csrf:跨站点请求伪造(Cross-Site Request Forgeries),也被称为 one-click attack 或者 session riding。冒充用户发起请求(在用户不知情的情况下), 完成一些违背用户意愿的事情(如修改用户信息,删初评论等)。
防范:同源检测、双重cookie检测等。
Css布局
布局方式
简答:
| 名称 | 内容 |
|---|---|
| 静态布局(static layout) | 不管浏览器尺寸具体是多少,网页布局始终按照最初写代码时的布局来显示。 |
| 流式布局(Liquid Layout) | 栅栏系统(网格系统):代表:bootstrap |
| 自适应布局(Adaptive Layout) | 屏幕分辨率变化时,页面里面元素的位置会变化而大小不会变化。 |
| 响应式布局(Responsive Layout) | 每个屏幕分辨率下面会有一个布局样式,即元素位置和大小都会变。 |
| 弹性布局(rem/em布局) | rem/em区别:rem是相对于html元素的font-size大小而言的,而em是相对于其父元素。 |
进一步: rem与px的转换
假设设计稿宽度为750px,查看750px宽度的页面对应的html{font-size:XXXpx}.
假设页面宽750px,html{font-size:100px},即100px=1rem。此时想要设置一个按钮的宽度,在设计稿中按钮为200px90px,那么转换之后的按钮即为2rem.9rem
html{//750的屏幕
font-size=10px;
/*font-size=62.5% //这里就是10/16x100%=62.5% 也就是默认10px的字号*/
}
@media screen and (min-width: 640px){
html{
font-size: ?;
}
}
问号里的值是多少?
解:
750/640=10/x
布局实例
需求: 只用css实现,一个div分上下两部分,上部分高度不固定,下面部分自动填满剩余高度
方法一:用flex 布局
.wrapper{
display:flex;
flex-direction: column; //竖轴方向
}
.body{
flex:auto; //自动铺满剩余空间
}
方法二:用绝对定位,然后在dom中增加一块高度占位的盒子
节流防抖
推荐阅读:
算法
手写二分法
要求手写!
function binary_search(arr,target) {
let min=0
let max=arr.length-1
while(min<=max){
let mid=Math.ceil((min+max)/2)
if(arr[mid]==target){
return mid
}else if(arr[mid]>target){
max=mid-1
}else if(arr[mid]<target){
min=mid+1
}
}
return "null"
}
console.log(binary_search([1,5,7,19,88],19))//3
冒泡排序
var arr=[10,20,50,100,40,200];
for(var i=0;i<arr.length-1;i++){
for(var j=0;j<arr.length-1-i;j++){
if(arr[j]>arr[j+1]){
var temp=arr[j]
arr[j]=arr[j+1]
arr[j+1]=temp
}
}
}
console.log(arr)
去重
1.不考虑Set()
2.不考虑双层for循环,性能太差
利用对象的属性不重复:
function distinct(arr) {
let result = []
let obj = {}
for (let i of arr) {
if (!obj[i]) {
result.push(i)
obj[i] = 1
}
}
return result
}
