

1.简介:
上篇文章咱们对Querydsl-JPA对了介绍以及基本讲解,下来咱们开始介绍一些平常咱们经常用的多表联查用Querydsl-JPA是如何实现的。
2.基础脚本:
2.1:用户信息表
-- Create table
create table USER_TMW
(
id VARCHAR2(32 CHAR) not null,
name VARCHAR2(32 CHAR),
age NUMBER(19,2),
money NUMBER(19,2),
begin_time VARCHAR2(32 CHAR),
end_time VARCHAR2(32 CHAR),
dept_id VARCHAR2(32 CHAR)
)
-- Create/Recreate primary, unique and foreign key constraints
alter table USER_TMW
add primary key (ID)
using index
tablespace UFGOV
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
insert into user_tmw (ID, NAME, AGE, MONEY, BEGIN_TIME, END_TIME, DEPT_ID)
values ('8a84a8b36bbbc8e1016bbbd803c60016', '老王', 20.00, 2000.00, '1567579914276', '1567579904276', 'C8477CE676B143E983260B45D05C06B3');
insert into user_tmw (ID, NAME, AGE, MONEY, BEGIN_TIME, END_TIME, DEPT_ID)
values ('0000000000000000000111', '小王', 30.00, 1500.00, '1567579924276', '1567579904276', 'C8477CE676B143E983260B45D05C06B3');
insert into user_tmw (ID, NAME, AGE, MONEY, BEGIN_TIME, END_TIME, DEPT_ID)
values ('0000000000000000000001', '王五', 18.00, 1800.00, '1567579934276', '1567579904276', '8a90959d6b88ce95016b8c547cfb03e7');
insert into user_tmw (ID, NAME, AGE, MONEY, BEGIN_TIME, END_TIME, DEPT_ID)
values ('0000000000000000000011', '小刚', 25.00, 1000.00, '1567579944276', '1567579904276', '8a90959d6b88ce95016b8c547cfb03e7');
insert into user_tmw (ID, NAME, AGE, MONEY, BEGIN_TIME, END_TIME, DEPT_ID)
values ('0000000000000000011111', '张三', 30.00, 2000.00, '1567579954276', '1567579904276', '8a90959d6b92c60e016b937f0d550080');
insert into user_tmw (ID, NAME, AGE, MONEY, BEGIN_TIME, END_TIME, DEPT_ID)
values ('0000000000000000000021', '李四', 30.00, 3000.00, '1567579964276', '1567579904276', '8a90959d6b92c60e016b937f0d550080');
2.2:部门信息表
-- Create table
create table DEPT_TMW
(
id VARCHAR2(32 CHAR) not null,
dept_name VARCHAR2(32 CHAR),
dept_no VARCHAR2(32 CHAR),
create_time VARCHAR2(32 CHAR),
p_dept_id VARCHAR2(32 CHAR)
)
-- Create/Recreate primary, unique and foreign key constraints
alter table DEPT_TMW
add primary key (ID)
using index
tablespace UFGOV
pctfree 10
initrans 2
maxtrans 255
storage
(
initial 64K
next 1M
minextents 1
maxextents unlimited
);
insert into dept_tmw (ID, DEPT_NAME, DEPT_NO, CREATE_TIME, P_DEPT_ID)
values ('C8477CE676B143E983260B45D05C06B3', '研发部门', 'N001', '1567579904276', null);
insert into dept_tmw (ID, DEPT_NAME, DEPT_NO, CREATE_TIME, P_DEPT_ID)
values ('8a90959d6b88ce95016b8c547cfb03e7', '测试部门', 'N002', '1567579804276', 'C8477CE676B143E983260B45D05C06B3');
insert into dept_tmw (ID, DEPT_NAME, DEPT_NO, CREATE_TIME, P_DEPT_ID)
values ('8a90959d6b92c60e016b937f0d550080', '运维部门', 'N003', '1567579704276', '8a90959d6b88ce95016b8c547cfb03e7');
3.Querydsl-JPA多表操作:
3.1:新增用户和部门的实体类
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
/**
* @ProjectName: queryDsl
* @Package: com.springboot.demo.bean
* @ClassName: Dept
* @Author: tianmengwei
* @Description:
* @Date: 2019/9/4 15:10
*/
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
@Table(name = "dept_tmw")
@JsonIgnoreProperties({"hibernateLazyInitializer", "handler"})
public class Dept {
@Id
@GeneratedValue(strategy = GenerationType.AUTO, generator = "custom-uuid")
@GenericGenerator(name = "custom-uuid", strategy = "com.springboot.demo.bean.CustomUUIDGenerator")
@Column(name = "id", nullable = false, length = 32)
private String id;
@Column(name = "dept_name")
private String deptName;
@Column(name = "dept_no")
private String deptNo;
@Column(name = "create_time")
private String createTime;
@Column(name = "p_dept_id")
private String pDeptId;
}
import com.fasterxml.jackson.annotation.JsonIgnoreProperties;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.hibernate.annotations.GenericGenerator;
import javax.persistence.*;
import java.math.BigDecimal;
/**
* @ProjectName: queryDsl
* @Package: com.springboot.demo
* @ClassName: User
* @Author: tianmengwei
* @Description:
* @Date: 2019/8/19 19:35
*/
@AllArgsConstructor
@NoArgsConstructor
@Data
@Entity
@Table(name = "user_tmw")
@JsonIgnoreProperties({"hibernateLazyInitializer", "handler"})
public class User {
@Id
@GeneratedValue(strategy = GenerationType.AUTO, generator = "custom-uuid")
@GenericGenerator(name = "custom-uuid", strategy = "com.springboot.demo.bean.CustomUUIDGenerator")
@Column(name = "id", nullable = false, length = 32)
private String id;
@Column(name = "name", length = 10)
private String name;
@Column(name = "age")
private Integer age;
@Column(name = "money")
private BigDecimal money;
@Column(name = "begin_time")
private String beginTime;
@Column(name = "end_time")
private String endTime;
@Column(name = "dept_id")
private String deptId;
}
3.2:多表关联查询 结果多字段拼接显示处理(concat())
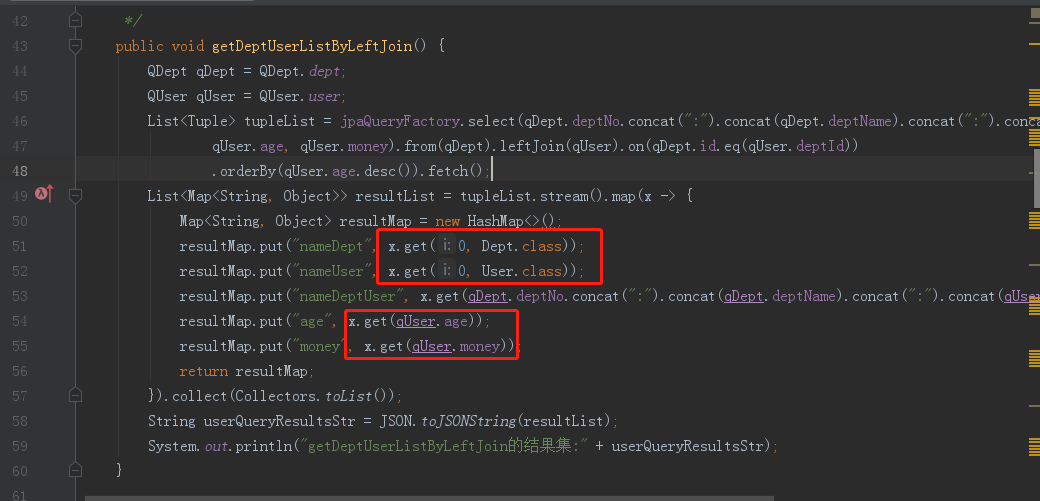
public void getDeptUserListByLeftJoin() {
QDept qDept = QDept.dept;
QUser qUser = QUser.user;
List<Tuple> tupleList = jpaQueryFactory.select(qDept.deptNo.concat(":").concat(qDept.deptName).concat(":").concat(qUser.name),
qUser.age, qUser.money).from(qDept).leftJoin(qUser).on(qDept.id.eq(qUser.deptId))
.orderBy(qUser.age.desc()).fetch();
List<Map<String, Object>> resultList = tupleList.stream().map(x -> {
Map<String, Object> resultMap = new HashMap<>();
resultMap.put("nameDept", x.get(0, Dept.class));
resultMap.put("nameUser", x.get(0, User.class));
resultMap.put("nameDeptUser", x.get(qDept.deptNo.concat(":").concat(qDept.deptName).concat(":").concat(qUser.name)));
resultMap.put("age", x.get(qUser.age));
resultMap.put("money", x.get(qUser.money));
return resultMap;
}).collect(Collectors.toList());
String userQueryResultsStr = JSON.toJSONString(resultList);
System.out.println("getDeptUserListByLeftJoin的结果集:" + userQueryResultsStr);
}
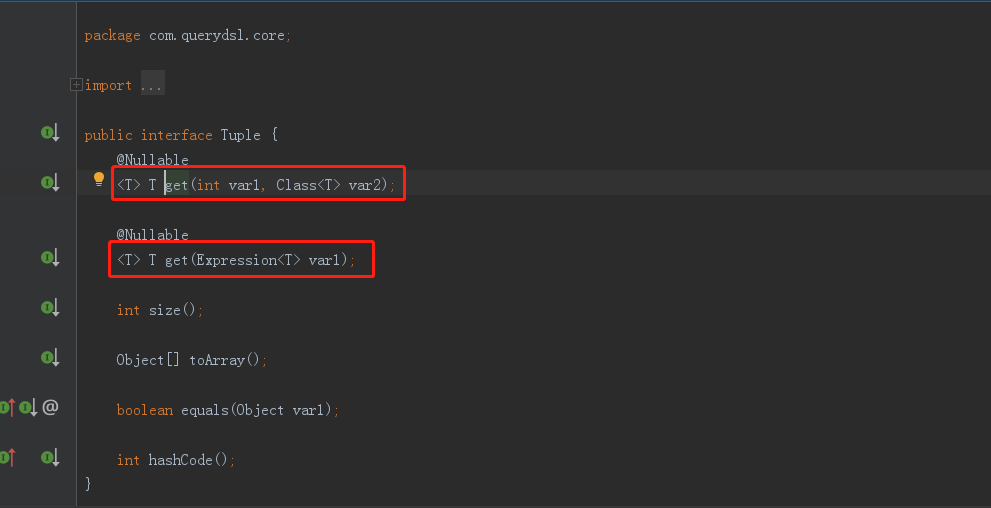
此处,我们在获取返回结果根据jpaFactory关联查询返回的类型是Tuple,Tuple提供了以下两种方式,可以根据下标和指定某个属性去获取:
3.3:关联查询结果 case when在querydsl中的使用
此处querydsl提供了CaseBuilder类,我们可以使用该类对字段的值做处理转换,当然我们呢也可以在用stream流的时候也进行处理;
public void getDeptUserListByJoin() {
QDept qDept = QDept.dept;
QUser qUser = QUser.user;
StringExpression otherwise = new CaseBuilder().when(qUser.age.gt(18)).then("成年人").when(qUser.age.lt(18)).then("青少年")
.otherwise("快成年了");
List<Tuple> tupleList = jpaQueryFactory.select(qUser.name,
otherwise, qUser.age, qUser.money).from(qDept).join(qUser).on(qDept.id.eq(qUser.deptId))
.orderBy(qUser.age.desc()).fetch();
List<Map<String, Object>> resultList = tupleList.stream().map(x -> {
Map<String, Object> resultMap = new HashMap<>();
resultMap.put("name", x.get(qUser.name));
resultMap.put("age", x.get(1, User.class));
return resultMap;
}).collect(Collectors.toList());
String userQueryResultsStr = JSON.toJSONString(resultList);
System.out.println("getDeptUserListByJoin的结果集:" + userQueryResultsStr);
}
3.4:Querydsl子查询的使用:
此处Querydsl提供了JPAExpressions类,我们使用该类做子查询处理。
public void getMaxMoneyUserInfo() {
QUser qUser = QUser.user;
List<User> userList = jpaQueryFactory.selectFrom(qUser)
.where(qUser.money.eq(JPAExpressions.select(qUser.money.max()).from(qUser))).fetch();
String userQueryResultsStr = JSON.toJSONString(userList);
System.out.println("getMaxMoneyUserInfo的结果集:" + userQueryResultsStr);
}
3.5:Querydsl多表关联查询返回结果处理:
在上面的多表关联查询我们在select()的填充要查询的列名,jpaQueryFactory处理返回的类型是Tuple,我们通过流处理在根据需要查询的字段名或者下标获取相应的数据再填充到集合里,有些麻烦了;
此处我们可以通过使用querydsl提供的Projections类处理,代码如下:
定义一个vo类,属性与查询的字段名称一致(此处可以采用别名)即可自动装箱到对象里面。
public void getDeptListResultDeal() {
QDept qDept = QDept.dept;
QUser qUser = QUser.user;
List<UserVo> resultList = jpaQueryFactory.select(
Projections.bean(UserVo.class,
qDept.deptNo.concat(":").concat(qDept.deptName).concat(":").concat(qUser.name).as("deptUserName"),
qUser.age, qUser.money)).from(qDept).leftJoin(qUser).on(qDept.id.eq(qUser.deptId))
.orderBy(qUser.age.desc()).fetch();
String userQueryResultsStr = JSON.toJSONString(resultList);
System.out.println("getDeptListResultDeal的结果集:" + userQueryResultsStr);
}
3.6:Querydsl自查询的使用:
此处我们在处理自查询类似写sql一样,别名肯定不一样,所以我们在通过querydsl的时候创建的创建两个Q版的实体类对象,Q版的实体类提供了有参构造,可以指定别名。
public void getDeptParentInfo() {
//select t.dept_name,t1.* from dept_tmw t right join dept_tmw t1 on t.id = t1.p_dept_id
QDept dept1 = new QDept("dept1");
QDept dept2 = new QDept("dept2");
StringExpression otherwise = new CaseBuilder().when(dept1.deptName.isNull().or(dept1.deptName.isEmpty()))
.then("总部")
.otherwise(dept1.deptName);
List<Tuple> fetch = jpaQueryFactory.select(otherwise.concat(":").concat(dept2.deptName), dept2.deptNo, dept2.createTime)
.from(dept1).rightJoin(dept2).on(dept1.id.eq(dept2.pDeptId)).orderBy(dept2.deptNo.desc()).fetch();
List<Map<String, Object>> collect = fetch.stream().map(x -> {
Map<String, Object> resultMap = new HashMap<>();
resultMap.put("name", x.get(0, Dept.class));
resultMap.put("deptNo", x.get(dept2.deptNo));
resultMap.put("createTime", x.get(dept2.createTime));
return resultMap;
}).collect(Collectors.toList());
String userQueryResultsStr = JSON.toJSONString(collect);
System.out.println("getDeptParentInfo的结果集:" + userQueryResultsStr);
}
3.7:Querydsl查询时间区间范围内的用户:
此处时间传递的值是个时间戳字符串,范围取值把字符串转换为了数值进行的区间查询。
public void getUserListByBetweenCreateTime() {
QUser qUser = QUser.user;
List<User> fetch = jpaQueryFactory.selectFrom(qUser).where(qUser.beginTime.between("1567579924276", "1567579954276")).fetch();
String userQueryResultsStr = JSON.toJSONString(fetch);
System.out.println("getUserListByBetweenCreateTime的结果集:" + userQueryResultsStr);
}
4. Querydsl与spring web的整合:
此处spring-data提供了注解@QuerydslPredicate可以将http请求的参数转换为Predicate;
以下代码如下链接通过访问:
http://localhost:8080/user/seach?age=30&money=3000
查询结果就是年龄为30并且money为3000的用户,但具体其他的模糊查询,区间查询还未知。
import com.querydsl.core.types.Predicate;
import com.springboot.demo.bean.User;
import com.springboot.demo.dao.UserDao;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.querydsl.binding.QuerydslPredicate;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestMethod;
import org.springframework.web.bind.annotation.ResponseBody;
import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController
@RequestMapping(value = "/user")
public class UserController {
@Autowired
private UserDao userDao;
@RequestMapping(value = "/seach", method = RequestMethod.GET)
@ResponseBody
//http://localhost:8080/ar/user/seach?age=30&money=3000
public Iterable<User> getUsers(
@QuerydslPredicate(root = User.class) Predicate predicate) {
Iterable<User> list = userDao.findAll(predicate);
return list;
}
}
import com.springboot.demo.bean.User;
import org.springframework.data.jpa.repository.JpaRepository;
import org.springframework.data.jpa.repository.JpaSpecificationExecutor;
import org.springframework.data.querydsl.QuerydslPredicateExecutor;
public interface UserDao extends JpaRepository<User, String>, JpaSpecificationExecutor<User>, QuerydslPredicateExecutor<User> {
}
5. 总结:
通过对querydsl-jpa的学习了解,与spring-data-jpa比较,我们在处理复杂查询以及多表关联的时候使用querydsl-jpa,可以使代码可读性更高,而使用spring-data-jpa提供的dao层的继承接口:JpaRepository以及JpaSpecificationExecutor让我们对单表的查询操作更简洁,所以在实际应用中我们可以结合的使用,取其优点去其糟粕。
