


Storm,Spark Streaming,Flink流处理的三驾马车各有各的优势.
Storm低延迟,并且在市场中占有一定的地位,目前很多公司仍在使用。
Spark Streaming借助Spark的体系优势,活跃的社区,也占有一定的份额。
而Flink在设计上更贴近流处理,并且有便捷的API,未来一定很有发展。

但是他们都离不开Kafka的消息中转,所以Kafka于0.10.0.0版本推出了自己的流处理框架,Kafka Streams。Kafka的定位也正式成为Apache Kafka® is *a distributed streaming platform,*分布式流处理平台。
实时流式计算
近几年来实时流式计算发展迅速,主要原因是实时数据的价值和对于数据处理架构体系的影响。实时流式计算包含了 无界数据 近实时 一致性 可重复结果 等等特征。a type of data processing engine that is designed with infinite data sets in mind 一种考虑了无线数据集的数据处理引擎。
1、无限数据:一种不断增长的,基本上无限的数据集。这些通常被称为“流式数据”。无限的流式数据集可以称为无界数据,相对而言有限的批量数据就是有界数据。
2、无界数据处理:一种持续的数据处理模式,应用于上面的无界数据。批量处理数据(离线计算)也可以重复运行来处理数据,但是会有性能的瓶颈。
3、低延迟,近实时的结果:相对于离线计算而言,离线计算并没有考虑延迟的问题。
解决了两个问题,流处理可以提代批处理系统:
1、正确性:有了这个,就和批量计算等价了。
Streaming需要能随着时间的推移依然能计算一定时间窗口的数据。Spark Streaming通过微批的思想解决了这个问题,实时与离线系统进行了一致性的存储,这一点在未来的实时计算系统中都应该满足。
2、推理时间的工具:这可以让我们超越批量计算。
好的时间推理工具对于处理不同事件的无界无序数据至关重要。
而时间又分为事件时间和处理时间。
还有很多实时流式计算的相关概念,这里不做赘述。
Kafka Streams简介
Kafka Streams被认为是开发实时应用程序的最简单方法。它是一个Kafka的客户端API库,编写简单的java和scala代码就可以实现流式处理。
优势:
-
弹性,高度可扩展,容错
-
部署到容器,VM,裸机,云
-
同样适用于小型,中型和大型用例
-
与Kafka安全性完全集成
-
编写标准Java和Scala应用程序
-
在Mac,Linux,Windows上开发
-
Exactly-once 语义
用例:
纽约时报使用Apache Kafka和Kafka Streams将发布的内容实时存储和分发到各种应用程序和系统,以供读者使用。
Pinterest大规模使用Apache Kafka和Kafka Streams来支持其广告基础架构的实时预测预算系统。使用Kafka Streams,预测比以往更准确。
作为欧洲领先的在线时尚零售商,Zalando使用Kafka作为ESB(企业服务总线),帮助我们从单一服务架构转变为微服务架构。使用Kafka处理 事件流使我们的技术团队能够实现近乎实时的商业智能。
荷兰合作银行是荷兰三大银行之一。它的数字神经系统Business Event Bus由Apache Kafka提供支持。它被越来越多的财务流程和服务所使用,其中之一就是Rabo Alerts。此服务会在财务事件时实时向客户发出警报,并使用Kafka Streams构建。
LINE使用Apache Kafka作为我们服务的中央数据库,以便彼此通信。每天产生数亿亿条消息,用于执行各种业务逻辑,威胁检测,搜索索引和数据分析。LINE利用Kafka Streams可靠地转换和过滤主题,使消费者可以有效消费的子主题,同时由于其复杂而简单的代码库,保持易于维护性。
Topology
Kafka Streams通过一个或多个拓扑定义其计算逻辑,其中拓扑是通过流(边缘)和流处理器(节点)构成的图。
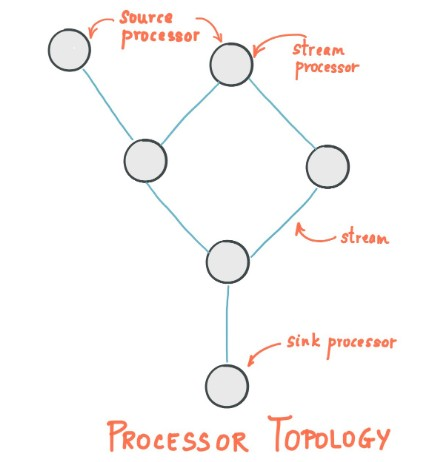
拓扑中有两种特殊的处理器
- 源处理器:源处理器是一种特殊类型的流处理器,没有任何上游处理器。它通过使用来自这些主题的记录并将它们转发到其下游处理器,从一个或多个Kafka主题为其拓扑生成输入流。
- 接收器处理器:接收器处理器是一种特殊类型的流处理器,没有下游处理器。它将从其上游处理器接收的任何记录发送到指定的Kafka主题。
在正常处理器节点中,还可以把数据发给远程系统。因此,处理后的结果可以流式传输回Kafka或写入外部系统。
Kafka在这当中提供了最常用的数据转换操作,例如map,filter,join和aggregations等,简单易用。
当然还有一些关于时间,窗口,聚合,乱序处理等。未来再一一做详细介绍,下面我们进行简单的入门案例开发。
快速入门
首先提供WordCount的java版和scala版本。
java8+:
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.common.utils.Bytes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.KTable;
import org.apache.kafka.streams.kstream.Materialized;
import org.apache.kafka.streams.kstream.Produced;
import org.apache.kafka.streams.state.KeyValueStore;
import java.util.Arrays;
import java.util.Properties;
public class WordCountApplication {
public static void main(final String[] args) throws Exception {
Properties props = new Properties();
props.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application");
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092");
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
StreamsBuilder builder = new StreamsBuilder();
KStream<String, String> textLines = builder.stream("TextLinesTopic");
KTable<String, Long> wordCounts = textLines
.flatMapValues(textLine -> Arrays.asList(textLine.toLowerCase().split("\\W+")))
.groupBy((key, word) -> word)
.count(Materialized.<String, Long, KeyValueStore<Bytes, byte[]>>as("counts-store"));
wordCounts.toStream().to("WordsWithCountsTopic", Produced.with(Serdes.String(), Serdes.Long()));
KafkaStreams streams = new KafkaStreams(builder.build(), props);
streams.start();
}
}
scala:
import java.util.Properties
import java.util.concurrent.TimeUnit
import org.apache.kafka.streams.kstream.Materialized
import org.apache.kafka.streams.scala.ImplicitConversions._
import org.apache.kafka.streams.scala._
import org.apache.kafka.streams.scala.kstream._
import org.apache.kafka.streams.{KafkaStreams, StreamsConfig}
object WordCountApplication extends App {
import Serdes._
val props: Properties = {
val p = new Properties()
p.put(StreamsConfig.APPLICATION_ID_CONFIG, "wordcount-application")
p.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, "kafka-broker1:9092")
p
}
val builder: StreamsBuilder = new StreamsBuilder
val textLines: KStream[String, String] = builder.stream[String, String]("TextLinesTopic")
val wordCounts: KTable[String, Long] = textLines
.flatMapValues(textLine => textLine.toLowerCase.split("\\W+"))
.groupBy((_, word) => word)
.count()(Materialized.as("counts-store"))
wordCounts.toStream.to("WordsWithCountsTopic")
val streams: KafkaStreams = new KafkaStreams(builder.build(), props)
streams.start()
sys.ShutdownHookThread {
streams.close(10, TimeUnit.SECONDS)
}
}
如果kafka已经启动了,可以跳过前两步。
1、下载
下载 2.3.0版本并解压缩它。请注意,有多个可下载的Scala版本,我们选择使用推荐的版本(2.12):
> tar -xzf kafka_2.12-2.3.0.tgz
> cd kafka_2.12-2.3.0
2、启动
Kafka使用ZooKeeper,因此如果您还没有ZooKeeper服务器,则需要先启动它。
> bin/zookeeper-server-start.sh config/zookeeper.properties
[2013-04-22 15:01:37,495] INFO Reading configuration from: config/zookeeper.properties (org.apache.zookeeper.server.quorum.QuorumPeerConfig)
...
启动Kafka服务器:
> bin/kafka-server-start.sh config/server.properties
[2013-04-22 15:01:47,028] INFO Verifying properties (kafka.utils.VerifiableProperties)
[2013-04-22 15:01:47,051] INFO Property socket.send.buffer.bytes is overridden to 1048576 (kafka.utils.VerifiableProperties)
...
3、创建topic 启动生产者
我们创建名为streams-plaintext-input的输入主题和名为streams-wordcount-output的输出主题:
> bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-plaintext-input
Created topic "streams-plaintext-input".
> bin/kafka-topics.sh --create \
--bootstrap-server localhost:9092 \
--replication-factor 1 \
--partitions 1 \
--topic streams-wordcount-output \
--config cleanup.policy=compact
Created topic "streams-wordcount-output".
查看:
> bin/kafka-topics.sh --bootstrap-server localhost:9092 --describe
Topic:streams-plaintext-input PartitionCount:1 ReplicationFactor:1 Configs:
Topic: streams-plaintext-input Partition: 0 Leader: 0 Replicas: 0 Isr: 0
Topic:streams-wordcount-output PartitionCount:1 ReplicationFactor:1 Configs:cleanup.policy=compact
Topic: streams-wordcount-output Partition: 0 Leader: 0 Replicas: 0 Isr: 0
4、启动WordCount
以下命令启动WordCount演示应用程序:
> bin/kafka-run-class.sh org.apache.kafka.streams.examples.wordcount.WordCountDemo
演示应用程序将从输入主题stream-plaintext-input读取,对每个读取消息执行WordCount算法的计算,并连续将其当前结果写入输出主题streams-wordcount-output。因此,除了日志条目之外不会有任何STDOUT输出,因为结果会写回Kafka。
现在我们可以在一个单独的终端中启动控制台生成器,为这个主题写一些输入数据:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
并通过在单独的终端中使用控制台使用者读取其输出主题来检查WordCount演示应用程序的输出:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
5、处理数据
我们在生产者端输入一些数据。
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
输出端:
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
继续输入:
> bin/kafka-console-producer.sh --broker-list localhost:9092 --topic streams-plaintext-input
all streams lead to kafka
hello kafka streams
> bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 \
--topic streams-wordcount-output \
--from-beginning \
--formatter kafka.tools.DefaultMessageFormatter \
--property print.key=true \
--property print.value=true \
--property key.deserializer=org.apache.kafka.common.serialization.StringDeserializer \
--property value.deserializer=org.apache.kafka.common.serialization.LongDeserializer
all 1
streams 1
lead 1
to 1
kafka 1
hello 1
kafka 2
streams 2
我们看到随着数据实时输入,wordcount的结果实时的输出了。
6、停止程序
您现在可以通过Ctrl-C按顺序停止控制台使用者,控制台生产者,Wordcount应用程序,Kafka代理和ZooKeeper服务器。
什么是Kafka? Kafka监控工具汇总 Kafka快速入门 Kafka核心之Consumer Kafka核心之Producer
更多实时计算,Flink,Kafka等相关技术博文,欢迎关注实时流式计算

