实现一个 new 操作符
function _new(constructor, ...args) {
// 以构造函数的原型为原型创建一个对象
const obj = Object.create(constructor.prototype)
const result = constructor.call(obj, ...args)
return result instanceof Object ? result : obj;
}
ES5 继承
主要有构造函数继承、原型继承、组合继承
下面是一个组合继承:
function Parent (name) {
this.name = name;
this.colors = ['red', 'blue', 'green'];
}
Parent.prototype.getName = function () {
console.log(this.name)
}
function Child (name, age) {
// 构造函数继承
Parent.call(this, name);
this.age = age;
}
// 原型继承
Child.prototype = Object.create(Parent.prototype);
Child.prototype.constructor = Child;
const child1 = new Child("kevin", '18');
深拷贝
递归版本
const isObject = obj => typeof obj === 'object' && obj !== null
function deepClone(object) {
const result = Array.isArray(object) ? [] : {}
for (const key in object) {
if (isObject(object[key])) {
result[key] = deepClone(object[key])
} else {
result[key] = object[key]
}
}
return result
}
循环版本
箭头函数
- 箭头函数没有自己的 this,它会从父级作用域继承 this
- 箭头函数无法 new,没有 prototype
call apply bind
Function.prototype.call = function(context, ...args) {
const fn = this;
context.__fn = fn;
const result = context.__fn(...args)
delete context.__fn
return result
}
Function.prototype.apply = function(context, args) {
const fn = this;
context.__fn = fn;
const result = context.__fn(...args)
delete context.__fn
return result
}
Function.prototype.bind = function(context, prependArgs) {
const fn = this;
return function (...args) {
return fn.apply(context, prependArgs.concat(args))
}
}
Promise 实现
浏览器地址栏输入到页面渲染
- dns 查询,计算机缓存、路由器缓存 dns 服务器 找到服务器ip
- 建立 tcp 连接,3次握手
- 建立 http 连接,下载并解析 html,css 文件,同时构建 html、css 树,合成渲染树
- 这时如果遇到js文件,会阻塞 dom 的渲染,执行 js 文件,可能引起重流重绘
- 断开 tcp 链接
BFC
BFC 就是块级格式化上下文,它是 css 的渲染模式,可以保证元素内部和外部不相互影响、清除浮动,我们可以通过以下方式创建 BFC:
- float 元素
- 绝对定位
- overflow hidden auto
- display flex
CSS module
什么是逻辑像素,什么是物理像素,设备像素比又是什么?
物理像素指设备显示器最小的物理单位,比如 1900 * 1080 分辨率表示屏幕横向有1900个物理像素,纵向有1080个物理像素 逻辑像素指脱离物理像素抽象出来的一个单位,比如css像素,一般由开发者指定,由底层系统转换为对应的逻辑像素。

引申:
位图和矢量图的区别:

回流 重绘
浏览器采用流式布局 回流:当盒模型发生变化,或者元素的大小、尺寸发生变化。 重绘:当元素样式变化,但不影响它在文档流之中的位置,比如 color background visibility 等。 如何避免回流和重绘:
- 动画使用 css animation
- 频繁变化的元素设置脱离文档流
- 避免频繁操作样式,最好一次性重写style属性,或者将样式列表定义为class并一次性更改class属性。
- 避免频繁的 dom 操作,比如 virtual dom 或者 documentFragment
跨域
跨域是因为浏览器的同源策略,同源策略主要为了规避两种安全问题:
- 跨站请求,CRSF 攻击,钓鱼网站可以伪造成真实站点向后端发起请求,比如支付、购物
- 跨站 dom 访问,其他站点可以访问到你的账号密码输入框
解决方式:
- JSONP img 标签
- CORS
- 代理
- postMessage, 纯前端两个站点之间的通信
cookie 和 storage
- 大小
- 使用方式 API
- 时效 过期时间
- HTTP 请求时,cookie 默认会带上,而 storage 则不会;后端可以通过 set-cookie 操作 cookie值,storage 则不行
浏览器缓存
缓存命中规则:一个请求发起后,会先后检查强缓存和协商缓存。强制缓存优先于协商缓存进行,若强制缓存(Expires和Cache-Control)生效则直接使用缓存,若不生效则进行协商缓存(Last-Modified / If-Modified-Since和Etag / If-None-Match),协商缓存由服务器决定是否使用缓存,若协商缓存失效,那么代表该请求的缓存失效,重新获取请求结果,再存入浏览器缓存中;生效则返回304,继续使用缓存,主要过程如下:
XSS CRSF
XSS:跨站脚本攻击,指攻击者在页面插入恶意脚本脚本,来获取用户信息或者控制页面。原理是利用评论之类的功能注入恶意的 script 脚本,有可能是持久化的。
防范措施:
- 用户输入过滤,script 等
- cookie 设置 httpOnly,防止被恶意脚本获取
CRSF:跨站请求伪造,指攻击者利用受害者的cookie,伪造请求发给服务器。比如,用户访问钓鱼网站,点击伪造按钮,发起请求,默认会当上用户真实站点的cookie,服务器信赖cookie从而请求完成。
防范措施:
- referer 检查,校验请求的来源
- 将 token 渲染到页面上,提交请求时同时发送 cookie 和 token,服务端进行校验
HTTP 加密过程
分为对称加密和不对称加密,HTTPS的加密过程综合了这两种加密算法。
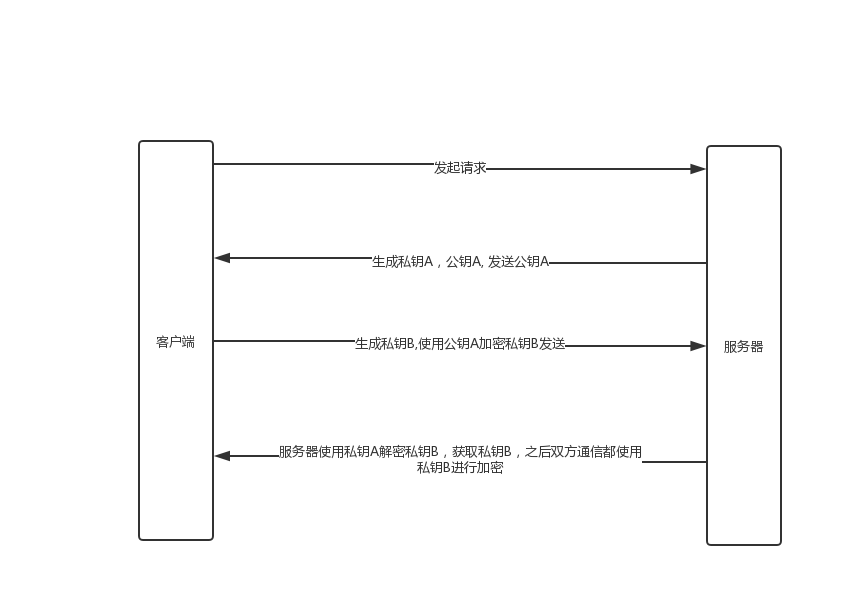
证书: 通信的过程加密还是不够安全的。攻击者可以对客户端伪造成服务器,对服务器伪造成客户端,也就是中间人攻击,抓包攻击 Charles 就是采用这种方式拦截http请求。 因此,我们还要一种手段来验证客户端或者服务器的身份,这就是证书。双方通信时,不仅要使用加密算法机密,还要提交证书,验证双方的合法性,
Session JWT
session:当用户登录后,服务器会把用户的认证信息保存到内存或数据库中,并颁发给客户端存储起来(cookie,storage)。以后每次通信都使用 session 来校验用户身份。 优点:服务器保存,相对安全;可以主动清除 session
缺点:有状态,不好扩展;cookie 可能会被crsf;
JWT:JWT 本质上是时间换空间的思路,服务端通过用户认证后,生成一个 json 对象颁发给客户端,并使用签名加密,以后每次通信都使用这段 json 认证用户身份。
优点:无状态,好扩展 缺点:默认无法清除用户认证状态
树 遍历 堆
递归版 递归版
// 深度遍历
function deepFirstTraversal(node, callback) {
if (node.children) node.children.forEach(child => deepFirstTraversal(child, callback))
callback(node);
}
// 广度遍历
function breadthFirstTraversal(node, callback) {
callback(node);
if (node.children) node.children.forEach(child => breadthFirstTraversal(child, callback))
}
非递归版本
// 深度遍历
function deepFirstTraversal(root, callback) {
// 使用两个栈,使用栈1遍历树入栈2,出栈2的顺序即深度优先遍历
let node = root, nodes = [root], next = [], children, i, n;
// 入栈1
while (node = nodes.pop()) {
// 先入栈1父节点
next.push(node), children = node.children;
// 入栈2子节点
if (children) for (i = 0, n = children.length; i < n; ++i) {
nodes.push(children[i]);
}
}
// 出栈2 nodes
while (node = next.pop()) {
callback(node);
}
return this;
}
// 广度遍历
function breadthFirstTraversal(node, callback) {
const queue = [node]
while(queue.length) {
const current = queue.shift();
callback(current)
if (current.child) {
queue = queue.concat(current)
}
}
}
堆属于二叉树的一种,它的特点:
- 完全二叉树
- 父节点大于等于(或小于等于)子节点,也就是最大堆和最小堆
链表
链表分为单向和双向链表,主要考察链表的新增、删除、查找
排序
主要是归并和快速排序
function quickSort(originalArray) {
// 复制原数组
const array = [...originalArray]
// 数组长度小于1时,已排序
if (array.length <= 1) {
return array
}
const leftArray = []
const rightArray = []
// 选择一个对比元素
const pivotElement = array.shift()
const centerArray = [pivotElement]
while (array.length) {
const currentElement = array.shift()
if (currentElement === pivotElement) {
centerArray.push(currentElement)
} else if (currentElement < pivotElement) {
leftArray.push(currentElement)
} else {
rightArray.push(currentElement)
}
}
// 递归排序左右数组
const leftArraySorted = quickSort(leftArray)
const rightArraySorted = quickSort(rightArray)
return leftArraySorted.concat(centerArray, rightArraySorted)
}
function mergeSort(originalArray) {
// If array is empty or consists of one element then return this array since it is sorted.
if (originalArray.length <= 1) {
return originalArray
}
// Split array on two halves.
const middleIndex = Math.floor(originalArray.length / 2)
const leftArray = originalArray.slice(0, middleIndex)
const rightArray = originalArray.slice(middleIndex, originalArray.length)
// Sort two halves of split array
const leftSortedArray = mergeSort(leftArray)
const rightSortedArray = mergeSort(rightArray)
// Merge two sorted arrays into one.
return mergeSortedArrays(leftSortedArray, rightSortedArray)
}
function mergeSortedArrays(leftArray, rightArray) {
let sortedArray = []
// In case if arrays are not of size 1.
while (leftArray.length && rightArray.length) {
let minimumElement = null
// Find minimum element of two arrays.
if (leftArray[0] < rightArray[0]) {
minimumElement = leftArray.shift()
} else {
minimumElement = rightArray.shift()
}
// Push the minimum element of two arrays to the sorted array.
sortedArray.push(minimumElement)
}
// If one of two array still have elements we need to just concatenate
// this element to the sorted array since it is already sorted.
if (leftArray.length) {
sortedArray = sortedArray.concat(leftArray)
}
if (rightArray.length) {
sortedArray = sortedArray.concat(rightArray)
}
return sortedArray
}
virtual dom
diff 算法
- 深度遍历新旧树,生成 patch
- 列表 diff,新增 删除 替换 移动
双向绑定
发布订阅
路由原理
主要靠 hash 和 history API
react fiber 架构
说 fiber 之前,有两点前置知识
- js 和 浏览器渲染 线程互斥
- 人眼最多识别30帧,为了保持渲染的流畅,至少要保证 33 ms 渲染一次
fiber 产生的原因在于:当 virtual dom 树非常大时,整个 diff 的过程超过了 30 ms,大量的 js 运算阻塞了渲染线程,浏览器无法正常响应用户的交互行为。
fiber 架构引入了分片机制,可以让一个 diff 可暂停,给浏览器渲染和响应交互的时间,再继续之前 diff 的流畅。
引申:CPU 时间分片
debounce 和 throttle
// 一定时间间隔内,重复调用函数会取消之前的调用,场景:输入框搜索
function debounce(fn, timeout) {
let timer;
return function (...args) {
if (timer) {
clearTimeout(timer)
}
timer = setTimeout(() => {
fn.call(this, ...args)
timer = null
}, timeout);
}
}
// 限制函数调用的频率,一定时间间隔内只能调用一次,场景:滚动事件监听
function throttle(fn, timeout) {
let timer;
return function (...args) {
if (timer) return
timer = setTimeout(() => {
fn.call(this, ...args)
timer = null
}, timeout);
}
}
Promise.all Promise.race Promise.finally
Promise.prototype.finally = function(callback) {
return this.then(
value => Promise.resolve(callback).then(() => value),
reason => Promise.reject(callback).catch(() => {
throw reason;
}),
)
}
Promise.prototype.race = function(ps) {
return new Promise((resolve, reject) => {
ps.forEach(p => p.then(resolve, reject));
})
}
Promise.prototype.all = function(ps) {
return new Promise((resolve, reject) => {
const next = gen(ps.length, resolve)
ps.forEach((p, index) => p.then(value => {
next(index, value)
}, reject));
})
}
function gen(length, resolve) {
let i = 0;
const values = []
return function(index, value) {
values[index] = value
if (++i === length) {
resolve(values)
}
}
}
循环引用检测
function isCyclic(obj) {
// 存储已遍历的对象
const seenObjects = [];
// object 树按广度优先顺序推入数组
function detect(object) {
if (object && typeof object === 'object') {
if (seenObjects.indexOf(object) !== -1) {
return true;
}
seenObjects.push(object);
// 递归遍历子节点
for (const key in object) {
if (object.hasOwnProperty(key) && detect(object[key])) {
return true;
}
}
}
return false;
}
return detect(obj);
}
前端性能优化
性能优化是一块比较零碎的知识,借助一些分类我们可以将其体系化
网络层
- http2 有时搞了半天性能优化还不如升级个协议
- 请求数量 静态资源、压缩,critical css,精灵图,懒加载
- 请求大小 静态资源压缩 gzip
- 缓存 service worker,强缓存和协商缓存、CDN
加载时
- 避免 js 脚本阻塞页面渲染
运行时
- 减少回流重绘 virtual dom,BFC,css3硬件加速
- 页面卡顿 惰性计算,Fiber 异步渲染
- 内存泄露 闭包 定时器 释放 dom 节点引用
性能优化的前提是方向,了解应用性能的瓶颈在哪里,需要性能数据的支撑。
设计模式
- 发布订阅 Vue响应式原理 浏览器事件
- 观察者 redux 中
store.subscribe方法 - 生产消费 react 中
Provider和Consumer - 单例 redux 中的单 store
- 装饰器 面向切片吧编程 redux 中
@connect,@withRouter - 工厂模式 高阶函数可以看做工厂模式的变体,比如一个高阶函数根据参数返回不同作用的函数
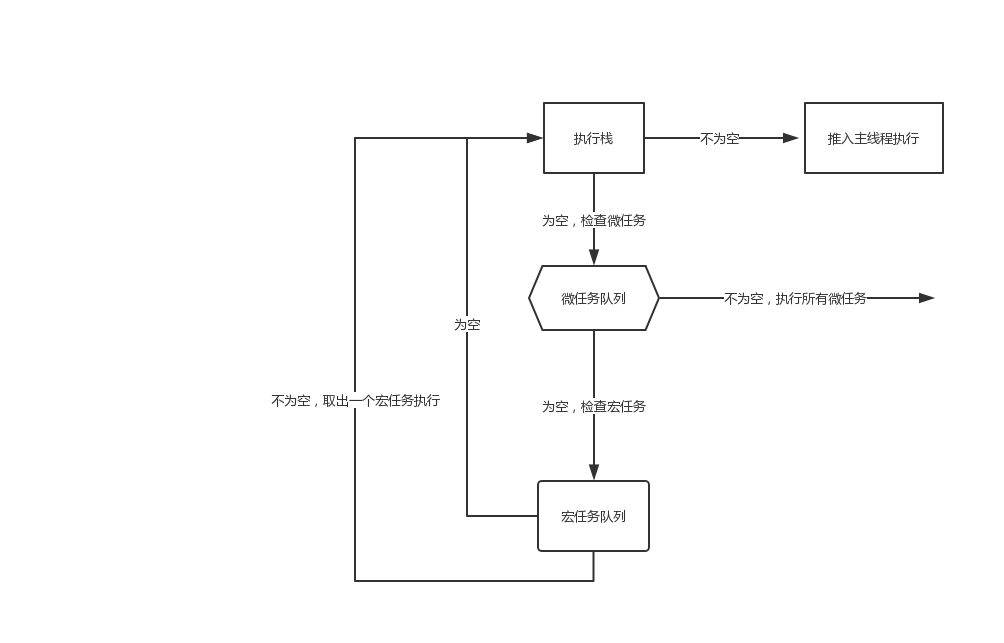
事件循环