

该文是Rasa官网文档的一个简单翻译,用于日常查看。
官网文档地址:Rasa文档
1、用户指南
安装
推荐通过pip命令安装Rasa
pip install rasa-x --extra-index-url https://pypi.rasa.com/simple
该命令会安装Rasa和Rasa X。如果不想使用Rasa X,使用pip install rasa替换即可。
除非你已经安装了numpy和scipy,否则我们强烈建议你安装和使用Anaconda。
如果您想使用Rasa的开发版本,可以从GitHub获取:
git clone https://github.com/RasaHQ/rasa.git
cd rasa
pip install -r requirements.txt
pip install -e .
Windows先决条件
确保安装了Microsoft VC ++编译器,因此python可以编译任何依赖项。您可以从Visual Studio获取编译器。下载安装程序,然后在列表中选择VC ++ Build工具。
NLU Pipeline Dependencies
Rasa NLU具有用于识别意图和实体的不同组件,其中大多数具有一些额外的依赖性。
当您训练NLU模型时,Rasa将检查是否安装了所有必需的依赖项,并告诉您是否缺少任何依赖项。选择管道的页面将帮助您选择要使用的管道。
如果你想确保为你可能需要的任何组件安装了依赖项,并且你不介意附加的依赖项,你可以使用如下命令安装所有依赖项。
pip install -r alt_requirements/requirements_full.txt
入门:使用spaCy预训练向量
pretrained_embeddings_spacy管道结合了一些不同的库,是一种流行的选择。有关更多信息,请查看spaCy文档。
可以通过下面的命令安装:
pip install rasa[spacy]
python -m spacy download en_core_web_md
python -m spacy link en_core_web_md en
该命令会安装Rasa NLU以及spacy和它的英语语言模型。我们建议使用最新的“medium”大小的模型(_md),代替spacy默认的最小的en_core_web_sm模型。小的模型需要更少的内存来运行,但有时会降低意图分类的性能。
第一种选择:Tensorflow
为了使用supervised_embeddings管道,需要安装tensorflow,为了实现实体识别需要安装sklearn-crfsuite库。运行下面的命令:
pip install rasa
第二种选择:MITIE
后端使用MITIE对于小型数据集更适用,如果你有数百个例子,训练时间可能会比较长。未来我们可能会弃用MITIE。
首先,运行:
pip install git+https://github.com/mit-nlp/MITIE.git
pip install rasa[mitie]
下载MITIE模型文件total_word_feature_extractor.dat。
MITIE的完整pipeline:
language: "en"
pipeline:
- name: "MitieNLP"
model: "data/total_word_feature_extractor.dat"
- name: "MitieTokenizer"
- name: "MitieEntityExtractor"
- name: "EntitySynonymMapper"
- name: "RegexFeaturizer"
- name: "MitieFeaturizer"
- name: "SklearnIntentClassifier"
单独使用MITIE训练可能会很慢,但你可以使用如下配置:
language: "en"
pipeline:
- name: "MitieNLP"
model: "data/total_word_feature_extractor.dat"
- name: "MitieTokenizer"
- name: "MitieEntityExtractor"
- name: "EntitySynonymMapper"
- name: "RegexFeaturizer"
- name: "MitieIntentClassifier"
Rasa教程
本页介绍了使用Rasa构建助手的基础知识,并显示了Rasa项目的结构。你可以在这里测试它而不需要安装任何东西。您还可以安装Rasa并在命令行中进行操作。
- 创建一个新项目
- 查看NLU训练数据
- 定义模型配置
- 书写第一个故事(stories)
- 定义domain
- 训练模型
- 与你的助手交谈
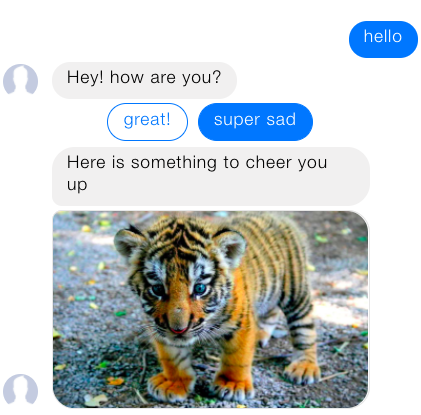
在这个教程中,你将建立一个简单、友好的助手,它会问你在做什么并发送给你一个有趣的图片让你振作起来。
1. 创建一个新项目
第一步是创建一个新的Rasa项目,运行:
rasa init --no-prompt
rasa init命令创建Rasa项目所需的所有文件,并在一些示例数据上训练一个简单的bot。如果省略--no-prompt标志,将会询问有关您希望如何设置项目的一些问题。
将创建以下文件:
| 文件 | 含义 |
|---|---|
__init__py |
一个空文件,帮助python找到actions |
actions.py |
自定义actions的代码 |
config.yml‘*’ |
NLU和Core模型的配置 |
credentials.yml |
连接其他服务的细节 |
data/nlu.md‘*’ |
NLU训练数据 |
data/stories.md‘*’ |
stories |
domain.yml‘*’ |
助手的domain |
endpoints.yml |
连接通道的细节 |
model/<timestamp>.tar.gz |
初始化模型 |
标‘*’的是重要的文件。
2. 查看训练数据
Rasa助手的第一部分是NLU模型。NLU代表自然语言理解,这意味着将用户消息转换为结构化数据。要使用Rasa执行此操作,需要提供训练示例,以说明Rasa应如何理解用户消息,然后通过向其展示这些示例来训练模型。
## intent:greet
- hey
- hello
- hi
- good morning
- good evening
- hey there
## intent:goodbye
- bye
- goodbye
- see you around
- see you later
以##开头的行定义了意图的名称,这些意图是具有相同含义的消息组。当您的用户向助理发送新的,看不见的消息时,Rasa的工作将是预测正确的意图。您可以在“训练数据格式”中找到数据格式的所有详细信息。
3. 定义你的模型配置
配置文件定义模型将使用的NLU和Core组件。在此示例中,您的NLU模型将使用supervised_embeddings管道。您可以在此处了解不同的NLU管道。 我们来看看你的模型配置文件:
cat config.yml
配置如下:
# Configuration for Rasa NLU.
# https://rasa.com/docs/rasa/nlu/components/
language: en
pipeline: supervised_embeddings
# Configuration for Rasa Core.
# https://rasa.com/docs/rasa/core/policies/
policies:
- name: MemoizationPolicy
- name: KerasPolicy
- name: MappingPolicy
关键字language和pipeline指定了NLU模型如何建立。policy定义了Core模型使用的决策信息。
4. 写你的第一个stories
在此阶段,您将教您的助手如何回复您的消息,这称为对话管理,由您的Core模型处理。 Core模型以训练“故事”的形式从真实的会话数据中学习。故事是用户和助手之间的真实对话。具有意图和实体的行反映了用户的输入,操作名称显示了助手应该做出的响应。
以下是简单对话的示例。用户打招呼,助理回答问好。这就是它看起来像一个故事:
## story1
* greet
- utter_greet
以 - 开头的行是助手采取的行动。在本教程中,我们的所有操作都是发送回用户的消息,例如utter_greet,但通常,操作可以执行任何操作,包括调用API和与外部世界交互。
运行下面的命令行查看data/stories.md的示例:
## happy path
* greet
- utter_greet
* mood_great
- utter_happy
## sad path 1
* greet
- utter_greet
* mood_unhappy
- utter_cheer_up
- utter_did_that_help
* affirm
- utter_happy
5. 定义domain
domain定义了您的助手所处的领域:它应该获得的用户输入,应该能够预测的操作,如何响应以及要存储的信息。我们助手的domain保存在名为domain.yml的文件中:
intents:
- greet
- goodbye
- affirm
- deny
- mood_great
- mood_unhappy
actions:
- utter_greet
- utter_cheer_up
- utter_did_that_help
- utter_happy
- utter_goodbye
templates:
utter_greet:
- text: "Hey! How are you?"
utter_cheer_up:
- text: "Here is something to cheer you up:"
image: "https://i.imgur.com/nGF1K8f.jpg"
utter_did_that_help:
- text: "Did that help you?"
| 名称 | 含义 |
|---|---|
| intents | things you expect users to say |
| actions | things your assistant can do and say |
| templates | template strings for the things your assistant can say |
这如何组合在一起?Rasa Core的工作是选择在对话的每个步骤执行的正确操作。
在这种情况下,我们的操作只是向用户发送消息,这些简单的话语动作是域中以utter_开头的动作。助理将根据模板部分的模板回复消息。请参阅自定义操作以构建不仅仅是发送消息的操作。
6. 训练模型
无论何时我们添加新的NLU或Core数据,或更新domain或配置,我们都需要在我们的示例stories和NLU数据上重新训练神经网络。为此,请运行以下命令。此命令将调用Rasa Core和NLU训练功能,并将训练好的模型存储到模型/目录中。如果数据或配置发生变化,该命令将自动仅重新训练不同的模型部件。
rasa train
rasa train命令将查找NLU和Core数据,并将训练组合模型。
7. 和你的助手交谈
恭喜!🚀你刚刚建立了一个完全由机器学习驱动的助手。下一步就是尝试一下!如果您在本地计算机上关注本教程,请通过运行以下方式与助理通话:
rasa shell
您还可以使用Rasa X收集更多对话并改进助手。
命令行接口
备忘单
命令行接口(CLI)为您提供易于记忆的常见任务命令。
| 命令 | 作用 |
|---|---|
| rasa_init | 创建一个新的项目,包含示例训练数据,动作和配置文件 |
| rasa_train | 使用NLU数据和stories训练模型,保存模型在./models中 |
| rasa interactive | 通过交谈开启一个新的交互学习会话来创建新的训练数据 |
| rasa shell | 加载训练模型,与助手通过命令行交谈 |
| rasa run | 使用训练的模型开启一个Rasa服务 |
| rasa run actions | 使用Rasa SDK开启action服务器 |
| rasa visualize | 可视化stories |
| rasa test | 使用测试NLU数据和故事来测试训练好的Rasa模型 |
| rasa data split nlu | 根据指定的百分比执行NLU数据的拆分 |
| rasa data convert nlu | 在不同格式之间转换NLU训练数据 |
| rasa x | 在本地启动Rasa X |
| rasa -h | 显示所有可用命令 |
创建新项目
单个命令为您设置一个完整的项目,其中包含一些示例训练数据。
rasa init
包含以下文件:
.
├── __init__.py
├── actions.py
├── config.yml
├── credentials.yml
├── data
│ ├── nlu.md
│ └── stories.md
├── domain.yml
├── endpoints.yml
└── models
└── <timestamp>.tar.gz
rasa init命令会询问你是否想要使用数据训练一个初始模型,如果回答no,model目录将为空。
训练模型
命令:
rasa train
该命令训练Rasa模型,该模型结合了Rasa NLU和Rasa Core模型。如果您只想训练NLU或Core模型,您可以运行rasa train nlu或rasa train core。但是,如果训练数据和配置没有改变,Rasa将自动跳过训练Core或NLU。
rasa trian将存储训练好的模型到--out指定的目标下。模型的名字默认是<timestamp>.tar.gz。如果想要自己命名,可以通过--fixed-model-name来指定。
以下参数可用于配置训练过程:
usage: rasa train [-h] [-v] [-vv] [--quiet] [--data DATA [DATA ...]]
[-c CONFIG] [-d DOMAIN] [--out OUT]
[--augmentation AUGMENTATION] [--debug-plots]
[--dump-stories] [--fixed-model-name FIXED_MODEL_NAME]
[--force]
{core,nlu} ...
positional arguments:
{core,nlu}
core Trains a Rasa Core model using your stories.
nlu Trains a Rasa NLU model using your NLU data.
optional arguments:
-h, --help show this help message and exit
--data DATA [DATA ...]
Paths to the Core and NLU data files. (default:
['data'])
-c CONFIG, --config CONFIG
The policy and NLU pipeline configuration of your bot.
(default: config.yml)
-d DOMAIN, --domain DOMAIN
Domain specification (yml file). (default: domain.yml)
--out OUT Directory where your models should be stored.
(default: models)
--augmentation AUGMENTATION
How much data augmentation to use during training.
(default: 50)
--debug-plots If enabled, will create plots showing checkpoints and
their connections between story blocks in a file
called `story_blocks_connections.html`. (default:
False)
--dump-stories If enabled, save flattened stories to a file.
(default: False)
--fixed-model-name FIXED_MODEL_NAME
If set, the name of the model file/directory will be
set to the given name. (default: None)
--force Force a model training even if the data has not
changed. (default: False)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
使用
rasa train命令训练模型时,确保Core和NLU的训练数据存在。如果仅存在一种模型类型的训练数据,则该命令将根据提供的训练文件自动回退到rasa train nlu或rasa train core。
交互式学习
要与助理开始交互式学习会话,请运行:
rasa interactive
如果使用--model参数指定训练模型,则使用提供的模型启动交互式学习过程。如果没有指定模型,rasa interactive将训练一个新的Rasa模型,如果没有其他目录传递给--data标志,则其数据位于data /中。在训练初始模型之后,交互式学习会话开始。如果训练数据和配置没有改变,将跳过训练。
rasa interactive所有参数列表如下:
usage: rasa interactive [-h] [-v] [-vv] [--quiet] [-m MODEL]
[--data DATA [DATA ...]] [--skip-visualization]
[--endpoints ENDPOINTS] [-c CONFIG] [-d DOMAIN]
[--out OUT] [--augmentation AUGMENTATION]
[--debug-plots] [--dump-stories] [--force]
{core} ... [model-as-positional-argument]
positional arguments:
{core}
core Starts an interactive learning session model to create
new training data for a Rasa Core model by chatting.
Uses the 'RegexInterpreter', i.e. `/<intent>` input
format.
model-as-positional-argument
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: None)
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: None)
--data DATA [DATA ...]
Paths to the Core and NLU data files. (default:
['data'])
--skip-visualization Disable plotting the visualization during interactive
learning. (default: False)
--endpoints ENDPOINTS
Configuration file for the model server and the
connectors as a yml file. (default: None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
Train Arguments:
-c CONFIG, --config CONFIG
The policy and NLU pipeline configuration of your bot.
(default: config.yml)
-d DOMAIN, --domain DOMAIN
Domain specification (yml file). (default: domain.yml)
--out OUT Directory where your models should be stored.
(default: models)
--augmentation AUGMENTATION
How much data augmentation to use during training.
(default: 50)
--debug-plots If enabled, will create plots showing checkpoints and
their connections between story blocks in a file
called `story_blocks_connections.html`. (default:
False)
--dump-stories If enabled, save flattened stories to a file.
(default: False)
--force Force a model training even if the data has not
changed. (default: False)
与你的助手交谈
使用如下命令:
rasa shell
应该用于与机器人交互的模型可以由--model指定。如果使用仅NLU模型启动shell,则rasa shell允许您获取在命令行上键入的任何文本的intent和实体。如果您的模型包含经过训练的Core模型,您可以与机器人聊天,并查看机器人预测的下一步操作。如果您已经训练了一个组合的Rasa模型,但是想要查看模型从文本中提取的意图和实体,您可以使用命令rasa shell nlu。
要增加调试的日志记录级别,请运行:
rasa shell --debug
rasa shell的所有选项列表如下:
usage: rasa shell [-h] [-v] [-vv] [--quiet] [-m MODEL] [--log-file LOG_FILE]
[--endpoints ENDPOINTS] [-p PORT] [-t AUTH_TOKEN]
[--cors [CORS [CORS ...]]] [--enable-api]
[--remote-storage REMOTE_STORAGE]
[--credentials CREDENTIALS] [--connector CONNECTOR]
[--jwt-secret JWT_SECRET] [--jwt-method JWT_METHOD]
{nlu} ... [model-as-positional-argument]
positional arguments:
{nlu}
nlu Interprets messages on the command line using your NLU
model.
model-as-positional-argument
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: None)
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: models)
--log-file LOG_FILE Store logs in specified file. (default: None)
--endpoints ENDPOINTS
Configuration file for the model server and the
connectors as a yml file. (default: None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
Server Settings:
-p PORT, --port PORT Port to run the server at. (default: 5005)
-t AUTH_TOKEN, --auth-token AUTH_TOKEN
Enable token based authentication. Requests need to
provide the token to be accepted. (default: None)
--cors [CORS [CORS ...]]
Enable CORS for the passed origin. Use * to whitelist
all origins. (default: None)
--enable-api Start the web server API in addition to the input
channel. (default: False)
--remote-storage REMOTE_STORAGE
Set the remote location where your Rasa model is
stored, e.g. on AWS. (default: None)
Channels:
--credentials CREDENTIALS
Authentication credentials for the connector as a yml
file. (default: None)
--connector CONNECTOR
Service to connect to. (default: None)
JWT Authentication:
--jwt-secret JWT_SECRET
Public key for asymmetric JWT methods or shared
secretfor symmetric methods. Please also make sure to
use --jwt-method to select the method of the
signature, otherwise this argument will be ignored.
(default: None)
--jwt-method JWT_METHOD
Method used for the signature of the JWT
authentication payload. (default: HS256)
启动服务器
要启动运行Rasa模型的服务器,请运行:
rasa run
下面的参数可以用来配置你的Rasa服务器
usage: rasa run [-h] [-v] [-vv] [--quiet] [-m MODEL] [--log-file LOG_FILE]
[--endpoints ENDPOINTS] [-p PORT] [-t AUTH_TOKEN]
[--cors [CORS [CORS ...]]] [--enable-api]
[--remote-storage REMOTE_STORAGE] [--credentials CREDENTIALS]
[--connector CONNECTOR] [--jwt-secret JWT_SECRET]
[--jwt-method JWT_METHOD]
{actions} ... [model-as-positional-argument]
positional arguments:
{actions}
actions Runs the action server.
model-as-positional-argument
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: None)
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: models)
--log-file LOG_FILE Store logs in specified file. (default: None)
--endpoints ENDPOINTS
Configuration file for the model server and the
connectors as a yml file. (default: None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
Server Settings:
-p PORT, --port PORT Port to run the server at. (default: 5005)
-t AUTH_TOKEN, --auth-token AUTH_TOKEN
Enable token based authentication. Requests need to
provide the token to be accepted. (default: None)
--cors [CORS [CORS ...]]
Enable CORS for the passed origin. Use * to whitelist
all origins. (default: None)
--enable-api Start the web server API in addition to the input
channel. (default: False)
--remote-storage REMOTE_STORAGE
Set the remote location where your Rasa model is
stored, e.g. on AWS. (default: None)
Channels:
--credentials CREDENTIALS
Authentication credentials for the connector as a yml
file. (default: None)
--connector CONNECTOR
Service to connect to. (default: None)
JWT Authentication:
--jwt-secret JWT_SECRET
Public key for asymmetric JWT methods or shared
secretfor symmetric methods. Please also make sure to
use --jwt-method to select the method of the
signature, otherwise this argument will be ignored.
(default: None)
--jwt-method JWT_METHOD
Method used for the signature of the JWT
authentication payload. (default: HS256)
开启Action服务器
使用如下命令运行:
rasa run actions
下面的参数可用于调整服务器设置:
usage: rasa run actions [-h] [-v] [-vv] [--quiet] [-p PORT]
[--cors [CORS [CORS ...]]] [--actions ACTIONS]
optional arguments:
-h, --help show this help message and exit
-p PORT, --port PORT port to run the server at (default: 5055)
--cors [CORS [CORS ...]]
enable CORS for the passed origin. Use * to whitelist
all origins (default: None)
--actions ACTIONS name of action package to be loaded (default: None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
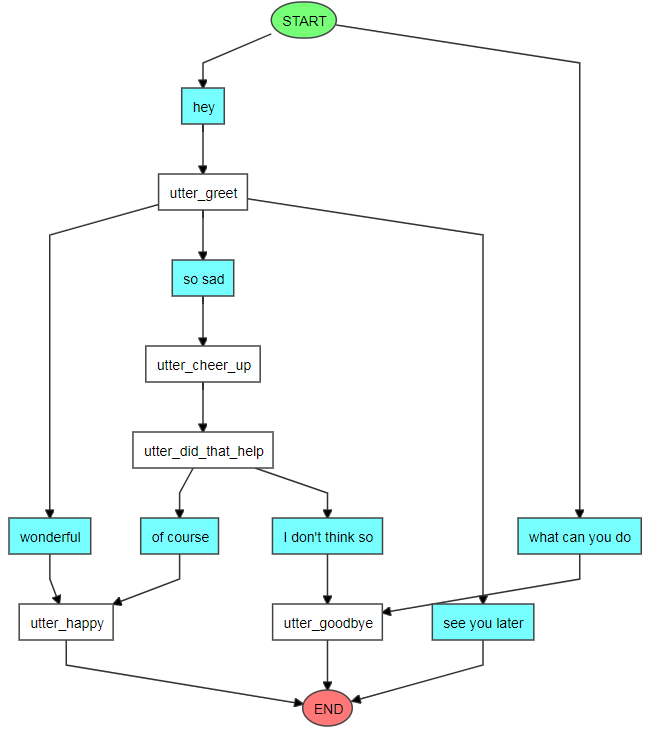
可视化你的stories
rasa visualize
通常,训练的stories位于data目录下是可视的。如何你的stories存储在其他地方,使用--stories指定他们的位置。
参数如下:
usage: rasa visualize [-h] [-v] [-vv] [--quiet] [-d DOMAIN] [-s STORIES]
[-c CONFIG] [--out OUT] [--max-history MAX_HISTORY]
[-u NLU]
optional arguments:
-h, --help show this help message and exit
-d DOMAIN, --domain DOMAIN
Domain specification (yml file). (default: domain.yml)
-s STORIES, --stories STORIES
File or folder containing your training stories.
(default: data)
-c CONFIG, --config CONFIG
The policy and NLU pipeline configuration of your bot.
(default: config.yml)
--out OUT Filename of the output path, e.g. 'graph.html'.
(default: graph.html)
--max-history MAX_HISTORY
Max history to consider when merging paths in the
output graph. (default: 2)
-u NLU, --nlu NLU File or folder containing your NLU data, used to
insert example messages into the graph. (default:
None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
会生成一个graph.html文件在当前路径下。
在测试数据上验证模型
运行:
rasa test
使用--model指定模型。
参数如下:
usage: rasa test [-h] [-v] [-vv] [--quiet] [-m MODEL] [-s STORIES]
[--max-stories MAX_STORIES] [--e2e] [--endpoints ENDPOINTS]
[--fail-on-prediction-errors] [--url URL]
[--evaluate-model-directory] [-u NLU] [--out OUT]
[--report [REPORT]] [--successes [SUCCESSES]]
[--errors ERRORS] [--histogram HISTOGRAM] [--confmat CONFMAT]
[-c CONFIG [CONFIG ...]] [--cross-validation] [-f FOLDS]
[-r RUNS] [-p PERCENTAGES [PERCENTAGES ...]]
{core,nlu} ...
positional arguments:
{core,nlu}
core Tests Rasa Core models using your test stories.
nlu Tests Rasa NLU models using your test NLU data.
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: models)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
Core Test Arguments:
-s STORIES, --stories STORIES
File or folder containing your test stories. (default:
data)
--max-stories MAX_STORIES
Maximum number of stories to test on. (default: None)
--e2e, --end-to-end Run an end-to-end evaluation for combined action and
intent prediction. Requires a story file in end-to-end
format. (default: False)
--endpoints ENDPOINTS
Configuration file for the connectors as a yml file.
(default: None)
--fail-on-prediction-errors
If a prediction error is encountered, an exception is
thrown. This can be used to validate stories during
tests, e.g. on travis. (default: False)
--url URL If supplied, downloads a story file from a URL and
trains on it. Fetches the data by sending a GET
request to the supplied URL. (default: None)
--evaluate-model-directory
Should be set to evaluate models trained via 'rasa
train core --config <config-1> <config-2>'. All models
in the provided directory are evaluated and compared
against each other. (default: False)
NLU Test Arguments:
-u NLU, --nlu NLU File or folder containing your NLU data. (default:
data)
--out OUT Output path for any files created during the
evaluation. (default: results)
--report [REPORT] Output path to save the intent/entity metrics report.
(default: None)
--successes [SUCCESSES]
Output path to save successful predictions. (default:
None)
--errors ERRORS Output path to save model errors. (default:
errors.json)
--histogram HISTOGRAM
Output path for the confidence histogram. (default:
hist.png)
--confmat CONFMAT Output path for the confusion matrix plot. (default:
confmat.png)
-c CONFIG [CONFIG ...], --config CONFIG [CONFIG ...]
Model configuration file. If a single file is passed
and cross validation mode is chosen, cross-validation
is performed, if multiple configs or a folder of
configs are passed, models will be trained and
compared directly. (default: None)
拆分Train Test训练数据 要进行NLU数据的拆分,请运行:
rasa data split nlu
你可以指定训练数据,输出目录等,参数如下:
usage: rasa data split nlu [-h] [-v] [-vv] [--quiet] [-u NLU]
[--training-fraction TRAINING_FRACTION] [--out OUT]
optional arguments:
-h, --help show this help message and exit
-u NLU, --nlu NLU File or folder containing your NLU data. (default:
data)
--training-fraction TRAINING_FRACTION
Percentage of the data which should be in the training
data. (default: 0.8)
--out OUT Directory where the split files should be stored.
(default: train_test_split)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
此命令将尝试在训练和测试中保持意图的比例相同。
在Markdown和JSON之间转换数据
要将NLU数据从LUIS数据格式,WIT数据格式,Dialogflow数据格式,JSON或Markdown转换为JSON或Markdown,请运行:
rasa data convert nlu
可以指定输入文件,输出文件,输出格式等,参数如下:
usage: rasa data convert nlu [-h] [-v] [-vv] [--quiet] --data DATA --out OUT
[-l LANGUAGE] -f {json,md}
optional arguments:
-h, --help show this help message and exit
--data DATA Path to the file or directory containing Rasa NLU
data. (default: None)
--out OUT File where to save training data in Rasa format.
(default: None)
-l LANGUAGE, --language LANGUAGE
Language of data. (default: en)
-f {json,md}, --format {json,md}
Output format the training data should be converted
into. (default: None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
启动Rasa X
Rasa X是一个工具,可帮助您构建\改进和部署由Rasa框架提供支持的AI Assistants。您可以在此处找到有关它的更多信息。
您可以通过执行来本地启动Rasa X:
rasa x
为了能够启动Rasa X,您需要安装Rasa X,您需要进入Rasa项目。
默认情况下,
Rasa X在端口5002上运行。使用参数--rasa-x-port可以将其更改为任何其他端口。
以下参数可用于rasa x:
usage: rasa x [-h] [-v] [-vv] [--quiet] [-m MODEL] [--data DATA] [--no-prompt]
[--production] [--rasa-x-port RASA_X_PORT] [--log-file LOG_FILE]
[--endpoints ENDPOINTS] [-p PORT] [-t AUTH_TOKEN]
[--cors [CORS [CORS ...]]] [--enable-api]
[--remote-storage REMOTE_STORAGE] [--credentials CREDENTIALS]
[--connector CONNECTOR] [--jwt-secret JWT_SECRET]
[--jwt-method JWT_METHOD]
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: models)
--data DATA Path to the file or directory containing stories and
Rasa NLU data. (default: data)
--no-prompt Automatic yes or default options to prompts and
oppressed warnings. (default: False)
--production Run Rasa X in a production environment. (default:
False)
--rasa-x-port RASA_X_PORT
Port to run the Rasa X server at. (default: 5002)
--log-file LOG_FILE Store logs in specified file. (default: None)
--endpoints ENDPOINTS
Configuration file for the model server and the
connectors as a yml file. (default: None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
Server Settings:
-p PORT, --port PORT Port to run the server at. (default: 5005)
-t AUTH_TOKEN, --auth-token AUTH_TOKEN
Enable token based authentication. Requests need to
provide the token to be accepted. (default: None)
--cors [CORS [CORS ...]]
Enable CORS for the passed origin. Use * to whitelist
all origins. (default: None)
--enable-api Start the web server API in addition to the input
channel. (default: False)
--remote-storage REMOTE_STORAGE
Set the remote location where your Rasa model is
stored, e.g. on AWS. (default: None)
Channels:
--credentials CREDENTIALS
Authentication credentials for the connector as a yml
file. (default: None)
--connector CONNECTOR
Service to connect to. (default: None)
JWT Authentication:
--jwt-secret JWT_SECRET
Public key for asymmetric JWT methods or shared
secretfor symmetric methods. Please also make sure to
use --jwt-method to select the method of the
signature, otherwise this argument will be ignored.
(default: None)
--jwt-method JWT_METHOD
Method used for the signature of the JWT
authentication payload. (default: HS256)
框架
消息处理
此图显示了使用Rasa构建的助手如何响应消息的基本步骤:
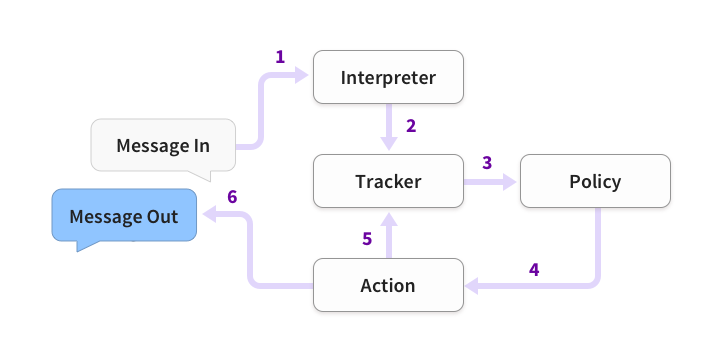
步骤如下:
- 收到消息并将其传递给解释器,解释器将其转换为包含原始文本,意图和找到的任何实体的字典。这部分由NLU处理。
Tracker是跟踪对话状态的对象。它接收新消息进入的信息。- 策略接收
Tracker的当前状态。 - 该政策选择接下来采取的行动。
- 选择的操作由
Tracker记录。 - 响应被发送给用户。
消息可以是人类输入的文本,也可以是按钮按下等结构化输入。
Messaging和Voice通道
如果你是在本地计算机(不是服务器)上进行测试,你需要使用ngrok。这会给你的机器一个domain名字让Facebook, Slack等知道消息发送到哪里来到达你的本地机器。
为了让你的助手在消息传递平台上可用,您需要在credentials.yml文件中提供凭据。运行rasa init时会创建一个示例文件,因此最简单的方法是编辑该文件并在其中添加凭据
。以下是Facebook凭据的示例:
facebook:
verify: "rasa-bot"
secret: "3e34709d01ea89032asdebfe5a74518"
page-access-token: "EAAbHPa7H9rEBAAuFk4Q3gPKbDedQnx4djJJ1JmQ7CAqO4iJKrQcNT0wtD"
评估模型
评估NLU模型
使用如下命令分离NLU的训练和测试数据:
rasa data split nlu
使用NLU模型在测试用例上预测:
rasa test nlu -u test_set.md --model models/nlu-xxx.tar.gz
如果您不想创建单独的测试集,仍可以使用交叉验证来估计模型的优化程度。为此,请添加标志--cross-validation:
rasa test nlu -u data/nlu.md --config config.yml --cross-validation
该脚本的完整选项列表如下:
usage: rasa test nlu [-h] [-v] [-vv] [--quiet] [-m MODEL] [-u NLU] [--out OUT]
[--report [REPORT]] [--successes [SUCCESSES]]
[--errors ERRORS] [--histogram HISTOGRAM]
[--confmat CONFMAT] [-c CONFIG [CONFIG ...]]
[--cross-validation] [-f FOLDS] [-r RUNS]
[-p PERCENTAGES [PERCENTAGES ...]]
optional arguments:
-h, --help show this help message and exit
-m MODEL, --model MODEL
Path to a trained Rasa model. If a directory is
specified, it will use the latest model in this
directory. (default: models)
-u NLU, --nlu NLU File or folder containing your NLU data. (default:
data)
--out OUT Output path for any files created during the
evaluation. (default: results)
--report [REPORT] Output path to save the intent/entity metrics report.
(default: None)
--successes [SUCCESSES]
Output path to save successful predictions. (default:
None)
--errors ERRORS Output path to save model errors. (default:
errors.json)
--histogram HISTOGRAM
Output path for the confidence histogram. (default:
hist.png)
--confmat CONFMAT Output path for the confusion matrix plot. (default:
confmat.png)
-c CONFIG [CONFIG ...], --config CONFIG [CONFIG ...]
Model configuration file. If a single file is passed
and cross validation mode is chosen, cross-validation
is performed, if multiple configs or a folder of
configs are passed, models will be trained and
compared directly. (default: None)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
Cross Validation:
--cross-validation Switch on cross validation mode. Any provided model
will be ignored. (default: False)
-f FOLDS, --folds FOLDS
Number of cross validation folds (cross validation
only). (default: 10)
Comparison Mode:
-r RUNS, --runs RUNS Number of comparison runs to make. (default: 3)
-p PERCENTAGES [PERCENTAGES ...], --percentages PERCENTAGES [PERCENTAGES ...]
Percentages of training data to exclude during
comparison. (default: [0, 25, 50, 75])
比较NLU管道 通过将多个管道配置(或包含它们的文件夹)传递给CLI,Rasa将在管道之间进行比较检查。
rasa test nlu --config pretrained_embeddings_spacy.yml supervised_embeddings.yml
--nlu data/nlu.md --runs 3 --percentages 0 25 50 70 90
上例中的命令将根据数据创建训练/测试集,然后多次训练每个管道,其中0,25,50,70和90%的意图数据从训练集中排除。然后在测试集上评估模型,并记录每个排除百分比的f1-scores。该过程运行三次(即总共有3个测试集),然后使用f1-scores的平均值和标准偏差绘制图表。
f1-score图表 - 以及所有训练/测试集,训练模型,分类和错误报告将保存到名为nlu_comparison_results的文件夹中。
意图分类
评估脚本将为您的模型生成报告,混淆矩阵和置信度直方图。
该报告记录每个意图和实体的精确度,召回率和f1度量,并提供总体平均值。您可以使用--report参数将这些报告另存为JSON文件。
混淆矩阵向您显示哪些意图被误认为是其他意图;任何错误预测的样本都会被记录并保存到名为errors.json的文件中,以便于调试。
脚本生成的直方图允许您可视化所有预测的置信度分布,其中正确和错误预测的量分别由蓝色和红色条显示。提高训练数据的质量会使蓝色直方图条向右移动,红色直方图条移动到图的左侧。
只有在评估测试集上的模型时,才会创建混淆矩阵。在交叉验证模式下,将不会生成混淆矩阵。
实体识别
CRFEntityExtractor是您使用自己的数据训练的唯一实体提取器,因此是唯一将被评估的实体提取器。如果您使用spaCy或duckling预训练实体提取器,Rasa NLU将不会在评估中包含这些。
Rasa NLU将报告CRFEntityExtractor经过培训识别的每种实体类型的召回,精确度和f1度量。
实体得分
为了评估实体提取,我们应用一种简单的基于标签的方法。我们不考虑BILOU标记,而只考虑每个标记的实体类型标记。对于像“亚历山大广场附近”这样的位置实体,我们期望标签LOC LOC而不是基于BILOU的B-LOC L-LOC。我们的方法在评估时更宽松,因为它奖励部分提取并且不惩罚实体的分裂。
评估Core模型
rasa test core --stories test_stories.md --out results
将失败的stories输出在results/failed_stories.md中。如果至少有一个动作被错误预测,我们会将任何故事视为失败。
此外,这会将混淆矩阵保存到名为results / story_confmat.pdf的文件中。对于您domian的每个操作,混淆矩阵会显示操作的正确预测频率以及预测错误操作的频率。
脚本的所有选项列表如下:
usage: rasa test core [-h] [-v] [-vv] [--quiet] [-m MODEL [MODEL ...]]
[-s STORIES] [--max-stories MAX_STORIES] [--out OUT]
[--e2e] [--endpoints ENDPOINTS]
[--fail-on-prediction-errors] [--url URL]
[--evaluate-model-directory]
optional arguments:
-h, --help show this help message and exit
-m MODEL [MODEL ...], --model MODEL [MODEL ...]
Path to a pre-trained model. If it is a 'tar.gz' file
that model file will be used. If it is a directory,
the latest model in that directory will be used
(exception: '--evaluate-model-directory' flag is set).
If multiple 'tar.gz' files are provided, all those
models will be compared. (default: [None])
-s STORIES, --stories STORIES
File or folder containing your test stories. (default:
data)
--max-stories MAX_STORIES
Maximum number of stories to test on. (default: None)
--out OUT Output path for any files created during the
evaluation. (default: results)
--e2e, --end-to-end Run an end-to-end evaluation for combined action and
intent prediction. Requires a story file in end-to-end
format. (default: False)
--endpoints ENDPOINTS
Configuration file for the connectors as a yml file.
(default: None)
--fail-on-prediction-errors
If a prediction error is encountered, an exception is
thrown. This can be used to validate stories during
tests, e.g. on travis. (default: False)
--url URL If supplied, downloads a story file from a URL and
trains on it. Fetches the data by sending a GET
request to the supplied URL. (default: None)
--evaluate-model-directory
Should be set to evaluate models trained via 'rasa
train core --config <config-1> <config-2>'. All models
in the provided directory are evaluated and compared
against each other. (default: False)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
比较策略Policy
选择特定的策略配置,或选择特定策略的超参数,您需要衡量Rasa Core将会概括为以前从未见过的对话的程度。特别是在项目的开始阶段,你没有很多真正的对话来用来训练你的机器人,所以你不只是想扔掉一些用作测试集。
Rasa Core有一些脚本可帮助您选择和微调策略配置。一旦您满意,您就可以在完整数据集上训练最终配置。要做到这一点,首先必须为不同的策略训练模型。创建两个(或更多)配置文件,包括要比较的策略(每个只包含一个策略),然后使用训练脚本的比较模式训练模型:
rasa train core -c config_1.yml config_2.yml \
-d domain.yml -s stories_folder --out comparison_models --runs 3 \
--percentages 0 5 25 50 70 95
低于提供的每个policy配置,Rasa Core将进行多次培训,将0,5,25,50,70和95%的培训故事排除在培训数据之外。这是为多次运行完成的,以确保一致的结果。
训练完成后,进行评估:
rasa test core -m comparison_models --stories stories_folder
--out comparison_results --evaluate-model-directory
这将评估训练集上的每个模型,并绘制一些图表以显示哪个策略表现最佳。通过评估整套故事,您可以衡量Rasa Core对预测故事的预测效果。
如果您不确定要比较哪些策略,我们建议您尝试使用EmbeddingPolicy``和KerasPolicy来查看哪种策略更适合您。
这个训练过程可能需要很长时间,所以我们建议让它在后台运行,不能中断。
端到端评估
Rasa允许您端到端地评估对话,运行测试对话并确保NLU和Core都能做出正确的预测。 为此,您需要一些端到端格式的故事,其中包括NLU输出和原始文本。这是一个例子:
## end-to-end story 1
* greet: hello
- utter_ask_howcanhelp
* inform: show me [chinese](cuisine) restaurants
- utter_ask_location
* inform: in [Paris](location)
- utter_ask_price
如果您将端到端故事保存为名为e2e_stories.md的文件,则可以通过运行以下命令来评估您的模型:
rasa test --stories e2e_stories.md --e2e
确保模型中的模型文件是组合
Core和nlu模型。如果它不包含NLU模型,Core将使用默认的RegexInterpreter。
测试Domain和Data文件的错误
要验证域文件,NLU数据或故事数据中是否存在任何错误,请运行验证脚本。您可以使用以下命令运行它:
rasa data validate
上面的脚本运行文件的所有验证。以下是脚本的选项列表:
usage: rasa data validate [-h] [-v] [-vv] [--quiet] [-d DOMAIN] [--data DATA]
optional arguments:
-h, --help show this help message and exit
-d DOMAIN, --domain DOMAIN
Domain specification (yml file). (default: domain.yml)
--data DATA Path to the file or directory containing Rasa data.
(default: data)
Python Logging Options:
-v, --verbose Be verbose. Sets logging level to INFO. (default:
None)
-vv, --debug Print lots of debugging statements. Sets logging level
to DEBUG. (default: None)
--quiet Be quiet! Sets logging level to WARNING. (default:
None)
还可以通过导入Validator类来运行这些验证,该类具有以下方法:
from_files():从字符串路径中的文件创建实例。verify_intents():检查domain文件中的intents列表包含NLU数据。verify_intents_in_stories():验证stories中的意图,检查它们是否有效。verify_utterances():检查domain文件,以确定话语模板与操作下列出的话语之间的一致性。verify_utterances_in_stories():验证stories中的话语,检查它们是否有效。verify_all():运行上面的所有验证。
要使用这些函数,必须创建Validator对象并初始化记录器。请参阅以下代码:
import logging
from rasa import utils
from rasa.core.validator import Validator
logger = logging.getLogger(__name__)
utils.configure_colored_logging('DEBUG')
validator = Validator.from_files(domain_file='domain.yml',
nlu_data='data/nlu_data.md',
stories='data/stories.md')
validator.verify_all()
Running the Server
运行HTTP服务器
可以使用经过训练的Rasa模型运行一个简单的HTTP服务器来处理请求:
rasa run -m models --enable-api --log-file out.log
此API公开的所有端点都记录在HTTP API中。
-m: 包含Rasa 模型的文件夹路径--enable-api: enable this additional API--log-file: log文件路径
Rasa可以通过三种不同的方式加载您的模型:
- 从服务器获取模型
- 从远程存储中获取模型 (参阅云存储)
- 从本地存储系统通过
-m加载指定的模型
Rasa尝试按上述顺序加载模型,即如果没有配置模型服务器和远程存储,它只会尝试从本地存储系统加载模型。
提醒: 确保通过限制对服务器的访问(例如,使用防火墙)或启用身份验证方法来保护您的服务器:安全注意事项。
Note:
- 如果使用自定义操作,请确保操作服务器正在运行(请参阅启动操作服务器)。如果您的操作在另一台计算机上运行,或者您没有使用
Rasa SDK,请确保更新您的endpoints.yml文件。- 如果使用仅NLU模型启动服务器,则不能调用所有可用端点。请注意,某些端点将返回409状态代码,因为需要经过培训的Core模型来处理请求。
从服务器获取模型
可以配置HTTP服务器以从其他URL获取模型:
rasa run --enable-api --log-file out.log --endpoints my_endpoints.yml
模型服务器在端点配置(my_endpoints.yml)中指定,您可以在其中指定服务器URL Rasa定期查询压缩的Rasa模型:
models:
url: http://my-server.com/models/default@latest
wait_time_between_pulls: 10 # [optional](default: 100)
Note 如果要从服务器中仅拉取模型一次,请将
wait_time_between_pulls设置为None。
Note 您的模型服务器必须提供压缩的Rasa模型,并将
{“ETag”:<model_hash_string>}作为其标头之一。如果此模型哈希发生更改,Rasa将仅下载新模型。
Rasa可能对您的模型服务器提出的示例请求如下所示:
curl --header "If-None-Match: d41d8cd98f00b204e9800998ecf8427e" http://my-server.com/models/default@latest
从远程存储中获取模型
可以配置Rasa服务器以从远程存储中获取模型:
rasa run -m 20190506-100418.tar.gz --enable-api --log-file out.log --remote-storage aws
该模型将下载并存储在本地存储系统的临时目录中。
安全考虑因素
我们建议不要将Rasa服务器暴露给外部世界,而是通过专用连接(例如,在docker容器之间)从后端连接到它。 然而,内置了两种身份验证方法:
- 基于令牌的身份验证:
启动服务器时使用
--auth-token thisismysecret传递令牌:
请求应该传递令牌,在我们的案例中是rasa run \ -m models \ --enable-api \ --log-file out.log \ --auth-token thisismysecretthisismysecret,作为参数:curl -XGET localhost:5005/conversations/default/tracker?token=thisismysecret - 基于JWT的Auth:
使用
--jwt-secret thisismysecret启用基于JWT的身份验证。对服务器的请求需要在使用此密钥和HS256算法签名的Authorization标头中包含有效的JWT令牌。 用户必须具有username和role属性。如果role是admin,则可以访问所有端点。如果role是user,则只有sender_id与用户的username匹配时才能访问具有sender_id参数的端点。
请求应该设置正确的JWT标头:rasa run \ -m models \ --enable-api \ --log-file out.log \ --jwt-secret thisismysecret"Authorization": "Bearer eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJ" "zdWIiOiIxMjM0NTY3ODkwIiwibmFtZSI6IkpvaG4gRG9lIi" "wiaWF0IjoxNTE2MjM5MDIyfQ.qdrr2_a7Sd80gmCWjnDomO" "Gl8eZFVfKXA6jhncgRn-I"
Endpoint配置
要将Rasa连接到其他端点,您可以在YAML文件中指定端点配置。然后使用标志--endpoints <path to endpoint configuration.yml>运行Rasa。
例如:
rasa run \
--m <Rasa model> \
--endpoints <path to endpoint configuration>.yml
可以使用$ {name of environment variable}指定配置文件中的环境变量。然后,这些占位符将替换为环境变量的值。
