

内核源码:linux-4.4 目标平台:ARM体系结构 源码工具:source insight 4
说明: 文中由于 md 语法问题,无法在代码高亮的同时而忽略由于
__或者*造成斜体的 问题,所以类似__user改成__ user,或者char *filename改成char* filename。 通过在中间添加空格进行避免。注释统一使用了\\。
open 对应的内核系统调用
应用层的 open 函数是 glibc 库封装了系统调用以比较友好的方式提供给开发者。
那么为什么要这么做?
这主要是从安全以及性能这两大方面进行了考虑:
在用户空间和内核空间之间,有一个叫做Syscall(系统调用, system call)的中间层,是连接用 户态和内核态的桥梁。这样即提高了内核的安全型,也便于移植, 只需实现同一套接口即可。Linux系统,用户空间通过向内核空间发出Syscall,产生软中断, 从而让程序陷入内核态,执行相应的操作。对于每个系统调用都会有一个对应的系统调用号 ,比很多操作系统要少很多。
安全性与稳定性:内核驻留在受保护的地址空间,用户空间程序无法直接执行内核代码 ,也无法访问内核数据,通过系统调用
性能:Linux上下文切换时间很短,以及系统调用处理过程非常精简,内核优化得好,所以性能上 往往比很多其他操作系统执行要好。
在应用层对于 open 操作主要使用的是以下两个函数:
(1) int open(const char *pathname, int flags, mode_t mode);
(2) int openat(int dirfd, const char *pathname, int flags, mode_t mode);
如果打开文件成功,那么返回文件描述符,值大于或等于0;如果打开文件失败,返 回负的错误号。
下面是该函数参数的说明:
- 参数 pathname 是文件路径,可以是相对路径(即不以 “/” 开头),也可以是绝对路径(即以 “/” 开头)。
- 参数 dirfd 是打开一个目录后得到的文件描述符,作为相对路径的基准目录。如果文件路径是
相对路径,那么在函数
openat中解释为相对文件描述符dirfd引用的目录,open函数中解释为相对 调用进程的当前工作目录。如果文件路径是绝对路径,openat忽略参数dirfd。 - 参数 flags 必须包含一种访问模式:
O_RDONLY(只读)、O_ WRONLY(只写)或O_RDWR(读写)。参数flags可以包含多个文件创建标志和文件状态标志。 两组标志的区别是: 文件创建标志只影响打开操作, 文件状态标志影响后面的读写操作。
文件创建标志包括如下:
O_CLOEXEC:开启 close-on-exc标志,使用系统调用 execve() 装载程序的时候关闭文件。CREAT:如果文件不存在,创建文件。ODIRECTORY:参数 pathname 必须是一个日录。EXCL:通常和标志位 CREAT 联合使用,用来创建文件。如果文件已经存在,那么 open() 失败,返回错误号 EEXIST。NOFOLLOW:不允许参数 pathname 是符号链接,即最后一个分量不能是符号 链接,其他分量可以是符号链接。如果参数 pathname 是符号链接,那么打开失败,返回错误号 ELOOP。O_TMPFILE:创建没有名字的临时普通文件,参数 pathname 指定目录关闭文件的时候,自动删除文件。O_TRUNC:如果文件已经存在,是普通文件并且访问模式允许写,那么把文件截断到长度为0。
文件状态标志包括如下:
APPEND:使用追加模式打开文件,每次调用 write 写文件的时候写到文件的末尾。O_ASYNC:启用信号驱动的输入输出,当输入或输出可用的时候,发送信号通知进程,默认的信号是 SIGIO。O_DIRECT:直接读写存储设备,不使用内核的页缓存。虽然会降低读写速度, 但是在某些情况下有用处,例如应用程序使用自己的缓冲区,不需要使用内核的页缓存文件。DSYNC:调用 write 写文件时,把数据和检索数据所需要的元数据写回到存储设备LARGEFILE:允许打开长度超过 4 GB 的大文件。NOATIME:调用 read 读文件时,不要更新文件的访问时间。O_NONBLOCK:使用非阻塞模式打开文件, open 和以后的操作不会导致调用进程阻塞。PATH:获得文件描述符有两个用处,指示在目录树中的位置以及执行文件描述符层次的操作。 不会真正打开文件,不能执行读操作和写操作。O_SYNC:调用 write 写文件时,把数据和相关的元数据写回到存储设备。
参数 mode:
参数 mode 指定创建新文件时的文件模式。当参数 flags 指定标志位 O_CREAT 或 O_TMPFILE
的时候,必须指定参数 mode,其他情况下忽略参数 mode。
参数 mode 可以是下面这些标准的文件模式位的组合。
S_IRWXU(0700,以0开头表示八进制):用户(即文件拥有者)有读、写和执行权限。S_IRUSR(00400):用户有读权限。S_IWUSR(00200):用户有写权限S_IXUSR(00100):用户有执行权限。S_IRWXG(00070):文件拥有者所在组的其他用户有读、写和执行权限S_IRGRP(00040):文件拥有者所在组的其他用户有读权限。S_IWGRP(00020):文件拥有者所在组的其他用户有写权限。S_IXGRP(0010):文件拥有者所在组的其他用户有执行权限。S_IRWXO(0007):其他组的用户有读、写和执行权限。S_IROTH(0004):其他组的用户有读权限。S_IWOTH(00002):其他组的用户有写权限。S_IXOTH(00001):其他组的用户有执行权限。
参数 mode 可以包含下面这些 Linux 私有的文件模式位:
S_ISUID(0004000):set-user-ID 位。S_ISGID(0002000):set-group-iD位。S_ISVTX(0001000):粘滞(sticky)位。
以上内容可以参考:open man7手册
那么我们该如何找到对应的 syscall?
有几个小技巧可以用来帮助我们:
- 用户空间的方法xxx,对应系统调用层方法则是 sys_xxx;
- unistd.h 文件记录着系统调用中断号的信息。
- 宏定义 SYSCALL_DEFINEx(xxx,…),展开后对应的方法则是 sys_xxx;
- 方法参数的个数x,对应于 SYSCALL_DEFINEx。
细节可以参考下面给出的链接:Linux系统调用(syscall)原理。
根据第一个小技巧,我们知道我们需要找的函数为:sys_open。
具体代码流程比较复杂,这里使用取巧的方式,找到对应的内核函数,前面提到需要找的的函数
为 sys_open。
这种函数在内核中是通过宏定义 SYSCALL_DEFINEx 展开后得到的。那么可以
利用 source insight 的搜索功能。应用层 open 函数的参数的个数为 3,可以假想先从
SYSCALL_DEFINE3 进行全局搜索。随便选择一个搜索结果,这里假设选择的是
SYSCALL_DEFINE3(mknod,这步主要是为了获取代码格式,把 mknod 改成 open
,然后搜索 SYSCALL_DEFINE3(open。
很快我们就在 kernel\fs\open.c 文件中找到唯一的搜索结果,代码如下:
SYSCALL_DEFINE3
SYSCALL_DEFINE3(open, const char __ user*, filename, int, flags, umode_t, mode)
{
if (force_o_largefile())
flags |= O_LARGEFILE;
return do_sys_open(AT_FDCWD, filename, flags, mode);
}
if (force_o_largefile())
flags |= O_LARGEFILE;
表示 flags 会在 64 位 Kernel 的情况下强制么设置 O_LARGEFILE 来表示支持大文件。
接着跳转到 do_sys_open 函数。
do_sys_open 系统调用主体
long do_sys_open(int dfd, const char __ user *filename, int flags, umode_t mode)
{
struct open_flags op;
//检查并包装传递进来的标志位
int fd = build_open_flags(flags, mode, &op);
struct filename * tmp;
if (fd)
return fd;
//用户空间的路径名复制到内核空间
tmp = getname(filename);
if (IS_ERR(tmp))
return PTR_ERR(tmp);
//获取一个未使用的 fd 文件描述符
fd = get_unused_fd_flags(flags);
if (fd >= 0) {
//调用 do_filp_open 完成对路径的搜寻和文件的打开
struct file * f = do_filp_open(dfd, tmp, &op);
if (IS_ERR(f)) {
//如果发生了错误,释放已分配的 fd 文件描述符
put_unused_fd(fd);
//释放已分配的 struct file 数据
fd = PTR_ERR(f);
} else {
fsnotify_open(f);
//绑定 fd 与 f。
fd_install(fd, f);
}
}
//释放已分配的 filename 结构体。
putname(tmp);
return fd;
}
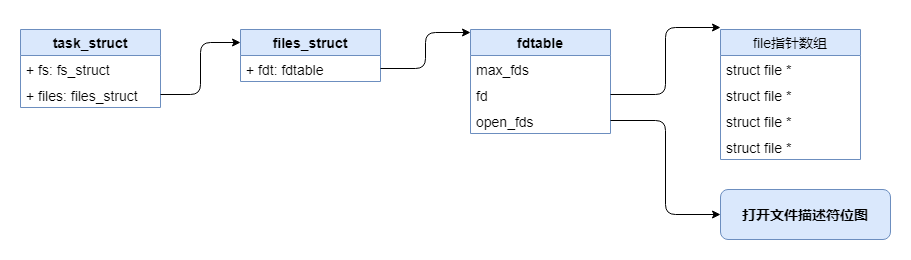
fd 是一个整数,它其实是一个数组的下标,用来获取指向 file 描述符的指针,
每个进程都有个 task_struct 描述符用来描述进程相关的信息,其中有个
files_struct 类型的 files 字段,里面有个保存了当前进程所有已打开文件
描述符的数组,而通过 fd 就可以找到具体的文件描述符,之间的关系可以参考下图:
这里的参数已经在上面提到过了,唯一需要注意的是 AT_FDCWD,其定义在
include/uapi/linux/fcntl.h,是一个特殊值(** -100 **),
该值表明当 filename 为相对路径的情况下将当前进程的工作目录设置为起始路径。相对而言,
你可以在另一个系统调用 openat 中为这个起始路径指定一个目录,
此时 AT_FDCWD 就会被该目录的描述符所替代。
build_open_flags 初始化 flags
static inline int build_open_flags(int flags, umode_t mode, struct open_flags *op)
{
int lookup_flags = 0;
//O_CREAT 或者 `__O_TMPFILE*` 设置了,acc_mode 才有效。
int acc_mode;
// Clear out all open flags we don't know about so that we don't report
// them in fcntl(F_GETFD) or similar interfaces.
// 只保留当前内核支持且已被设置的标志,防止用户空间乱设置不支持的标志。
flags &= VALID_OPEN_FLAGS;
if (flags & (O_CREAT | __ O_TMPFILE))
op->mode = (mode & S_IALLUGO) | S_IFREG;
else
//如果 O_CREAT | __ O_TMPFILE 标志都没有设置,那么忽略 mode。
op->mode = 0;
// Must never be set by userspace
flags &= ~FMODE_NONOTIFY & ~O_CLOEXEC;
// O_SYNC is implemented as __ O_SYNC|O_DSYNC. As many places only
// check for O_DSYNC if the need any syncing at all we enforce it's
// always set instead of having to deal with possibly weird behaviour
// for malicious applications setting only __ O_SYNC.
if (flags & __ O_SYNC)
flags |= O_DSYNC;
//如果是创建一个没有名字的临时文件,参数 pathname 用来表示一个目录,
//会在该目录的文件系统中创建一个没有名字的 iNode。
if (flags & __ O_TMPFILE) {
if ((flags & O_TMPFILE_MASK) != O_TMPFILE)
return -EINVAL;
acc_mode = MAY_OPEN | ACC_MODE(flags);
if (!(acc_mode & MAY_WRITE))
return -EINVAL;
} else if (flags & O_PATH) {
// If we have O_PATH in the open flag. Then we
// cannot have anything other than the below set of flags
// 如果设置了 O_PATH 标志,那么 flags 只能设置以下 3 个标志。
flags &= O_DIRECTORY | O_NOFOLLOW | O_PATH;
acc_mode = 0;
} else {
acc_mode = MAY_OPEN | ACC_MODE(flags);
}
op->open_flag = flags;
// O_TRUNC implies we need access checks for write permissions
// 如果设置了,那么写之前可能需要清空内容。
if (flags & O_TRUNC)
acc_mode |= MAY_WRITE;
// Allow the LSM permission hook to distinguish append
// access from general write access.
// 让 LSM 有能力区分 追加访问和普通访问。
if (flags & O_APPEND)
acc_mode |= MAY_APPEND;
op->acc_mode = acc_mode;
//设置意图,如果没有设置 O_PATH,表示此次调用有打开文件的意图。
op->intent = flags & O_PATH ? 0 : LOOKUP_OPEN;
if (flags & O_CREAT) {
//是否有创建文件的意图
op->intent |= LOOKUP_CREATE;
if (flags & O_EXCL)
op->intent |= LOOKUP_EXCL;
}
//判断查找的目标是否是目录。
if (flags & O_DIRECTORY)
lookup_flags |= LOOKUP_DIRECTORY;
//判断当发现符号链接时是否继续跟下去
if (!(flags & O_NOFOLLOW))
lookup_flags |= LOOKUP_FOLLOW; //查找标志设置了 LOOKUP_FOLLOW 表示会继续跟下去。
//设置查找标志,lookup_flags 在路径查找时会用到
op->lookup_flags = lookup_flags;
return 0;
}
上面的函数主要是根据用户传递进来的 flags 进一步设置具体的标志,然后把这些标志封装到 open_flags 结构体中。以便后续使用。
接下来就是函数 getname() ,这个函数定义在 fs/namei.c,主体是 getname_flags,
我们捡重点的分析,无关紧要的代码以 ... 略过。
getname_flags 复制路径名
struct filename * getname(const char __ user *filename) {
return getname_flags(filename, 0, NULL);
}
struct filename {
const char* name; // pointer to actual string ---指向真实的字符串
const __ user char* uptr; // original userland pointer -- 指向原来用户空间的 filename
struct audit_names* aname;
int refcnt;
const char iname[]; //用来保存 pathname
};
struct filename * getname_flags(const char __ user *filename, int flags, int* empty) {
struct filename* result;
char* kname;
int len;
// 这里一般来说赋值为 NULL。这里主要是针对Linux 审计工具 audit,我们不管。
result = audit_reusename(filename);
// 如果不为空直接返回。
if (result)
return result;
// 通过__getname 在内核缓冲区专用队列里申请一块内存用来放置路径名(filemname 结构体)
result = __getname();
if (unlikely(!result))
return ERR_PTR(-ENOMEM);
//First, try to embed the struct filename inside the names_cache
//allocation
//kname 指向 struct filename 的 iname 数组。
kname = (char*)result->iname;
// 把 filename->name 指向 iname[0],待会 iname 用来保存用户空间传递过来的路径名(filemname 结构体)。
result->name = kname;
//该函数把用户空间的 filename 复制到 iname
len = strncpy_from_user(kname, filename, EMBEDDED_NAME_MAX);
//如果复制失败,释放已分配的 result 并返回错误。
if (unlikely(len < 0)) {
__putname(result);
return ERR_PTR(len);
}
// Uh-oh. We have a name that's approaching PATH_MAX. Allocate a
// separate struct filename so we can dedicate the entire
// names_cache allocation for the pathname, and re-do the copy from
// userland.
// 这里判断用户空间传递过来的路径名的长度接近了 PATH_MAX,所以需要分配一个独立的空间
// 用来保存 struct filename 前面的字段,并把 name_cache 全部空间用来保存路径名 (filename->iname)。
//
// #define PATH_MAX 4096 // 4 kb 大小。
// #define offsetof(TYPE, MEMBER) ((size_t) &((TYPE * )0)->MEMBER)
// #define EMBEDDED_NAME_MAX (PATH_MAX - offsetof(struct filename, iname))
// EMBEDDED_NAME_MAX 指的就是:字段 iname 在 filename 结构体中的偏移。
if (unlikely(len == EMBEDDED_NAME_MAX)) {
// 注意,这里是把 iname[1] 的偏移赋值给了 size。这样 size 的大小包含了 inaem[0]
// 可以用来保存 iname 数组的首地址。
const size_t size = offsetof(struct filename, iname[1]);
// 把旧 result 的首地址赋值给了 kanme。
kname = (char * )result;
// size is chosen that way we to guarantee that
// result->iname[0] is within the same object and that
// kname can't be equal to result->iname, no matter what.
// 分配一个独立空间用来保存 filename,这样就可以把 filename 分离出来。
result = kzalloc(size, GFP_KERNEL);
//分配失败,释放资源并返回错误。
if (unlikely(!result)) {
__putname(kname);
return ERR_PTR(-ENOMEM);
}
// 把原来的 filename 的首地址赋值给新分配的 result。这样就实现了分离。
result->name = kname;
// 把用户空间的 filename 复制到 kname(name_cache 起始地址)。
len = strncpy_from_user(kname, filename, PATH_MAX);
// 原来:
// filename struct(内核空间,用 name_cach 来保存)
// result ---> name_cache-----> name
// uptr
// aname
// .... 复制操作(strncpy_from_user())
// iname <--------------> filename struct(用户空间)
//
// 现在:
// filename struct(内核空间,注意这里是新开独立的空间。)
// result ---> name ------> name_cache <---------------> filename struct(用户空间)
// uptr 复制操作(strncpy_from_user())
// aname
// ....
// iname
// 新分配的 filename 的首地址指向 name_cach,而 name_cach 又保存了用户
// 空间的 filename,所以新的 filename(result) 能间接访问到用户空间的 filename。
// 复制失败,释放资源,返回。
if (unlikely(len < 0)) {
__putname(kname);
kfree(result);
return ERR_PTR(len);
}
// 路径过长,同样返回错误(从这里也可以看出,在 Linux 中路径名的长度不能超过 4096 字节)。
if (unlikely(len == PATH_MAX)) {
__putname(kname);
kfree(result);
return ERR_PTR(-ENAMETOOLONG);
}
}
// 引用计数为 1
result->refcnt = 1;
// The empty path is special.空路径的处理。
if (unlikely(!len)) {
if (empty)
* empty = 1;
// 如果 LOOKUP_EMPTY 没有设置,也就是本次 open 操作的目标不是空路径,但是传递了一个
// 空路径,所以返回错误。
if (! (flags & LOOKUP_EMPTY)) {
//回收资源
putname(result);
return ERR_PTR(-ENOENT);
}
}
// 指向用户空间的 filename
result->uptr = filename;
result->aname = NULL;
audit_getname(result);
return result;
}
struct filename {
const char* name; //pointer to actual string ---指向真实的字符串
const __ user char* uptr; //original userland pointer --- 指向原来用户空间
struct audit_names* aname;
int refcnt;
const char iname[]; //用来保存 pathname
};
首先通过 __getname 在内核缓冲区专用队列里申请一块内存用来放置路径名,其实这块内存就是
一个 4KB 的内存页。这块内存页是这样分配的,在开始的一小块空间放置结构体 struct filename
结构体前面字段的信息,这里我们假设 iname 字段之前的结构使用 struct filename-iname 表示,
之后的空间放置字符串(保存在 iname)。初始化字符串指针 kname,使其指向这个字符串
(iname[])的首地址。然后就是拷贝字符串,返回值 len 代表了 已经
拷贝的字符串长度。如果这个字符串已经填满了内存页剩余空间,就说明该字符串的长度已经大于
4KB - (sizeof(struct filename-iname)了,这时就需要将结构体 struct filename-iname
从这个内存页中分离并单独分配空间,然后用整个内存页保存该字符串。
get_unused_fd_flags 获取 fd
get_unused_fd_flags() 函数用来查找一个可用的 fd(文件描述符)。
int get_unused_fd_flags(unsigned flags)
{
return __alloc_fd(current->files, 0, rlimit(RLIMIT_NOFILE), flags);
}
/*
* allocate a file descriptor, mark it busy.
*/
int __alloc_fd(struct files_struct *files,
unsigned start, unsigned end, unsigned flags)
{
unsigned int fd;
int error;
struct fdtable * fdt;
spin_lock(&files->file_lock);
repeat:
// 通过 files 字段获取 fdt 字段。(该函数考虑了线程竞争,较复杂不展开了。)
fdt = files_fdtable(files);
//从 start 开始搜索
fd = start;
// 进程上一次获取的 fd 的下一个号(fd + 1)保存在 next_fd 中。所以从 next_fd 开始进行查找。
if (fd < files->next_fd)
fd = files->next_fd;
if (fd < fdt->max_fds)
//获取下一个 fd
fd = find_next_fd(fdt, fd);
// N.B. For clone tasks sharing a files structure, this test
// will limit the total number of files that can be opened.
error = -EMFILE;
if (fd >= end)
goto out;
// 获取 fd 后,判断是否需要扩展用来保存 file struct 描述符的数组(fdtable->fd)的容量。
// 返回 0 表示不需要,<0 表示错误,1 表示成功。
error = expand_files(files, fd);
if (error < 0)
goto out;
// If we needed to expand the fs array we
// might have blocked - try again.
// 1,扩容成功,并且重新尝试获取fd
// 因为扩容过程可能会发生阻塞,这期间就有可能其他线程也在获取 fd,所以前面获取的 fd
// 可能被其他线程抢先占用了,因为 Linux 的唤醒是不保证顺序的。
if (error)
goto repeat;
if (start <= files->next_fd)
files->next_fd = fd + 1;
// 在 fdtable->open_fds 位图中置位表示当前获取的 fd 处于使用状态。
// 也就是说当释放该 fd 位图中对应的位清除,从而达到重复使用的的目的。
__set_open_fd(fd, fdt);
// 如果设置了 O_CLOEXEC 标志,那么在 fdtable->close_on_exec 位图对应的位置位。
// 前面提到过开启 close-on-exc 标志,使用系统调用 execve() 装载程序的时候会关闭设置过该标志的文件。
// Linux 中使用 fork() 产生子进程的时候回继承父进程已打开的文件描述符集。execve() 一般就是在子进程
// 里用来运行新程序。
if (flags & O_CLOEXEC)
__set_close_on_exec(fd, fdt);
else
__clear_close_on_exec(fd, fdt);
// 设置返回值。
error = fd;
#if 1
// Sanity check 一些合法性检查。
if (rcu_access_pointer(fdt->fd[fd]) != NULL) {
printk(KERN_WARNING "alloc_fd: slot %d not NULL!\n", fd);
rcu_assign_pointer(fdt->fd[fd], NULL);
}
#endif
out:
spin_unlock(&files->file_lock);
return error;
}
struct fdtable {
unsigned int max_fds;
struct file __ rcu ** fd; // current fd array
unsigned long * close_on_exec;
unsigned long * open_fds;
unsigned long * full_fds_bits;
struct rcu_head rcu;
};
#ifdef CONFIG_64BIT
#define BITS_PER_LONG 64
#else
#define BITS_PER_LONG 32
#endif /* CONFIG_64BIT */
static inline void __set_open_fd(unsigned int fd, struct fdtable *fdt)
{
__set_bit(fd, fdt->open_fds);
fd /= BITS_PER_LONG;
if (!~fdt->open_fds[fd])
__set_bit(fd, fdt->full_fds_bits);
}
这里以 32 位 arm 芯片为例。其中函数 __set_bit 表示以某个地址开始在某个位置 1。
假设我们目前数组的容量为 128 ,那么如下表:共有 4 行,一行 32 列,fd = 32 * row + column。
每个格子中 0 表示当前 fd 没有被占用,1 表示占用了。其中 ... 表示所有的列为 1。
假设我们现在获取的 fd 为 66 也就是第 3 行第 3 列,此时我们可以看到该格子为 0。
调用 __set_bit(fd, fdt->open_fds); 把该位(66)置1,fd /= BITS_PER_LONG; 获取行号
66 / 32 = 2(行号从 0 开始),!~fdt->open_fds[fd], open_fds为 long 类型
指针,也就是说步长为 32 位,相当于取第 3 个 long 数据的值,然后位取反,因为此时该 long 数据
的每一位都置 1 了,所以取反后的值为 0,!0 就为 true 了。此时我们可以确定第 3 行所有的
列都被使用了,所以我们可以把 full_fds_bits 的第 2 位置 1,表示该行已全部被使用。
| 0 | 1 | 2 | ... | 30 | 31 |
|---|---|---|---|---|---|
| 1 | 1 | 1 | ... | 1 | 1 |
| 1 | 1 | 1 | ... | 1 | 1 |
| 1 | 1 | 0 | ... | 1 | 1 |
| 1 | 1 | 1 | ... | 0 | 0 |
接下来看找 fd 函数 find_next_fd() 就很简单了。
static unsigned long find_next_fd(struct fdtable *fdt, unsigned long start)
{
unsigned long maxfd = fdt->max_fds;
// 当前容量最后的一行
unsigned long maxbit = maxfd / BITS_PER_LONG;
// 开始行
unsigned long bitbit = start / BITS_PER_LONG;
// 先找到一个空行(有空闲位的某一行)
bitbit = find_next_zero_bit(fdt->full_fds_bits, maxbit, bitbit) * BITS_PER_LONG;
if (bitbit > maxfd)
return maxfd;
if (bitbit > start)
start = bitbit;
// 在该行上找到一个具体的空位。
return find_next_zero_bit(fdt->open_fds, maxfd, start);
}
尽量以自己的能力对每行代码进行了注释,同时只是为了学习内核大神是如何玩转指针以及数据结构。
可以从 __set_open_fd() 函数看出对指针熟练的使用方式,以及快速定位的思想。
