

1 集合概述
Java中有很多集合类,例如ArrayList,LinkedList,HashMap,TreeMap等。集合的功能就是容纳多个对象,它们就像容器一样(实际上,直接称为容器也没有毛病,C++就是这样称呼的),当需要的时候,可以从里面拿出来,非常方便。在Java5提供了泛型机制之后,使容器有了在编译期做类型检查的能力,使用起来更加安全、方便。
Java中的集合类主要是有两个接口派生出来的:Collection和Map,如下所示:
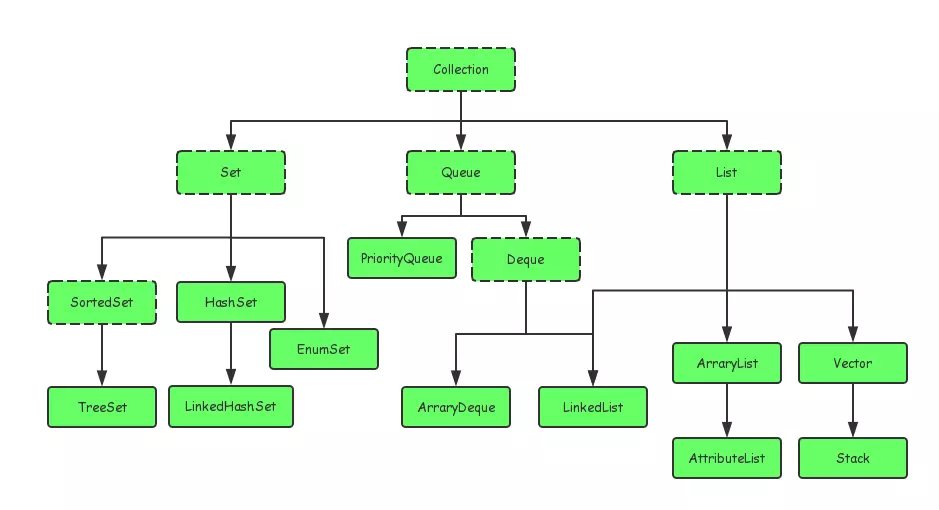
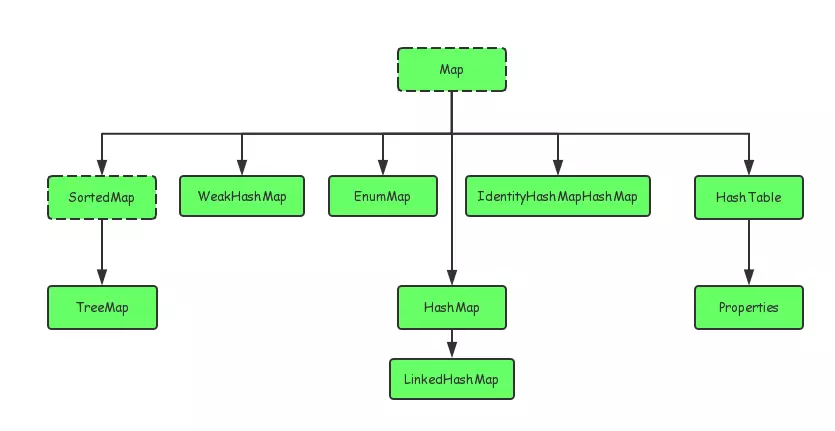
Collection又主要有Set,Queue,List三大接口,在此基础上,又有多个实现类。Map接口下同样有总多的实现类,例如HashMap,EnumMap,HashTable等。接下来我将会挑选几个常用的集合类来具体讨论讨论。
2 ArrayList和LinkedList
List集合可以说是最常用的集合了,比HashMap还常用,一般我们写代码的时候一旦遇到需要存储多个元素的情况,就优先想到使用List集合,至于使用的是ArrayList实现类还是LinkedList实现类,那就具体情况具体分析了。
2.1 ArrayList
ArrayList实现了List接口,继承了AbstractList抽象类,AbstractList抽象类实现了绝大部分List接口定义的抽象方法,所以我们在ArrayList源码中看不到大部分List接口中定义的抽象方法的实现。ArrayList的内部使用数组来存储对象,这也是ArrayList这个名字的由来,其各种操作,例如get,add等都是基于数组操作的,下面是add方法的源码:
public void add(int index, E element) {
//先检查index是否在一个合理的范围内
rangeCheckForAdd(index);
//保证数组的容量足够加入新的元素,发现不足够的话会进行扩容操作
ensureCapacityInternal(size + 1); // Increments modCount!!
//进行一次数组拷贝,这里的elementData就是保存对象的Object数组
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
//往数组中加入元素
elementData[index] = element;
//修改size大小
size++;
}
解释在注释中给出了,get方法也非常简单,就不浪费时间了。
2.2 LinkedList
LinkedList继承了AbstractSequentialList类,AbstractSequentialList类又继承了AbstractList类,同时LinkedList也当然有实现List接口的,而且还实现了Deque接口,这就比较有意思了,说明LinkedList不仅仅是List,还是一个Queue。下图表示其继承体系:
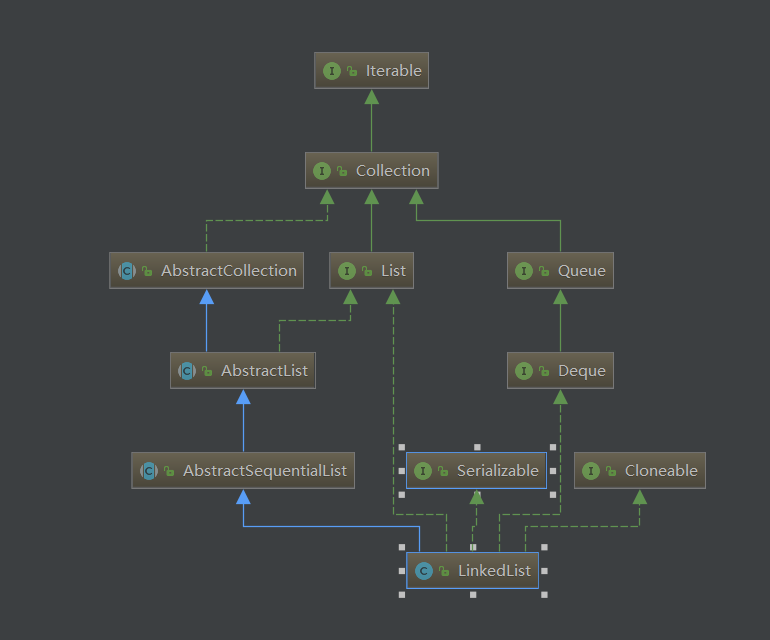
LinkedList的基于链表实现的List,这是和ArrayList最大的区别。LinkedList有一个Node内部类,用来表示节点,如下所示:
private static class Node<E> {
E item;
Node<E> next;
Node<E> prev;
Node(Node<E> prev, E element, Node<E> next) {
this.item = element;
this.next = next;
this.prev = prev;
}
}
该类有next指针和prev指针,可见是一个双向链表。接下来看看LinkedList的add操作:
public void add(int index, E element) {
//检查index
checkPositionIndex(index);
//如果index和size相等,说明已经到最后了,直接在last节点后插入节点接口
if (index == size)
linkLast(element);
else //否则就在index位置插入节点
linkBefore(element, node(index));
}
在linkLast()和linkBefore()方法里会涉及到链表的操作,其中LinkLast()的实现比较简单,linkBefore()稍微复杂一些,但只要学过数据结构的朋友,看这些源码应该没什么问题,在此不贴出源码了,比较本文定位不是源码解析。
2.3 ArrayList和LinkedList的区别
在前面的介绍中其实有说到过,在这里总结一下:
- ArayyList是基于数组实现的,LinkedList是基于链表实现的,因为实现不同,他们的效率之间肯定是有差别的,ArrayList的随机访问效率较高,但插入操作会涉及到数组拷贝,所以效率插入效率不高。LinkedList的插入效率可高可低,如果是在尾部插入,因为有一个last节点,所以尾部插入的速度非常快,但在其他位置的插入效率并不高,对于随机访问来说,因为需要从头开始遍历节点,所以随机访问的效率并不高。
- 他们的继承体系稍微有些区别,LinkedList还实现了Deque接口,这是比较有特点的。
3 SynchronizedList和Vector
之所以把他们俩发在一起是因为它们是线程安全的列表集合。SynchronizedList是Collections工具类里的一个内部静态类,实现了List接口,继承了SynchronizedCollection类,Vector是JDK早期的一个同步的List,和ArrayList的继承体系完全一样,而且也是基于数组实现的,只是他的各种方法都是同步的。
3.1 SynchronizedList
SynchronizedList类是一个Collections类中包级私有的静态内部类,我们在编写代码的时候无法直接调用这个类,只能通过Collection.synchronizedList()方法并传入一个List来使用它,这个方法实际上就是帮我们将原来没有同步措施的普通List包装成了SynchronizedList,使其拥有线程安全的特性,对其进行操作就是对原List的操作,如下所示:
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}
3.2 Vector
Vector是JDK1.0就有的类,算是一个远古时期的类了,在当时因为没有比较好的同步工具,所以在并发场景下会使用到这个类,但现在随着并发技术的进步,有了更好的同步工具类,所以Vector已经快成为半废弃状态了。为什么呢?主要还是因为同步效率太低,同步手段太粗暴了,粗暴到直接将绝大多数方法弄成同步方法(在方法上加入synchronized关键字),连clone方法都没放过:
public synchronized Object clone() {
try {
@SuppressWarnings("unchecked")
Vector<E> v = (Vector<E>) super.clone();
v.elementData = Arrays.copyOf(elementData, elementCount);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
这样做虽然能确保线程安全,但效率实在太低了啊,尤其是在竞争激烈的环境下,效率可能还不如单线程。相比之下,SynchronizedList就好很多,只是在必要的地方进行加锁而已(不过实际上效率还是挺低的)。基于它的CRUD操作就不多说了,和ArrayList没什么大的区别。
SynchronizedList和Vector的区别
他们最大区别就在同步效率,Vector的同步手段过于粗暴以至于效率太低,SynchronizedList的同步手段没那么粗暴,只是在有必要的地方进行同步而已,效率较Vector会好一些,但实际上也不会太好,比较同步手段比较单一,只是用内置锁一种方案而已。
4 HashMap、HashTable和ConcurrentHashMap
当我们想要存储键值对或者说是想要表达某种映射关系的时候,都会用到HashMap这个类,HashTable则是HashMap的同步版本,是线程安全的,但效率很低,ConcurrentHashMap是JDK1.5之后替代HashTable的类,效率较高,所以现在在并发环境下一般不再使用HashTable,而是使用ConcurrentHashMap。
顺便说一下,ConcurrentHashMap是在J.U.C包下的,该包的主要作者是Doug Lea,这位大佬几乎一个人撑起了Java并发技术。
4.1 HashMap
HashMap的内部结构是数组(称作table)+链表(达到阈值会转换成红黑树)的形式。数组和链表存储的元素都是Node,如下所示:
static class Node<K,V> implements Map.Entry<K,V> {
final int hash;
final K key;
V value;
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}
当向HashMap插入键值对的时候,会先拿key进行hash运算,得到一个hashcode,然后根据hashcode来确定该键值对(最终的形式上其实是Node)应该放置在table的哪个位置,这个过程中如果有Hash冲突,即table中该位置已经有了Node节点A,那么就会将这个新的键值对插入到以A节点为头节点的链表中(此尾插法,在JDK1.8中改为头插法),如果在遍历链表的途中遇到key相同的情况,那么就直接用新的value值替换到原来的值,这种情况就不再创建新的Node了,如果在途中没有遇到的话,就在最后创建一个Node节点,并将其插入到链表末尾。
关于HashMap更多的内容,例如什么并发扩容导致的问题,以及扩容因子对性能的影响等等,建议网上搜索,网上这样的文章非常非常多,多到打开一个社区,都TM是将HashMap的文章.....
4.2 HashTable
HashTable的算法实现和HashMap并没有太多区别,可以简单把HashTable理解成HashMap的线程安全版本,HashTable实现线程安全的手段也是非常粗暴的,和Vector几乎一样,直接将绝大多数方法设置成同步方法,如下所示:
public synchronized boolean contains(Object value) {
if (value == null) {
throw new NullPointerException();
}
Entry<?,?> tab[] = table;
for (int i = tab.length ; i-- > 0 ;) {
for (Entry<?,?> e = tab[i] ; e != null ; e = e.next) {
if (e.value.equals(value)) {
return true;
}
}
}
return false;
}
所以,其效率可以说是非常低的,一般很少用了,而是使用接下来要讲到的ConcurrentHashMap代替。
4.3 ConcurrentHashMap
该类位于java.util.concurrent(简称J.U.C)包下,是一款优秀的并发工具类。ConcurrentHashMap内部元素的存储结构和HashMap几乎一样,都是数组+链表(达到阈值会转换成红黑树)的结构。不同的是,CouncurrentHashMap是线程安全的,但并不像HashTable那样粗暴的在每个方法上加入synchronized内置锁。而是采用一种叫做“分段锁”的技术,将一整个table数组分成多个段,每个段有不同的锁,每个锁只能影响到自己所在的段,对其他段没有影响,也就是说,在并发环境下,多个线程可以同时对ConcurrentHashMap的不同的段进行操作。效果就是吞吐量提高了,效率也比HashTable高很多,但麻烦的是一些全局性变量不太好保证一致性,例如size。
关于ConcurrentHashMap更多的内容,还是建议自行查找资料,网上有很多分析ConcurrentHashMap的优秀文章。
4.4 HashMap、HashTable和ConcurrentHashMap的区别
其实上面几个小节都一直有比较,就在这里总结一下:
- HashTable是HashMap的同步版本,但由于同步手段太粗暴,效率较低,ConcurrentHashMap在JDK1.5之后出现,是HashTable的替代类,在此之前,如果想要保证HashMap的线程安全,要么使用HashTable,要么使用Collections.synchronizedMap来包装HashMap,但这两个方案的效率都比较低。
- 他们三者的实现方式几乎一样,内部存储结构并没有什么差别。
- HashTable几乎处于半废弃的状态,不建议在新项目中使用了,推荐使用ConcurrentHashMap。
5 Java8中Stream对集合类的增强
Java8中除了lambda表达式,最大的特性就是Stream流了。Stream API可以将集合看做流,集合中的元素看做一个一个的流元素。这样的抽象可以将对集合的操作变得很简单、清晰,例如在以前要想合并两个集合,就不得不做创建一个新的集合,然后遍历两个集合将元素放入到新的集合中,但用流API的话就非常简单了,只需要将两个集合看做两个流,直接将两个流合成一个流即可。
Stream API还提供了很多高阶函数用于操作流元素,流入map,reduce,filter等,下面是一个使用Stream API的示例:
public void streamTest() {
Random random = new Random();
List<Integer> integers = IntStream.generate(() -> random.nextInt(100))
.limit(100).boxed()
.collect(Collectors.toList());
integers.stream().map(num -> num * 10)
.filter(num -> num % 2 == 0)
.forEach(System.out::println);
}
就这几行代码,实际上只能算是三行代码,就实现了随机生成元素放入list中,并且做了一个map操作和filter操作,还顺带遍历了一下List。如果要用以前的方法,就不得不这样写:
public void originTest() {
Random random = new Random();
List<Integer> integers = new ArrayList<>();
for (int i = 0; i < 100; i++) {
integers.add(random.nextInt(100));
}
for (int i = 0; i < 100; i++) {
integers.set(i, integers.get(i) * 10); //map
}
for (int i = 0; i < 100; i++) {
if (integers.get(i) % 2 == 0) //filter
System.out.println(integers.get(i)); //foreach
}
}
这三个for循环看起来实在是难看。这就是Stream API的优点,简洁,方便,抽象程度高,但可读性会差一些,如果对lambda和Stream不熟悉的朋友第一次看到可能会比较费劲(但实际上,这是很简单的代码)。
那是不是以后对集合的操作都使用Stream API呢?别那么极端,Stream API确实简洁,但可读性很差,Debug难度非常高,更多的时候是靠人肉Debug,而且性能上可能会低于传统的方法,也有可能高,所以,我的建议是:在使用之前,最后先测试一下,将两种方案对比一下,最终根据测试结果挑选一个比较好的方案。
6 小结
集合类是Java开发者必须要掌握的,通过阅读源码理解它们比看文章详解来的更加深刻。本文只是简单的讲了几个常用的集合类,还有很多其他的例如TreeMap,HashSet,TreeSet,Stack都没有涉及,不是说这些集合类不重要,只是受篇幅限制,无法一一道来,希望读者能好好认真看看这些类的源码,看源码的时候不需要从头看到尾,可以先看几个常用的方法,例如get,put等,然后一步一步跟进去,也可以使用调试器单步跟踪代码。
