

今天在看书时,看到了路由解析,看着看着就想到了以前遇到的一道面试题:从浏览器输入网址到显示页面之间发生了什么?
这个问题说难不难,要说简单也不简单,涉及的领域有很多。本着刨根问底的精神,我就想把这个问题往深里挖。
声明:欢迎在评论中指出本文章中的错误,也可以私信我哦。
先说简单的回答:
- 浏览器地址栏输入URL并回车确认
- URL解析/DNS解析查找域名IP地址
- 网络连接发起HTTP请求
- HTTP报文传输过程
- 服务器接收数据
- 服务器响应请求
- 服务器返回数据
- 客户端接收数据
- 浏览器加载/渲染页面
- 打印绘制输出
接下来是重头戏,为了便于理解,可以将问题划分为几个小问题,分步进行:
浏览器地址栏输入URL并回车确认到客户端发送请求期间发生了什么?
1. 浏览器查看缓存
使用http时,浏览器通常情况下大多数缓存只应用在GET请求中,如POST,DELETE, PUT这类带行为性的操作不作任何缓存。
浏览器会查看请求资源本地缓存是否存在并新鲜,使用缓存流程如下图
后面会写一篇文章来详细介绍浏览器如何使用缓存
强制缓存和协商缓存

2. 浏览器解析url
url构成:
在输入网址时浏览器默认使用http协议
浏览器解析url获取协议,主机,端口和路径,封装成一个http(GET)请求报文。
还有细节,以后补充
浏览器根据域名获取主机ip
- 浏览器缓存
- 本机缓存
- hosts文件
- 路由器缓存
- ISP DNS缓存
- DNS递归查询(可能存在负载均衡导致每次IP不一样)
当我们输入这样一个请求时,首先要建立一个socket连接,因为socket是通过ip和端口建立的,所以之前还有一个DNS解析过程,把www.mycompany.com变成ip,如果url里不包含端口号,则会使用该协议的默认端口号。
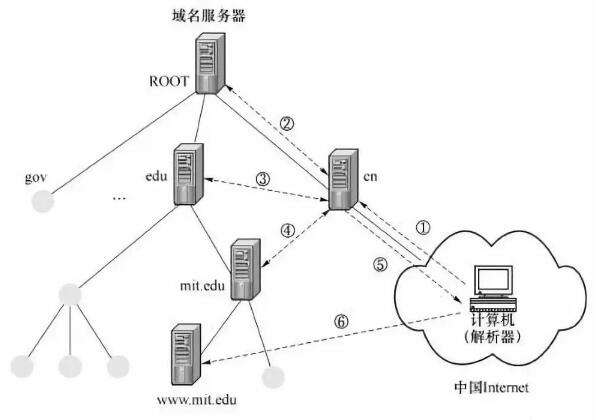
首先我们知道我们本地的机器上在配置网络时都会填写DNS,这样本机就会把这个URL发给这个配置的DNS服务器,如果能够找到相应的URL则返回其ip,否则该DNS将继续将该解析请求发送给上级DNS,整个DNS可以看做是一个树状结构,该请求将一直发送到根直到得到结果。现在已经拥有了目标ip和端口号,这样我们就可以打开socket连接了。
连接成功建立后,开始向web服务器发送请求,这个请求一般是GET或POST命令(POST用于FORM参数的传递)。
ISO七层模型和TCP/IP四层模型
这部分内容以后补充
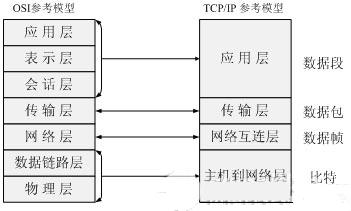
http协议是基于TCP/IP的应用层协议
ARP
是根据IP地址获取物理地址的一个TCP/IP协议。主机发送信息时将包含目标IP地址的ARP请求广播到局域网络上的所有主机,并接收返回消息,以此确定目标的物理地址;收到返回消息后将该IP地址和物理地址存入本机ARP缓存中并保留一定时间,下次请求时直接查询ARP缓存以节约资源。
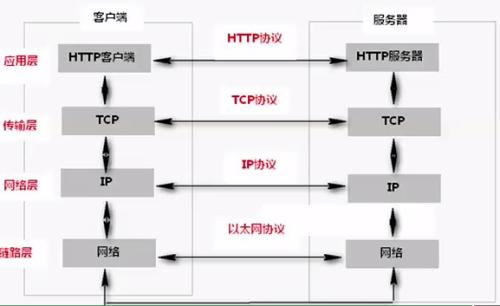
客户端数据包从应用层一步步封装至物理层发送给服务器,服务器又自下而上解析成有效数据
- 应用层: 应用层是在用户空间实现的,负责处理众多业务逻辑,如文件传输、网络管理
- http协议属于应用层
- 传输层: 为应用程序隐藏了数据包跳转的细节,负责数据包的收发、链路超时重连等
- TCP协议
- 网络层: 能够使得不同应用类型的数据在Internet上通畅地传输
- IP协议
- ARP(地址解析协议),根据ip在网络上找到对应主机网卡的MAC地址
- 物理层: 实现网卡接口的网络驱动,以处理数据在以太网等物理媒介上的传输
Socket 库提供查询 IP 地址的功能,用于调用网络功能的程序组件集合,通过socket、协议栈、网卡和DNS服务器查询IP地址,委托协议栈发送消息时通过:
- 创建套接字
- 将管道连接到服务器端的套接字上
- 收发数据
- 断开管道并删除套接字。
浏览器确定了 Web 服务器和文件名,再根据这些信息来生成 HTTP请求消息,使用get或post方法等发送请求。
从服务器接受到客户端请求到响应期间发生了什么?
- 网卡将接收到的信号转换成数字信息, MAC 模块将网络包从信号还原为数字信息,校验 FCS,并存入缓冲区,网卡驱动会根据 MAC 头部判断协议类型,并将包交给相应的协议栈。
- IP模块会进行接收操作,协议栈的IP模块会检查 IP 头部,判断是不是发给自己的并且判断网络包是否经过分片,再将包转交给 TCP 模块或 UDP 模块。
- TCP模块处理连接包和数据包,收到的是发起连接的包时,则TCP模块会确认TCP头部的控制位SYN,检查接收方端口号,为相应的等待连接套接字复制一个新的副本,记录发送方 IP 地址和端口号等信息。
- 收到数据包时TCP模块会根据收到的包的发送方IP地址、发送方端口号、接收方 IP 地址、接收方端口号找到相对应的套接字,将数据块拼合起来并保存在接收缓冲区中,向客户端返回ACK。
- 当数据收发完成后,TCP模块便开始执行断开操作。
- 服务器解释请求并作出响应
- 后端在这里实现功能
- 将请求的 URI 转换为实际的文件名,再运行 CGI 程序最终返回响应消息。
浏览器接收到服务端返回的响应到页面渲染完成。
- 浏览器检查响应状态吗:是否为1XX,3XX, 4XX, 5XX,这些情况处理与2XX不同
- 如果资源可缓存,进行缓存
- 对响应进行解码(例如gzip压缩)
- 根据资源类型决定如何处理(假设资源为HTML文档)
- 解析HTML文档,构件DOM树,下载资源,构造CSSOM树,执行js脚本,这些操作没有严格的先后顺序,以下分别解释
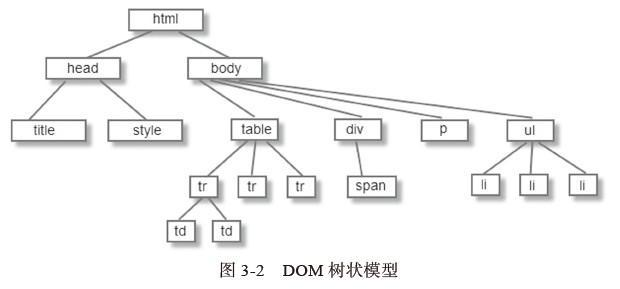
- 构建DOM树:
- Tokenizing:根据HTML规范将字符流解析为标记
- Lexing:词法分析将标记转换为对象并定义属性和规则
- DOM construction:根据HTML标记关系将对象组成DOM树
- 解析过程中遇到图片、样式表、js文件,启动下载
- 图例:
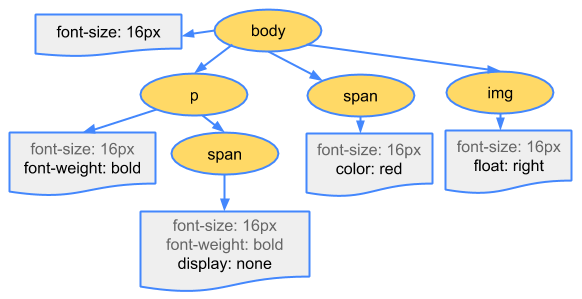
- 构建CSSOM树:
- Tokenizing:字符流转换为标记流
- Node:根据标记创建节点
- CSSOM:节点创建CSSOM树
- 图例:
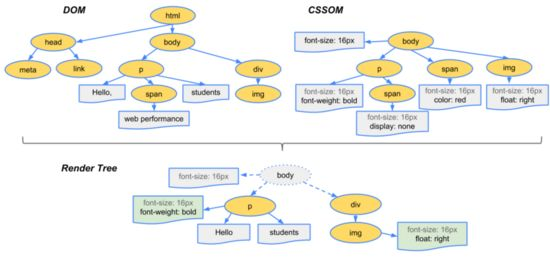
- 根据DOM树和CSSOM树构建渲染树:
- 从DOM树的根节点遍历所有可见节点,不可见节点包括:1)script,meta这样本身不可见的标签。2)被css隐藏的节点,如display: none
- 对每一个可见节点,找到恰当的CSSOM规则并应用
- 发布可视节点的内容和计算样式
- 图例:
- js解析如下:
- 创建Document对象,开始解析web页面,解析HTML元素和他们的文本内容后添加Element对象和Text节点到文档中。这个阶段Document。readyState = "loading"。
- 遇到link外部css,创建线程加载,并继续解析文档。
- 遇到script外部js,并且没有设置async , defer,浏览器加载,并阻塞,等待js加载完成并执行该脚本,然后继续解析文档
- 遇到script外部js,并且设置有async,defer 浏览器创建线程加载,并继续解析文档,对于async属性的脚本,脚本加载完成后立即执行(异步禁止使用docuemnt.write())。
- 遇到img标签等,先正常解析dom结构,然后浏览器异步加载src,并继续解析文档
- 当文档解析完成,document.readyState = "interactive";
- 文档解析完成后,所有设置有defer的脚本会按照顺序执行。
- 当文档解析完成之后,document对象触发DOMContentLoaded事件,这也标志着程序执行从同步脚本执行阶段,转化为事件驱动阶段
- 当所有saync的脚本加载完成并执行后,img等加载完成后,document.readyState = "complete" window对象触发load事件
- 从此,页面以异步响应方式处理用户输入,网络事件等
- 显示页面(HTML解析过程中会逐步显示页面)
现在为止就写了这么多,网上也找了很多资料,在这期间也学到了很多,在写的过程中才能发现这个问题不好深挖,涉及的领域太多,底层原理太多,就我这篇文章来说,其实大多数还是属于应用层面的东西,非常的浅。大多数底层,如屏幕的显示原理,操作系统原理,网络技术,通信技术,东西太多,以后会慢慢补充,争取把这篇文章完成。
参考文章:
- socket和http的区别:blog.csdn.net/jy55149676/…
- 从输入 URL 到页面加载完成的过程中都发生了什么事情?fex.baidu.com/blog/2014/0…
- 一个完整的http请求发送到服务端?blog.csdn.net/qq_29503203…
- 从http发送请求到服务端响应?blog.csdn.net/qq_41974256…
