

这张照片,你能分辨出是真人实拍还是对着手机屏幕照片翻拍的吗?

如果告诉你,这张照片,实际上是对着手机屏幕照片翻拍的,你会不会惊讶?
但就是对于这种几乎以假乱真的照片,双目活体能很轻松地判断出来这张照片到底是真人照片还是照片翻拍。在金融、征信、安防等人脸识别应用最广泛的场景中,人脸活体识别可以说是具备大规模应用的最关键环节。
1 什么是双目活体
双目,就是有两个眼睛。一个眼睛是可见光摄像头,采集彩色照;还有一个眼睛是近红外摄像头,采集的黑白照。而双目活体,实际上也对应了两种算法,单目人脸活体识别和近红外活体识别。
-
可见光人脸活体识别的原理,是利用图片中人像的破绽(摩尔纹、成像畸形等)来判断目标对象是否为活体,可有效防止屏幕二次翻拍等作弊攻击
-
近红外活体识别的原理,是红外摄像头发射红外光线,照射到物体表面,利用成像元件(CCD或CMOS)去感受周围环境反射回来的红外光,因为不同材质的反射率不同等原因,再通过算法分析,即可识别是当前用户是否是真人。
由于自带红外光源,因此受环境光的影响较小,可以在完全黑暗的环境下成像,对于手机屏幕有近100%的防攻击能力,如下图!

人脸活体识别的关键指标包括:
-
识别速度:算法从接收到图片到输出结果的时间
-
通过率:设定好一个阈值,给定N个真人样本,算法输出的分值高于阈值(即正确判断为真人)的样本为M,则通过率=M/N
-
拒绝率:设定好一个阈值,给定N个攻击样本,算法输出的分值低于阈值(即正确判断为假人)的样本为M,则拒绝率=M/N
通过率与拒绝率,是在同一个阈值下测试出来的,选取的阈值高,通过率低,拒绝率高;选取的阈值低,通过率越高,但是拒绝率高。
2 双目人脸活体识别为什么这么重要
-
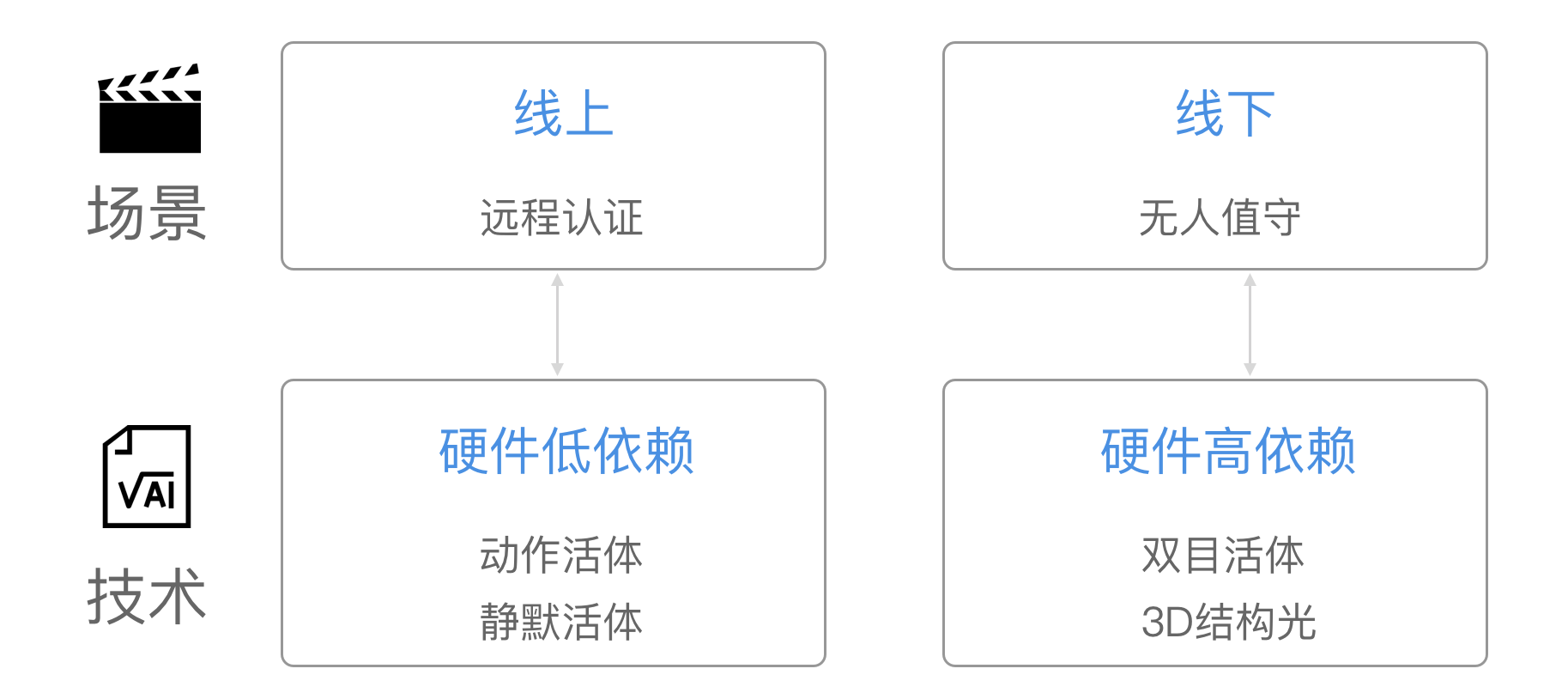
线下场景,高度契合
云识客将目前人脸识别的主要应用场景分为两类:线上远程认证场景(金融开户、刷脸注册、刷脸登录等)、线下无人值守场景(人脸门禁、刷脸取款、刷脸支付等)。
人脸活体识别的技术上,目前也主要有两大类:对硬件依赖度比较低的,如动作活体,静默活体;对硬件有一定要求,需要和硬件适配的,比如双目活体、3D结构光活体等。虽然后者的成本比前者高,但是防攻击效果更好,而在线下场景中,天然的需要硬件,因而后者也成为线下场景的最好选择。
-
技术成熟,商用广泛
成本上,双目活体比3D结构光活体的技术难度也更低,因而成本更低,市场上双目摄像头模组成本大概¥300左右,而3D结构光模组要¥500~800;
产业结构上,能够批量做3D结构光硬件的,中国目前只有两家;而能做双目活体硬件的,则数不胜数。所以线下场景的主流还是双目活体,普及度更高,行业发展更成熟。
-
黑产博弈,依然可靠
有光明的地方,就会有黑暗。如今的黑产,已不仅仅是只会懂得用电信诈骗等手段来欺诈,他们也懂得利用AI和科技,并形成产业化,提供给上下游使用。
比如目前很多互金app的人脸活体识别,都采用动作活体的方式(即系统出现随机动作,用户即时做出指定动作才被认为是真人),黑产针对这种方式,使用3D建模技术,只需要一张照片,即可生成任何指定的动作。而双目活体,依然是目前最可靠的防攻击手段之一。
3 详解云识客的双目活体技术
3.1 核心思路
虽然目前业界已经有多种双目人脸活体识别算法,但多数算法为了得到准确率高的人脸活体识别模型,使用了比较大的神经网络,虽然提升了模型的表现能力,但是模型太大,运算耗时。如何兼顾识别准确率与识别速度,一直是业界的一大难题。
云识客通过采集多张人脸区域,更有效的捕捉活体和非活体数据之间的区别,引入更多的有效判别信息到卷积神经网络,提升识别准确率;同时多张人脸共享卷积神经网络,相比其他一张人脸对应一个神经网络,有效减小模型计算复杂度。
3.2 实现思路
先来看看整体的实现逻辑:
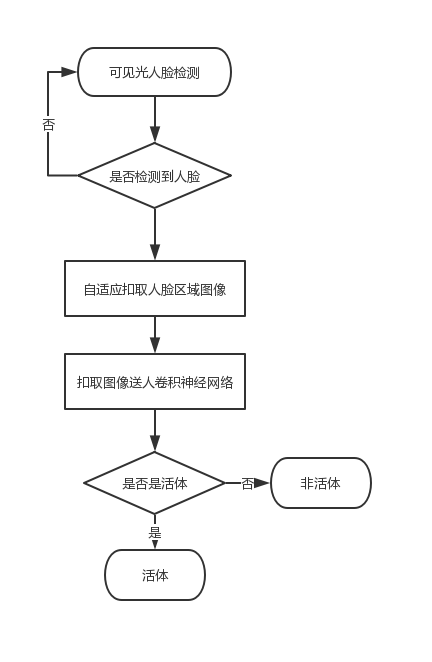
从这个流程图上,可以很清晰的看到,整体上有两个关键步骤:自适应扣取人脸、卷积神经网络。
-
自适应扣取人脸
更有效地捕捉活体与非活体数据的区别,采集到更多的有效判别信息,帮助提升识别准确率。
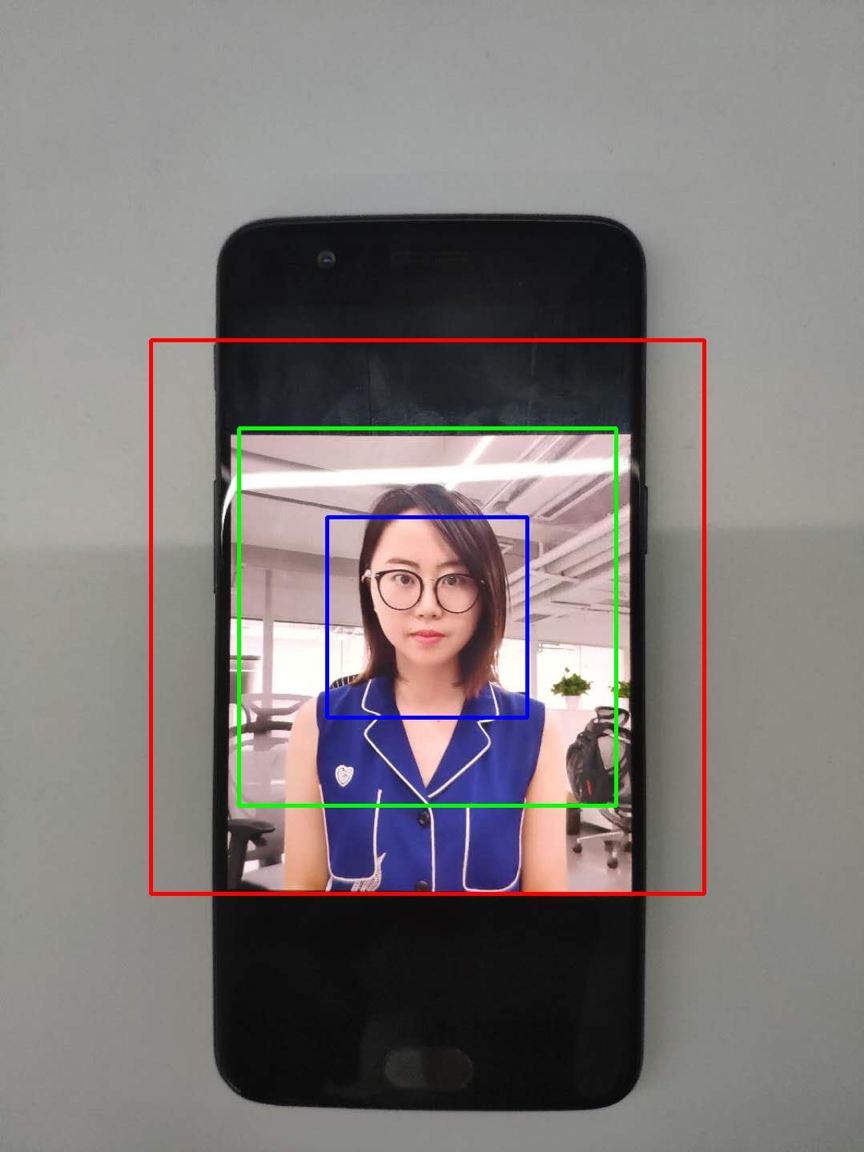
如上图,我们依次扣取不同人脸占比的图像送入同一个CNN网络,增加了更多活体判断的有效信息,其中蓝色框主要捕获摩尔纹、反光、人脸畸变等信息,红色区域捕捉手机边界、纸张边界等明显攻击信息,绿色区域是过渡区域,捕捉相关背景信息。
整体计算公式如下:

-
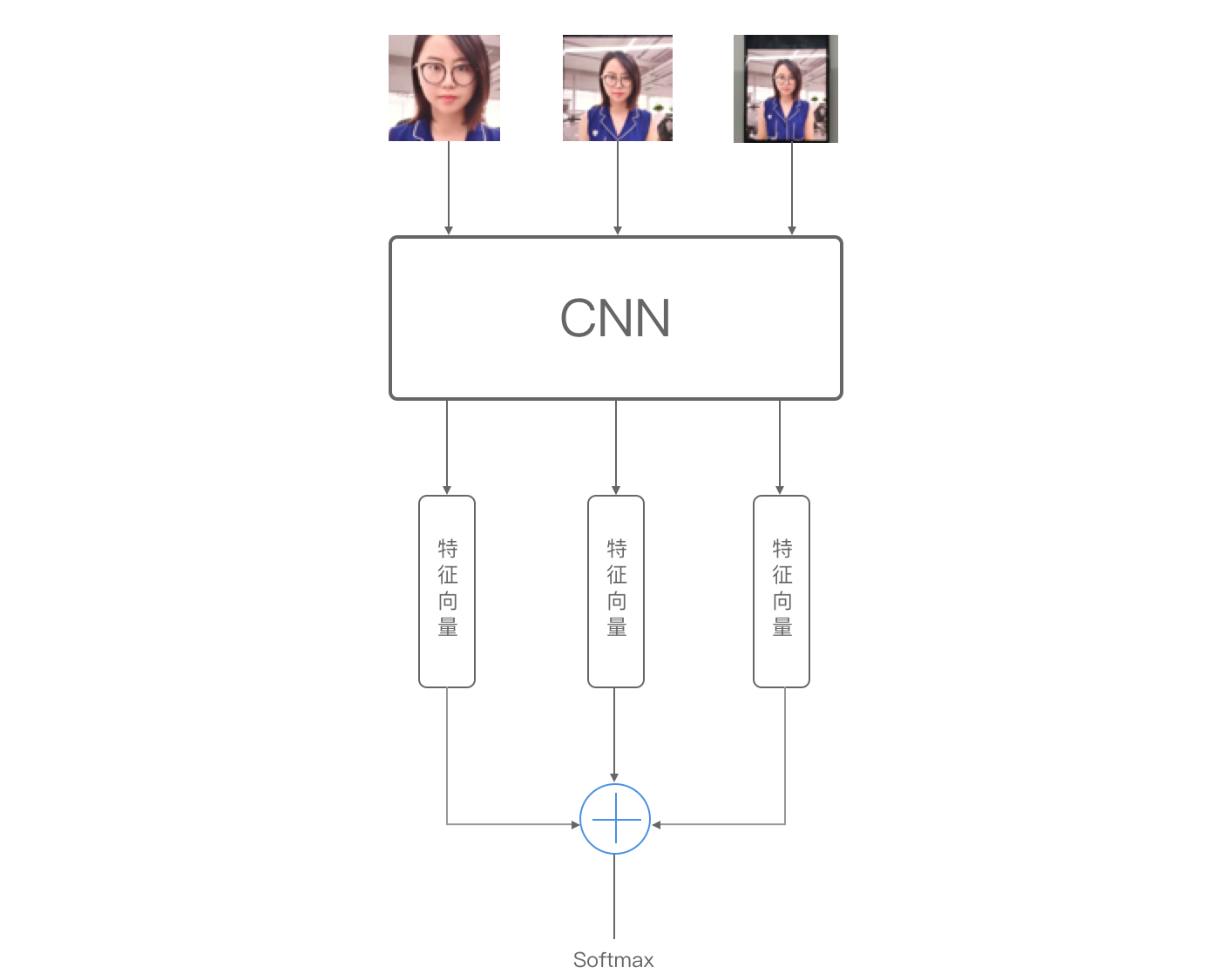
卷积神经网络
在自适应扣取人脸中,我们截取的三个不同区域的图像数据,共享CNN,这样也能减少模型的复杂度,再融合三个图像输出的不同特征,共同决定最后的分类结果。
同时设计新颖的针对单目/活体网络训练的损失函数,增加网络的泛化性能。

-
样本搜集
最后,除了算法的维度,云识客还搜集了海量的攻击样本数据,包括手机、屏幕、纸张、面具等攻击场景样本,覆盖面广泛,进一步增强活体防攻击效果。

-
光流法辅助单目活体判断
最后,针对单目活体,云识客也采用光流法辅助活体判断的校验机制。所谓的光流场,即物体在三维真实世界中的运动,在二维图像平面上的投影。

如图:通过帧间信息求取光流场数据,对于纸张攻击和手机攻击来说,求得的光流场与实际活体人脸区域的光流场有很大区别。活体人脸区域的光流场存在方向不一致性,并且与背景分离,纸张和手机攻击的光流场存在方向一致性并且人脸区域与背景是不分离的,通过此类规律可以过滤掉大部分运动状态下的非活体攻击数据。
3.3 测试关键指标
-
识别速度
整体算法模型大小仅5M,即使在低性能设备上,也能流畅运行。在3288的CPU上,仅耗时120ms,比同类竞争对手快200ms。
-
通过率与拒绝率
实际场景照片下的通过率达99.5%,拒绝率达99.9%
4 写在最后
算法的关键在于策略。算法不是空中楼阁,也需要结合实际的应用场景与需求,并深度结合,才能发挥最大的价值。
