
XGBoost(eXtreme Gradient Boosting)其核心是对决策树(Decision Tree)的增强(Boosting)方法,属于集成学习(Ensemble Learning)。
下文分别对决策树、决策树集成以及Xgboost进行介绍。
一、决策树 Decision Tree
决策树是一种常见的监督学习方法,可以用于处理分类和回归问题。
分类问题(离散值):西瓜甜不甜?
回归问题(连续值):房价多少?
顾名思义就是构建一个树形的决策过程。树中的每个节点即挑选特定特征对样本进行决策。
特征树的构建主要分为三个步骤:特征选择、决策树构建、剪枝。
其中根据特征选择的方式不同,分为ID3、C4.5、CART三类主要算法。
ID3基于信息增益进行特征选择:
![]()
分为训练集数据在经过特征A前/后的信息熵。
通过选取特征A最大化信息增益:
![]()
但是由于特征的取值不均衡的问题(比如性别只有男女,年龄可以分很多类),ID3算法更倾向于选择取值更多的特征。
CART(Classification And Regression Tree)基于基尼系数进行特征选择,在分类问题中:
通过将计算熵值(对数运算)转变为计算基尼系数(平方运算)大大降低了运算复杂度。
对于回归树而言,CART可以处理回归树问题,其优化目标如下:
即通过特征j和切分点s将数据集切分为两个集合, 并最小化两个集合中各自样本的方差(c1,c2分别是集合样本的均值)。
总的来说,决策树是基于特征进行if-then的决策过程,高效、易于理解。但是对训练样本严重依赖,容易生成复杂的树结构,造成过拟合(overfitting)等问题。而且如果要学习得到一棵最优的决策树被认为是NP-Complete问题。实际中的决策树是基于启发式的贪心算法建立的,这种算法不能保证建立全局最优的决策树。
二、决策树集成 Tree Ensemble
集成学习(ensemble learning)通过构建并结合多个学习器来完成学习任务,这里主要关注Bagging和Boosting两类。
2.1 Bagging
Bagging (bootstrap aggregating) 是基于Bootstraping重采样方法(有放回的采样),独立训练产生k个模型,并综合k个模型的输出得到最终结果(分类问题可以采用投票方式,回归问题可以采用均值)。Bootstraping通常能够包含63.2%的数据样本
![]()
。它可以并行执行,并通过这种方式避免模型对于训练数据过于敏感,减少模型的方差。
Bagging与决策树的结合就得到了随机森林(Random Forest),与Bagging方法唯一的不同在于Random Forest在特征选择前,使用了特征采样(一般使用
![]()
个特征),减少了强分类属性对模型的影响,使得不同模型更为独立。
2.2 Boosting
Boosting方法中数据集是不变的而在改变样本的权重,使得后续模型更关注与先前模型错分的样本,需要串行执行。具体而言可以分为如下几类:
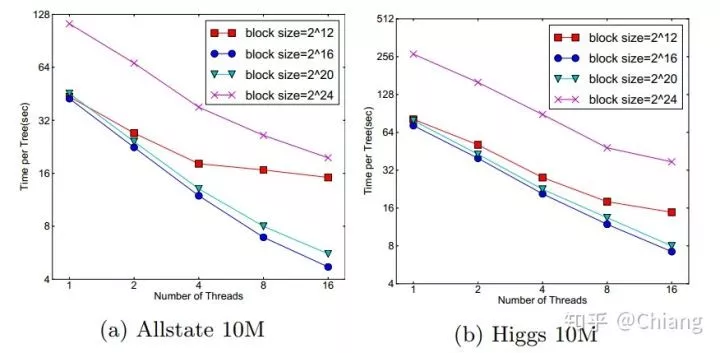
AdaBoosting(Adaptive Boosting),在Boosting的基础上AdaBoosting为每轮迭代过程中基于加权后样本的误率赋予每个模型对应权值。模型权重与迭代过程中样本权重的更新方法如下:
Gradient Boosting 一般用于回归树,采用上轮模型预测值与真实值之间的残差作为下一轮的输入
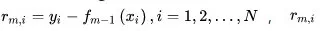
表示第i个样本第m轮的残差,
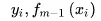
分别为真实值和预测值。
GBDT(Gradient Boosting Decision Tree), 对于下一轮的输入(残差),根据不同的损失函数提供了不同的计算方法,
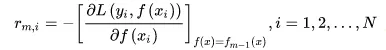
。当损失函数为平方差时,残差与GB中一致。通过加入了学习率的概念,可以调整对于错分数据的关注。
Xgboost本文主角,这里与GBDT先做一个比较,后续做详细说明:
1. 将树模型的复杂度加入到正则项中,来避免过拟合,因此泛化性能会优于GBDT。
2. 损失函数是用泰勒展开式展开的,同时用到了一阶导和二阶导,可以加快优化速度。
3. 和GBDT只支持CART作为基分类器之外,还支持线性分类器,在使用线性分类器的时候可以使用L1,L2正则化。
4. 引进了特征子采样,像RandomForest那样,这种方法既能降低过拟合,还能减少计算。
5. 在寻找最佳分割点时,考虑到传统的贪心算法效率较低,实现了一种近似贪心算法,用来加速和减小内存消耗,除此之外还考虑了稀疏数据集和缺失值的处理,对于特征的值有缺失的样本,XGBoost依然能自动找到其要分裂的方向。
6. XGBoost支持并行处理,XGBoost的并行不是在模型上的并行,而是在特征上的并行,将特征列排序后以block的形式存储在内存中,在后面的迭代中重复使用这个结构。这个block也使得并行化成为了可能,其次在进行节点分裂时,计算每个特征的增益,最终选择增益最大的那个特征去做分割,那么各个特征的增益计算就可以开多线程进行。
三、Xgboost
与论文对应,这里分为三个部分对Xgboost进行介绍:Xgboost模型、分割点的查找、算法并行实现。
3.1.3 Shrinkage and Column Subsampling
Shrinkage(收缩)即能和GBDT一样设置学习率,削减每棵树的影响,让后面有更大的学习空间。实际应用中,一般把学习率设置得小一点,然后迭代次数设置得大一点。
Column Subsampling(列抽样)即Random Forest中的特征抽样方法,使得每棵树能够尽量独立。
3.2 分割点的查找 Split Finding
为了找到特征的最优切分点,需要遍历特征所有的取值,并得到所有可能的切分点。然后带入目标函数进行计算,并将最优的目标函数值对应的切分点,作为特征的切分点。但是由于回归问题中,特征是连续的存在很多候选切分点,所以找到最优切分点需要耗费大量的时间和内存。
3.2.1 Approximate Algorithm
Xgboost采用了一种近似做法,对排序后的特征进行分段,只在分段和分段间形成候选的切分点,大大减少了候选分割点的个数。其算法和效果如下图所示
![]()
分割点的近似查找方法,分为全局和局部两种
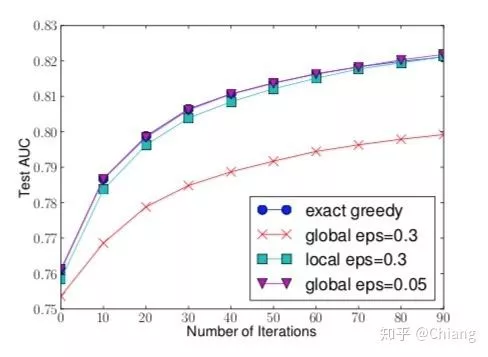
最优分割和近似分割比较。eps = epsilon,表示按照eps比例对数据集进行划分
这里一个重要的问题是按照何种标准生成候选分割点,Xgboost中并不是简单地等分切割,而是根据二阶导数进行加权切割。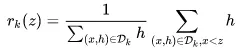 。
。
3.2.2 Sparsity-aware Split Finding
对于数据稀疏的情况,比如:1. 数据缺失值;2. 大量的0值; 3. 进行了One-hot 编码。Xgboost提供了对应的算法给与稀疏的数据一个默认值。其方法核心在于将缺失的样本全部划分在节点的左侧或是右侧,并选择其中增益最大的一种划分方法作为默认划分。

3.3 系统设计 System Design
3.3.1 Column Block for Parallel Learning
建树过程中最大的耗时在于对样本的排序,为了降低排序时间,采用Block结构对排序信息进行存储:
可以看出,只需在建树前排序一次,后面节点分裂时可以直接根据索引得到梯度信息。
在Exact greedy算法中,将整个数据集存放在一个Block中。这样,复杂度从原来的![]()
这样,Exact greedy算法就省去了每一步中的排序开销。
在近似算法中,使用多个Block,每个Block对应原来数据的子集。不同的Block可以在不同的机器上计算。该方法对Local策略尤其有效,因为Local策略每次分支都重新生成候选切分点。
Block结构还有其它好处,数据按列存储,可以同时访问所有的列,很容易实现并行的寻找分裂点算法。此外也可以方便实现之后要讲的out-of score计算。但缺点是空间消耗大了一倍。
3.3.2 Cache-aware Access
使用Block结构的一个缺点是取梯度的时候,是通过索引来获取的,而这些梯度的获取顺序是按照特征的大小顺序的。这将导致非连续的内存访问,可能使得CPU cache缓存命中率低,从而影响算法效率。
因此,对于exact greedy算法中, 使用缓存预取。具体来说,对每个线程分配一个连续的buffer,读取梯度信息并存入Buffer中(这样就实现了非连续到连续的转化),然后再统计梯度信息。该方式在训练样本数大的时候特别有用,见下图:
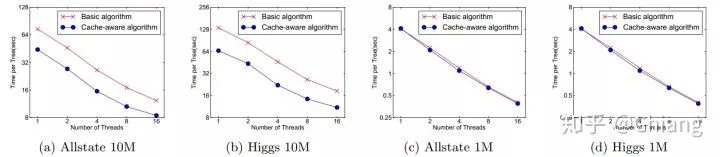
在approximate 算法中,对Block的大小进行了合理的设置。定义Block的大小为Block中最多的样本数。设置合适的大小是很重要的,设置过大则容易导致命中率低,过小则容易导致并行化效率不高。经过实验,发现2^16比较好。
3.3.3 Blocks for Out-of-core Computation
当数据量太大不能全部放入主内存的时候,为了使得out-of-core计算称为可能,将数据划分为多个Block并存放在磁盘上。
计算的时候,使用独立的线程预先将Block放入主内存,因此可以在计算的同时读取磁盘
Block压缩,貌似采用的是近些年性能出色的LZ4 压缩算法,按列进行压缩,读取的时候用另外的线程解压。对于行索引,只保存第一个索引值,然后用16位的整数保存与该block第一个索引的差值。
Block Sharding, 将数据划分到不同硬盘上,提高磁盘吞吐率



 ,
,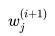 为j样本在i+1轮的权重,
为j样本在i+1轮的权重, 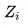 用于正则化权重。
用于正则化权重。
