

为什么需要一致性hash
假设你有10000个并发请求,同时请求单台redis(又是redis :p ),此时redis是处理不了这么多并发请求的。
那么如何提供系统的高可用性呢?
一个比较简单的想法就是对于系统进行横向扩展(也就是加机器),并且对于一些读写请求进行hash路由。
比如,目前你有四台redis服务器[0,1,2,3],此时client发起请求set("name","tom")
此时的路由变成
1.crc32('name') % 4 // 先找到写哪台redis
2.set("name","tom") // 真实的写操作
这样看起来的确提升了系统的可用性,但是假设业务量暴涨,4台redis也处理不过来了,那么我们此时的想法一定也是加机器(:p),但是加机器可能导致之前存储在redis上的key失效,以加当前机器基础上两台机器为例:
crc32('name') % 6 != crc32('name') % 4
从上面的代码可以看出此时直接加机器的方式会导致key失效(可能会导致缓存雪崩,或者对于一些强依赖cache的服务,会造成部分数据丢失,服务不可用),此时就引入了一致性hash的概念
什么是一致性hash
In computer science, consistent hashing is a special kind of hashing such that when a hash table is resized, only K/n keys need to be remapped on average, where K is the number of keys, and n is the number of slots.
上述是wikipad给出的示意,翻译过来就是
在计算机科学中,一致性hash是一种特殊的hash,这样当调整hash表的大小时,平均只需要重新映射K/n个key,其中K是keys的数量,n是slot的数量。
实际理解起来还是有点抽象,举个例子,目前有10个key,3台服务器,假设你加两台机器那么需要变化的就是 10 / 5 = 2个key
一致性Hash算法也是使用取模的方法,只是,刚才描述的取模法是对服务器的数量进行取模,而一致性Hash算法是对2^32取模
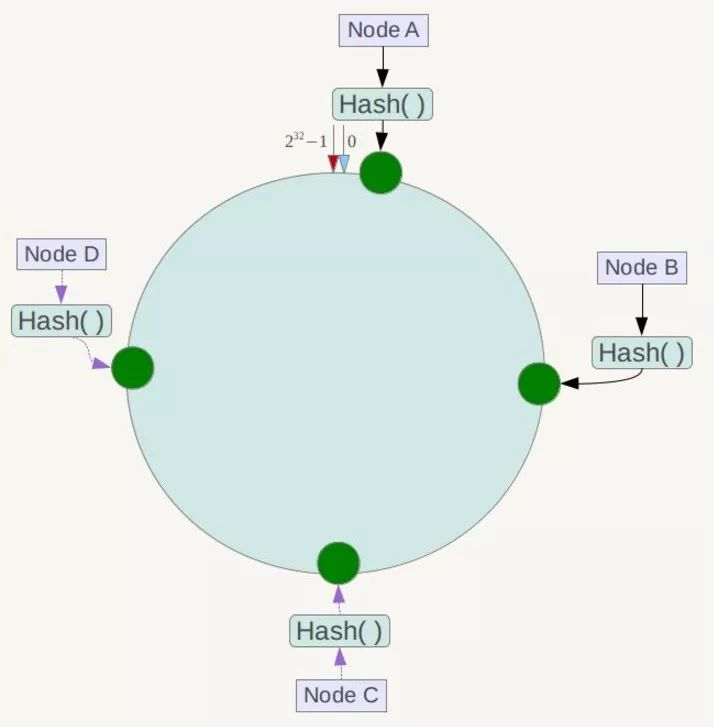
如上图是一致性hash实现,类似圆环
一致性hash数据倾斜问题
实际上还有一个问题,一致性Hash算法在服务节点太少时,容易因为节点分部不均匀而造成数据倾斜
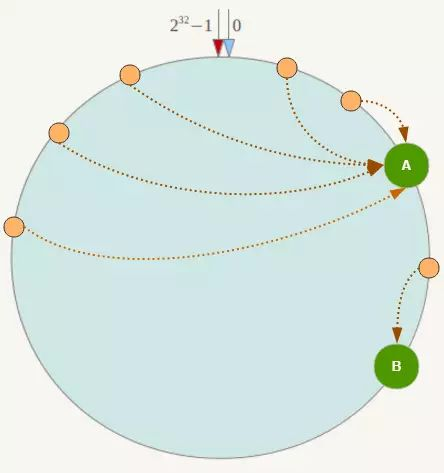
如上图,A节点(机器)附近的key比较多,而B节点只有一个key,那么怎么解决这种问题呢?
虚拟节点的概念被引入了
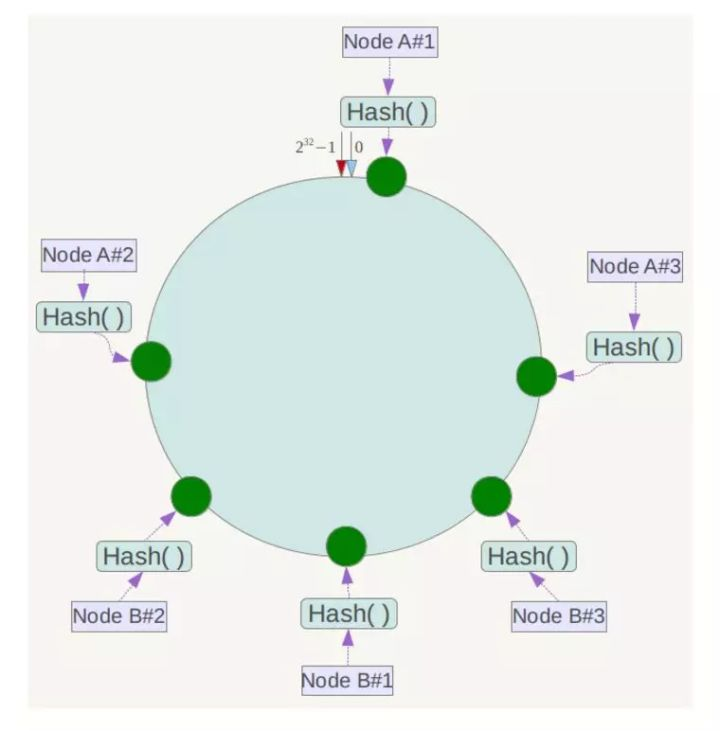
如图,因为引入了虚拟节点,使得key分布的更均匀了(NODEA#1,NODEA#2为NODEA的虚拟节点。
golang consistent hasing实现
让我们来看一个golang consistent库实现 eg:https://github.com/stathat/consistent
我们先来看下一致性hash的结构体
type Consistent struct {
circle map[uint32]string // 存储crc32后该key的值
members map[string]bool // 存储键值
sortedHashes uints // 排序后的数组
NumberOfReplicas int // 实际上是虚拟节点
count int64 // 整个结构体的数量
scratch [64]byte // 这个字段没有用
sync.RWMutex // 读写锁
}
初始化
func New() *Consistent {
c := new(Consistent)
c.NumberOfReplicas = 20 // 默认每个节点虚拟节点的数量
c.circle = make(map[uint32]string) // 初始化circle
c.members = make(map[string]bool) // 初始化members
return c
}
新增机器
func (c *Consistent) Add(elt string) {
c.Lock()
defer c.Unlock()
// 增加互斥锁,防止并发新增
c.add(elt)
}
func (c *Consistent) add(elt string) {
// 遍历,增加虚节点cache
for i := 0; i < c.NumberOfReplicas; i++ {
c.circle[c.hashKey(c.eltKey(elt, i))] = elt
// output like: c.circle[1765504436] = cacheA
}
// 存储键值
c.members[elt] = true
// 使hashkey有序
c.updateSortedHashes()
// 数量 + 1
c.count++
}
// 对key进行string化
func (c *Consistent) eltKey(elt string, idx int) string {
// return elt + "|" + strconv.Itoa(idx)
// if string == cacheA
/* output like 0cacheA
1cacheA
2cacheA
*/
return strconv.Itoa(idx) + elt
}
func (c *Consistent) hashKey(key string) uint32 {
// 如果传进来的字符串小于64位,优化操作
if len(key) < 64 {
var scratch [64]byte
copy(scratch[:], key)
return crc32.ChecksumIEEE(scratch[:len(key)])
}
// 对于key进行crc32得出key的int值
return crc32.ChecksumIEEE([]byte(key))
}
查找数据接口
func (c *Consistent) Get(name string) (string, error) {
// 加读锁
c.RLock()
defer c.RUnlock()
// 如果c.circle没数据,返回error
if len(c.circle) == 0 {
return "", ErrEmptyCircle
}
// 把key hash化
key := c.hashKey(name)
// 搜索key
i := c.search(key)
return c.circle[c.sortedHashes[i]], nil
}
// 查找过程
func (c *Consistent) search(key uint32) (i int) {
f := func(x int) bool {
return c.sortedHashes[x] > key
}
// sort.Search实际上是个基于f()函数进行search,找到c.sortedHashes[x] > key的位置然后进行返回
i = sort.Search(len(c.sortedHashes), f)
// 如果i>数组的长度,则默认i在0号位置上
if i >= len(c.sortedHashes) {
i = 0
}
return
}
从一致性hash内移除数据(机器)
func (c *Consistent) Remove(elt string) {
c.Lock()
defer c.Unlock()
// 加锁,防止并发删除
c.remove(elt)
}
// 移除数据
func (c *Consistent) remove(elt string) {
for i := 0; i < c.NumberOfReplicas; i++ {
// 从map里面删除这个元素
delete(c.circle, c.hashKey(c.eltKey(elt, i)))
}
delete(c.members, elt)
// 重新排序
c.updateSortedHashes()
// 数量 - 1
c.count--
}
一致性hash的应用
- Partitioning component of Amazon's storage system Dynamo
- Data partitioning in Apache Cassandra
- Data Partitioning in Voldemort
一致性hash在这几款数据库都有应用
refrence
- consistent paper:(timroughgarden.org/s17/l/l1.pd…)
- 一致性hash图参考 zhuanlan.zhihu.com/p/34985026
- wikipad:en.wikipedia.org/wiki/Consis…
