

题目:设计一个身份证查询系统,将身份证号md5 之后存储,输入md5值查询对应的身份证号。 要求:成本低,查询速度快
设计思路:
- 将所有可能的身份证号做一个简单的统计计算数据量
- 根据数据量选择存储方式
- 查询
身份证生成规则:
身份号码是特征组合码,由前十七位数字本体码和最后一位数字校验码组成。排列顺序从左至右依次为六位数字地址码,八位数字出生日期码,三位数字顺序码和一位数字校验码。
地址码: 表示编码对象常住户口所在县(市、旗、区)的行政区划代码。对于新生儿,该地址码为户口登记地行政区划代码。需要没说明的是,随着行政区划的调整,同一个地方进行户口登记的可能存在地址码不一致的情况。行政区划代码按GB/T2260的规定执行。
出生日期码:表示编码对象出生的年、月、日,年、月、日代码之间不用分隔符,格式为YYYYMMDD,如19880328。按GB/T 7408的规定执行。原15位身份证号码中出生日期码还有对百岁老人特定的标识,其中999、998、997、996分配给百岁老人。
顺序码: 表示在同一地址码所标识的区域范围内,对同年、同月、同日出生的人编定的顺序号,顺序码的奇数分配给男性,偶数分配给女性。
校验码: 根据本体码,通过采用ISO 7064:1983,MOD 11-2校验码系统计算出校验码。算法可参考下文。前面有提到数字校验码,我们知道校验码也有X的,实质上为罗马字符X,相当于10.
校验码算法
将本体码各位数字乘以对应加权因子并求和,除以11得到余数,根据余数通过校验码对照表查得校验码。
加权因子表:
+-----------------------------------------------------------+
|位置序号|1 |2 |3 |4 |5 |6 |7 |8 |9 |10|11|12|13|14|15|16|17|
+-----------------------------------------------------------+
|加权因子|7 |9 |10|5 |8 |4 |2 |1 |6 |3 |7 |9 |10|5 |8 |4 |2 |
+-----------------------------------------------------------+
校验码表:
+----------------------------------------------------+
| 余数 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
+----------------------------------------------------+
| 校验码| 1 | 0 | X | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 |
+----------------------------------------------------+
算法举例:
本体码为11010519491231002
- 第一步:各位数与对应加权因子乘积求和1* 7+1 * 9+0 * 10+1 * 5+ *** =167
- 第二步:对求和进行除11得余数167%11=2
- 第三步:根据余数2对照校验码得X
**因此完整身份证号为:11010519491231002X **
预估数据量:
- 身份证号18位,前六位为地区码,中间八位为日期,日期后三位为顺序码,最后一位为校验位,占32个字节
- md5值为32位,占32个字节
- 计算最近100年数据,大约数据量为:
3465x100x365x999=126346027500 - 数据以字符串存储,每条数据
32+18=50B - 则数据量为 `126346027500 x 50=6317301375000B=6169239624k=6024648M=5883G=5.74T ``
存储方式有文件存储、关系型数据库存储和es存储等。从结果可以看到有接近6T的数据,如果存入数据库或es成本较高,这里选择以文件的方式存储。
那有没有方式压缩存储空间呢?
- 身份证号最后一位为校验位,可以不存储,省略掉这一位会节约1/50点空间
- 不以字符串的方式存储,将身份证号以uint64存储,md5值也转化成两个uint64存储。uint64占8阁字节空间,这样一条数据的空间由50降为了 24。最终数据量为2.74T,节约一半多的空间。
那现在有一个问题,每个文件多大合适呢?
如果文件太大,每次将文件读取到内存中耗时较长,如果文件太小,则会生成太多的文件可能超出系统的文件数限制。
这里可以参考数据库索引的存储方式,设定每个数据文件的大小(2.8T数据可以设置每个数据文件1G左右。
数据生成后如何查询?
- 遍历,依次读取文件,查找数据,效率太低
- 这里参考数据库索引的查询方式,首先将数据按md5值排序后存储多个文件,记录每个文件中md5值的范围,输入md5值确定文件,再读取文件使用二分查找。
- 这时查找数据只需要读取一个文件,但是每个文件都有几百兆的数据,查询效率还是太低,再参考一下数据库索引,这里将文件内部再分页,记录每页的范围,和文件所自身记录的起始值一起生成索引,索引结构如图所示:
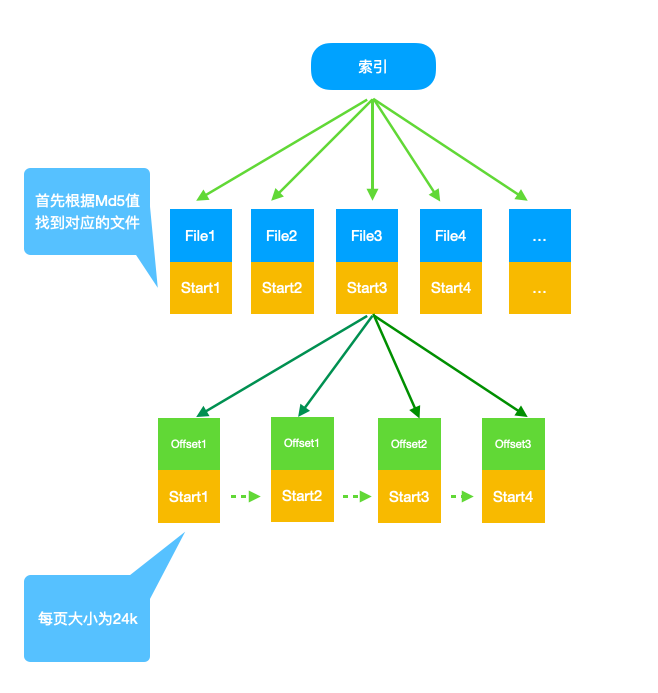
索引数据结构为:
# 为了简化存储,这里file1、file2、file3、file4 为该文件第一条数据的md5值,也是对应的文件名
# 页的大小固定,所以二级索引只需要按顺序记录每页的第一个md5值即可
indexes = {
"file1": ["md51", "md52", "md53", "..."],
"file2": ["md51", "md52", "md53", "..."],
"file3": ["md51", "md52", "md53", "..."],
"file4": ["md51", "md52", "md53", "..."],
}
第一层索引为文件索引,首先通过md5值判断md5值所在文件,比如输入的 start1 > md5 > start1,可以判断结果可能在file1 中;
第二层为文件内索引,通过md5值判断所在的页,读取根据offset读取该页的全部数据,再通过二分查找找到对应的身份证号。
代码实现源码地址:github.com/gusibi/onep…
使用方式:
1. go run main.go
2. curl http://127.0.0.1:8080/search?md5={id md5}
参考链接:
最后,感谢女朋友支持和包容,比❤️
也可以在公号输入以下关键字获取历史文章:公号&小程序 | 设计模式 | 并发&协程

