

引言
SparseArray是在API level 1就已经添加的适用于Android的集合类,而ArrayMap实在API level 19才加入的集合类,虽说这两者实在不同时期加入的,但是它们的目的只有一个,那就是在小数据量的情况下尽可能权衡内存占用以及使用效率,从而达到小数据量时能够替换JDK中类似于HashMap之类的集合类模板。- 由于两者源码实际上存在很多相似之处,因此就放一起看了,源码还是比较容易理解的。
SparseArray
-
SparseArray的数据构造可以从下面这几行代码得知,显然是使用两个数组分别存储key和value的值,而这两者又因元素索引存在对应关系而刚好形成元素间的相互映射,可以说是很简单粗暴又有效了。public class SparseArray<E> implements Cloneable { // ... private int[] mKeys; private Object[] mValues; private int mSize; } -
put方法:揭露核心的方法
- 通过源码可以看出,
SparseArray使用的是二分查找法来查找key所在的位置索引,如果存在则替换掉对应索引上的value,如果不存在,则将在索引取反后的位置上添加元素,这点跟JDK中的Map是一样的行为,存在则覆盖。
public void put(int key, E value) { // 二分查找算法 找到 key,也就是索引位置 int i = ContainerHelpers.binarySearch(mKeys, mSize, key); if (i >= 0) { // 存在 mValues[i] = value; // value数组中找到key位置上的value } else { // 不存在 i = ~i; if (i < mSize && mValues[i] == DELETED) { mKeys[i] = key; mValues[i] = value; return; } if (mGarbage && mSize >= mKeys.length) {//可能value元素已经被删除了 gc(); // 那么chufa一次gc // 中心搜索一遍 i = ~ContainerHelpers.binarySearch(mKeys, mSize, key); } mKeys = GrowingArrayUtils.insert(mKeys, mSize, i, key); mValues = GrowingArrayUtils.insert(mValues, mSize, i, value); mSize++; } }- 这里的
gc并非JVM中的那个GC,而是说当我们删除了某个元素之后,被删除元素所占用的那个位置上的数据就标记成了垃圾数据,然后就会通过gc来去除这个位置上的元素,而本质上,对于数组而言,就是挪动位置覆盖掉这个位置咯。
private void gc() { int n = mSize; int o = 0; int[] keys = mKeys; Object[] values = mValues; for (int i = 0; i < n; i++) { Object val = values[i]; if (val != DELETED) { if (i != o) { // 相当于把key、value元素都向前挪动一次 keys[o] = keys[i]; values[o] = val; values[i] = null; } o++; } } mGarbage = false; mSize = o; }- 上面代码中的
mGarbage会在删除元素时被设置为true,也就是说标记这个位置上的元素为垃圾数据。
public void delete(int key) { int i = ContainerHelpers.binarySearch(mKeys, mSize, key); if (i >= 0) { if (mValues[i] != DELETED) { mValues[i] = DELETED; mGarbage = true; } } } - 通过源码可以看出,
SparseArray 综述
-
特点:使用
int数组作为map的key容器,Object数组作为value容器,使用索引对应的形式组成key-value这使得SparseArray可以不按照像数组索引那样的顺序来添加元素。可看成增强型的数组或者ArrayList。 -
查找:使用二分查找法查找
key在数组中的位置,然后根据这个数组位置得到对应value数组中的value值。 -
优劣:相对于
HashMap,合理使用SparseArray可以节省大量创建Entry节点时产生的内存,提高性能,但是因为基于数组,插入和删除操作需要挪动数组,非常消耗性能,而当数据有几百条时,性能会比HashMap低近50%,因此SparseArray适用于数据量很小的场景。 -
使用场景举例:
- 通过
View id来映射View对象实例。 一个非常现实的场景是,当我们使用RecyclerView时,我们可能需要创建若干个ViewHolder,特别是如果一个列表包含若干中布局类型的时候,而如果我们不适用类似于ButterKnife或DataBinding这类工具的话,那么我们需要对每个控件进行findViewById,这是件很糟心的事情,那么我们可以怎么简化呢?欸,这种情况可以使用SparseArray来缓存一下我们的View(实际上ArrayMap、HashMap等也可以),比方说以下示例代码:
public class CommViewHolder extends RecyclerView.ViewHolder { private SparseArray<View> mViewCache; private Object tag; public CommViewHolder(@NonNull View itemView) { super(itemView); mViewCache = new SparseArray<>(); } public <T extends View> T getView(@IdRes int id) { T t = (T) mViewCache.get(id); if (t == null) { t = itemView.findViewById(id); mViewCache.put(id, t); } return t; } public void releaseCache(){ mViewCache.clear(); mViewCache = null; } public void setTag(Object tag) { this.tag = tag; } public Object getTag() { return tag; } }通过上面这个通用的
ViewHolder,我们就可以应用于任意的布局类型,而不用每个都去写一个对应的ViewHolder了,可以说很方便了。 - 通过
ArrayMap
-
通过阅读
ArrayMap的源码可以发现,它和SparseArray简直就是亲生兄弟啊,不同点就是,ArrayMap具备完整的Map特性,因为继承自Map,并且具备哈希表的相关特性。public final class ArrayMap<K, V> implements Map<K, V> { final boolean mIdentityHashCode; int[] mHashes; // 存储哈希值 Object[] mArray; // 存储元素 int mSize; MapCollections<K, V> mCollections; } -
我们先来看看查找索引
index源码,可以看到想要得到index,需要先使用二分查找法去mHashs数组中找出这个hash在数组中的位置,而这个位置就是index。这里就必然存在几种情况,具体可以看下面的注释。int indexOf(Object key, int hash) { final int N = mSize; // 使用二分查找算法搜索元素位置 int index = binarySearchHashes(mHashes, N, hash); // 1. 不存在相关该hash if (index < 0) { return index; } // 2. 存在该hash,且对应位置上有对应key if (key.equals(mArray[index<<1])) { return index; } // 3. 存在该hash,但是对应位置上无对应key, 也就是说冲突了 // 那么先搜索后半部分,之所以分成两半来查找是为了缩小查询范围,提升搜索速度 // 这实际实在赌博,赌目标值在数组后半段 ,最终能否提升速度就看是不是在数组后半段了 int end; for (end = index + 1; end < N && mHashes[end] == hash; end++) { if (key.equals(mArray[end << 1])) return end; } // 再搜索前半部分 for (int i = index - 1; i >= 0 && mHashes[i] == hash; i--) { if (key.equals(mArray[i << 1])) return i; } // 对应key实在没找到,说明确实是冲突了,那么返回个mHashes数组大小的取反值(负数) return ~end; } -
有了上面的分析过程,我们已经了解了
ArrayMap的index是如何决定的了,那么通过put方法就可以比较直观地看出ArrayMap的存储过程了,首先会计算我们给定key的哈希值,然后通过这个哈希值去查找index,如果在这个index上已经元素,那么替换这个元素,如果不存在,那么将数据存入数组中;如果存在冲突,则校检一下数组容量(看看需不需要扩容),然后存入数组。public V put(K key, V value) { final int osize = mSize; final int hash; int index; // 1. 查找hash,计算index if (key == null) { hash = 0; index = indexOfNull(); } else { hash = mIdentityHashCode ? System.identityHashCode(key) : key.hashCode(); index = indexOf(key, hash); } // 2. 根据index存值 // 存在,则覆盖掉旧元素,并返回旧元素 if (index >= 0) { index = (index<<1) + 1; final V old = (V)mArray[index]; mArray[index] = value; return old; } // 有冲突的情况 index = ~index; // 数组可用空间不够,那么扩容 if (osize >= mHashes.length) { final int n = osize >= (BASE_SIZE*2) ? (osize+(osize>>1)) : (osize >= BASE_SIZE ? (BASE_SIZE*2) : BASE_SIZE); final int[] ohashes = mHashes; final Object[] oarray = mArray; allocArrays(n); // 扩容 // ... if (mHashes.length > 0) { // 转移元素到新数组 System.arraycopy(ohashes, 0, mHashes, 0, ohashes.length); System.arraycopy(oarray, 0, mArray, 0, oarray.length); } freeArrays(ohashes, oarray, osize); // 清理就数组 } // 3. 存值 if (index < osize) { System.arraycopy(mHashes, index, mHashes, index + 1, osize - index); System.arraycopy(mArray, index << 1, mArray, (index + 1) << 1, (mSize - index) << 1); } mHashes[index] = hash; // key和value存在同一个数组上 mArray[index<<1] = key; mArray[(index<<1)+1] = value; mSize++; return null; }上面有个比较新颖的地方,就是它把
key和value都存到了一个数组中去了,也就是mArray数组,key在前,value在后,同index的关系如下图:
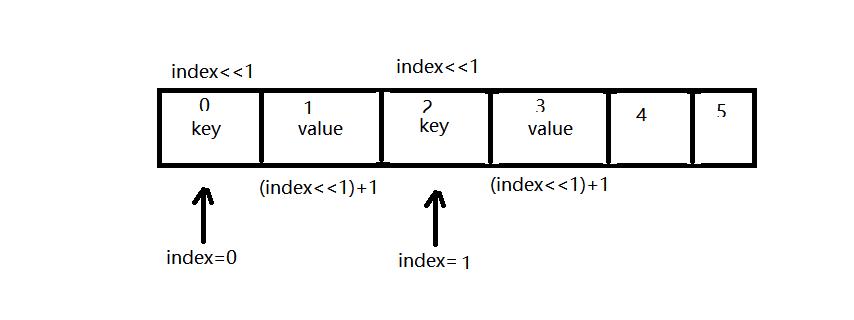
ArrayMap 综述
-
特点
- 实现了
Map接口,并使用int[]数来存储key的hash值,数组的索引用作index,而使用Object[]数组来存储key<->value,这还是比较新颖的 。 - 使用二分查找查找
hash值在key数组中的位置,然后根据这个位置得到value数组中对应位置的元素。 - 和
SparseArray类似,当数据有几百条时,性能会比HashMap低50%,因此ArrayMap适用于数据量很小的场景
- 实现了
-
ArrayMap和HashMap的区别?
- ArrayMap的存在是为了解决HashMap占用内存大的问题,它内部使用了一个int数组用来存储元素的hashcode,使用了一个Object数组用来存储元素,两者根据索引对应形成key-value结构,这样就不用像HashMap那样需要额外的创建Entry对象来存储,减少了内存占用。但是在数据量比较大时,ArrayMap的性能就会远低于HashMap,因为 ArrayMap基于二分查找算法来查找元素的,并且数组的插入操作如果不是末尾的话需要挪动数组元素,效率较低。
- 而HashMap内部基于数组+单向链表+红黑树实现,也是key-value结构, 正如刚才提到的,HashMap每put一个元素都需要创建一个Entry来存放元素,导致它的内存占用会比较大,但是在大数据量的时候,因为HashMap中当出现冲突时,冲突的数据量大于8,就会从单向链表转换成红黑树,而红黑树的插入、删除、查找的时间复杂度为O(logn),相对于ArrayMap的数组而言在插入和删除操作上要快不少,所以数据量上百的情况下,使用HashMap会有更高的效率。
-
如何解决冲突问题? 在
ArrayMap中,假设存在冲突的话,并不会像HashMap那样使用单向链表或红黑树来保留这些冲突的元素,而是全部key、value都存储到一个数组当中,然后查找的话通过二分查找进行,这也就是当数据量大时不宜用ArrayMap的原因了。
