

写在前面:正式因为经历了去年的秋招,才知道秋招有多难过,把一些经历过的一些面试题和笔试题整理一下,还有一些设计特别巧妙的题,希望可以帮助到大家总结回顾一下。还有一些回答是之前在网上的资料里面借鉴的,时间太久了也就忘了,原作者看到了麻烦告诉我!
还有蛮多题会慢慢更新。敬请期待!
Javascript
函数、模块作用域,面向对象(类、继承)、Promise是大家应该关注的点,也是面试经常问到的。
- [函数作用域]以下代码运行的结果是怎样的?
请说出结果并说明原因。
var a = 5
var b = 6
function test(){
var a = 7,
b = 8
console.log({a,b}) //7,8
}
test()
console.log({a,b}) //5,8
作用域的问题。
- [函数作用域]请举例描述const与var的不同?
const声明一个只读的常量。一旦声明,常量的值就不能改变。const定义的变量不会提升,var 定义的变量会提升。对于const来说,只声明不赋值,就会报错。const的作用域与let命令相同:只在声明所在的块级作用域内有效。 ES6新增的const关键字可以用来声明常量,但是它只对基本数据类型生效(Number、String、Boolean等)
const a=8;
a=10;
//Uncaught SyntaxError: Identifier 'a' has already been declared at <anonymous>:1:1
var c=10;
c=17;
console.log(c)//17
- [函数作用域、闭包]闭包是什么?什么场景下我们需要闭包?
阮一峰是这么说的:闭包就是将函数内部和函数外部连接起来的一座桥梁。
具体的表现是:当一个函数的返回值是另外一个函数,而返回的那个函数如果调用了其父函数内部的其他值,而且返回的这个函数在外部被执行,就产生了闭包。 创建闭包的常见方式,就是在一个函数内部创建另外一个函数。 提问到闭包的时候,一定要联系到作用域!!!!
具体见下面的链接:www.ruanyifeng.com/blog/2009/0…
其他书籍上面的定义是这样的:
《JavaScript 高级程序设计》:闭包是指有权访问另一个函数作用域中的变量的函数
《JavaScript 权威指南》:从技术的角度讲,所有的 JavaScript 函数都是闭包:它们都是对象,它们都关联到作用域链。
《你不知道的 JavaScript》:函数可以记住并访问所在的词法作用域时,就产生了闭包,即使函数是在当前词法作用域之外执行。
MDN上面有更加具体的例子和解释: developer.mozilla.org/zh-CN/docs/…
-
JS中的继承 github.com/ljianshu/Bl…
-
js中基本数据类型和引用数据类型的存储位置?
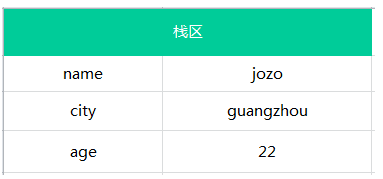
1.基本数据类型都是一些简单的数据段,它们是存储在栈内存中 例如下面:
var name = jozo;
var city = guangzhou;
var age = 22;
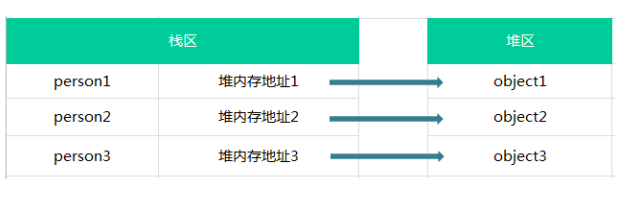
2.引用类型的存储需要内存的栈区和堆区共同完成,栈区内存保存变量标识符和指向堆内存中该对象的指针。
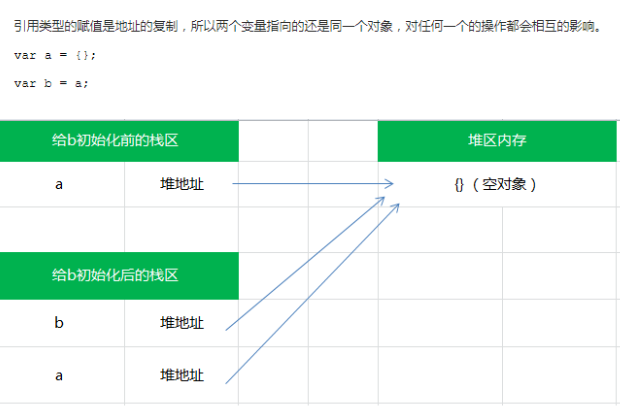
3.引用类型的复制就是地址的复制而已,对其中一个变量进行改变的话另外一个也会受到影响。
-
[异步逻辑]请实现一个函数,返回一个会延迟若干毫秒后resolve的Promise
function setTime(){ return new Promise((resolve,reject) => { setTimeout(resolve,600,'hhhhh'); }) } setTime().then((data) => console.log(data)); -
简述冒泡和捕获的区别,代码实现DOM绑定屏幕触摸开始事件,简述冒泡和捕获的区别。
事件冒泡:在p元素上发生click事件的顺序应该是p -> div -> body -> html -> document->window
事件捕获:p元素上发生click事件的顺序应该是window->document -> html -> body -> div -> p
DOM事件模型:事件捕获,时间冒泡。
DOM2级事件的事件流包括:事件捕获阶段,处于目标阶段,事件冒泡阶段。
-
abc.html?a=1&b=jq](abc.html/?a=1&b=jq 中如何得到a和b的值
第一种解决方案
function getQueryStringArgs(){
//取得查询字符串并去掉开头的问号
var qs = (location.search.length>0) ? location.search.substring(1) : "");
//保存数据的对象
var arg2 = {};
//取得每一项
var items = qs.length ? qs.split("&") : [];
var item=null, name=null, value=null;
for(var i=0;i<items.length;i++){
item = items[i].split("=");
name = decodeURIComponent(item[0]);
value = decodeURIComponent(item[1]);
if(name.length) args[name]=value;
}
return args;
}
第二种解决方案
function GetQueryString(name) {
var reg = new RegExp("(^|&)" + name + "=([^&]*)(&|$)","i");
var r = window.location.search.substr(1).match(reg);
if (r!=null) return (r[2]); return null;
}
alert(GetQueryString("参数名"));
- [接口]是否了解LocalStorage、IndexedDB、WebSocket、WebGL、WebRTC、WebAssembly等?
- JSONP如何让服务器信任,才能使服务器发送东西给他。
- HTTP和浏览器缓存
- 小程序和VUE有什么相同之处
- 什么是ajax?
- webpack的性能优化
- 输入URL到呈现页面的过程
- 如何避免JS阻塞
- HTTP状态码中304是什么意思
- 前端常见的安全问题 XSS CSRF
- 说一说VUE给你的感觉
- WEBPACK做了什么
- HTTP请求的组成
- 闭包的应用场景
- 垃圾回收机制
- HTTP1.0与HTTP2.0的区别
- 如何减少repaint的频率
- WEBPACK的Loader做了什么
CSS
-
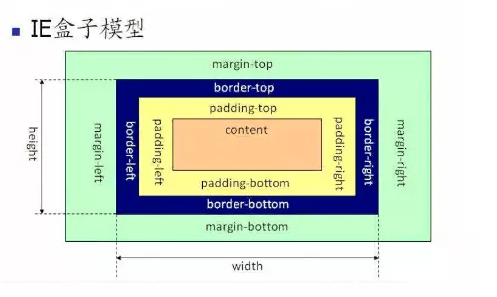
[CSS]简述两种盒模型的区别
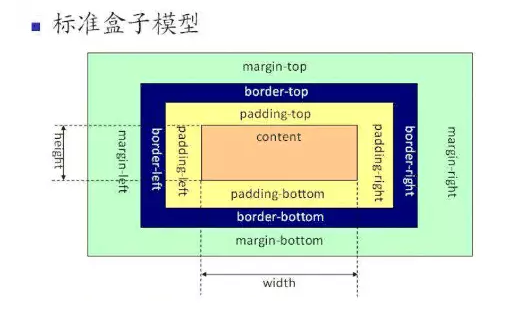
-
[CSS]在一个元素上,一个样式属性的样式定义优先级关系是怎样的?
层叠优先级是:
浏览器缺省 < 外部样式表 < 内部样式表 < 内联样式 其中样式表又有:
类选择器 < 类派生选择器 < ID选择器 < ID派生选择器
-
[CSS]BFC,IFC,FFC,GFC布局
Formatting context 是 W3C CSS2.1 规范中的一个概念。它是页面中的一块渲染区域,并且有一套渲染规则,它决定了其子元素将如何定位,以及和其他元素的关系和相互作用。
BFC(块级格式化上下文)
按照上面来讲,BFC就是决定这个块级元素应该如何渲染的规则。跟外面的没有关系。
- 如何产生BFC?(产生了BFC之后这个容器里面的元素就会按照BFC的规则来渲染,与其他盒子产生隔离,不会被影响到)
- 根元素
- float属性不为none
- position为absolute或fixed
- display为inline-block, table-cell, table-caption, flex, inline-flex
- overflow不为visible
渲染规则一:BFC区域不会跟float元素重叠
看例子:粉红色的被遮住了!!

利用BFC区域不会跟float元素重叠的特性,我们给粉红色的块加上一个overflow:hidden,就让他变成了BFC,所以就不会被红色的压在下面了
渲染规则二:计算元素高度时,浮动元素也会参与计算
一般情况下,父元素的两个子元素都是浮动的话,就会出现高度塌陷的问题,可以看到,我们父元素par设置边框,但是塌陷了,并没有把两个子元素套起来。

渲染规则三:两个BFC区域之间是不会发生边距重叠的


IFC(Inline Formatting Contexts)直译为"内联格式化上下文",IFC的line box(线框)高度由其包含行内元素中最高的实际高度计算而来(不受到竖直方向的padding/margin影响)
FFC(flex格式化上下文)
FFC(Flex Formatting Contexts)直译为"自适应格式化上下文",display值为flex或者inline-flex的元素将会生成自适应容器(flex container)。
GFC(gird格式化上下文)
GFC(GridLayout Formatting Contexts)直译为"网格布局格式化上下文",当为一个元素设置display值为grid的时候,此元素将会获得一个独立的渲染区域,我们可以通过在网格容器(grid container)上定义网格定义行(grid definition rows)和网格定义列(grid definition columns)属性各在网格项目(grid item)上定义网格行(grid row)和网格列(grid columns)为每一个网格项目(grid item)定义位置和空间。
MVVM
工具使用
必须有webpack了,当然gulp、gurant也有他们的空间,文档工具(jsdoc)、lint工具(eslint)、测试工具(jest、selenium、puppeteer)也都是工具,还有TypeScript这种比较特别的,他们有的优化你的结果,有的优化你的生产过程,当然了都不会用也一样可以写代码。
安全
虽然网络安全大多是后端同学的事情,对于前端,还是需要对JS、浏览器之类,网络安全、网络协议、算法结构等知识要有一定程度的了解。
-
HTTPS为什么比HTTP安全?
HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
-
关于http1.0和http1.1的区别?
HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较为简单的网页上和网络请求上,而HTTP1.1则在1999年才开始广泛应用于现在的各大浏览器网络请求中,同时HTTP1.1也是当前使用最为广泛的HTTP协议。
主要区别主要体现在:
-
缓存处理,在HTTP1.0中主要使用header里的If-Modified-Since,Expires来做为缓存判断的标准,HTTP1.1则引入了更多的缓存控制策略例如Entity tag,If-Unmodified-Since, If-Match, If-None-Match等更多可供选择的缓存头来控制缓存策略。
-
带宽优化及网络连接的使用,HTTP1.0中,存在一些浪费带宽的现象,例如客户端只是需要某个对象的一部分,而服务器却将整个对象送过来了,并且不支持断点续传功能,HTTP1.1则在请求头引入了range头域,它允许只请求资源的某个部分,即返回码是206(Partial Content),这样就方便了开发者自由的选择以便于充分利用带宽和连接。
-
错误通知的管理,在HTTP1.1中新增了24个错误状态响应码,如409(Conflict)表示请求的资源与资源的当前状态发生冲突;410(Gone)表示服务器上的某个资源被永久性的删除。
-
Host头处理,在HTTP1.0中认为每台服务器都绑定一个唯一的IP地址,因此,请求消息中的URL并没有传递主机名(hostname)。但随着虚拟主机技术的发展,在一台物理服务器上可以存在多个虚拟主机(Multi-homed Web Servers),并且它们共享一个IP地址。HTTP1.1的请求消息和响应消息都应支持Host头域,且请求消息中如果没有Host头域会报告一个错误(400 Bad Request)。
-
长连接,HTTP 1.1支持长连接(PersistentConnection)和请求的流水线(Pipelining)处理,在一个TCP连接上可以传送多个HTTP请求和响应,减少了建立和关闭连接的消耗和延迟,在HTTP1.1中默认开启Connection: keep-alive,一定程度上弥补了HTTP1.0每次请求都要创建连接的缺点。
-
-
HTTP和HTTPS的主要区别
-
HTTPS协议需要到CA申请证书,一般免费证书很少,需要交费。
-
HTTP协议运行在TCP之上,所有传输的内容都是明文,HTTPS运行在SSL/TLS之上,SSL/TLS运行在TCP之上,所有传输的内容都经过加密的。
-
HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
-
HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
-
-
一些数据结构在实际项目中的应用
队列:js有一个异步队列,将一些异步操作(setTimeout,addEventListener)等等会先放大异步队列中,等到主线程的程序执行完毕,再去执行队列里面的任务
树:用树去表达层级关系;用搜索树、红黑树等结构优化查询,虽然效率不及hash表但更有结构化 hash表: 能够直接定位到具体的数据,在大量资源存在的情况下可以使用这个方法快速定位资源 栈:很多时候都用到,表达式匹配啊
