

刚才英伟达的朋友指出此文有很多错误,大家先别看了,待我明天回炉重造
最近看fastertransformer源码,接触了很多底层到东西,cuda源码各种看不懂,就去学cuda,学了一会儿觉得就想放弃,结果翻回去看源码还是不懂,反复几次,最后干脆拿出一上午静静地把官方文档啃了啃才算入门。所以写这篇文章帮助同样想要放弃的同学入门一下。
网上关于cuda的文章并不多,知乎有一篇很高赞的Cuda入门极简教程,但看完了有些概念我还是弄混了,最后发现官方文档真的香,有时间的朋友建议还是老老实实读这个,没时间的话再看我简化的入门文章(只准备写到矩阵乘法)。
本文默认的读者是会用tensorflow等高级API但不太懂底层实现的同学们哦
1. 物理层
CUDA是英伟达2006年底推出的GPU并行计算平台,支持开发者通过各种语言对GPU计算编程。GPU有以下几种:
- Tesla系列:数值计算
- Quadro系列:高级的图形建模
- GeForce系列:打游戏
- Tegra系列:移动设备
每个系列的GPU会有不同的架构,从Kepler到Turing,每代架构都会进行一些改进。再上层也有封装好的计算库(cuDNN、cuBLAS),我们平常通过tensorflow、pytorch调的包都是对这些计算库的又一层封装。
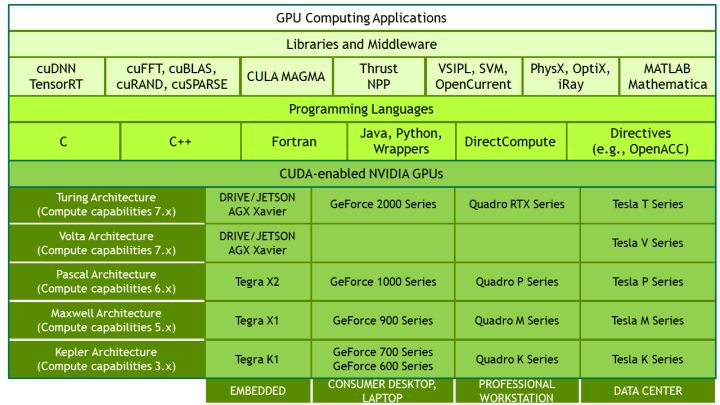
物理层上,一个GPU会包含显存和计算单元,

计算单元中有多个SM(streaming multiprocessors),每个SM上都有寄存器、内存和执行任务的SP(streaming processor/cuda core),运行时一个SP执行一个thread。
2. 逻辑层
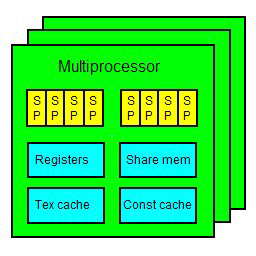
在编程时不需要自己进行线程的调度,只需要指定某个任务需要多少个线程就好了。CUDA中把每个任务叫做一个Kernel,可以理解为GPU上一个线程所执行的函数。实现时是带有__global__标志的函数。
在调用kernel前需要指定线程数。在cuda中有两个层级:grid和block,grid包含多个线程块(block),block中包含多个线程(最多1024个):
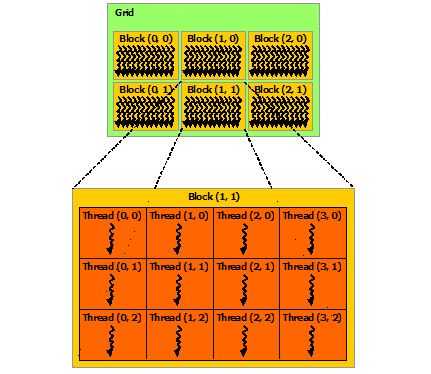
贴一个矩阵加法的例子,代码中每个block处理矩阵的一行,block中的一个线程处理一个element的相加:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int row = blockIdx.x;
int col = threadIdx.x;
if (row < N && col < N)
C[row][col] = A[row][col] + B[row][col];
}
int main()
{
...
// Kernel invocation
dim3 numBlocks(N); //grid dim
dim3 threadsPerBlock(N); //block dim
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}其实grid和block都是可以设置成多维(有x,y,z三个轴)的,比如英伟达文档中给的例子,就是一个block处理矩阵中的16*16加法:
// Kernel definition
__global__ void MatAdd(float A[N][N], float B[N][N],
float C[N][N])
{
int i = blockIdx.x * blockDim.x + threadIdx.x; //find row
int j = blockIdx.y * blockDim.y + threadIdx.y; //find col
if (i < N && j < N)
C[i][j] = A[i][j] + B[i][j];
}
int main()
{
...
// Kernel invocation
dim3 threadsPerBlock(16, 16);
dim3 numBlocks(N / threadsPerBlock.x, N / threadsPerBlock.y);
MatAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);
...
}事实上,逻辑层虽然一次launch很多个线程,物理层上是没有那么多线程同时执行的,CUDA每次的执行都是以wrap(32个线程)为单位,每个SM上只有8个SP,4个一组,一般会执行16个线程,原因是:
一个 warp 里面有 32 个 threads,分成两组 16 threads 的 half-warp。由于 stream processor 的运算至少有 4 cycles 的 latency,因此对一个 4D 的stream processors 来说,一次至少执行 16 个 threads(即 half-warp)才能有效隐藏各种运算的 latency( 如果你开始运算,再开一个线程,开始运算,再开一个线程,开始运算,再开一个线程开始运算,这时候第一个线程就ok了,第一个线程再开始运算 , 看起来就没有延迟了, 每个处理单元上最少开4个可以达到隐藏延迟的目的,也就是4*4=16个线程)。也因此,线程数达到隐藏各种latency的程度后,之后数量的提升就没有太大的作用了。
原文链接:blog.csdn.net/Bruce_0712/…2673
3. 内存分配
每个线程可以访问到自己的local memory,还有block上的shared memory和全局内存global memory,上面三种内存的访问速度是从小到大的,全局内存访问最慢:
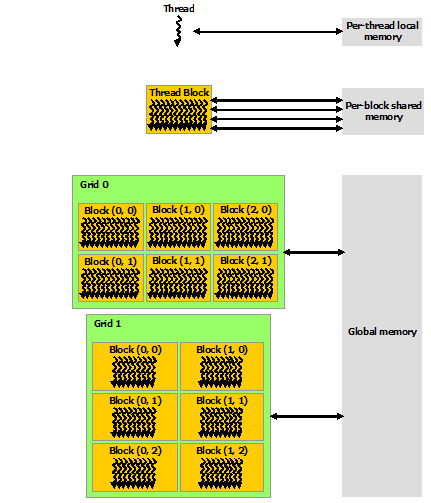
在英伟达的概念中,host指CPU,device指GPU,kernel运行时只能访问到GPU的内存,所以在执行任务前后都需要在host和device之间进行数据交互:
// Host code
int main()
{
int N = ...;
size_t size = N * sizeof(float);
// Allocate input vectors h_A and h_B in host memory 分配host内存
float* h_A = (float*)malloc(size);
float* h_B = (float*)malloc(size);
// Initialize input vectors
...
// Allocate vectors in device memory 分配device内存
float* d_A;
cudaMalloc(&d_A, size);
float* d_B;
cudaMalloc(&d_B, size);
float* d_C;
cudaMalloc(&d_C, size);
// Copy vectors from host memory to device memory 数据从host到device
cudaMemcpy(d_A, h_A, size, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, size, cudaMemcpyHostToDevice);
// Invoke kernel
int threadsPerBlock = 256;
int blocksPerGrid =
(N + threadsPerBlock - 1) / threadsPerBlock;
VecAdd<<<blocksPerGrid, threadsPerBlock>>>(d_A, d_B, d_C, N);
// Copy result from device memory to host memory 数据从device到host
// h_C contains the result in host memory
cudaMemcpy(h_C, d_C, size, cudaMemcpyDeviceToHost);
// Free device memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Free host memory
...
}3. CUDA矩阵乘法
了解了物理层的硬件结构和逻辑层的编程模型后,就可以进行cuda编程了。我认为重要的有两步:
- Kernel launch前的线程分配(我也没太懂,同学们多看些源码吧)
- Kernel的实现(如何根据当前thread找到运算的单元、以及如何高效运算)
下面主要通过矩阵乘法的官方例子讲一下我对第二步的理解。
void main()
{
...
// Invoke kernel
dim3 dimBlock(BLOCK_SIZE, BLOCK_SIZE);
dim3 dimGrid(B.width / dimBlock.x, A.height / dimBlock.y);
MatMulKernel<<<dimGrid, dimBlock>>>(d_A, d_B, d_C);
...
}
// Matrix multiplication kernel called by MatMul()
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
{
// Each thread computes one element of C
// by accumulating results into Cvalue
float Cvalue = 0;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int col = blockIdx.x * blockDim.x + threadIdx.x;
for (int e = 0; e < A.width; ++e)
Cvalue += A.elements[row * A.width + e]
* B.elements[e * B.width + col];
C.elements[row * C.width + col] = Cvalue;
}刚接触cuda肯定会云里雾里,被一堆blockId,blockDim,threadId搞晕,我个人的理解是一定要理解整体的分区,知道每个线程/kernel要做什么,然后找到当前线程与目标矩阵元素的对应关系,就可以看懂代码了。
比如在invoke kernel的时候我们可以看出目标矩阵C被分块处理,每个block处理矩阵中一个BLOCK_SIZE*BLOCK_SIZE的区域,然后每个线程计算一个区域中的一个目标元素(即A的某行*B的某列),如下图:
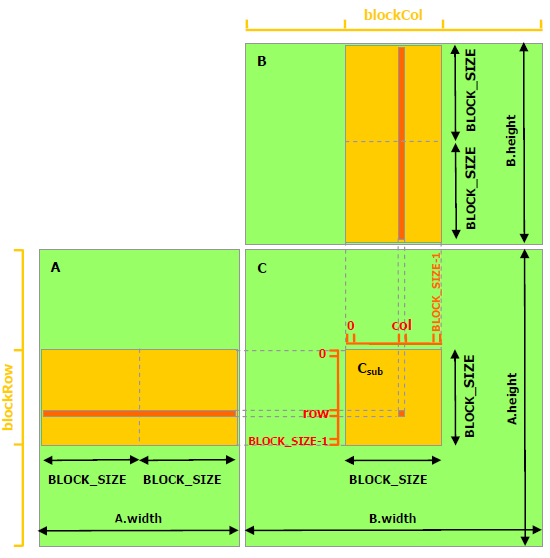
(没有人提问的话我就当做大家都理解了)
上述矩阵乘法做到了计算并行化,但还有一个问题就是对全局内存的频繁读写,每个element都从全局内存读,计算完后写回全局内存,如果很多线程同时进行这样的操作,会被带宽所限制,因此一个优化的方案就是把A、B子矩阵读到block的共享内存中,这样每个block内的线程都不用单独去全局内存中取:
// Matrices are stored in row-major order:
// M(row, col) = *(M.elements + row * M.stride + col)
typedef struct {
int width;
int height;
int stride;
float* elements;
} Matrix;
// Get a matrix element
__device__ float GetElement(const Matrix A, int row, int col)
{
return A.elements[row * A.stride + col];
}
// Set a matrix element
__device__ void SetElement(Matrix A, int row, int col,
float value)
{
A.elements[row * A.stride + col] = value;
}
// Get the BLOCK_SIZExBLOCK_SIZE sub-matrix Asub of A that is
// located col sub-matrices to the right and row sub-matrices down
// from the upper-left corner of A
__device__ Matrix GetSubMatrix(Matrix A, int row, int col)
{
Matrix Asub;
Asub.width = BLOCK_SIZE;
Asub.height = BLOCK_SIZE;
Asub.stride = A.stride;
Asub.elements = &A.elements[A.stride * BLOCK_SIZE * row
+ BLOCK_SIZE * col];
return Asub;
}
// Thread block size
#define BLOCK_SIZE 16
// Matrix multiplication kernel called by MatMul()
__global__ void MatMulKernel(Matrix A, Matrix B, Matrix C)
{
// Block row and column
int blockRow = blockIdx.y;
int blockCol = blockIdx.x;
// Each thread block computes one sub-matrix Csub of C
Matrix Csub = GetSubMatrix(C, blockRow, blockCol);
// Each thread computes one element of Csub
// by accumulating results into Cvalue
float Cvalue = 0;
// Thread row and column within Csub
int row = threadIdx.y;
int col = threadIdx.x;
// Loop over all the sub-matrices of A and B that are
// required to compute Csub
// Multiply each pair of sub-matrices together
// and accumulate the results
for (int m = 0; m < (A.width / BLOCK_SIZE); ++m) {
// Get sub-matrix Asub of A
Matrix Asub = GetSubMatrix(A, blockRow, m);
// Get sub-matrix Bsub of B
Matrix Bsub = GetSubMatrix(B, m, blockCol);
// Shared memory used to store Asub and Bsub respectively
__shared__ float As[BLOCK_SIZE][BLOCK_SIZE];
__shared__ float Bs[BLOCK_SIZE][BLOCK_SIZE];
// Load Asub and Bsub from device memory to shared memory
// Each thread loads one element of each sub-matrix
As[row][col] = GetElement(Asub, row, col);
Bs[row][col] = GetElement(Bsub, row, col);
// Synchronize to make sure the sub-matrices are loaded
// before starting the computation
__syncthreads();
// Multiply Asub and Bsub together
for (int e = 0; e < BLOCK_SIZE; ++e)
Cvalue += As[row][e] * Bs[e][col];
// Synchronize to make sure that the preceding
// computation is done before loading two new
// sub-matrices of A and B in the next iteration
__syncthreads();
}
// Write Csub to device memory
// Each thread writes one element
SetElement(Csub, row, col, Cvalue);
}代码中的__device__表示运行在GPU上的函数,且只能被GPU上的函数调用,__syncthreads表示线程同步,是比较常用的函数。
暂时就更到这里啦,按照自己的思路来的,可能讲的有些简略,不懂的欢迎提问~不过还是多看代码自己想一想来的快~
