

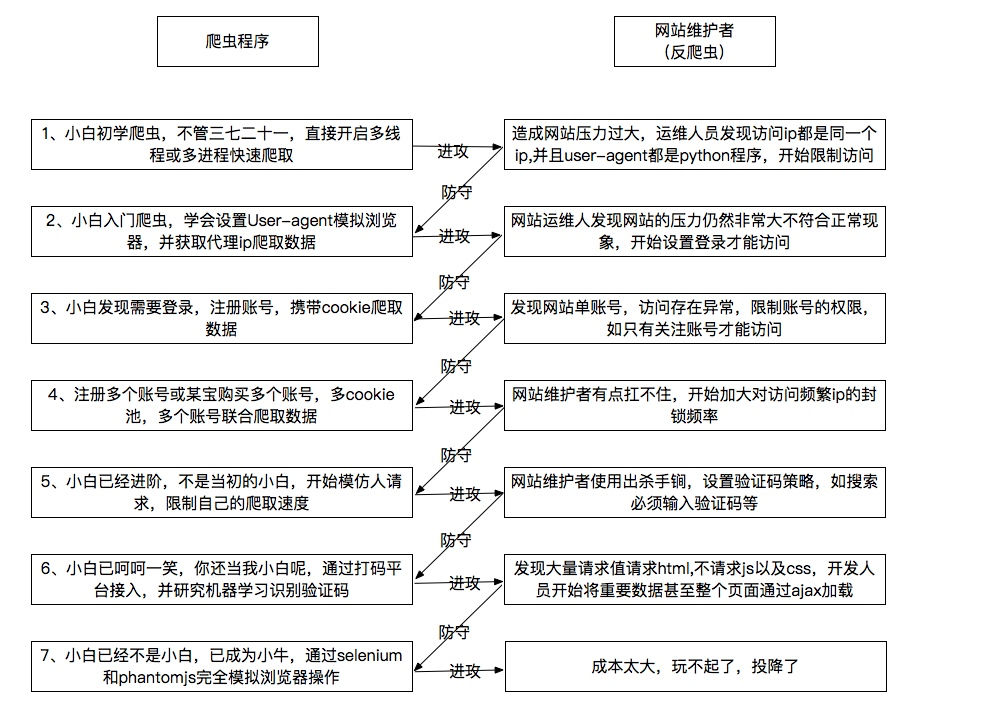
先来看一张图了解下爬虫
实现功能
- 多线程爬取拉勾网招聘信息
- 维护代理 ip 池
- 搭建 node 服务器
- Taro 使用 echarts 做数据分析
1、多线程爬取拉勾网招聘信息
Tip:涉及知识
1.Python3 基础语法 菜鸟教程
2.requests 模块 快速上手
3.Mongodb 数据库 快速安装
4.pymongo 的使用 快速上手
5.线程池 concurrent 快速上手
首先我们先了解下什么是爬虫,看下百度百科的定义
网络爬虫(又被称为网页蜘蛛,网络机器人,在 FOAF 社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
简单来说就是按照一定规则来抓取内容
抓取什么内容?
我们的目的是抓取拉勾网的招聘信息。 拉勾网武汉站 Python 招聘信息
ok,明白了我们要抓取的数据,下一步就是要找数据的来源了。
我们通过点击下一页观察浏览器控制台,发现每次点击下一页时都有一个新的请求
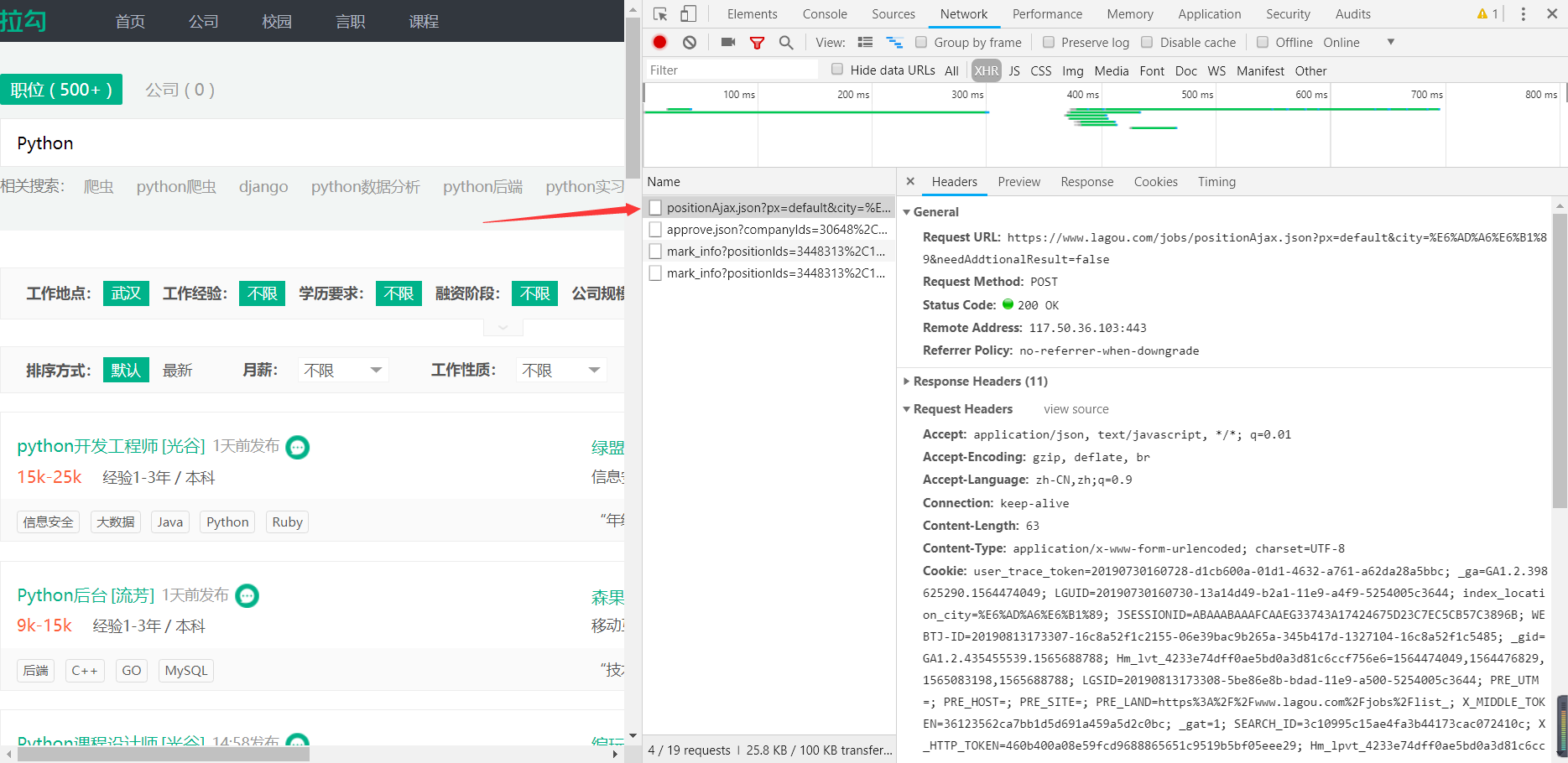 我们发现这个请求正是招聘数据的来源,这样只要我们之间请求这个接口就可以得来数据了。
于是我们快速的写出来下面的代码
我们发现这个请求正是招聘数据的来源,这样只要我们之间请求这个接口就可以得来数据了。
于是我们快速的写出来下面的代码
import requests
# 请求参数
data = {
'first': False, # 这个参数固定可以写False
'pn': 2, # pn表示页码
'kd': 'Python' # kd表示搜索关键测
}
# 发送post请求
response = requests.post(
'https://www.lagou.com/jobs/positionAjax.json?px=default&city=武汉&needAddtionalResult=false', data=data)
# 编码
response.encoding = 'utf-8'
# 获取json
res = response.json()
print(res)
运行后得到以下结果
{ "status": False, "msg": "您操作太频繁,请稍后再访问", "clientIp": "59.xxx.xxx.170", "state": 2408 }
为什么我们请求得到的结果和网页中返回的结果不一样呢?
再回到控制台看看这个请求,发现是需要携带 cookie 的,ok,那我们加上 cookie。可是 cookie 是从哪里来的,总不能写死吧。
我们先把浏览器的 cookie 清除以下(控制台-Application-Cookies 点击清除),然后再刷新下页面,发现了 cookie 的来源
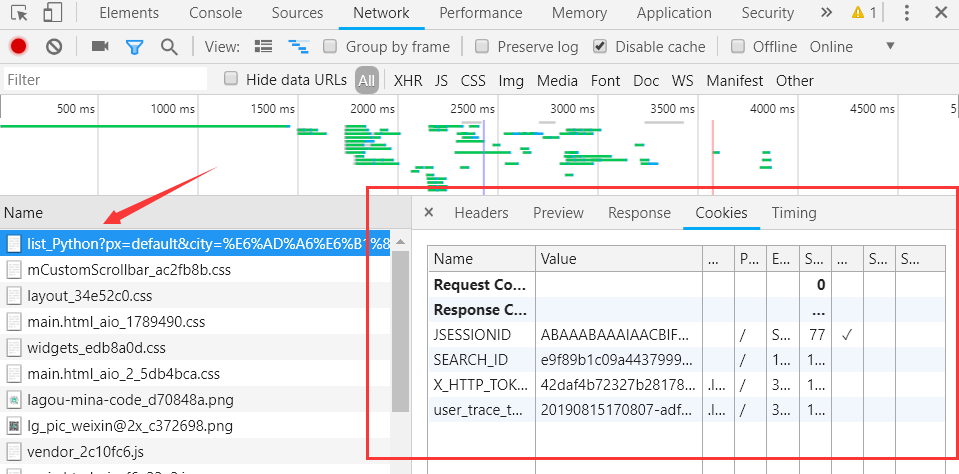
ok,那我们先获取 cookie,再去请求接口
import requests
response = requests.get(
'https://www.lagou.com/jobs/list_Python?px=default&city=%E6%AD%A6%E6%B1%89')
response.encoding = 'utf-8'
print(response.text)
运行发现返回内容中有这么一句
<div class="tip">当前请求存在恶意行为已被系统拦截,您的所有操作记录将被系统记录!</div>
我擦,什么,怎么会被拦截了~
这个时候我们再想想最前面的一张图,这个网站不会就是有 User-Agent 验证吧
不管,先加上 User-Agent 再试试
import requests
# 新增了User-Agent请求头
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"
}
response = requests.get(
'https://www.lagou.com/jobs/list_Python?px=default&city=%E6%AD%A6%E6%B1%89', headers=headers)
response.encoding = 'utf-8'
print(response.text)
惊奇的发现正常了,返回结果正常了!!!
既然正常了,那我们就获取 cookie 再去请求接口了
import requests
UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"
def getCookie():
'''
@method 获取cookie
'''
global UserAgent
response = requests.get('https://www.lagou.com/jobs/list_Python?px=default&city=%E6%AD%A6%E6%B1%89', headers={
"User-Agent": UserAgent
})
# 获取的cookie是字典类型的
cookies = response.cookies.get_dict()
# 因为请求头中cookie需要字符串,将字典转化为字符串类型
COOKIE = ''
for key, val in cookies.items():
COOKIE += (key + '=' + val + '; ')
return COOKIE
# 请求头
headers = {
"Cookie": getCookie()
}
print(headers)
# 请求数据
data = {
'first': False, # 这个参数固定可以写False
'pn': 2, # pn表示页码
'kd': 'Python' # kd表示搜索关键测
}
response = requests.post(
'https://www.lagou.com/jobs/positionAjax.json?px=default&city=武汉&needAddtionalResult=false', data=data, headers=headers)
# 编码
response.encoding = 'utf-8'
# 获取json
res = response.json()
print(res)
这下总该成功然后数据了吧,然后就发现...
尼玛,这么坑,怎么返回结果还是您操作太频繁,请稍后再访问
沉住气,再看看请求头
把其他请求头全加上试试
# 把headers改成这样
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Connection": "keep-alive",
"Host": "www.lagou.com",
"Referer": 'https://www.lagou.com/jobs/list_Python?px=default&city=%E6%AD%A6%E6%B1%89',
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": UserAgent,
"Cookie": getCookie()
}
运行之后就成功抓取到数据了。
到这里我们就已经成功的抓取了一页的数据,然后我们就要抓取多页啦。。。
考虑到抓取数据较多,可以采用多线程的方式来提高效率,同时应该将数据存到数据库去(这里使用 Mongodb 数据库,其他数据库一样的道理)
爬虫完成代码
import requests
from pymongo import MongoClient
from time import sleep
# 连接数据库
client = MongoClient('127.0.0.1', 27017)
db = client.db # 连接mydb数据库,没有则自动创建
# 请求头的cookie和UserAgent
COOKIE = ''
UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"
# 武汉
city = '%E6%AD%A6%E6%B1%89'
# 获取cookie
def getCookie(key_world):
global COOKIE, UserAgent, city
data = requests.get('https://www.lagou.com/jobs/list_' + key_world + '?px=default&city=' + city, headers={
"User-Agent": UserAgent
})
cookies = data.cookies.get_dict()
COOKIE = ''
for key, val in cookies.items():
COOKIE += (key + '=' + val + '; ')
# 请求数据接口
def getList(page, key_world):
global COOKIE, UserAgent
data = {
"first": "false",
"pn": page + 1,
"kd": key_world == 'web' and '前端' or key_world
}
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Connection": "keep-alive",
"Host": "www.lagou.com",
"Referer": 'https://www.lagou.com/jobs/list_' + key_world + '?px=default&city=' + city,
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": UserAgent,
"Cookie": COOKIE
}
response = requests.post(
'https://www.lagou.com/jobs/positionAjax.json?px=default&city=武汉&needAddtionalResult=false', data=data, headers=headers)
response.encoding = 'utf-8'
res = response.json()
return res
# 抓取数据
def getData(key_world):
global COOKIE, UserAgent, client, db
print('开始抓取'+key_world)
# 前端需要转为web
if key_world == '%E5%89%8D%E7%AB%AF':
table = db.web # 连接mydb数据库,没有则自动创建
else:
table = db[key_world] # 连接mydb数据库,没有则自动创建
# 因为请求接口需要cookie,先获取cookie
getCookie(key_world)
# 抓取数据
for page in range(1, 100):
# 请求数据
res = getList(page, key_world)
# 如果请求成功存入数据库中
if res['msg'] == None:
print('成功')
# 工作岗位
position = res['content']['positionResult']['result']
# 记录当前的数据
one_data = []
for idx, item in enumerate(position):
one_data.append({
'positionName': item['positionName'],
'workYear': item['workYear'],
'salary': item['salary'],
'education': item['education'],
'companySize': item['companySize'],
'companyFullName': item['companyFullName'],
'formatCreateTime': item['formatCreateTime'],
'positionId': item['positionId']
})
# 没有数据了
if len(one_data) == 0:
break
# 存储当前数据
table.insert_many(one_data)
else:
print('失败')
# 写日志
with open('./log.txt', 'a', -1, 'utf-8') as f:
f.write(str(res))
f.write('\n')
# 重新获取cookie
getCookie(key_world)
# 再爬取当页数据
res_once = getList(page, key_world)
# 工作岗位
position_once = res_once['content']['positionResult']['result']
# 记录当前的数据
one_data = []
for idx, item in enumerate(position_once):
one_data.append({
'positionName': item['positionName'],
'workYear': item['workYear'],
'salary': item['salary'],
'education': item['education'],
'companySize': item['companySize'],
'companyFullName': item['companyFullName'],
'formatCreateTime': item['formatCreateTime']
})
# 没有数据了
if len(one_data) == 0:
print(key_world + '存入成功')
# 这里用新cookie获取数据还是被限制了,获取不到,这里暂时先休眠60秒,等后面有代理ip池再使用代理ip来解决这个问题
sleep(60)
return
# 存储当前数据
table.insert_many(one_data)
print(key_world + '存入成功')
sleep(60)
# 抓取的数据搜索关键词, 前面的示例是Python,这里抓取多个类型的
key_worlds = ['Python', 'Java', 'PHP', 'C', 'C++', 'C#']
# 开始抓取数据
for idx, key_world in enumerate(key_worlds):
getData(key_world)
目前还需要解决的两个问题,等有了代理 ip 池再解决。
1.未使用多线程
2.还是会存在封 ip 的情况,需要使用代理
2、维护代理 ip 池
Tip:涉及知识
1.之前的所有知识
2.xpath 解析模块 lxml 快速上手
维护一个 ip 池大致分为两步
1.抓取网上免费代理存到数据库
2.筛选出数据库中的有效代理
看到这里相信你已经知道爬虫的运行原理。维护一个自己 ip 池其实也就是一个定时爬虫不停的去爬取网上免费的代理
先完成第一步, 抓取网上免费代理存到数据库
我们这里爬取 西拉免费代理 IP
老套路,先把网页抓下来,再提取我们想要的内容
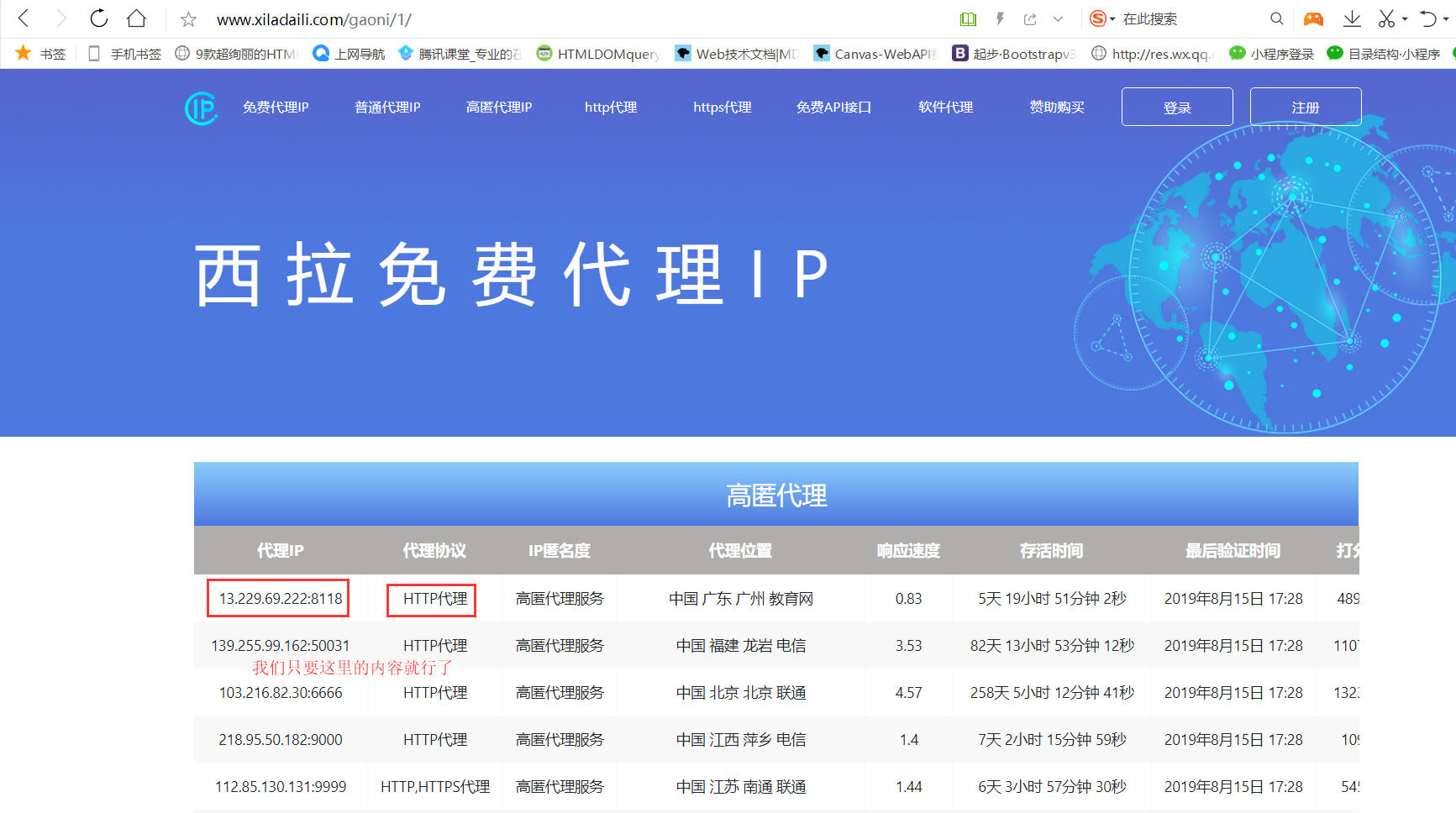
先抓数据
import requests
response = requests.get('http://www.xiladaili.com/gaoni/1/')
response.encoding = 'utf-8'
print(response.text)
运行起来就发现已经把所有的内容都抓下来了,很显然这个网站没有反爬虫。
再提取数据 xPath 怎么获取看这里
import requests
from lxml import etree # xpath解析模块
response = requests.get('http://www.xiladaili.com/gaoni/1/')
response.encoding = 'utf-8'
# print(response.text)
s = etree.HTML(response.text)
# 所有的ip
'''
第一条xpath /html/body/div[1]/div[3]/div[2]/table/tbody/tr[1]/td[1]
第二条xpath /html/body/div[1]/div[3]/div[2]/table/tbody/tr[2]/td[1]
所有的xpath就是把选择tr的部分去掉
/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[1]
'''
ips = s.xpath('/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[1]/text()')
# 所有的请求代理协议
types = s.xpath('/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[2]/text()')
print(ips)
print(types)
这样我们就提取了我们需要的内容了,再把需要的内容存到数据库
import requests
from lxml import etree # xpath解析模块
from pymongo import MongoClient
# 数据库连接
client = MongoClient('127.0.0.1', 27017)
db = client.ip # 连接ip数据库,没有则自动创建
table = db.table # 使用table集合,没有则自动创建
response = requests.get('http://www.xiladaili.com/gaoni/1/')
response.encoding = 'utf-8'
s = etree.HTML(response.text)
# 所有的ip
ips = s.xpath('/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[1]/text()')
# 所有的请求代理协议
types = s.xpath('/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[2]/text()')
# 存储到数据库
for index, ip in enumerate(ips):
host = ip.split(':')[0]
port = ip.split(':')[1]
table.insert_one({"ip": host, "port": port, "type": types[index]})
前面我们只爬取了一页,最后就改用多线程来爬取多页数据
import requests
from lxml import etree # xpath解析模块
from pymongo import MongoClient
from concurrent.futures import ThreadPoolExecutor # 线程池
# 数据库连接
client = MongoClient('127.0.0.1', 27017)
db = client.ip # 连接mydb数据库,没有则自动创建
table = db.table # 使用test_set集合,没有则自动创建
spider_poll_max = 5 # 爬虫线程池最大数量
spider_poll = ThreadPoolExecutor(
max_workers=spider_poll_max) # 爬虫线程池 max_workers最大数量
# 爬取单页数据
def getIp(page):
response = requests.get('http://www.xiladaili.com/gaoni/' + str(page + 1)+'/')
response.encoding = 'utf-8'
s = etree.HTML(response.text)
# 所有的ip
ips = s.xpath('/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[1]/text()')
# 所有的请求代理协议
types = s.xpath('/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[2]/text()')
print(ips)
print(types)
# 存储到数据库
for index, ip in enumerate(ips):
host = ip.split(':')[0]
port = ip.split(':')[1]
table.insert_one({"ip": host, "port": port, "type": types[index]})
# 爬取10页
for page in range(0, 10):
# 添加一个线程
spider_poll.submit(getIp, (page))
还存在的问题
1.还是会存在封 ip 的情况,需要使用代理
抓取 ip 完成了,现在到了验证 ip 的步骤了
再完成第二步,筛选出数据库中的有效代理 我们之前在数据库中创建了一个叫 table 的集合(表),用来存贮所有抓取的 ip(并未有效性检测),再这里我们要专门准备一个叫 ip 的集合,用来存有效 ip。
有效 ip 的检测也分为两步,第一:将 ip 表中的失效代理删除,第二:将 table 表中的有效代理存到 ip 表中。
import requests
from pymongo import MongoClient
from concurrent.futures import ThreadPoolExecutor # 线程池
REQ_TIMEOUT = 3 # 代理的超时时间,
# 数据库连接
client = MongoClient('127.0.0.1', 27017)
db = client.ip # 连接mydb数据库,没有则自动创建
table = db.table # 所有的ip表
ip_table = db.ip # 有效ip表
# 线程池
spider_poll_max = 20 # 多线程的最大数量
# 创建一个线程池
proving_poll = ThreadPoolExecutor(max_workers=spider_poll_max)
def proving(ip):
'''
@method 检测所有ip中有效的ip
'''
global table, ip_table
host = ip['ip']
port = ip['port']
_id = ip['_id']
types = ip['type']
proxies = {
'http': host+':'+port,
'https': host+':'+port
}
try:
# 通过比较ip是否相同来判断代理是否有效
OrigionalIP = requests.get("http://icanhazip.com", timeout=REQ_TIMEOUT).content
MaskedIP = requests.get("http://icanhazip.com",timeout=REQ_TIMEOUT, proxies=proxies).content
# 删除代理
if OrigionalIP == MaskedIP:
result = table.delete_one({"ip": host, "port": port, "type": types})
else:
print('新增有效代理', host+':'+port)
# 有效代理则存到ip表中
ip_table.insert_one({"ip": host, "port": port, "type": types})
except:
# 删除代理
result = table.delete_one({"ip": host, "port": port, "type": types})
def proving_ip(ip):
'''
@method 检测有效ip中无效ip
'''
global ip_table
host = ip['ip']
port = ip['port']
_id = ip['_id']
types = ip['type']
#代理
proxies = {
'http': host+':'+port,
'https': host+':'+port
}
#try except用于检测超时的代理
try:
# 通过比较ip是否相同来判断代理是否有效
OrigionalIP = requests.get("http://icanhazip.com", timeout=REQ_TIMEOUT).content
MaskedIP = requests.get("http://icanhazip.com",timeout=REQ_TIMEOUT, proxies=proxies).content
# 删除代理
if OrigionalIP == MaskedIP:
# ip相同则是无效代理
ip_table.delete_one({"ip": host, "port": port, "type": types})
else:
print('有效代理', host+':'+port)
except:
# 删除代理超时的代理
ip_table.delete_one({"ip": host, "port": port, "type": types})
# 进行第一步,先检测有效ip表中无效的ip
proving_ips = ip_table.find({})
print('开始清理无效ip...')
# 有效性验证
for data in proving_ips:
# 添加一个线程
proving_poll.submit(proving_ip, (data))
# 再进行第二步,提取所有ip中的有效ip
ips = table.find({})
print('开始代理有效性验证...')
# 有效性验证
for data in ips:
# 添加一个线程
proving_poll.submit(proving, (data))
到这里我们就有了一个专门存在有效代理的数据表了(ip 表),以后直接从这里取一个有效代理就可以直接使用了
现在解决一下前面所遗留的问题 1.使用 多线程 + 代理 完成招聘数据爬取
import requests
import random
from pymongo import MongoClient
from time import sleep
from concurrent.futures import ThreadPoolExecutor # 线程池
# 连接数据库
client = MongoClient('127.0.0.1', 27017)
db = client.db # 连接mydb数据库,没有则自动创建
ip_client = client.ip # 连接mydb数据库,没有则自动创建
ip_table = ip_client.ip # 有效ip表
# 线程池
spider_poll_max = 7 # 爬虫线程池最大数量
# 爬虫线程池 max_workers最大数量
spider_poll = ThreadPoolExecutor(max_workers=spider_poll_max)
# 请求头的cookie和UserAgent
UserAgent = "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3704.400 QQBrowser/10.4.3587.400"
# 武汉
city = '%E6%AD%A6%E6%B1%89'
def getRandomIp():
'''
@method 有效ip表中随机取一个ip
'''
global ip_table
# 获取总数量
count = ip_table.count_documents({}) # 查询一共有多少数据
# 随机取一个
index = random.randint(0, count) # 获取0到count的随机整数
print(count, index)
data = ip_table.find().skip(index).limit(1)
for item in data:
print({'ip': item['ip'], 'port': item['port']})
return {'ip': item['ip'], 'port': item['port']}
def getCookie(key_world):
'''
@method 获取cookie
'''
global UserAgent, city, ip_table
# 随机获取一个代理,防止被封ip
row = getRandomIp()
print(50, row)
try:
proxies = {
'http': row['ip'] + ':' + row['port'],
'https': row['ip'] + ':' + row['port']
}
data = requests.get('https://www.lagou.com/jobs/list_' + key_world + '?px=default&city=' + city, timeout=10, proxies=proxies, headers={
"User-Agent": UserAgent
})
cookies = data.cookies.get_dict()
COOKIE = ''
for key, val in cookies.items():
COOKIE += (key + '=' + val + '; ')
return COOKIE
except:
print('获取cookie失败,无效代理', row['ip'] + ':' + row['port'])
# 删除无效代理
ip_table.delete_one({"ip": row['ip'], "port": row['port']})
# 重新获取cookie
return getCookie(key_world)
def getData(obj):
'''
@method 抓取一页数据
'''
global UserAgent, client, db
key_world = obj['key_world'] # 关键词
page = obj['page'] # 分页
print('开始抓取')
# 连接数据表,前端需要转为web表,
if key_world == '%E5%89%8D%E7%AB%AF':
table = db.web # 连接mydb数据库,没有则自动创建
else:
table = db[key_world] # 连接mydb数据库,没有则自动创建
# 随机获取一个代理,防止被封ip
row = getRandomIp()
print(102, row)
proxies = {
'http': row['ip'] + ':' + row['port'],
'https': row['ip'] + ':' + row['port']
}
try:
# 因为请求接口需要cookie,先获取cookie
cookie = getCookie(key_world)
# 抓取数据开始
data = {
"first": "false",
"pn": page + 1,
"kd": key_world == '%E5%89%8D%E7%AB%AF' and '前端' or key_world
}
headers = {
"Accept": "application/json, text/javascript, */*; q=0.01",
"Connection": "keep-alive",
"Host": "www.lagou.com",
"Referer": 'https://www.lagou.com/jobs/list_' + key_world + '?px=default&city=' + city,
"Content-Type": "application/x-www-form-urlencoded; charset=UTF-8",
"User-Agent": UserAgent,
"Cookie": cookie
}
response = requests.post('https://www.lagou.com/jobs/positionAjax.json?px=default&city=武汉&needAddtionalResult=false',
data=data, timeout=10, proxies=proxies, headers=headers)
response.encoding = 'utf-8'
res = response.json()
print(res)
# 如果请求成功存入数据库中
if res['msg'] == None:
# 工作岗位
position = res['content']['positionResult']['result']
# 记录当前的数据
one_data = []
for idx, item in enumerate(position):
one_data.append({
'positionName': item['positionName'],
'workYear': item['workYear'],
'salary': item['salary'],
'education': item['education'],
'companySize': item['companySize'],
'companyFullName': item['companyFullName'],
'formatCreateTime': item['formatCreateTime'],
'positionId': item['positionId']
})
# 没有数据了
if len(one_data) == 0:
print(key_world + '第'+page+'页数据为空')
return
# 存储当前数据
table.insert_many(one_data)
print(key_world + '第'+page+'页存入成功')
else:
print(key_world + '第'+page+'页存入失败')
# 写日志
with open('./log.txt', 'a', -1, 'utf-8') as f:
f.write('key_world:'+key_world+',page:'+page+'\n')
f.write(str(res))
f.write('\n')
# 删除无效代理
ip_table.delete_one({"ip": row['ip'], "port": row['port']})
# 重新添加到任务中
spider_poll.submit(
getData, ({'key_world': key_world, 'page': page}))
except:
print('超时代理', row['ip'] + ':' + row['port'])
# 删除无效代理
ip_table.delete_one({"ip": row['ip'], "port": row['port']})
# 重新添加到任务中
spider_poll.submit(getData, ({'key_world': key_world, 'page': page}))
# 搜索的关键词, 第一个为前端
key_worlds = ['%E5%89%8D%E7%AB%AF', 'Python', 'Java', 'PHP', 'C', 'C++', 'C#']
# 添加任务
for idx, key_world in enumerate(key_worlds):
# 每种搜索关键词爬取100页
for page in range(1, 100):
# 添加一个任务
spider_poll.submit(getData, ({'key_world': key_world, 'page': page}))
2.使用代理爬取代理
import requests
import random
from pymongo import MongoClient
from lxml import etree # xpath解析模块
from concurrent.futures import ThreadPoolExecutor # 线程池
# 数据库连接
client = MongoClient('127.0.0.1', 27017)
db = client.ip # 连接mydb数据库,没有则自动创建
table = db.table # 将抓取的ip全部存到table表中
ip_table = db.ip # 有效ip表
# 线程池
spider_poll_max = 50 # 爬虫线程池最大数量
# 爬虫线程池 max_workers最大数量
spider_poll = ThreadPoolExecutor(max_workers=spider_poll_max)
def getRandomIp():
'''
@method 有效ip表中随机取一个ip
'''
global ip_table
# 获取总数量
count = ip_table.count_documents({}) # 查询一共有多少数据
# 随机取一个
index = random.randint(0, count) # 获取0到count的随机整数
# print(count, index)
data = ip_table.find().skip(index).limit(1)
for item in data:
return {'ip': item['ip'], 'port': item['port']}
def getIp(page):
'''
@method 爬取数据
'''
# 随机获取一个代理,防止被封ip
row = getRandomIp()
proxies = {
'http': row['ip'] + ':' + row['port'],
'https': row['ip'] + ':' + row['port']
}
try:
# 抓取代理
response = requests.get(
'http://www.xiladaili.com/gaoni/' + str(page + 1)+'/', timeout=10, proxies=proxies)
# 设置编码
response.encoding = 'utf-8'
# 解析
s = etree.HTML(response.text)
# 获取ip和请求类型
ips = s.xpath(
'/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[1]/text()')
types = s.xpath(
'/html/body/div[1]/div[3]/div[2]/table/tbody/tr/td[2]/text()')
if (len(ips) == 0):
print('抓取数据为空')
# 写日志
with open('./log.txt', 'a', -1, 'utf-8') as f:
f.write(response.text)
f.write('--------------------------------------------------')
f.write('\n')
f.write('\n')
f.write('\n')
f.write('\n')
# 删除无效代理
ip_table.delete_one({"ip": row['ip'], "port": row['port']})
else:
print('抓取数据成功, 正在存入数据库...')
# 存储ip
for index, ip in enumerate(ips):
host = ip.split(':')[0]
port = ip.split(':')[1]
table.insert_one(
{"ip": host, "port": port, "type": types[index]})
except:
print('超时')
# 删除无效代理
ip_table.delete_one({"ip": row['ip'], "port": row['port']})
# 抓取网页的数量
for page in range(0, 100):
# 添加一个线程
spider_poll.submit(getIp, (page))
3、搭建 node 服务器
Tip:涉及知识
server.js
const http = require('http');
var url = require('url');
var qs = require('qs');
const { get_education } = require('./api/education.js');
const { get_workYear } = require('./api/workYear.js');
const { get_salary } = require('./api/salary.js');
//用node中的http创建服务器 并传入两个形参
http.createServer(function(req, res) {
//设置请求头 允许所有域名访问 解决跨域
res.setHeader('Access-Control-Allow-Origin', '*');
res.writeHead(200, { 'Content-Type': 'application/json;charset=utf-8' }); //设置response编码
try {
//获取地址中的参数部分
var query = url.parse(req.url).query;
//用qs模块的方法 把地址中的参数转变成对象 方便获取
var queryObj = qs.parse(query);
//获取前端传来的myUrl=后面的内容  GET方式传入的数据
var type = queryObj.type;
/*
/get_education 获取学历分布
/get_workYear 获取工作经验分布
/get_salary 获取薪资分布
*/
if (req.url.indexOf('/get_education?type=') > -1) {
get_education(type, function(err, data) {
if (err) res.end({ errmsg: err });
console.log('[ok] /get_education');
res.end(JSON.stringify(data));
});
} else if (req.url.indexOf('/get_workYear?type=') > -1) {
get_workYear(type, function(err, data) {
if (err) res.end({ errmsg: err });
console.log('[ok] /get_workYear');
res.end(JSON.stringify(data));
});
} else if (req.url.indexOf('/get_salary?type=') > -1) {
get_salary(type, function(err, data) {
if (err) res.end({ errmsg: err });
console.log('[ok] /get_salary');
res.end(JSON.stringify(data));
});
} else {
console.log(req.url);
res.end('404');
}
} catch (err) {
res.end(err);
}
}).listen(8989, function(err) {
if (!err) {
console.log('服务器启动成功,正在监听8989...');
}
});
education.js 文件 (其他文件与这个类似)
const { model } = require('./db.js');
//获取学历
exports.get_education = function(type, callback) {
//查询所有的本科学历
model[type].find({}, { education: 1 }, function(err, res) {
if (err) return callback(err);
let result = [],
type = [];
//找出每种学历的数量
res.forEach(item => {
if (type.includes(item.education)) {
result[type.indexOf(item.education)].count++;
} else {
type.push(item.education);
result.push({
label: item.education,
count: 1
});
}
});
callback(null, result);
});
};
db.js
const mongoose = require('mongoose');
const DB_URL = 'mongodb://localhost:27017/db';
// 连接数据库
mongoose.connect(DB_URL, { useNewUrlParser: true });
var Schema = mongoose.Schema;
//所有的表
let collections = ['web', 'Python', 'PHP', 'Java', 'C++', 'C#', 'C'];
let model = {};
//为每张表都生成一个model用来操作表
collections.forEach(collection => {
let UserSchema = new Schema(
{
positionName: { type: String }, //职位
workYear: { type: String }, //工作年限
salary: { type: String }, //薪水
education: { type: String }, //学历
companySize: { type: String }, //规模
companyFullName: { type: String }, //公司名
formatCreateTime: { type: String }, //发布时间
positionId: { type: Number } //id
},
{
collection: collection
}
);
let web_model = mongoose.model(collection, UserSchema);
model[collection] = web_model;
});
exports.model = model;
然后我们用运行 server.js 文件, cmd 中输入 node server.js
运行成功后再用浏览器打开 localhost:8989/get_education?type=Python就可以看到数据了

4、Taro 使用 echarts 做数据分析
Tip:涉及知识
1.熟悉微信小程序 官方文档
2.熟悉 react 语法 官方文档
3.熟悉 Taro 的使用 官方文档
4.熟悉 echarts 的使用 快速上手 官网实例
5.在微信小程序中使用 echarts 快速上手
小程序源码请移步 github
Tip.
1.第一步请先抓取代理存入的table表中
2.第二步再验证代理确保ip表中有数据
3.最后在运行爬虫爬取数据
4.写个定时任务去循环前三步
项目源码 github 欢迎star
