

分区(Partition)
什么是分区?
分区主要是为了可扩展性。不同的分区可以放在不共享集群中的不同节点上
为什么要分区?
- 提升系统的扩展性
- 提升系统的可用性(节点故障只会引起一部分数据丢失)
*水平分区与垂直分区
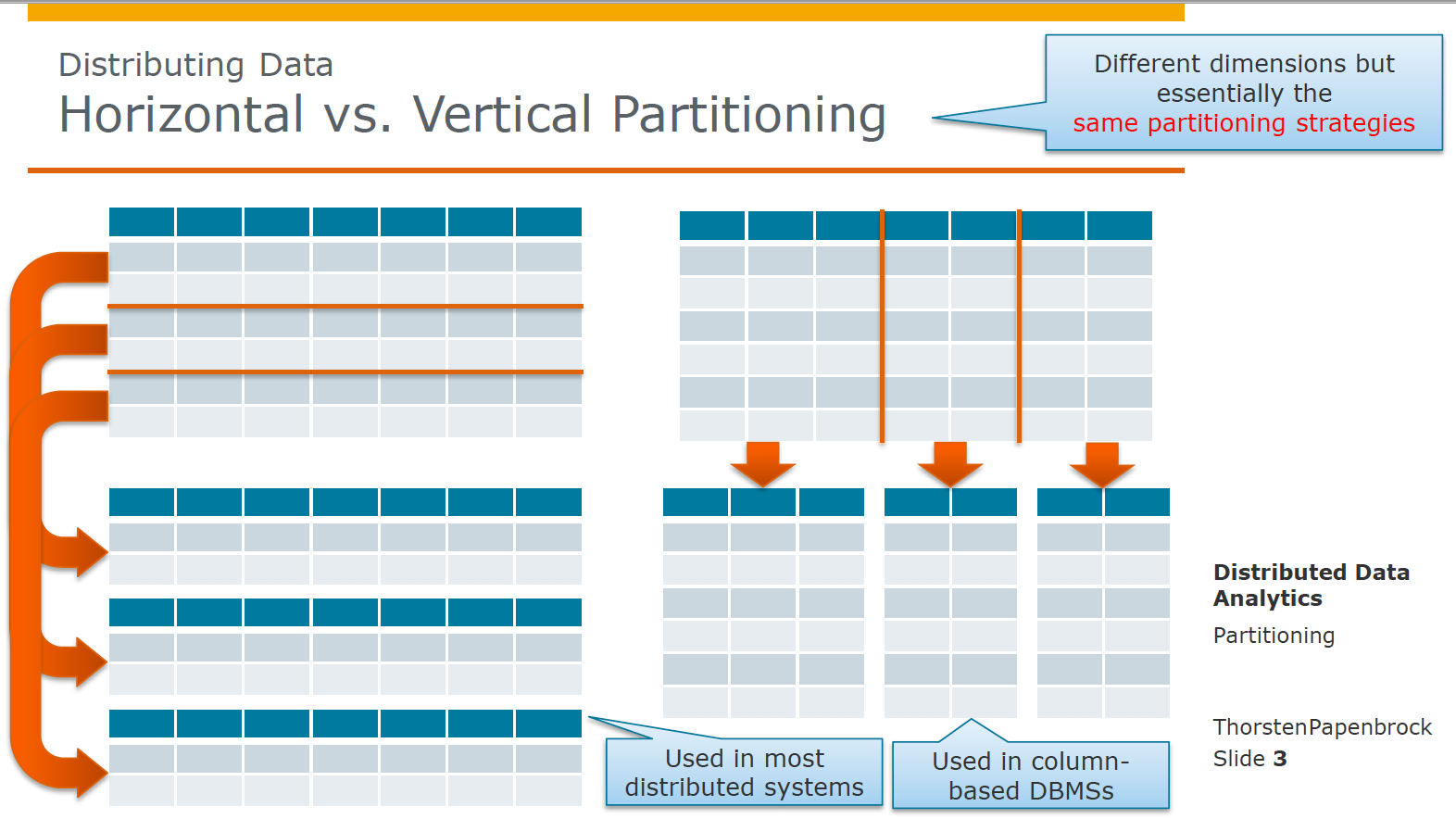
水平切分常用于分布式系统
- 不存在单库数据量过大、高并发的性能瓶颈,提升系统稳定性和负载能力
- 应用端改造较小,不需要拆分业务模块
垂直切分常用于DBMS
- 解决业务系统层面的耦合,业务清晰
- 与微服务的治理类似,也能对不同业务的数据进行分级管理、维护、监控、扩展等
- 高并发场景下,垂直切分一定程度的提升IO、数据库连接数、单机硬件资源的瓶颈
Synonymes(同义词)
分区partition在不同数据库有不同的称谓
Shard[分片]MongoDB,ElasticsearchRegion[区域]HBasetablet[表块]BigTablevnode[虚节点]Cassandra,Riak
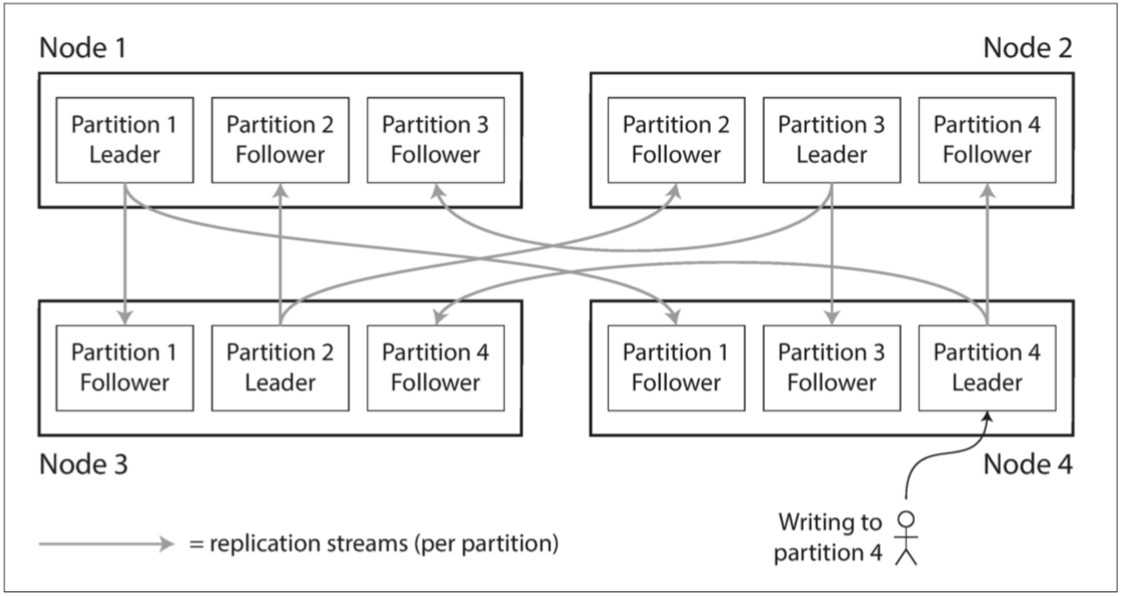
分区与复制
分区通常与复制结合使用,使得每个分区的副本存储在多个节点上。 这意味着,即使每条记录属于一个分区,它仍然可以存储在多个不同的节点上以获得容错能力。
键值数据的分区
分区目标是将数据和查询负载均匀分布在各个节点上。如果每个节点均匀分享数据和负载,那么理论上10个节点应该能够处理10倍的数据量和10倍的单个节点的读写吞吐量。
两个概念 skew&hot spot
skew:一些分区比其他分区有更多的数据或查询,我们称之为偏斜hot spot:不均衡导致的高负载的分区被称为热点
根据键的范围分区(Range Partitioning)
一种分区的方法是为每个分区指定一块连续的键范围(从最小值到最大值)
拿mysql range partition为例,创建一个employees表
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
可以看到store_id = 1~5被分到p0分区,6-11被分到p2分区,然后依次类推
range partition的优缺点
- 支持范围查询,比如按照时间散列
load skew
根据键的散列分区
hash partition 哈希散列
Map the (skewed) range of keys to a uniformly distributed range of hashes

一致性hash
上篇文章已经介绍过一致性hash的内容了,不再赘述。
分片与次级索引
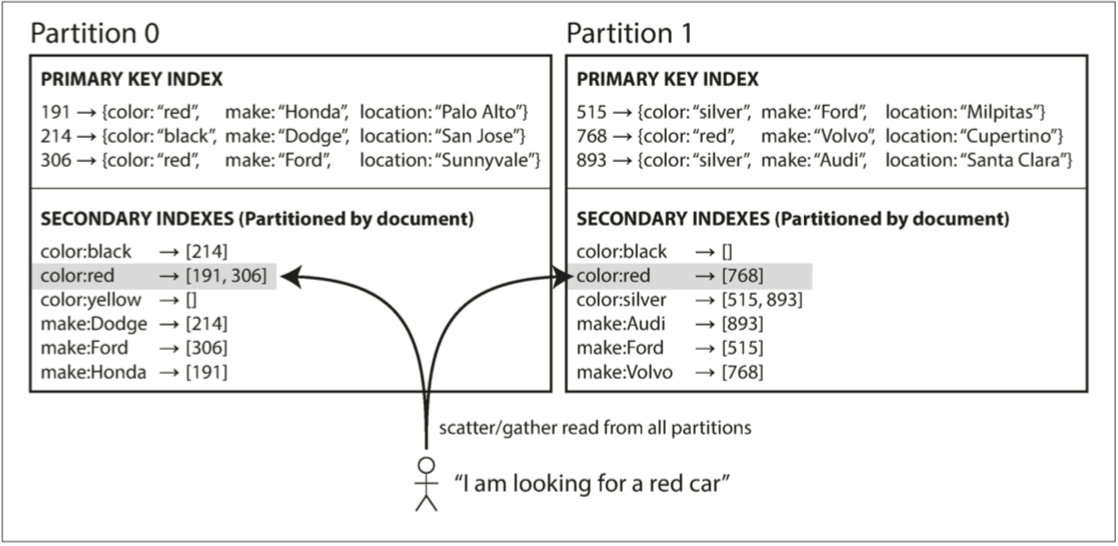
基于文档的分区(document-based)和基于关键词(term-based)的分区。
local index
Every partition manages its own index with all pointers to local data items
- Vertically(垂直) partitioned index
- Insert/update/delete: performed locally
- Select: queries all partition indexes
适用于OnLine Transaction Processing(联机事务处理过程)
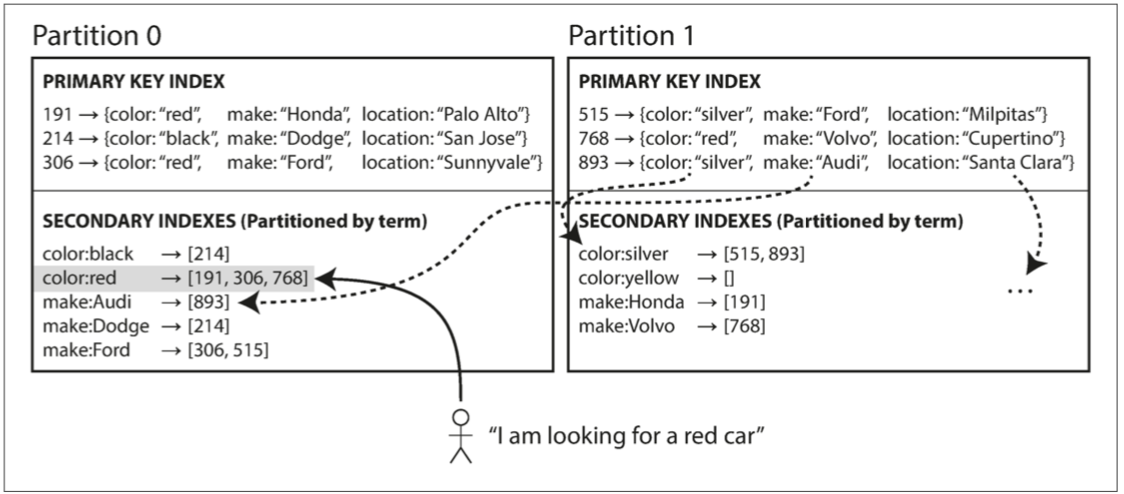
global index
Index entries are partitioned by their key independently from local data items
- Horizontally partitioned index
- Insert/update/delete: require remote updates
- Select: queries only one partition index
适用于OnLine Analytical Processing(分析处理过程)
分区再平衡
Things change:
- Query load → add more CPUs
- Data size → add more disks and RAM
- Nodes fail → other nodes need to take over
- Require to move data around (rebalancing)!
反面教材 hash mod N
如果n改变了,那么对于mod n的数值也会随着变更
比如:
123456 % 10 = 6, 123456 % 11 = 3, 123456 % 12 = 0,
固定数量的分区
如果一个节点被添加到集群中,新节点可以从当前每个节点中窃取一些分区,直到分区再次公平分配
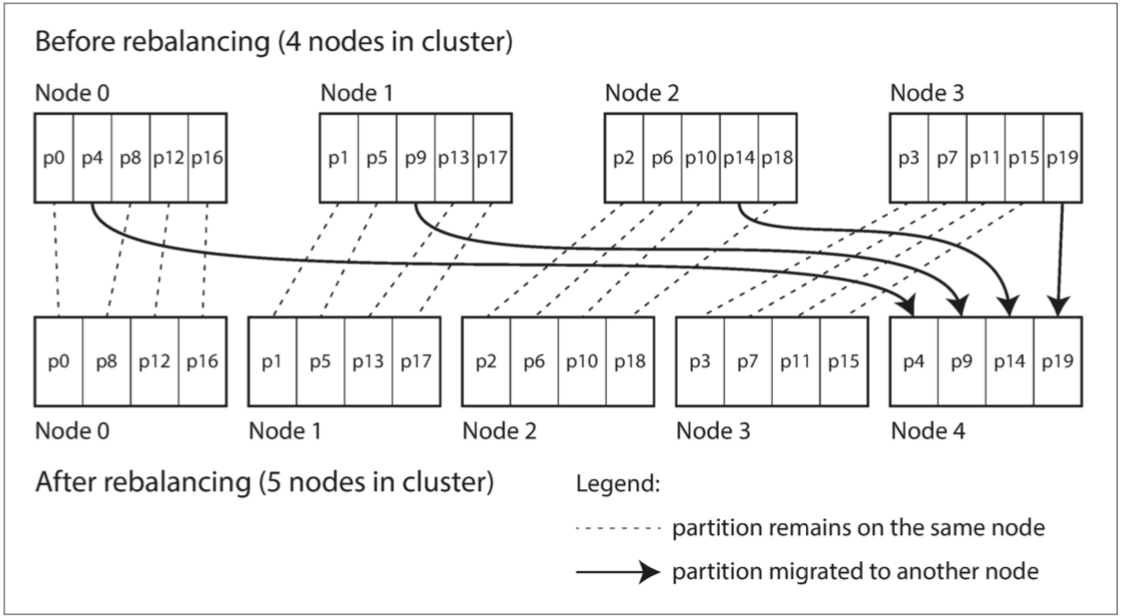
动态分区
- 创建一些初始分区数
- 如果分区超过某个最大大小阈值,将其拆分开来
- 如果分区小于最小的阈值,将其合并
类似于B树数据结构
按节点比例分区
请求路由
现在我们已经将数据集分割到多个机器上运行的多个节点上。但是仍然存在一个未解决的问题。当客户端想要发出请求时,如何知道要连接哪个节点?随着分区重新平衡,分区对节点的分配也发生变化。
这个问题可以概括为 服务发现(service discovery)
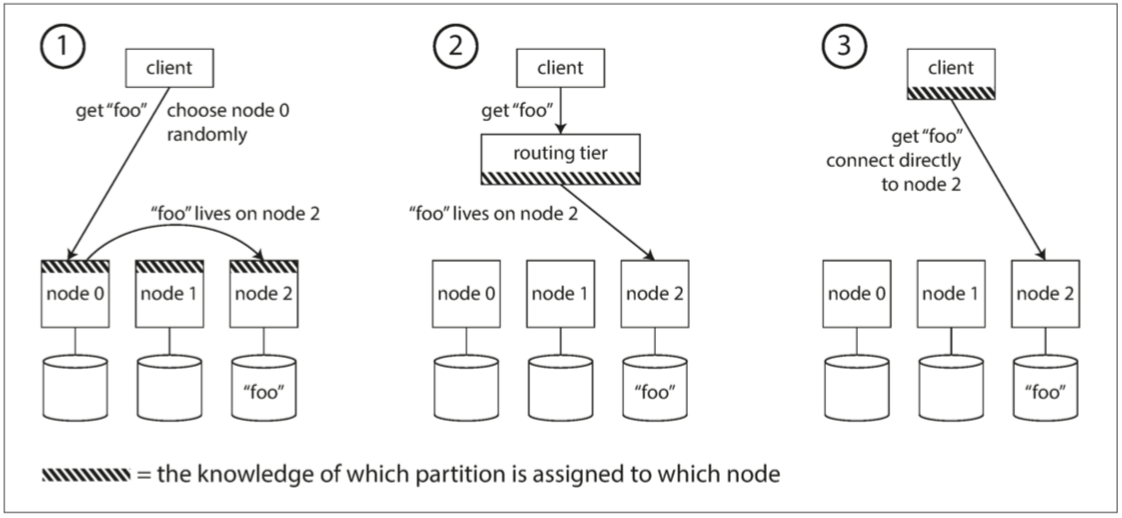
- 循环策略的负载均衡(
Round-Robin Load Balancer)如果节点恰好有请求的分区,则直接处理,否则转发到适当的节点 - 首先将所有来自客户端的请求发送到路由层,它决定了应该处理请求的节点,并相应地转
- 要求客户端知道分区和节点的分配
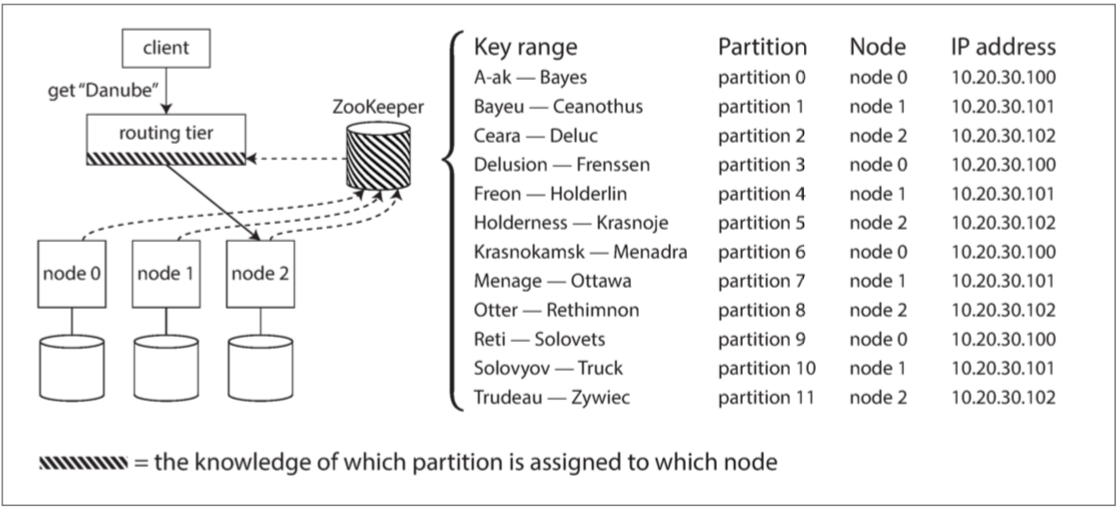
许多分布式数据系统都依赖于一个独立的协调服务,比如ZooKeeper来跟踪集群元数据。每个节点在ZooKeeper中注册自己,ZooKeeper维护分区到节点的可靠映射。
Cassandra和Riak采取不同的方法:他们在节点之间使用流言协议(gossip protocol) 来传播群集状态的变化。请求可以发送到任意节点,该节点会转发到包含所请求的分区的适当节点
